 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIT Autonomous Vehicle Technology Study: Large-Scale Deep Learning Based Analysis of Driver Behavior and Interaction with Automation
Sep 30, 2018
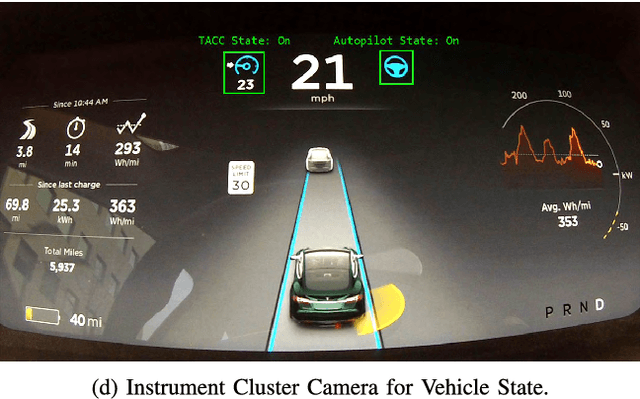
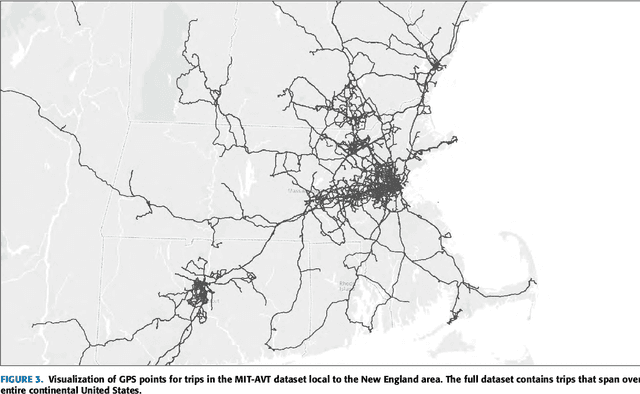
For the foreseeble future, human beings will likely remain an integral part of the driving task, monitoring the AI system as it performs anywhere from just over 0% to just under 100% of the driving. The governing objectives of the MIT Autonomous Vehicle Technology (MIT-AVT) study are to (1) undertake large-scale real-world driving data collection that includes high-definition video to fuel the development of deep learning based internal and external perception systems, (2) gain a holistic understanding of how human beings interact with vehicle automation technology by integrating video data with vehicle state data, driver characteristics, mental models, and self-reported experiences with technology, and (3) identify how technology and other factors related to automation adoption and use can be improved in ways that save lives. In pursuing these objectives, we have instrumented 21 Tesla Model S and Model X vehicles, 2 Volvo S90 vehicles, 2 Range Rover Evoque, and 2 Cadillac CT6 vehicles for both long-term (over a year per driver) and medium term (one month per driver) naturalistic driving data collection. Furthermore, we are continually developing new methods for analysis of the massive-scale dataset collected from the instrumented vehicle fleet. The recorded data streams include IMU, GPS, CAN messages, and high-definition video streams of the driver face, the driver cabin, the forward roadway, and the instrument cluster (on select vehicles). The study is on-going and growing. To date, we have 99 participants, 11,846 days of participation, 405,807 miles, and 5.5 billion video frames. This paper presents the design of the study, the data collection hardware, the processing of the data, and the computer vision algorithms currently being used to extract actionable knowledge from the data.
Automated Synchronization of Driving Data Using Vibration and Steering Events
Mar 01, 2016

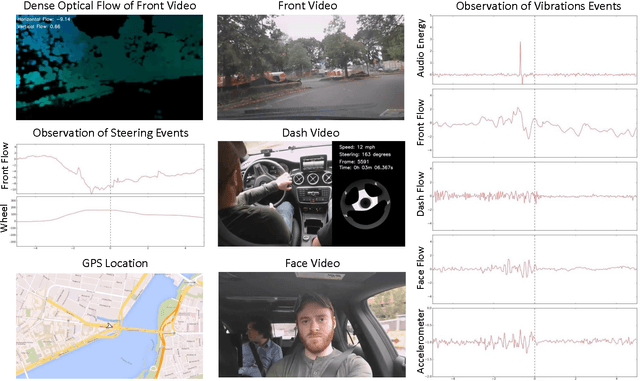
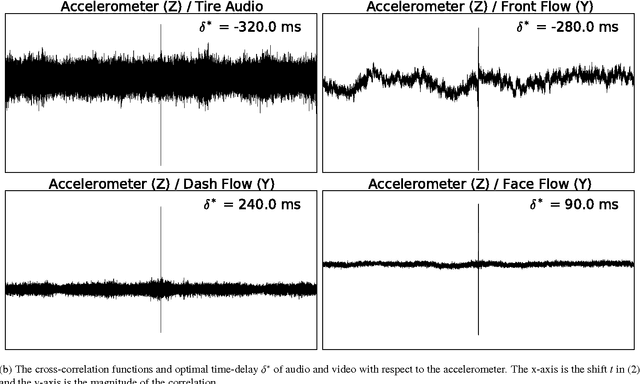
We propose a method for automated synchronization of vehicle sensors useful for the study of multi-modal driver behavior and for the design of advanced driver assistance systems. Multi-sensor decision fusion relies on synchronized data streams in (1) the offline supervised learning context and (2) the online prediction context. In practice, such data streams are often out of sync due to the absence of a real-time clock, use of multiple recording devices, or improper thread scheduling and data buffer management. Cross-correlation of accelerometer, telemetry, audio, and dense optical flow from three video sensors is used to achieve an average synchronization error of 13 milliseconds. The insight underlying the effectiveness of the proposed approach is that the described sensors capture overlapping aspects of vehicle vibrations and vehicle steering allowing the cross-correlation function to serve as a way to compute the delay shift in each sensor. Furthermore, we show the decrease in synchronization error as a function of the duration of the data stream.
Detecting Road Surface Wetness from Audio: A Deep Learning Approach
Dec 04, 2015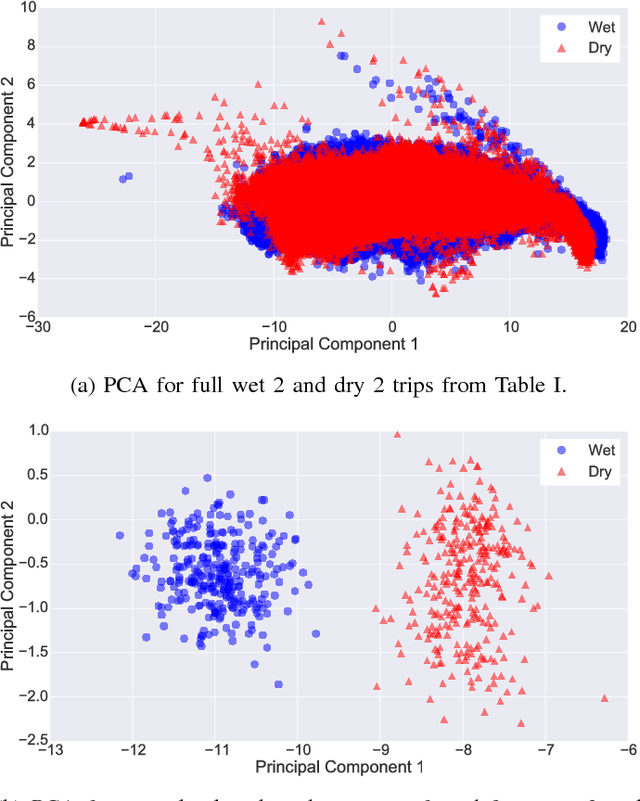


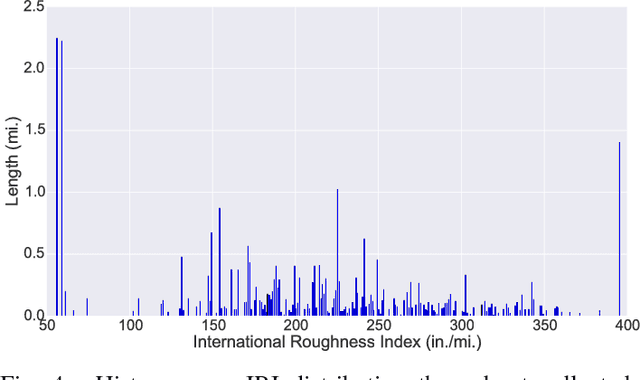
We introduce a recurrent neural network architecture for automated road surface wetness detection from audio of tire-surface interaction. The robustness of our approach is evaluated on 785,826 bins of audio that span an extensive range of vehicle speeds, noises from the environment, road surface types, and pavement conditions including international roughness index (IRI) values from 25 in/mi to 1400 in/mi. The training and evaluation of the model are performed on different roads to minimize the impact of environmental and other external factors on the accuracy of the classification. We achieve an unweighted average recall (UAR) of 93.2% across all vehicle speeds including 0 mph. The classifier still works at 0 mph because the discriminating signal is present in the sound of other vehicles driving by.