 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Convergence Analysis for A Class of Practical Variance-Reduction Stochastic Gradient MCMC
Paper and Code
Sep 04, 2017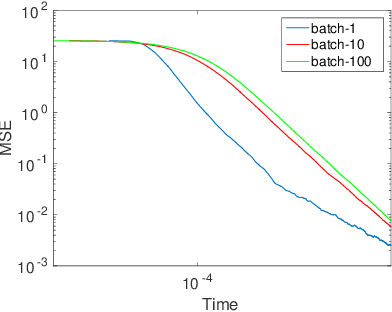
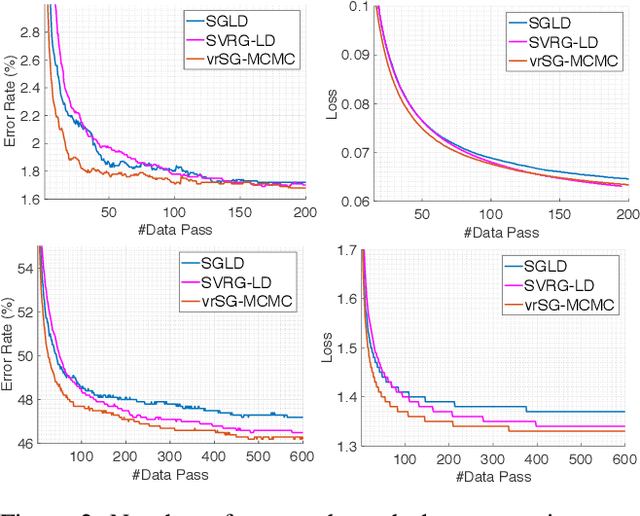
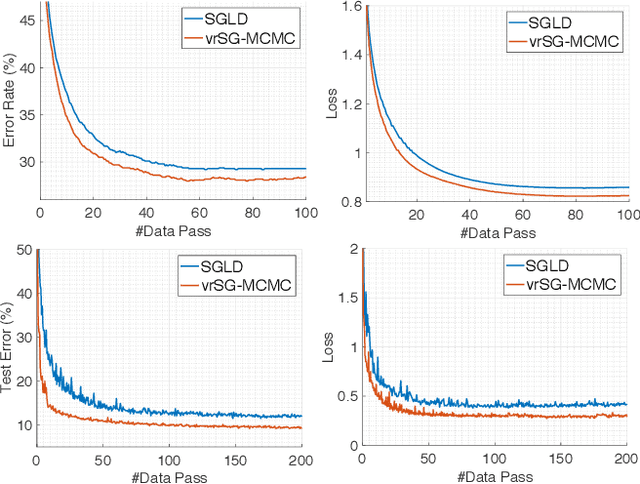
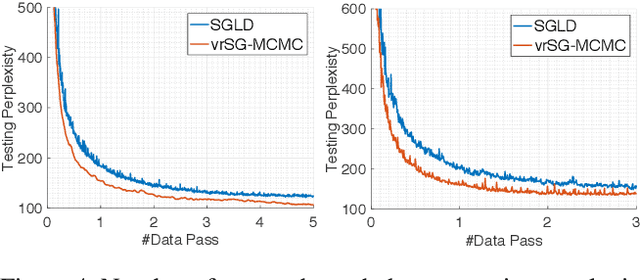
Stochastic gradient Markov Chain Monte Carlo (SG-MCMC) has been developed as a flexible family of scalable Bayesian sampling algorithms. However, there has been little theoretical analysis of the impact of minibatch size to the algorithm's convergence rate. In this paper, we prove that under a limited computational budget/time, a larger minibatch size leads to a faster decrease of the mean squared error bound (thus the fastest one corresponds to using full gradients), which motivates the necessity of variance reduction in SG-MCMC. Consequently, by borrowing ideas from stochastic optimization, we propose a practical variance-reduction technique for SG-MCMC, that is efficient in both computation and storage. We develop theory to prove that our algorithm induces a faster convergence rate than standard SG-MCMC. A number of large-scale experiments, ranging from Bayesian learning of logistic regression to deep neural networks, validate the theory and demonstrate the superiority of the proposed variance-reduction SG-MCMC framework.