 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparating Self-Expression and Visual Content in Hashtag Supervision
Nov 27, 2017



The variety, abundance, and structured nature of hashtags make them an interesting data source for training vision models. For instance, hashtags have the potential to significantly reduce the problem of manual supervision and annotation when learning vision models for a large number of concepts. However, a key challenge when learning from hashtags is that they are inherently subjective because they are provided by users as a form of self-expression. As a consequence, hashtags may have synonyms (different hashtags referring to the same visual content) and may be ambiguous (the same hashtag referring to different visual content). These challenges limit the effectiveness of approaches that simply treat hashtags as image-label pairs. This paper presents an approach that extends upon modeling simple image-label pairs by modeling the joint distribution of images, hashtags, and users. We demonstrate the efficacy of such approaches in image tagging and retrieval experiments, and show how the joint model can be used to perform user-conditional retrieval and tagging.
Learning Visual N-Grams from Web Data
Aug 06, 2017
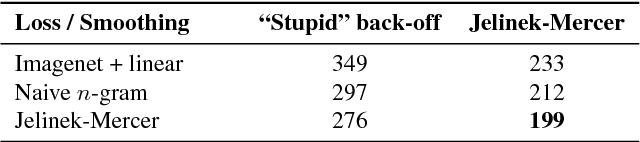


Real-world image recognition systems need to recognize tens of thousands of classes that constitute a plethora of visual concepts. The traditional approach of annotating thousands of images per class for training is infeasible in such a scenario, prompting the use of webly supervised data. This paper explores the training of image-recognition systems on large numbers of images and associated user comments. In particular, we develop visual n-gram models that can predict arbitrary phrases that are relevant to the content of an image. Our visual n-gram models are feed-forward convolutional networks trained using new loss functions that are inspired by n-gram models commonly used in language modeling. We demonstrate the merits of our models in phrase prediction, phrase-based image retrieval, relating images and captions, and zero-shot transfer.
Memory-Efficient Implementation of DenseNets
Jul 21, 2017
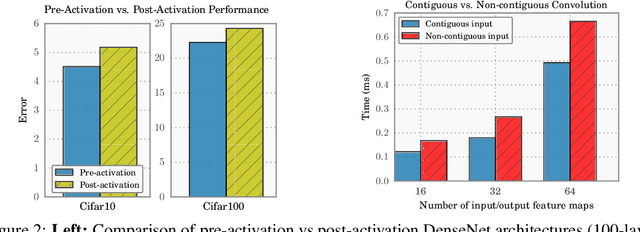
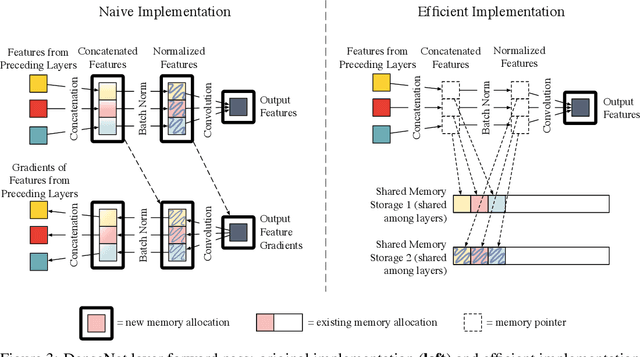
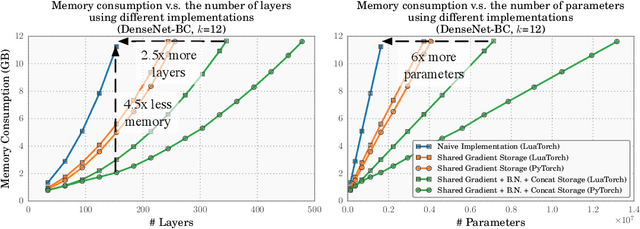
The DenseNet architecture is highly computationally efficient as a result of feature reuse. However, a naive DenseNet implementation can require a significant amount of GPU memory: If not properly managed, pre-activation batch normalization and contiguous convolution operations can produce feature maps that grow quadratically with network depth. In this technical report, we introduce strategies to reduce the memory consumption of DenseNets during training. By strategically using shared memory allocations, we reduce the memory cost for storing feature maps from quadratic to linear. Without the GPU memory bottleneck, it is now possible to train extremely deep DenseNets. Networks with 14M parameters can be trained on a single GPU, up from 4M. A 264-layer DenseNet (73M parameters), which previously would have been infeasible to train, can now be trained on a single workstation with 8 NVIDIA Tesla M40 GPUs. On the ImageNet ILSVRC classification dataset, this large DenseNet obtains a state-of-the-art single-crop top-1 error of 20.26%.
Submanifold Sparse Convolutional Networks
Jun 05, 2017
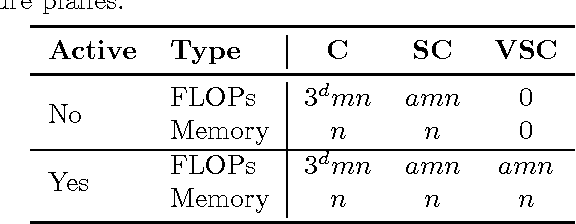
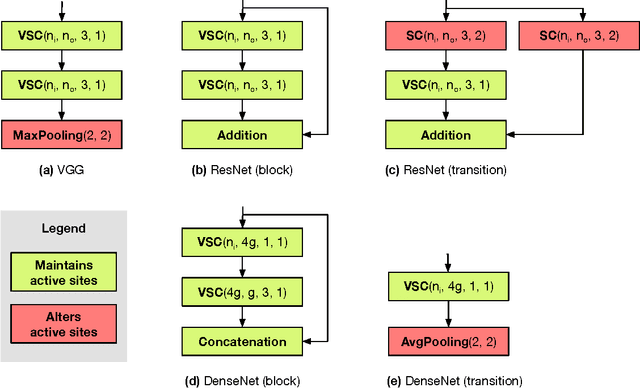
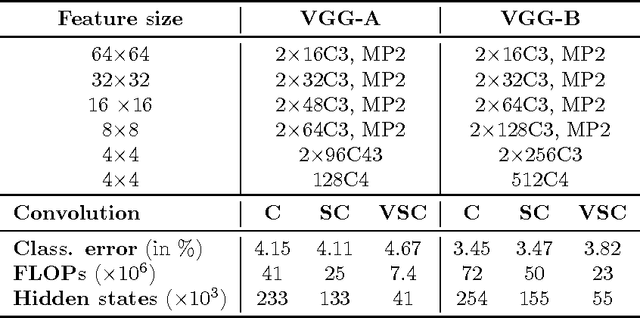
Convolutional network are the de-facto standard for analysing spatio-temporal data such as images, videos, 3D shapes, etc. Whilst some of this data is naturally dense (for instance, photos), many other data sources are inherently sparse. Examples include pen-strokes forming on a piece of paper, or (colored) 3D point clouds that were obtained using a LiDAR scanner or RGB-D camera. Standard "dense" implementations of convolutional networks are very inefficient when applied on such sparse data. We introduce a sparse convolutional operation tailored to processing sparse data that differs from prior work on sparse convolutional networks in that it operates strictly on submanifolds, rather than "dilating" the observation with every layer in the network. Our empirical analysis of the resulting submanifold sparse convolutional networks shows that they perform on par with state-of-the-art methods whilst requiring substantially less computation.
Inferring and Executing Programs for Visual Reasoning
May 10, 2017
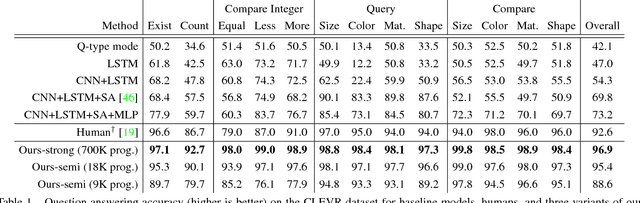
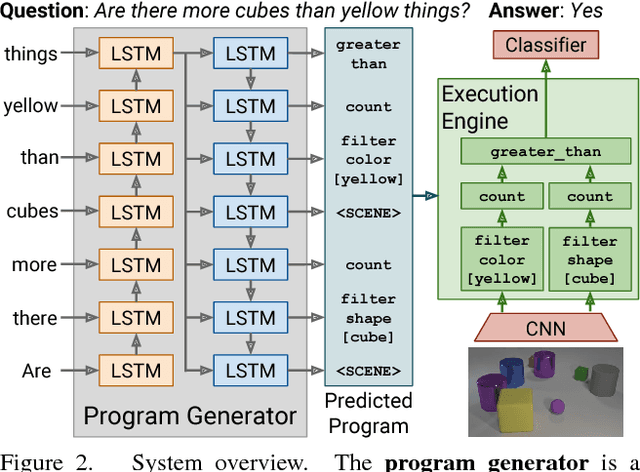
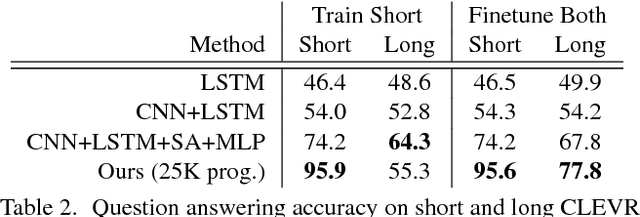
Existing methods for visual reasoning attempt to directly map inputs to outputs using black-box architectures without explicitly modeling the underlying reasoning processes. As a result, these black-box models often learn to exploit biases in the data rather than learning to perform visual reasoning. Inspired by module networks, this paper proposes a model for visual reasoning that consists of a program generator that constructs an explicit representation of the reasoning process to be performed, and an execution engine that executes the resulting program to produce an answer. Both the program generator and the execution engine are implemented by neural networks, and are trained using a combination of backpropagation and REINFORCE. Using the CLEVR benchmark for visual reasoning, we show that our model significantly outperforms strong baselines and generalizes better in a variety of settings.
CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning
Dec 20, 2016
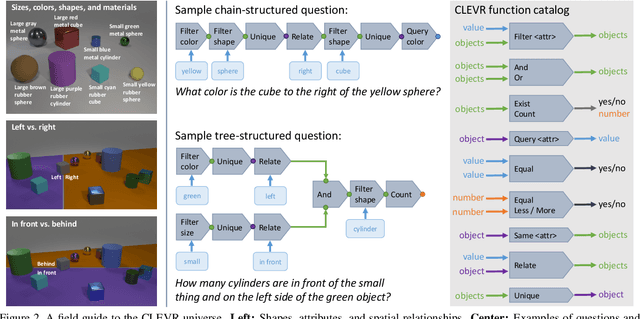
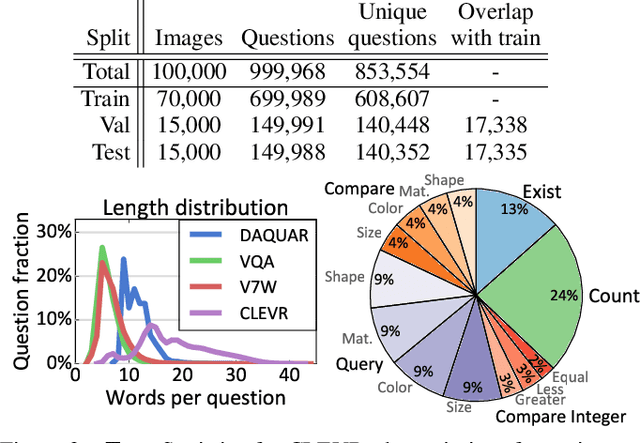
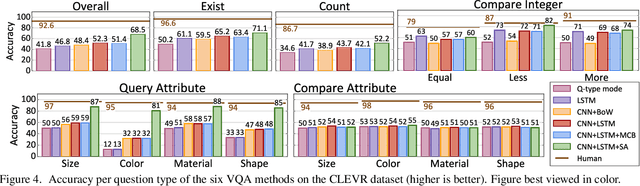
When building artificial intelligence systems that can reason and answer questions about visual data, we need diagnostic tests to analyze our progress and discover shortcomings. Existing benchmarks for visual question answering can help, but have strong biases that models can exploit to correctly answer questions without reasoning. They also conflate multiple sources of error, making it hard to pinpoint model weaknesses. We present a diagnostic dataset that tests a range of visual reasoning abilities. It contains minimal biases and has detailed annotations describing the kind of reasoning each question requires. We use this dataset to analyze a variety of modern visual reasoning systems, providing novel insights into their abilities and limitations.
Revisiting Visual Question Answering Baselines
Nov 22, 2016
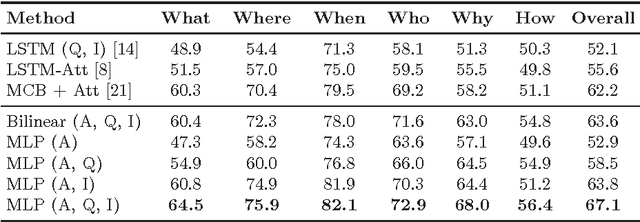
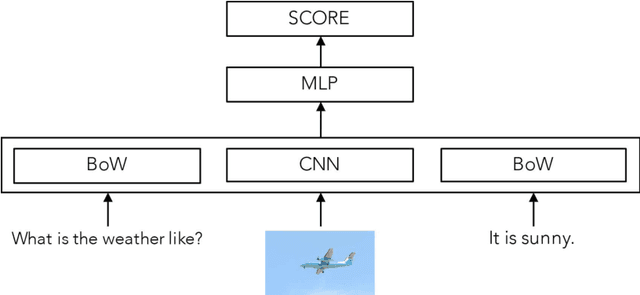
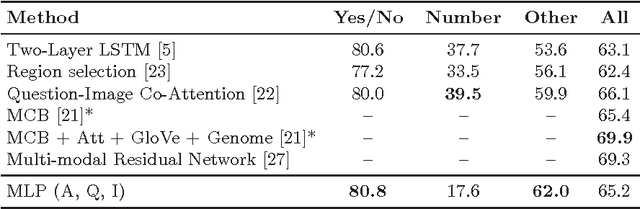
Visual question answering (VQA) is an interesting learning setting for evaluating the abilities and shortcomings of current systems for image understanding. Many of the recently proposed VQA systems include attention or memory mechanisms designed to support "reasoning". For multiple-choice VQA, nearly all of these systems train a multi-class classifier on image and question features to predict an answer. This paper questions the value of these common practices and develops a simple alternative model based on binary classification. Instead of treating answers as competing choices, our model receives the answer as input and predicts whether or not an image-question-answer triplet is correct. We evaluate our model on the Visual7W Telling and the VQA Real Multiple Choice tasks, and find that even simple versions of our model perform competitively. Our best model achieves state-of-the-art performance on the Visual7W Telling task and compares surprisingly well with the most complex systems proposed for the VQA Real Multiple Choice task. We explore variants of the model and study its transferability between both datasets. We also present an error analysis of our model that suggests a key problem of current VQA systems lies in the lack of visual grounding of concepts that occur in the questions and answers. Overall, our results suggest that the performance of current VQA systems is not significantly better than that of systems designed to exploit dataset biases.
Approximated and User Steerable tSNE for Progressive Visual Analytics
Jun 16, 2016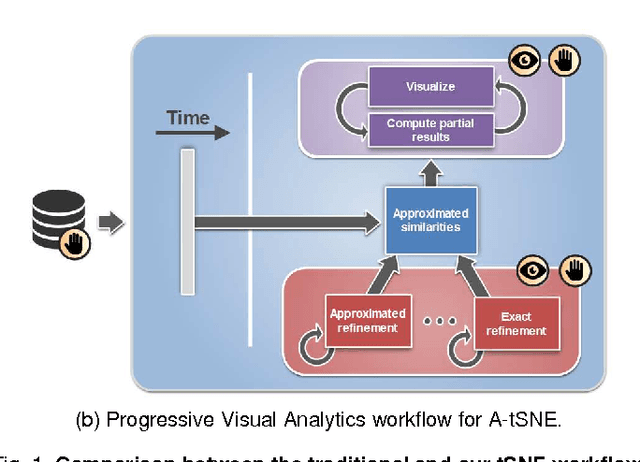
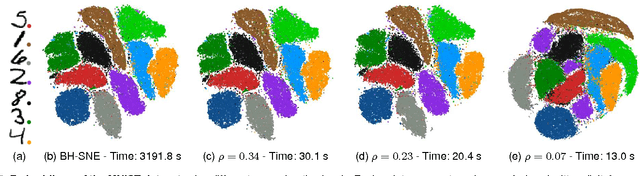
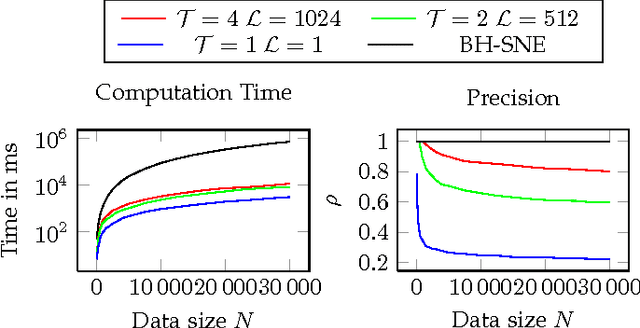
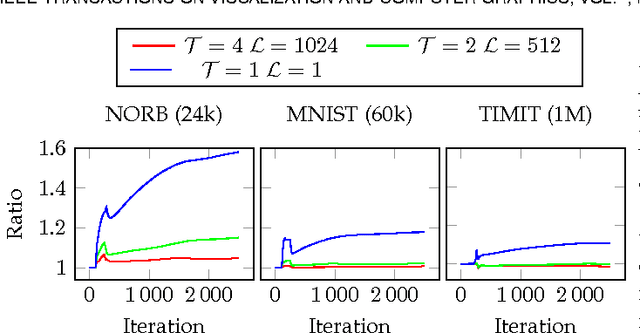
Progressive Visual Analytics aims at improving the interactivity in existing analytics techniques by means of visualization as well as interaction with intermediate results. One key method for data analysis is dimensionality reduction, for example, to produce 2D embeddings that can be visualized and analyzed efficiently. t-Distributed Stochastic Neighbor Embedding (tSNE) is a well-suited technique for the visualization of several high-dimensional data. tSNE can create meaningful intermediate results but suffers from a slow initialization that constrains its application in Progressive Visual Analytics. We introduce a controllable tSNE approximation (A-tSNE), which trades off speed and accuracy, to enable interactive data exploration. We offer real-time visualization techniques, including a density-based solution and a Magic Lens to inspect the degree of approximation. With this feedback, the user can decide on local refinements and steer the approximation level during the analysis. We demonstrate our technique with several datasets, in a real-world research scenario and for the real-time analysis of high-dimensional streams to illustrate its effectiveness for interactive data analysis.
Persistent self-supervised learning principle: from stereo to monocular vision for obstacle avoidance
Mar 25, 2016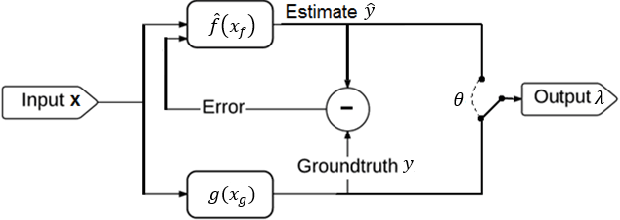
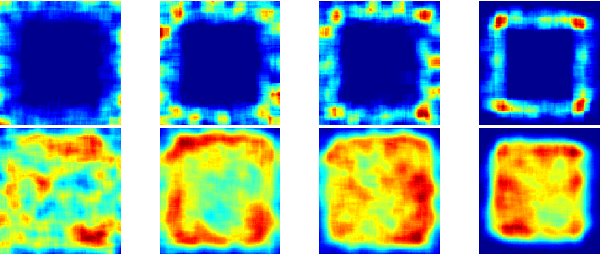

Self-Supervised Learning (SSL) is a reliable learning mechanism in which a robot uses an original, trusted sensor cue for training to recognize an additional, complementary sensor cue. We study for the first time in SSL how a robot's learning behavior should be organized, so that the robot can keep performing its task in the case that the original cue becomes unavailable. We study this persistent form of SSL in the context of a flying robot that has to avoid obstacles based on distance estimates from the visual cue of stereo vision. Over time it will learn to also estimate distances based on monocular appearance cues. A strategy is introduced that has the robot switch from stereo vision based flight to monocular flight, with stereo vision purely used as 'training wheels' to avoid imminent collisions. This strategy is shown to be an effective approach to the 'feedback-induced data bias' problem as also experienced in learning from demonstration. Both simulations and real-world experiments with a stereo vision equipped AR drone 2.0 show the feasibility of this approach, with the robot successfully using monocular vision to avoid obstacles in a 5 x 5 room. The experiments show the potential of persistent SSL as a robust learning approach to enhance the capabilities of robots. Moreover, the abundant training data coming from the own sensors allows to gather large data sets necessary for deep learning approaches.
Modeling Time Series Similarity with Siamese Recurrent Networks
Mar 15, 2016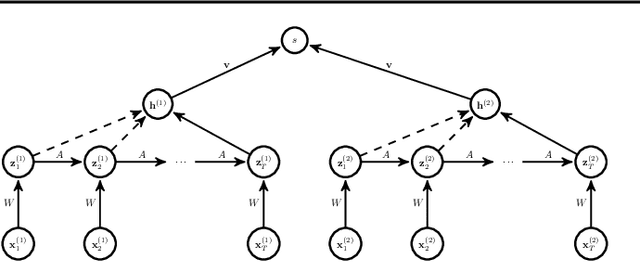
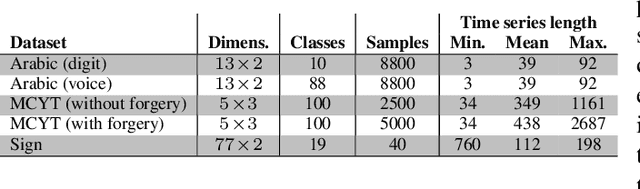
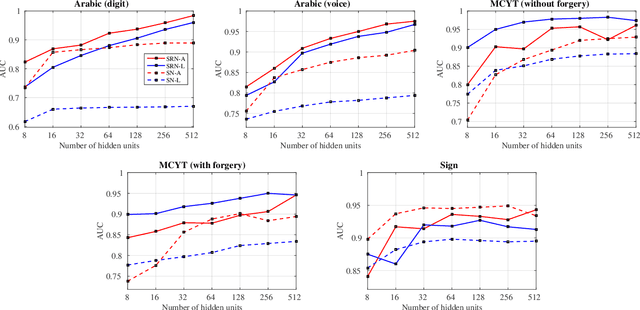
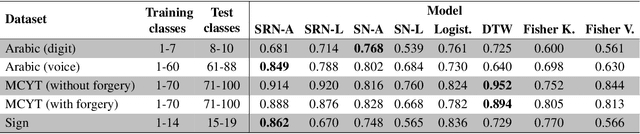
Traditional techniques for measuring similarities between time series are based on handcrafted similarity measures, whereas more recent learning-based approaches cannot exploit external supervision. We combine ideas from time-series modeling and metric learning, and study siamese recurrent networks (SRNs) that minimize a classification loss to learn a good similarity measure between time series. Specifically, our approach learns a vectorial representation for each time series in such a way that similar time series are modeled by similar representations, and dissimilar time series by dissimilar representations. Because it is a similarity prediction models, SRNs are particularly well-suited to challenging scenarios such as signature recognition, in which each person is a separate class and very few examples per class are available. We demonstrate the potential merits of SRNs in within-domain and out-of-domain classification experiments and in one-shot learning experiments on tasks such as signature, voice, and sign language recognition.