 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Brain Activity with High Spatial and Temporal Resolution using a Naturalistic MEG-fMRI Encoding Model
Oct 10, 2025



Current non-invasive neuroimaging techniques trade off between spatial resolution and temporal resolution. While magnetoencephalography (MEG) can capture rapid neural dynamics and functional magnetic resonance imaging (fMRI) can spatially localize brain activity, a unified picture that preserves both high resolutions remains an unsolved challenge with existing source localization or MEG-fMRI fusion methods, especially for single-trial naturalistic data. We collected whole-head MEG when subjects listened passively to more than seven hours of narrative stories, using the same stimuli in an open fMRI dataset (LeBel et al., 2023). We developed a transformer-based encoding model that combines the MEG and fMRI from these two naturalistic speech comprehension experiments to estimate latent cortical source responses with high spatiotemporal resolution. Our model is trained to predict MEG and fMRI from multiple subjects simultaneously, with a latent layer that represents our estimates of reconstructed cortical sources. Our model predicts MEG better than the common standard of single-modality encoding models, and it also yields source estimates with higher spatial and temporal fidelity than classic minimum-norm solutions in simulation experiments. We validated the estimated latent sources by showing its strong generalizability across unseen subjects and modalities. Estimated activity in our source space predict electrocorticography (ECoG) better than an ECoG-trained encoding model in an entirely new dataset. By integrating the power of large naturalistic experiments, MEG, fMRI, and encoding models, we propose a practical route towards millisecond-and-millimeter brain mapping.
Meta-Learning an In-Context Transformer Model of Human Higher Visual Cortex
May 21, 2025Understanding functional representations within higher visual cortex is a fundamental question in computational neuroscience. While artificial neural networks pretrained on large-scale datasets exhibit striking representational alignment with human neural responses, learning image-computable models of visual cortex relies on individual-level, large-scale fMRI datasets. The necessity for expensive, time-intensive, and often impractical data acquisition limits the generalizability of encoders to new subjects and stimuli. BraInCoRL uses in-context learning to predict voxelwise neural responses from few-shot examples without any additional finetuning for novel subjects and stimuli. We leverage a transformer architecture that can flexibly condition on a variable number of in-context image stimuli, learning an inductive bias over multiple subjects. During training, we explicitly optimize the model for in-context learning. By jointly conditioning on image features and voxel activations, our model learns to directly generate better performing voxelwise models of higher visual cortex. We demonstrate that BraInCoRL consistently outperforms existing voxelwise encoder designs in a low-data regime when evaluated on entirely novel images, while also exhibiting strong test-time scaling behavior. The model also generalizes to an entirely new visual fMRI dataset, which uses different subjects and fMRI data acquisition parameters. Further, BraInCoRL facilitates better interpretability of neural signals in higher visual cortex by attending to semantically relevant stimuli. Finally, we show that our framework enables interpretable mappings from natural language queries to voxel selectivity.
Brain Mapping with Dense Features: Grounding Cortical Semantic Selectivity in Natural Images With Vision Transformers
Oct 07, 2024



Advances in large-scale artificial neural networks have facilitated novel insights into the functional topology of the brain. Here, we leverage this approach to study how semantic categories are organized in the human visual cortex. To overcome the challenge presented by the co-occurrence of multiple categories in natural images, we introduce BrainSAIL (Semantic Attribution and Image Localization), a method for isolating specific neurally-activating visual concepts in images. BrainSAIL exploits semantically consistent, dense spatial features from pre-trained vision models, building upon their demonstrated ability to robustly predict neural activity. This method derives clean, spatially dense embeddings without requiring any additional training, and employs a novel denoising process that leverages the semantic consistency of images under random augmentations. By unifying the space of whole-image embeddings and dense visual features and then applying voxel-wise encoding models to these features, we enable the identification of specific subregions of each image which drive selectivity patterns in different areas of the higher visual cortex. We validate BrainSAIL on cortical regions with known category selectivity, demonstrating its ability to accurately localize and disentangle selectivity to diverse visual concepts. Next, we demonstrate BrainSAIL's ability to characterize high-level visual selectivity to scene properties and low-level visual features such as depth, luminance, and saturation, providing insights into the encoding of complex visual information. Finally, we use BrainSAIL to directly compare the feature selectivity of different brain encoding models across different regions of interest in visual cortex. Our innovative method paves the way for significant advances in mapping and decomposing high-level visual representations in the human brain.
StableSemantics: A Synthetic Language-Vision Dataset of Semantic Representations in Naturalistic Images
Jun 19, 2024



Understanding the semantics of visual scenes is a fundamental challenge in Computer Vision. A key aspect of this challenge is that objects sharing similar semantic meanings or functions can exhibit striking visual differences, making accurate identification and categorization difficult. Recent advancements in text-to-image frameworks have led to models that implicitly capture natural scene statistics. These frameworks account for the visual variability of objects, as well as complex object co-occurrences and sources of noise such as diverse lighting conditions. By leveraging large-scale datasets and cross-attention conditioning, these models generate detailed and contextually rich scene representations. This capability opens new avenues for improving object recognition and scene understanding in varied and challenging environments. Our work presents StableSemantics, a dataset comprising 224 thousand human-curated prompts, processed natural language captions, over 2 million synthetic images, and 10 million attention maps corresponding to individual noun chunks. We explicitly leverage human-generated prompts that correspond to visually interesting stable diffusion generations, provide 10 generations per phrase, and extract cross-attention maps for each image. We explore the semantic distribution of generated images, examine the distribution of objects within images, and benchmark captioning and open vocabulary segmentation methods on our data. To the best of our knowledge, we are the first to release a diffusion dataset with semantic attributions. We expect our proposed dataset to catalyze advances in visual semantic understanding and provide a foundation for developing more sophisticated and effective visual models. Website: https://stablesemantics.github.io/StableSemantics
Divergences between Language Models and Human Brains
Nov 15, 2023



Do machines and humans process language in similar ways? A recent line of research has hinted in the affirmative, demonstrating that human brain signals can be effectively predicted using the internal representations of language models (LMs). This is thought to reflect shared computational principles between LMs and human language processing. However, there are also clear differences in how LMs and humans acquire and use language, even if the final task they are performing is the same. Despite this, there is little work exploring systematic differences between human and machine language processing using brain data. To address this question, we examine the differences between LM representations and the human brain's responses to language, specifically by examining a dataset of Magnetoencephalography (MEG) responses to a written narrative. In doing so we identify three phenomena that, in prior work, LMs have been found to not capture well: emotional understanding, figurative language processing, and physical commonsense. By fine-tuning LMs on datasets related to these phenomena, we observe that fine-tuned LMs show improved alignment with human brain responses across these tasks. Our study implies that the observed divergences between LMs and human brains may stem from LMs' inadequate representation of these specific types of knowledge.
BrainSCUBA: Fine-Grained Natural Language Captions of Visual Cortex Selectivity
Oct 06, 2023Understanding the functional organization of higher visual cortex is a central focus in neuroscience. Past studies have primarily mapped the visual and semantic selectivity of neural populations using hand-selected stimuli, which may potentially bias results towards pre-existing hypotheses of visual cortex functionality. Moving beyond conventional approaches, we introduce a data-driven method that generates natural language descriptions for images predicted to maximally activate individual voxels of interest. Our method -- Semantic Captioning Using Brain Alignments ("BrainSCUBA") -- builds upon the rich embedding space learned by a contrastive vision-language model and utilizes a pre-trained large language model to generate interpretable captions. We validate our method through fine-grained voxel-level captioning across higher-order visual regions. We further perform text-conditioned image synthesis with the captions, and show that our images are semantically coherent and yield high predicted activations. Finally, to demonstrate how our method enables scientific discovery, we perform exploratory investigations on the distribution of "person" representations in the brain, and discover fine-grained semantic selectivity in body-selective areas. Unlike earlier studies that decode text, our method derives voxel-wise captions of semantic selectivity. Our results show that BrainSCUBA is a promising means for understanding functional preferences in the brain, and provides motivation for further hypothesis-driven investigation of visual cortex.
Brain Diffusion for Visual Exploration: Cortical Discovery using Large Scale Generative Models
Jun 05, 2023A long standing goal in neuroscience has been to elucidate the functional organization of the brain. Within higher visual cortex, functional accounts have remained relatively coarse, focusing on regions of interest (ROIs) and taking the form of selectivity for broad categories such as faces, places, bodies, food, or words. Because the identification of such ROIs has typically relied on manually assembled stimulus sets consisting of isolated objects in non-ecological contexts, exploring functional organization without robust a priori hypotheses has been challenging. To overcome these limitations, we introduce a data-driven approach in which we synthesize images predicted to activate a given brain region using paired natural images and fMRI recordings, bypassing the need for category-specific stimuli. Our approach -- Brain Diffusion for Visual Exploration ("BrainDiVE") -- builds on recent generative methods by combining large-scale diffusion models with brain-guided image synthesis. Validating our method, we demonstrate the ability to synthesize preferred images with appropriate semantic specificity for well-characterized category-selective ROIs. We then show that BrainDiVE can characterize differences between ROIs selective for the same high-level category. Finally we identify novel functional subdivisions within these ROIs, validated with behavioral data. These results advance our understanding of the fine-grained functional organization of human visual cortex, and provide well-specified constraints for further examination of cortical organization using hypothesis-driven methods.
Same Cause; Different Effects in the Brain
Feb 21, 2022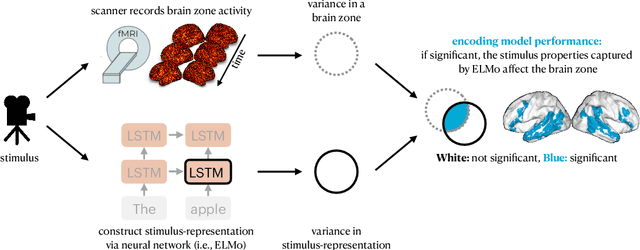
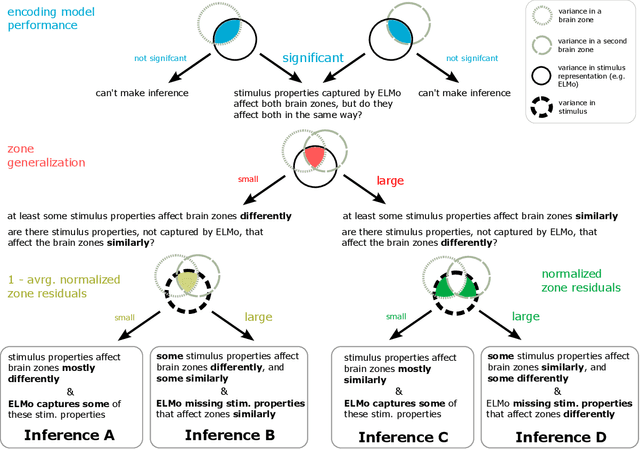
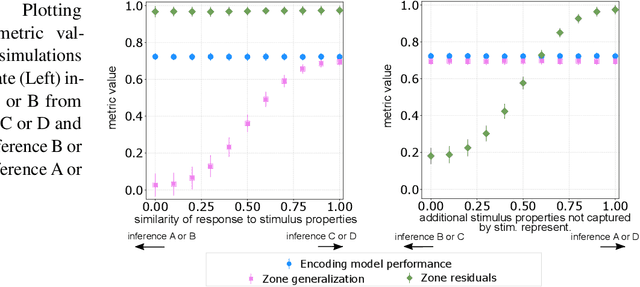
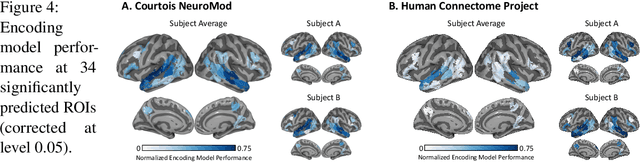
To study information processing in the brain, neuroscientists manipulate experimental stimuli while recording participant brain activity. They can then use encoding models to find out which brain "zone" (e.g. which region of interest, volume pixel or electrophysiology sensor) is predicted from the stimulus properties. Given the assumptions underlying this setup, when stimulus properties are predictive of the activity in a zone, these properties are understood to cause activity in that zone. In recent years, researchers have used neural networks to construct representations that capture the diverse properties of complex stimuli, such as natural language or natural images. Encoding models built using these high-dimensional representations are often able to significantly predict the activity in large swathes of cortex, suggesting that the activity in all these brain zones is caused by stimulus properties captured in the representation. It is then natural to ask: "Is the activity in these different brain zones caused by the stimulus properties in the same way?" In neuroscientific terms, this corresponds to asking if these different zones process the stimulus properties in the same way. Here, we propose a new framework that enables researchers to ask if the properties of a stimulus affect two brain zones in the same way. We use simulated data and two real fMRI datasets with complex naturalistic stimuli to show that our framework enables us to make such inferences. Our inferences are strikingly consistent between the two datasets, indicating that the proposed framework is a promising new tool for neuroscientists to understand how information is processed in the brain.
Prospective Learning: Back to the Future
Jan 19, 2022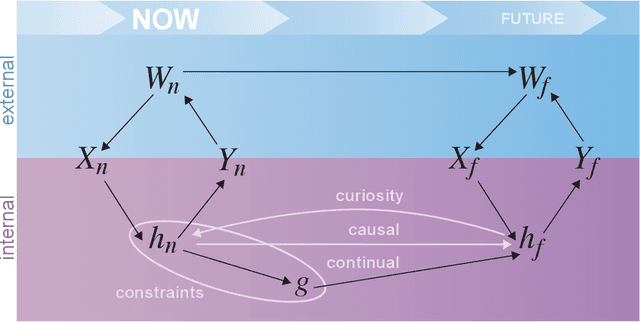

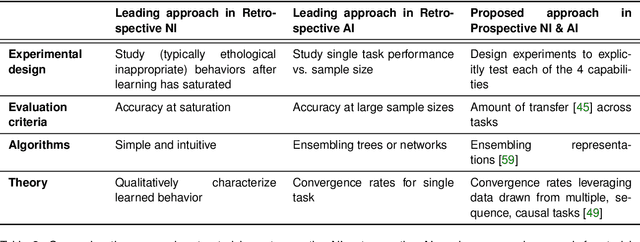
Research on both natural intelligence (NI) and artificial intelligence (AI) generally assumes that the future resembles the past: intelligent agents or systems (what we call 'intelligence') observe and act on the world, then use this experience to act on future experiences of the same kind. We call this 'retrospective learning'. For example, an intelligence may see a set of pictures of objects, along with their names, and learn to name them. A retrospective learning intelligence would merely be able to name more pictures of the same objects. We argue that this is not what true intelligence is about. In many real world problems, both NIs and AIs will have to learn for an uncertain future. Both must update their internal models to be useful for future tasks, such as naming fundamentally new objects and using these objects effectively in a new context or to achieve previously unencountered goals. This ability to learn for the future we call 'prospective learning'. We articulate four relevant factors that jointly define prospective learning. Continual learning enables intelligences to remember those aspects of the past which it believes will be most useful in the future. Prospective constraints (including biases and priors) facilitate the intelligence finding general solutions that will be applicable to future problems. Curiosity motivates taking actions that inform future decision making, including in previously unmet situations. Causal estimation enables learning the structure of relations that guide choosing actions for specific outcomes, even when the specific action-outcome contingencies have never been observed before. We argue that a paradigm shift from retrospective to prospective learning will enable the communities that study intelligence to unite and overcome existing bottlenecks to more effectively explain, augment, and engineer intelligences.
Behavior measures are predicted by how information is encoded in an individual's brain
Dec 11, 2021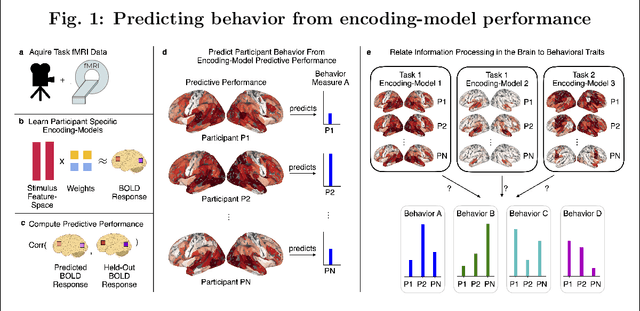
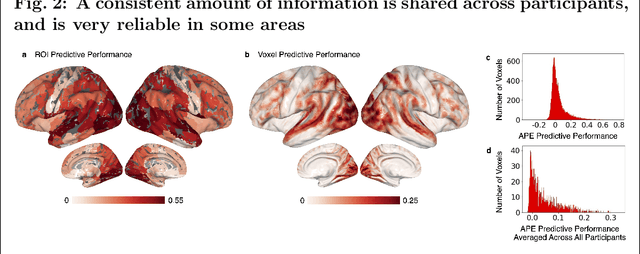
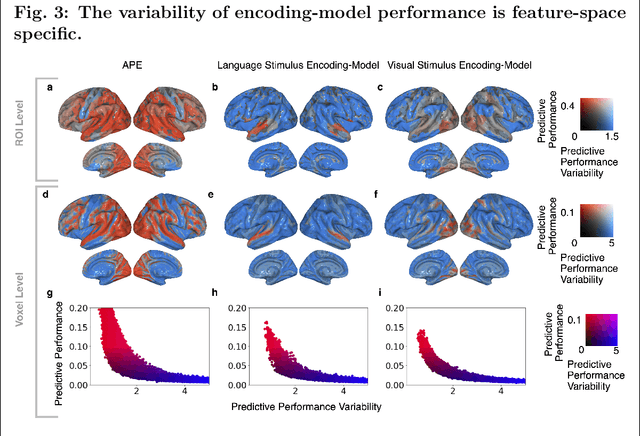
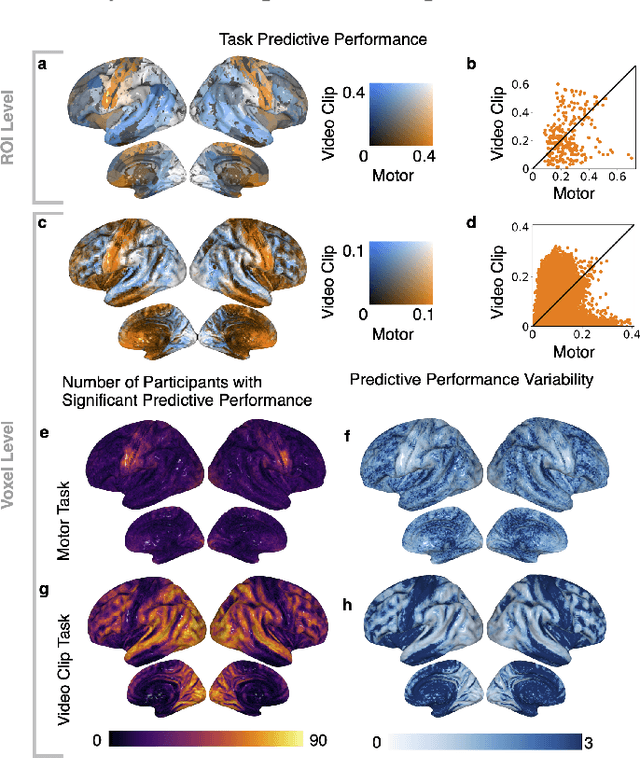
Similar to how differences in the proficiency of the cardiovascular and musculoskeletal system predict an individual's athletic ability, differences in how the same brain region encodes information across individuals may explain their behavior. However, when studying how the brain encodes information, researchers choose different neuroimaging tasks (e.g., language or motor tasks), which can rely on processing different types of information and can modulate different brain regions. We hypothesize that individual differences in how information is encoded in the brain are task-specific and predict different behavior measures. We propose a framework using encoding-models to identify individual differences in brain encoding and test if these differences can predict behavior. We evaluate our framework using task functional magnetic resonance imaging data. Our results indicate that individual differences revealed by encoding-models are a powerful tool for predicting behavior, and that researchers should optimize their choice of task and encoding-model for their behavior of interest.