 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressive Sensing via Convolutional Factor Analysis
Jan 11, 2017

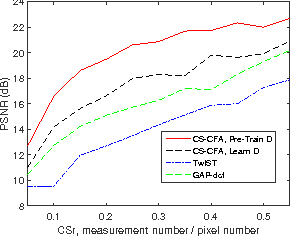

We solve the compressive sensing problem via convolutional factor analysis, where the convolutional dictionaries are learned {\em in situ} from the compressed measurements. An alternating direction method of multipliers (ADMM) paradigm for compressive sensing inversion based on convolutional factor analysis is developed. The proposed algorithm provides reconstructed images as well as features, which can be directly used for recognition ($e.g.$, classification) tasks. When a deep (multilayer) model is constructed, a stochastic unpooling process is employed to build a generative model. During reconstruction and testing, we project the upper layer dictionary to the data level and only a single layer deconvolution is required. We demonstrate that using $\sim30\%$ (relative to pixel numbers) compressed measurements, the proposed model achieves the classification accuracy comparable to the original data on MNIST. We also observe that when the compressed measurements are very limited ($e.g.$, $<10\%$), the upper layer dictionary can provide better reconstruction results than the bottom layer.
Nonlinear Statistical Learning with Truncated Gaussian Graphical Models
Nov 20, 2016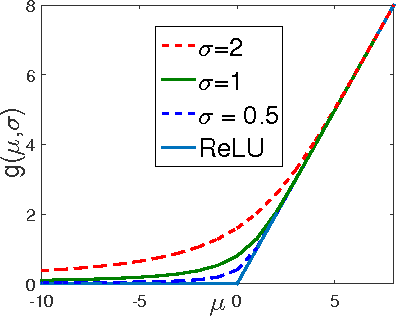
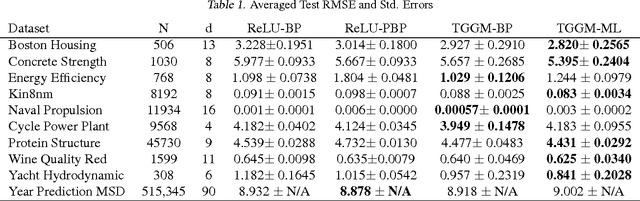
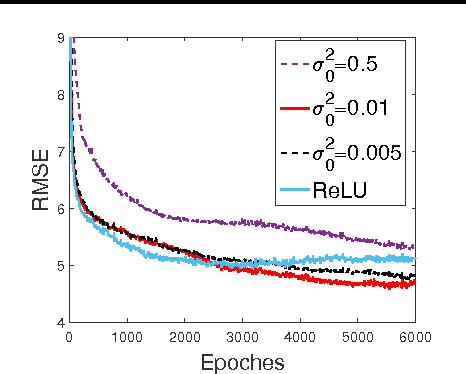
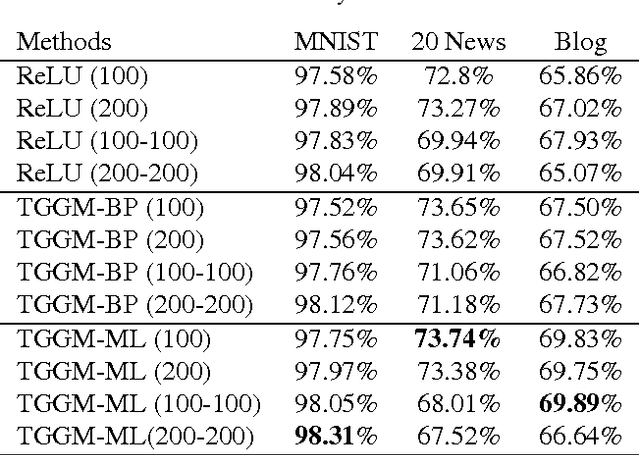
We introduce the truncated Gaussian graphical model (TGGM) as a novel framework for designing statistical models for nonlinear learning. A TGGM is a Gaussian graphical model (GGM) with a subset of variables truncated to be nonnegative. The truncated variables are assumed latent and integrated out to induce a marginal model. We show that the variables in the marginal model are non-Gaussian distributed and their expected relations are nonlinear. We use expectation-maximization to break the inference of the nonlinear model into a sequence of TGGM inference problems, each of which is efficiently solved by using the properties and numerical methods of multivariate Gaussian distributions. We use the TGGM to design models for nonlinear regression and classification, with the performances of these models demonstrated on extensive benchmark datasets and compared to state-of-the-art competing results.
Unsupervised Learning with Truncated Gaussian Graphical Models
Nov 20, 2016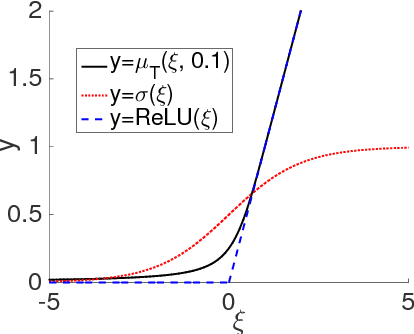

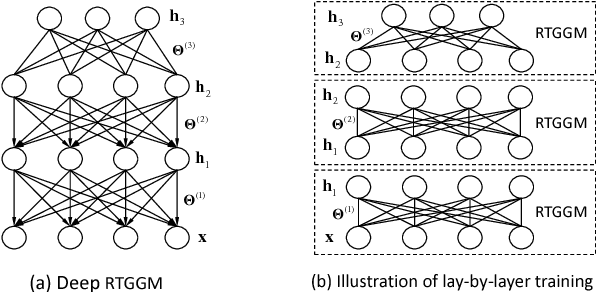

Gaussian graphical models (GGMs) are widely used for statistical modeling, because of ease of inference and the ubiquitous use of the normal distribution in practical approximations. However, they are also known for their limited modeling abilities, due to the Gaussian assumption. In this paper, we introduce a novel variant of GGMs, which relaxes the Gaussian restriction and yet admits efficient inference. Specifically, we impose a bipartite structure on the GGM and govern the hidden variables by truncated normal distributions. The nonlinearity of the model is revealed by its connection to rectified linear unit (ReLU) neural networks. Meanwhile, thanks to the bipartite structure and appealing properties of truncated normals, we are able to train the models efficiently using contrastive divergence. We consider three output constructs, accounting for real-valued, binary and count data. We further extend the model to deep constructions and show that deep models can be used for unsupervised pre-training of rectifier neural networks. Extensive experimental results are provided to validate the proposed models and demonstrate their superiority over competing models.
Earliness-Aware Deep Convolutional Networks for Early Time Series Classification
Nov 14, 2016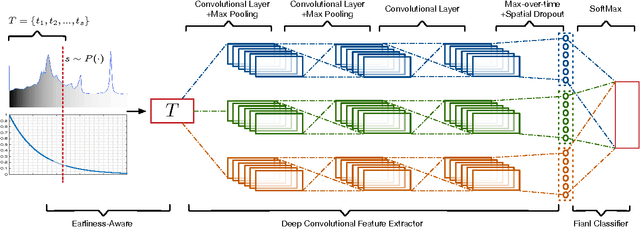
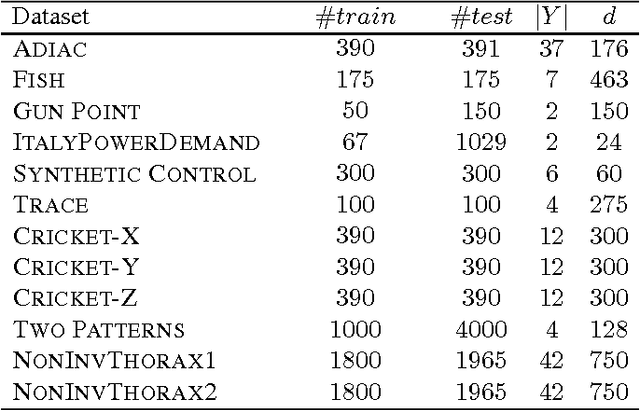
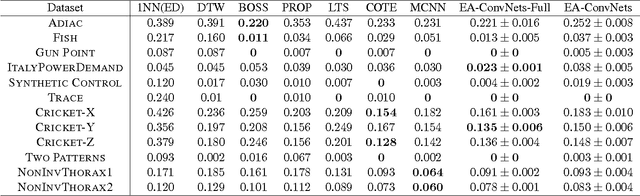
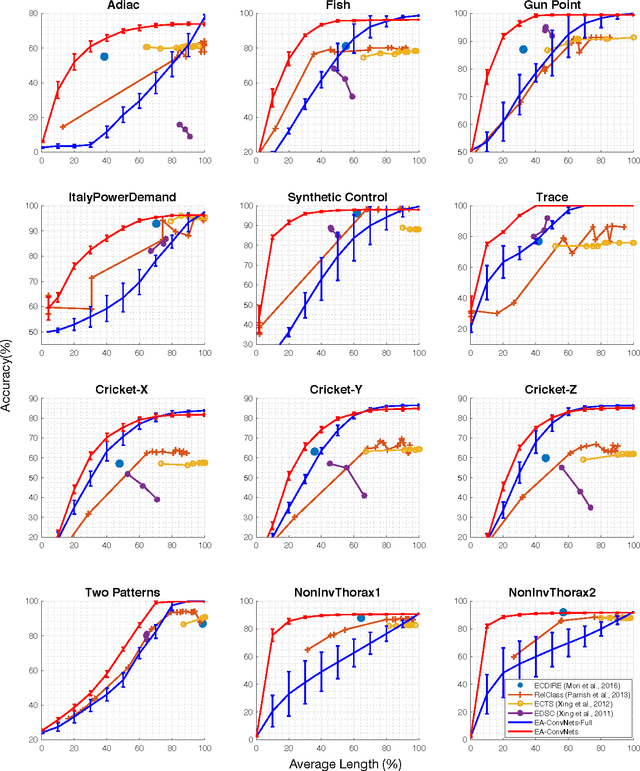
We present Earliness-Aware Deep Convolutional Networks (EA-ConvNets), an end-to-end deep learning framework, for early classification of time series data. Unlike most existing methods for early classification of time series data, that are designed to solve this problem under the assumption of the availability of a good set of pre-defined (often hand-crafted) features, our framework can jointly perform feature learning (by learning a deep hierarchy of \emph{shapelets} capturing the salient characteristics in each time series), along with a dynamic truncation model to help our deep feature learning architecture focus on the early parts of each time series. Consequently, our framework is able to make highly reliable early predictions, outperforming various state-of-the-art methods for early time series classification, while also being competitive when compared to the state-of-the-art time series classification algorithms that work with \emph{fully observed} time series data. To the best of our knowledge, the proposed framework is the first to perform data-driven (deep) feature learning in the context of early classification of time series data. We perform a comprehensive set of experiments, on several benchmark data sets, which demonstrate that our method yields significantly better predictions than various state-of-the-art methods designed for early time series classification. In addition to obtaining high accuracies, our experiments also show that the learned deep shapelets based features are also highly interpretable and can help gain better understanding of the underlying characteristics of time series data.
On the Convergence of Stochastic Gradient MCMC Algorithms with High-Order Integrators
Oct 21, 2016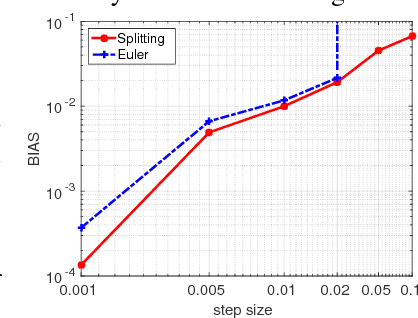
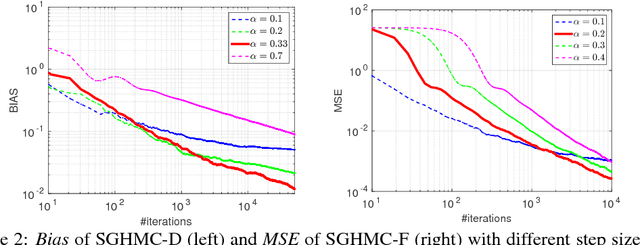
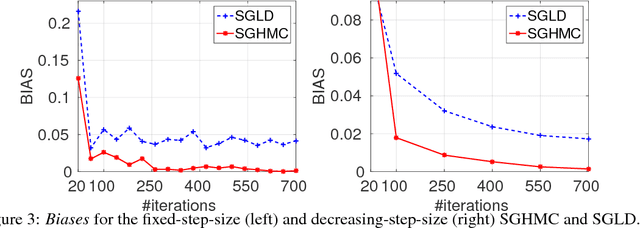
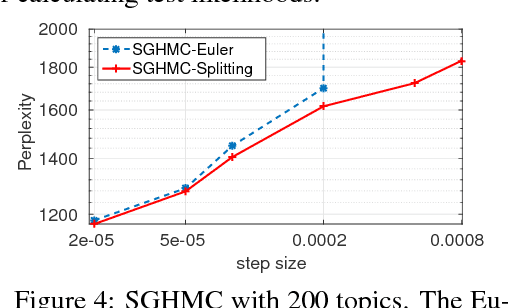
Recent advances in Bayesian learning with large-scale data have witnessed emergence of stochastic gradient MCMC algorithms (SG-MCMC), such as stochastic gradient Langevin dynamics (SGLD), stochastic gradient Hamiltonian MCMC (SGHMC), and the stochastic gradient thermostat. While finite-time convergence properties of the SGLD with a 1st-order Euler integrator have recently been studied, corresponding theory for general SG-MCMCs has not been explored. In this paper we consider general SG-MCMCs with high-order integrators, and develop theory to analyze finite-time convergence properties and their asymptotic invariant measures. Our theoretical results show faster convergence rates and more accurate invariant measures for SG-MCMCs with higher-order integrators. For example, with the proposed efficient 2nd-order symmetric splitting integrator, the {\em mean square error} (MSE) of the posterior average for the SGHMC achieves an optimal convergence rate of $L^{-4/5}$ at $L$ iterations, compared to $L^{-2/3}$ for the SGHMC and SGLD with 1st-order Euler integrators. Furthermore, convergence results of decreasing-step-size SG-MCMCs are also developed, with the same convergence rates as their fixed-step-size counterparts for a specific decreasing sequence. Experiments on both synthetic and real datasets verify our theory, and show advantages of the proposed method in two large-scale real applications.
Stochastic Gradient MCMC with Stale Gradients
Oct 21, 2016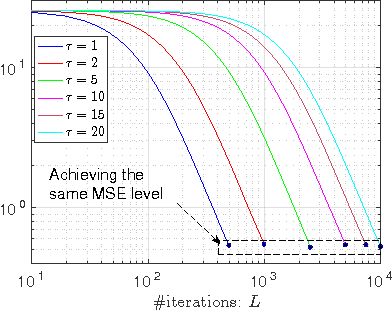
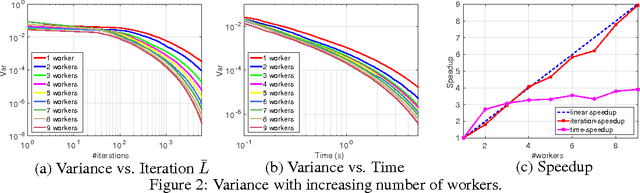
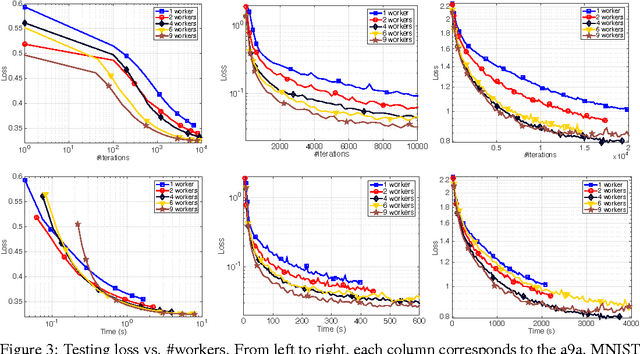
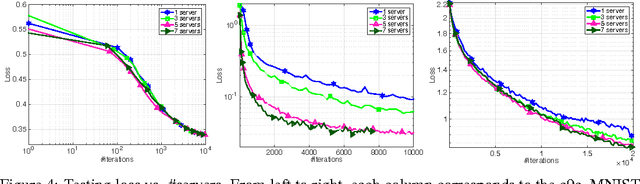
Stochastic gradient MCMC (SG-MCMC) has played an important role in large-scale Bayesian learning, with well-developed theoretical convergence properties. In such applications of SG-MCMC, it is becoming increasingly popular to employ distributed systems, where stochastic gradients are computed based on some outdated parameters, yielding what are termed stale gradients. While stale gradients could be directly used in SG-MCMC, their impact on convergence properties has not been well studied. In this paper we develop theory to show that while the bias and MSE of an SG-MCMC algorithm depend on the staleness of stochastic gradients, its estimation variance (relative to the expected estimate, based on a prescribed number of samples) is independent of it. In a simple Bayesian distributed system with SG-MCMC, where stale gradients are computed asynchronously by a set of workers, our theory indicates a linear speedup on the decrease of estimation variance w.r.t. the number of workers. Experiments on synthetic data and deep neural networks validate our theory, demonstrating the effectiveness and scalability of SG-MCMC with stale gradients.
Variational Autoencoder for Deep Learning of Images, Labels and Captions
Sep 28, 2016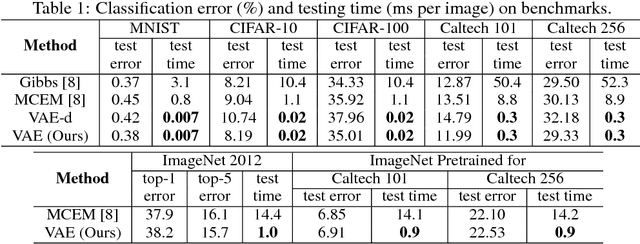
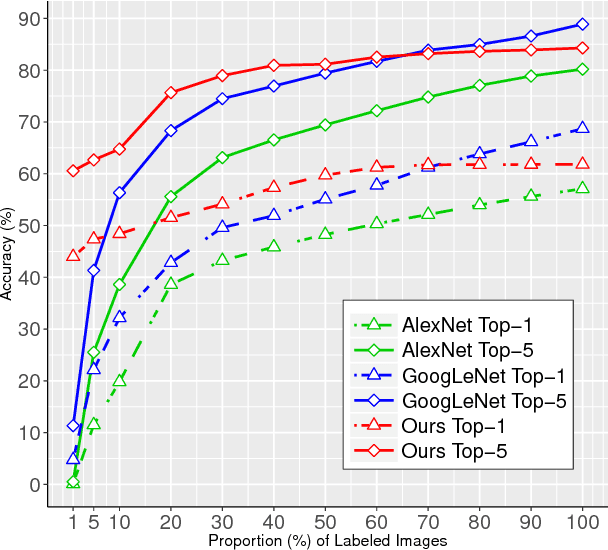

A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the latent DGDN features/code. The latent code is also linked to generative models for labels (Bayesian support vector machine) or captions (recurrent neural network). When predicting a label/caption for a new image at test, averaging is performed across the distribution of latent codes; this is computationally efficient as a consequence of the learned CNN-based encoder. Since the framework is capable of modeling the image in the presence/absence of associated labels/captions, a new semi-supervised setting is manifested for CNN learning with images; the framework even allows unsupervised CNN learning, based on images alone.
Bridging the Gap between Stochastic Gradient MCMC and Stochastic Optimization
Aug 05, 2016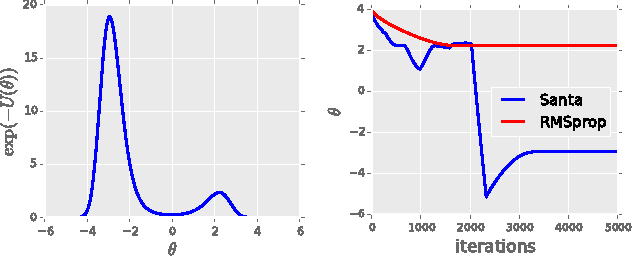
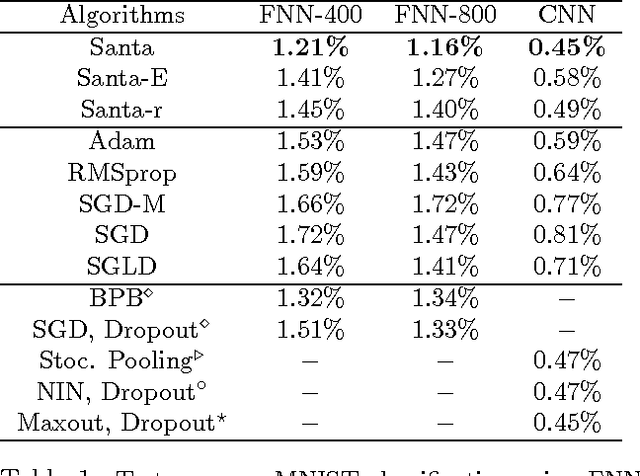
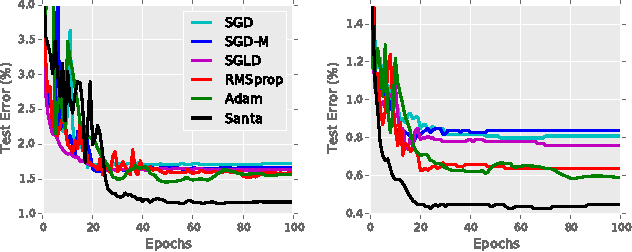
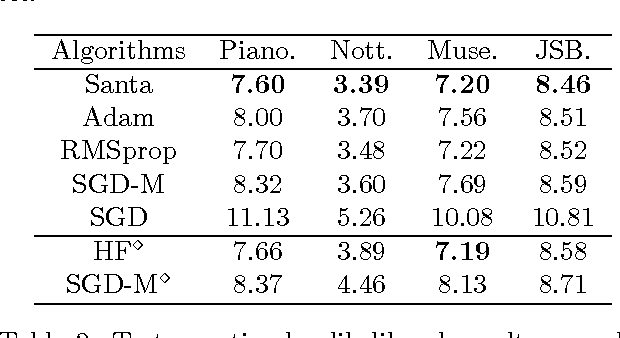
Stochastic gradient Markov chain Monte Carlo (SG-MCMC) methods are Bayesian analogs to popular stochastic optimization methods; however, this connection is not well studied. We explore this relationship by applying simulated annealing to an SGMCMC algorithm. Furthermore, we extend recent SG-MCMC methods with two key components: i) adaptive preconditioners (as in ADAgrad or RMSprop), and ii) adaptive element-wise momentum weights. The zero-temperature limit gives a novel stochastic optimization method with adaptive element-wise momentum weights, while conventional optimization methods only have a shared, static momentum weight. Under certain assumptions, our theoretical analysis suggests the proposed simulated annealing approach converges close to the global optima. Experiments on several deep neural network models show state-of-the-art results compared to related stochastic optimization algorithms.
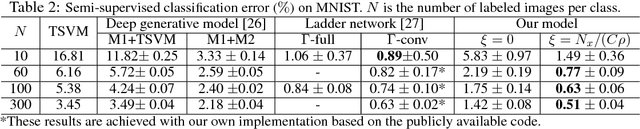
Factored Temporal Sigmoid Belief Networks for Sequence Learning
May 22, 2016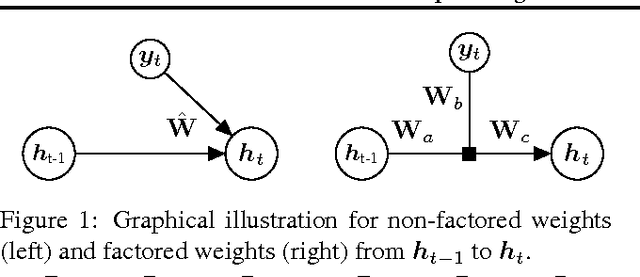
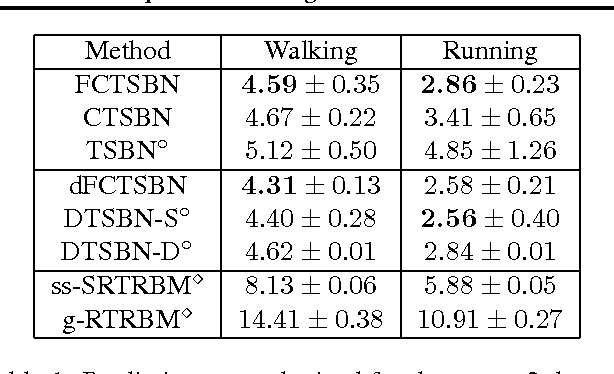
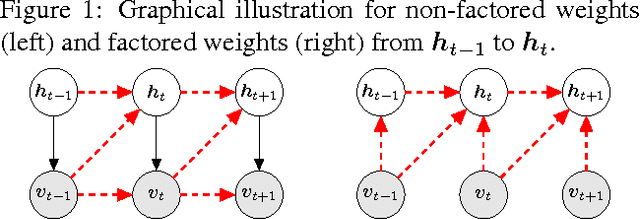
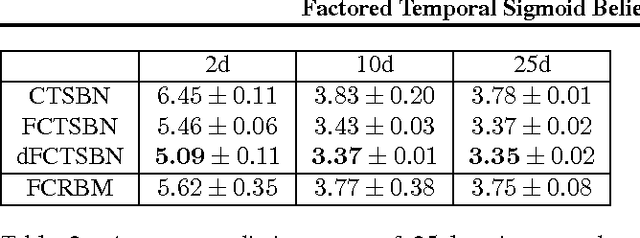
Deep conditional generative models are developed to simultaneously learn the temporal dependencies of multiple sequences. The model is designed by introducing a three-way weight tensor to capture the multiplicative interactions between side information and sequences. The proposed model builds on the Temporal Sigmoid Belief Network (TSBN), a sequential stack of Sigmoid Belief Networks (SBNs). The transition matrices are further factored to reduce the number of parameters and improve generalization. When side information is not available, a general framework for semi-supervised learning based on the proposed model is constituted, allowing robust sequence classification. Experimental results show that the proposed approach achieves state-of-the-art predictive and classification performance on sequential data, and has the capacity to synthesize sequences, with controlled style transitioning and blending.
Variational Gaussian Copula Inference
May 18, 2016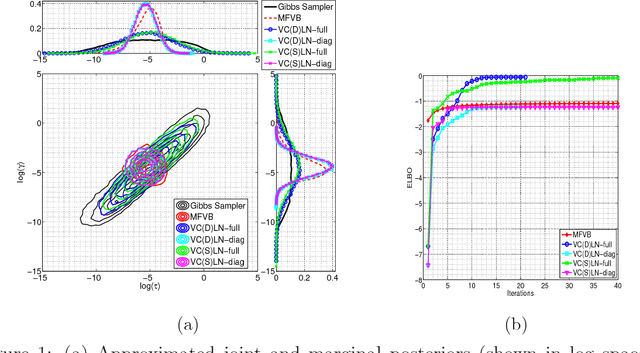
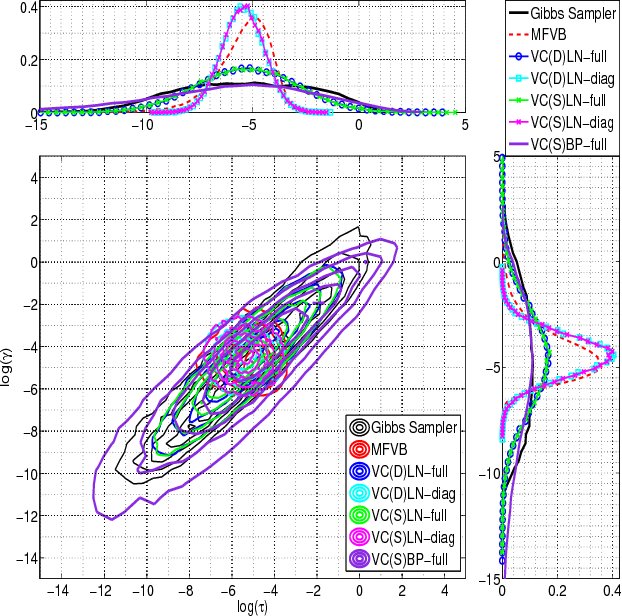
We utilize copulas to constitute a unified framework for constructing and optimizing variational proposals in hierarchical Bayesian models. For models with continuous and non-Gaussian hidden variables, we propose a semiparametric and automated variational Gaussian copula approach, in which the parametric Gaussian copula family is able to preserve multivariate posterior dependence, and the nonparametric transformations based on Bernstein polynomials provide ample flexibility in characterizing the univariate marginal posteriors.