 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-supervised Any-shot Object Detection
Jun 12, 2020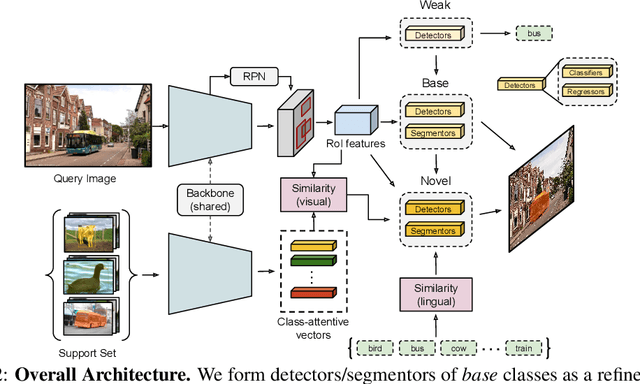
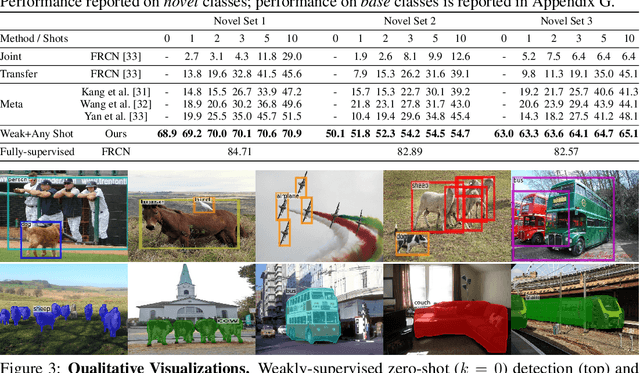
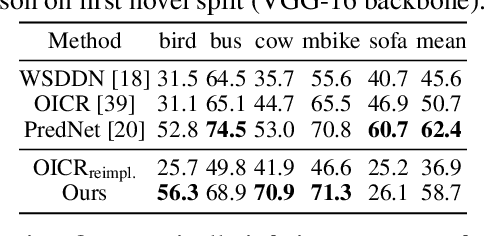
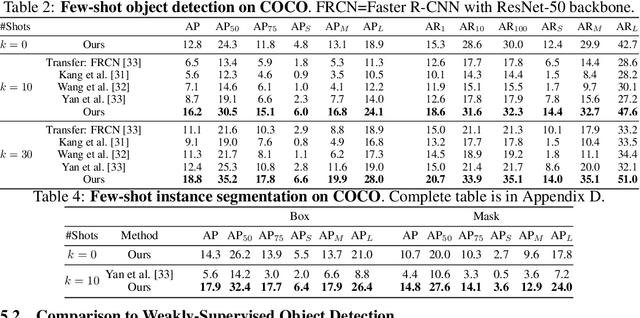
Methods for object detection and segmentation rely on large scale instance-level annotations for training, which are difficult and time-consuming to collect. Efforts to alleviate this look at varying degrees and quality of supervision. Weakly-supervised approaches draw on image-level labels to build detectors/segmentors, while zero/few-shot methods assume abundant instance-level data for a set of base classes, and none to a few examples for novel classes. This taxonomy has largely siloed algorithmic designs. In this work, we aim to bridge this divide by proposing an intuitive weakly-supervised model that is applicable to a range of supervision: from zero to a few instance-level samples per novel class. For base classes, our model learns a mapping from weakly-supervised to fully-supervised detectors/segmentors. By learning and leveraging visual and lingual similarities between the novel and base classes, we transfer those mappings to obtain detectors/segmentors for novel classes; refining them with a few novel class instance-level annotated samples, if available. The overall model is end-to-end trainable and highly flexible. Through extensive experiments on MS-COCO and Pascal VOC benchmark datasets we show improved performance in a variety of settings.
Consistent Multiple Sequence Decoding
Apr 15, 2020
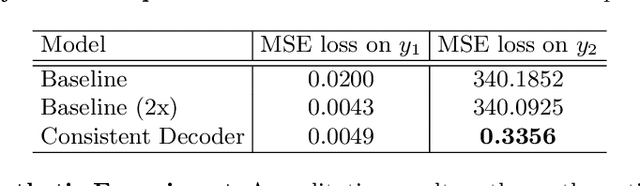
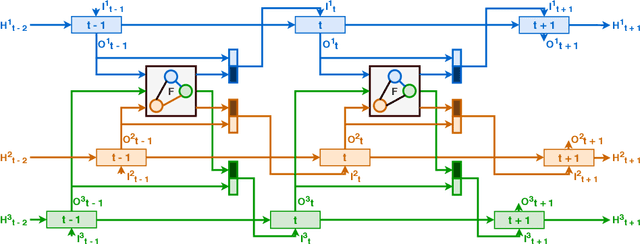
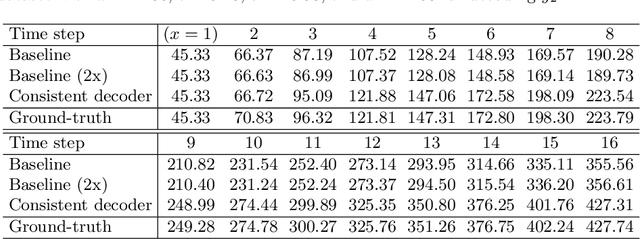
Sequence decoding is one of the core components of most visual-lingual models. However, typical neural decoders when faced with decoding multiple, possibly correlated, sequences of tokens resort to simple independent decoding schemes. In this paper, we introduce a consistent multiple sequence decoding architecture, which is while relatively simple, is general and allows for consistent and simultaneous decoding of an arbitrary number of sequences. Our formulation utilizes a consistency fusion mechanism, implemented using message passing in a Graph Neural Network (GNN), to aggregate context from related decoders. This context is then utilized as a secondary input, in addition to previously generated output, to make a prediction at a given step of decoding. Self-attention, in the GNN, is used to modulate the fusion mechanism locally at each node and each step in the decoding process. We show the efficacy of our consistent multiple sequence decoder on the task of dense relational image captioning and illustrate state-of-the-art performance (+ 5.2% in mAP) on the task. More importantly, we illustrate that the decoded sentences, for the same regions, are more consistent (improvement of 9.5%), while across images and regions maintain diversity.
Variational Hyper RNN for Sequence Modeling
Feb 24, 2020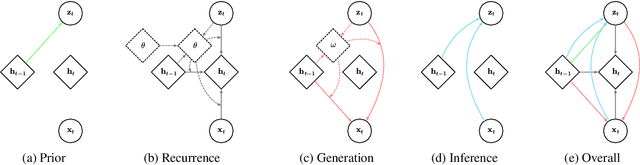

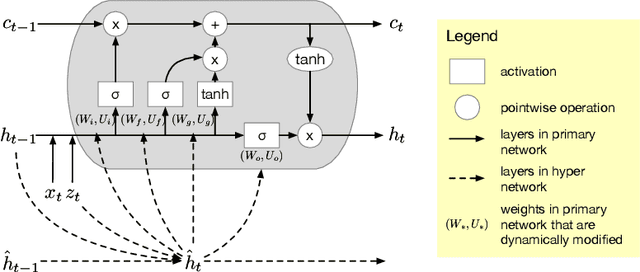
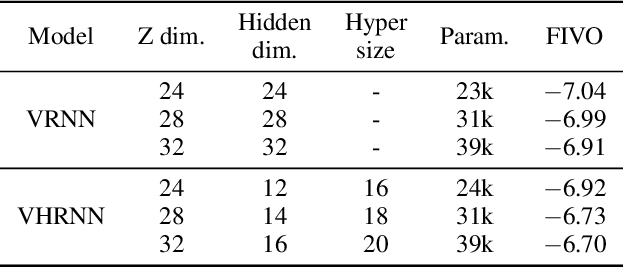
In this work, we propose a novel probabilistic sequence model that excels at capturing high variability in time series data, both across sequences and within an individual sequence. Our method uses temporal latent variables to capture information about the underlying data pattern and dynamically decodes the latent information into modifications of weights of the base decoder and recurrent model. The efficacy of the proposed method is demonstrated on a range of synthetic and real-world sequential data that exhibit large scale variations, regime shifts, and complex dynamics.
Front2Back: Single View 3D Shape Reconstruction via Front to Back Prediction
Jan 31, 2020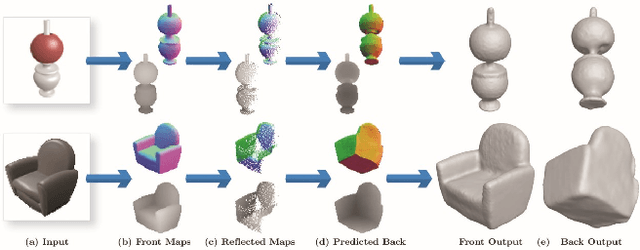



Reconstruction of a 3D shape from a single 2D image is a classical computer vision problem, whose difficulty stems from the inherent ambiguity of recovering occluded or only partially observed surfaces. Recent methods address this challenge through the use of largely unstructured neural networks that effectively distill conditional mapping and priors over 3D shape. In this work, we induce structure and geometric constraints by leveraging three core observations: (1) the surface of most everyday objects is often almost entirely exposed from pairs of typical opposite views; (2) everyday objects often exhibit global reflective symmetries which can be accurately predicted from single views; (3) opposite orthographic views of a 3D shape share consistent silhouettes. Following these observations, we first predict orthographic 2.5D visible surface maps (depth, normal and silhouette) from perspective 2D images, and detect global reflective symmetries in this data; second, we predict the back facing depth and normal maps using as input the front maps and, when available, the symmetric reflections of these maps; and finally, we reconstruct a 3D mesh from the union of these maps using a surface reconstruction method best suited for this data. Our experiments demonstrate that our framework outperforms state-of-the art approaches for 3D shape reconstructions from 2D and 2.5D data in terms of input fidelity and details preservation. Specifically, we achieve 12% better performance on average in ShapeNet benchmark dataset, and up to 19% for certain classes of objects (e.g., chairs and vessels).
Improved Few-Shot Visual Classification
Dec 12, 2019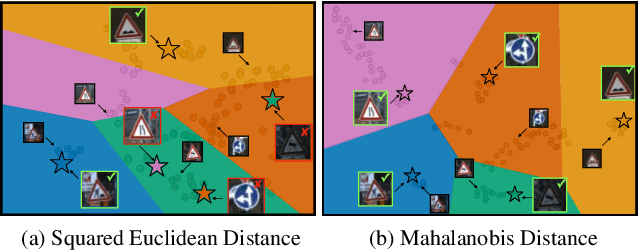

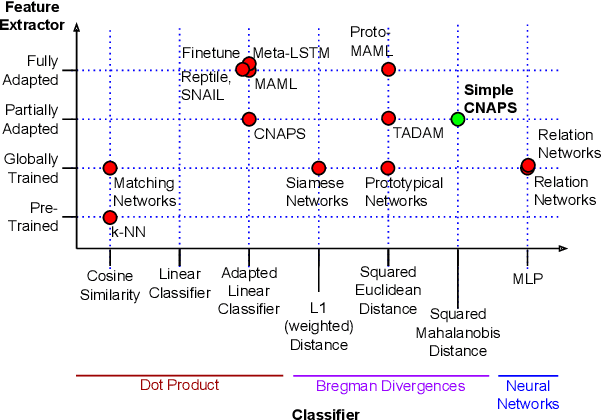

Few-shot learning is a fundamental task in computer vision that carries the promise of alleviating the need for exhaustively labeled data. Most few-shot learning approaches to date have focused on progressively more complex neural feature extractors and classifier adaptation strategies, as well as the refinement of the task definition itself. In this paper, we explore the hypothesis that a simple class-covariance-based distance metric, namely the Mahalanobis distance, adopted into a state of the art few-shot learning approach (CNAPS) can, in and of itself, lead to a significant performance improvement. We also discover that it is possible to learn adaptive feature extractors that allow useful estimation of the high dimensional feature covariances required by this metric from surprisingly few samples. The result of our work is a new "Simple CNAPS" architecture which has up to 9.2% fewer trainable parameters than CNAPS and performs up to 6.1% better than state of the art on the standard few-shot image classification benchmark dataset.
Zero-Shot Generation of Human-Object Interaction Videos
Dec 09, 2019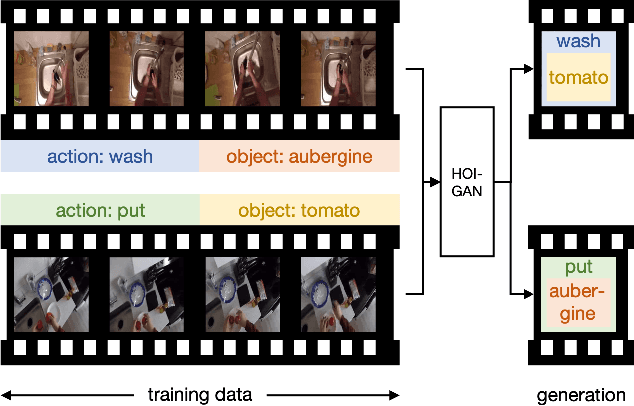
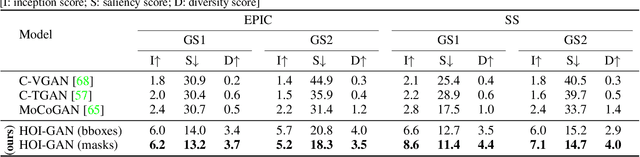
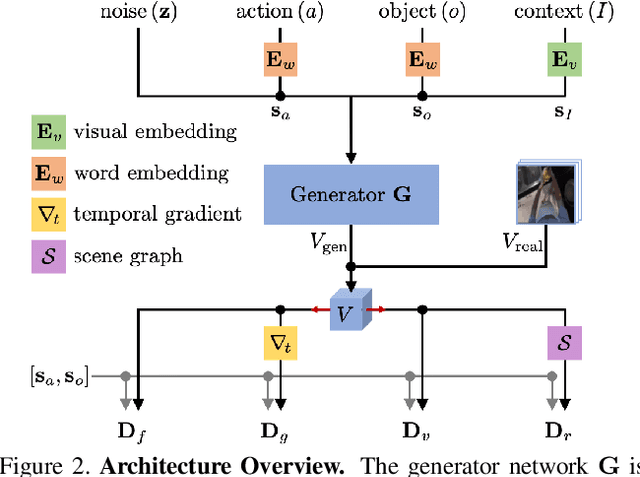
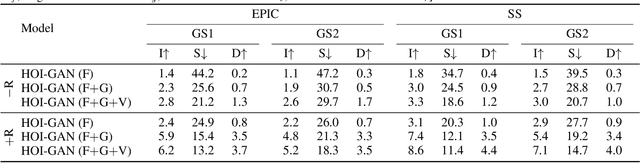
Generation of videos of complex scenes is an important open problem in computer vision research. Human activity videos are a good example of such complex scenes. Human activities are typically formed as compositions of actions applied to objects -- modeling interactions between people and the physical world are a core part of visual understanding. In this paper, we introduce the task of generating human-object interaction videos in a zero-shot compositional setting, i.e., generating videos for action-object compositions that are unseen during training, having seen the target action and target object independently. To generate human-object interaction videos, we propose a novel adversarial framework HOI-GAN which includes multiple discriminators focusing on different aspects of a video. To demonstrate the effectiveness of our proposed framework, we perform extensive quantitative and qualitative evaluation on two challenging datasets: EPIC-Kitchens and 20BN-Something-Something v2.
OptiBox: Breaking the Limits of Proposals for Visual Grounding
Nov 29, 2019
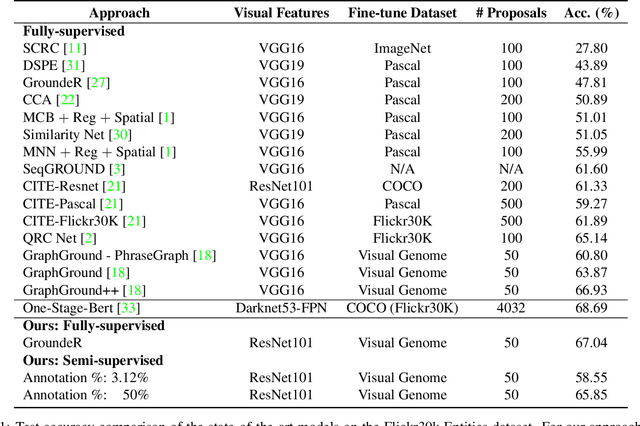
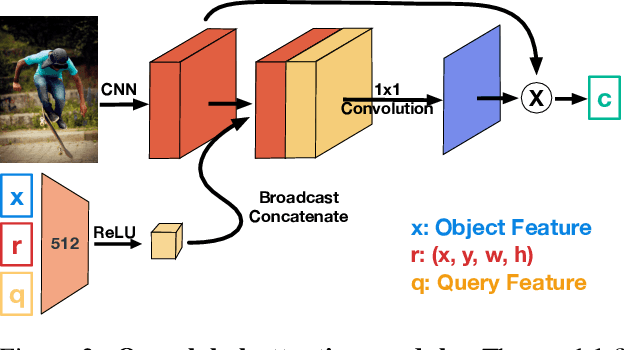

The problem of language grounding has attracted much attention in recent years due to its pivotal role in more general image-lingual high level reasoning tasks (e.g., image captioning, VQA). Despite the tremendous progress in visual grounding, the performance of most approaches has been hindered by the quality of bounding box proposals obtained in the early stages of all recent pipelines. To address this limitation, we propose a general progressive query-guided bounding box refinement architecture (OptiBox) that leverages global image encoding for added context. We apply this architecture in the context of the GroundeR model, first introduced in 2016, which has a number of unique and appealing properties, such as the ability to learn in the semi-supervised setting by leveraging cyclic language-reconstruction. Using GroundeR + OptiBox and a simple semantic language reconstruction loss that we propose, we achieve state-of-the-art grounding performance in the supervised setting on Flickr30k Entities dataset. More importantly, we are able to surpass many recent fully supervised models with only 50% of training data and perform competitively with as low as 3%.
Watch, Listen and Tell: Multi-modal Weakly Supervised Dense Event Captioning
Oct 25, 2019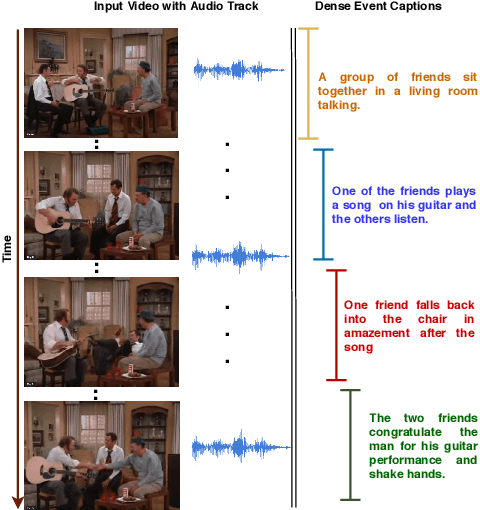
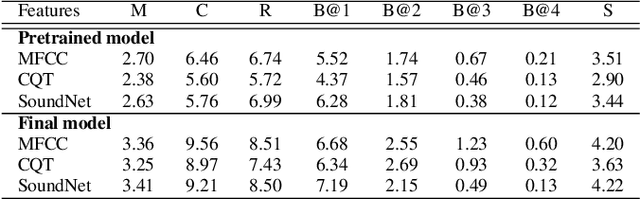
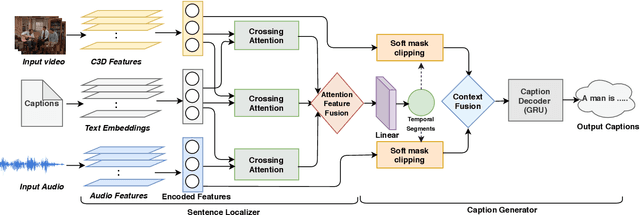
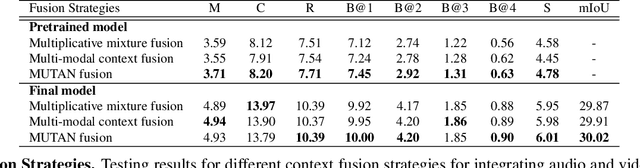
Multi-modal learning, particularly among imaging and linguistic modalities, has made amazing strides in many high-level fundamental visual understanding problems, ranging from language grounding to dense event captioning. However, much of the research has been limited to approaches that either do not take audio corresponding to video into account at all, or those that model the audio-visual correlations in service of sound or sound source localization. In this paper, we present the evidence, that audio signals can carry surprising amount of information when it comes to high-level visual-lingual tasks. Specifically, we focus on the problem of weakly-supervised dense event captioning in videos and show that audio on its own can nearly rival performance of a state-of-the-art visual model and, combined with video, can improve on the state-of-the-art performance. Extensive experiments on the ActivityNet Captions dataset show that our proposed multi-modal approach outperforms state-of-the-art unimodal methods, as well as validate specific feature representation and architecture design choices.
DwNet: Dense warp-based network for pose-guided human video generation
Oct 21, 2019

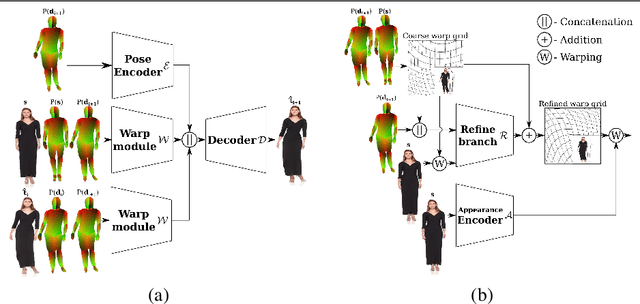

Generation of realistic high-resolution videos of human subjects is a challenging and important task in computer vision. In this paper, we focus on human motion transfer - generation of a video depicting a particular subject, observed in a single image, performing a series of motions exemplified by an auxiliary (driving) video. Our GAN-based architecture, DwNet, leverages dense intermediate pose-guided representation and refinement process to warp the required subject appearance, in the form of the texture, from a source image into a desired pose. Temporal consistency is maintained by further conditioning the decoding process within a GAN on the previously generated frame. In this way a video is generated in an iterative and recurrent fashion. We illustrate the efficacy of our approach by showing state-of-the-art quantitative and qualitative performance on two benchmark datasets: TaiChi and Fashion Modeling. The latter is collected by us and will be made publicly available to the community.
LayoutVAE: Stochastic Scene Layout Generation From a Label Set
Aug 13, 2019
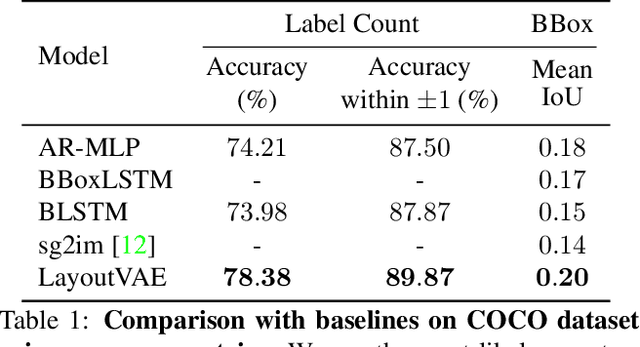
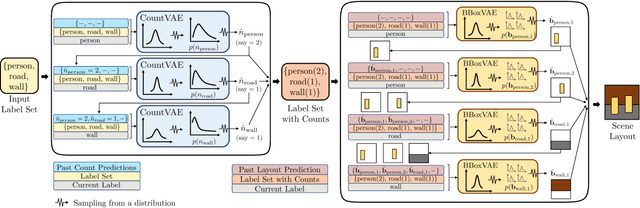
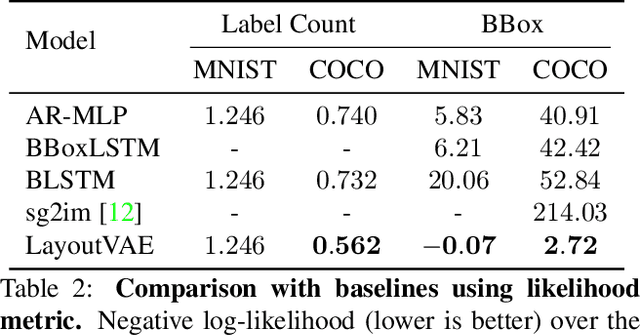
Recently there is an increasing interest in scene generation within the research community. However, models used for generating scene layouts from textual description largely ignore plausible visual variations within the structure dictated by the text. We propose LayoutVAE, a variational autoencoder based framework for generating stochastic scene layouts. LayoutVAE is a versatile modeling framework that allows for generating full image layouts given a label set, or per label layouts for an existing image given a new label. In addition, it is also capable of detecting unusual layouts, potentially providing a way to evaluate layout generation problem. Extensive experiments on MNIST-Layouts and challenging COCO 2017 Panoptic dataset verifies the effectiveness of our proposed framework.