 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayout Generation and Completion with Self-attention
Jun 25, 2020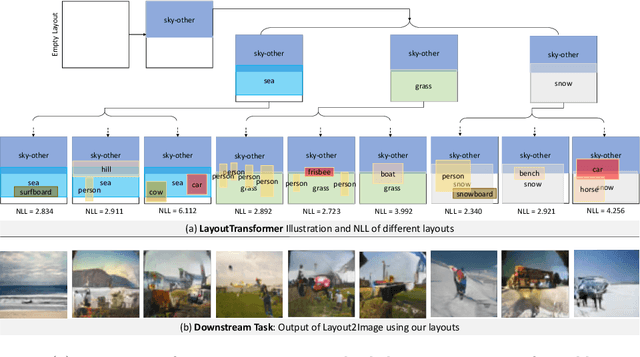
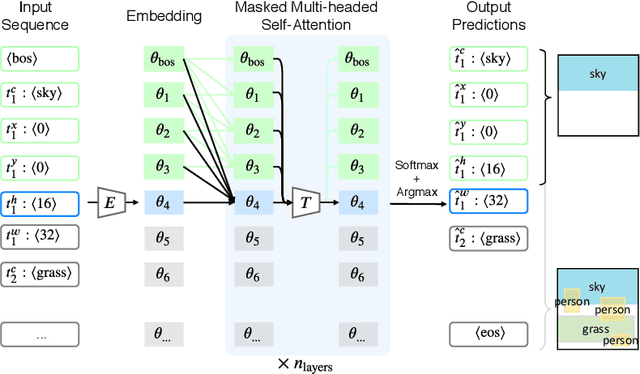

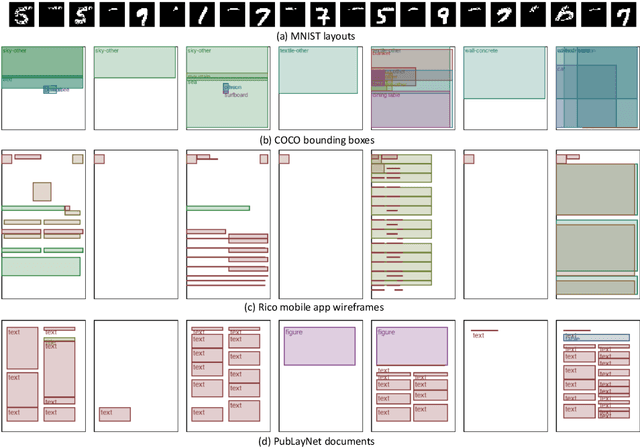
We address the problem of layout generation for diverse domains such as images, documents, and mobile applications. A layout is a set of graphical elements, belonging to one or more categories, placed together in a meaningful way. Generating a new layout or extending an existing layout requires understanding the relationships between these graphical elements. To do this, we propose a novel framework, LayoutTransformer, that leverages a self-attention based approach to learn contextual relationships between layout elements and generate layouts in a given domain. The proposed model improves upon the state-of-the-art approaches in layout generation in four ways. First, our model can generate a new layout either from an empty set or add more elements to a partial layout starting from an initial set of elements. Second, as the approach is attention-based, we can visualize which previous elements the model is attending to predict the next element, thereby providing an interpretable sequence of layout elements. Third, our model can easily scale to support both a large number of element categories and a large number of elements per layout. Finally, the model also produces an embedding for various element categories, which can be used to explore the relationships between the categories. We demonstrate with experiments that our model can produce meaningful layouts in diverse settings such as object bounding boxes in scenes (COCO bounding boxes), documents (PubLayNet), and mobile applications (RICO dataset).
Quantization Guided JPEG Artifact Correction
Apr 17, 2020
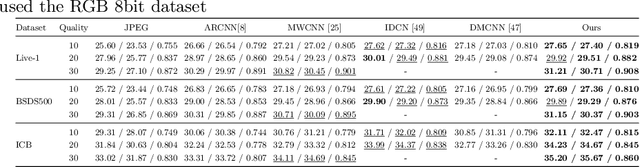
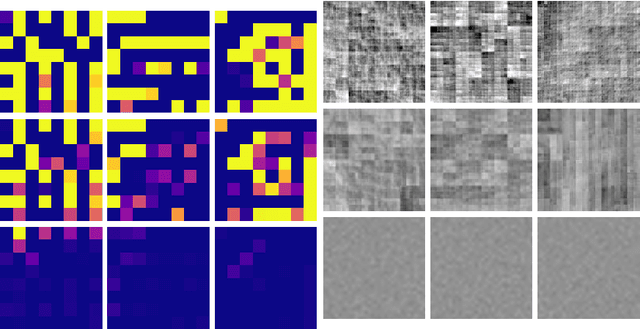

The JPEG image compression algorithm is the most popular method of image compression because of its ability for large compression ratios. However, to achieve such high compression, information is lost. For aggressive quantization settings, this leads to a noticeable reduction in image quality. Artifact correction has been studied in the context of deep neural networks for some time, but the current state-of-the-art methods require a different model to be trained for each quality setting, greatly limiting their practical application. We solve this problem by creating a novel architecture which is parameterized by the JPEG files quantization matrix. This allows our single model to achieve state-of-the-art performance over models trained for specific quality settings.
Inclusive GAN: Improving Data and Minority Coverage in Generative Models
Apr 12, 2020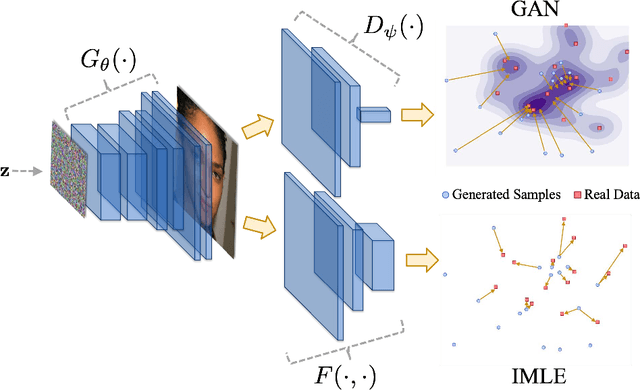

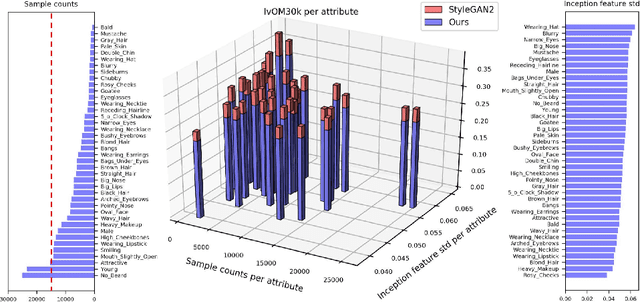
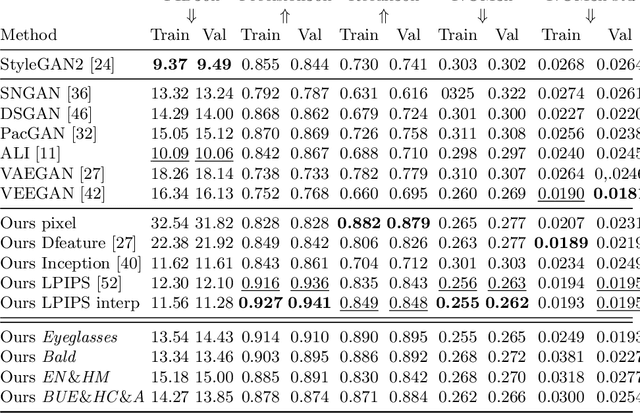
Generative Adversarial Networks (GANs) have brought about rapid progress towards generating photorealistic images. Yet the equitable allocation of their modeling capacity among subgroups has received less attention, which could lead to potential biases against underrepresented minorities if left uncontrolled. In this work, we first formalize the problem of minority inclusion as one of data coverage, and then propose to improve data coverage by harmonizing adversarial training with reconstructive generation. The experiments show that our method outperforms the existing state-of-the-art methods in terms of data coverage on both seen and unseen data. We develop an extension that allows explicit control over the minority subgroups that the model should ensure to include, and validate its effectiveness at little compromise from the overall performance on the entire dataset. Code, models, and supplemental videos are available at GitHub.
Making an Invisibility Cloak: Real World Adversarial Attacks on Object Detectors
Oct 31, 2019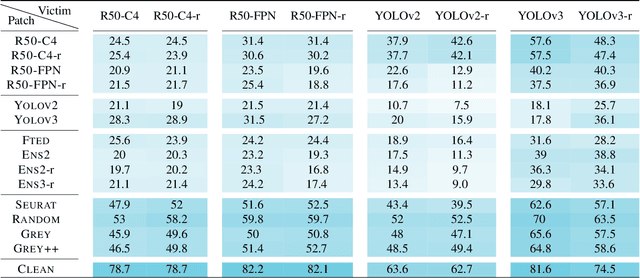
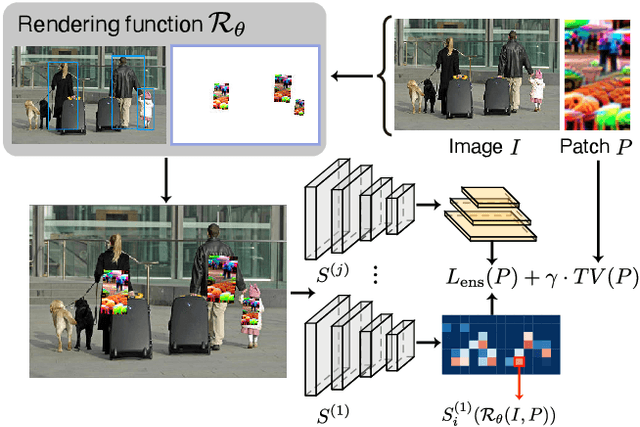

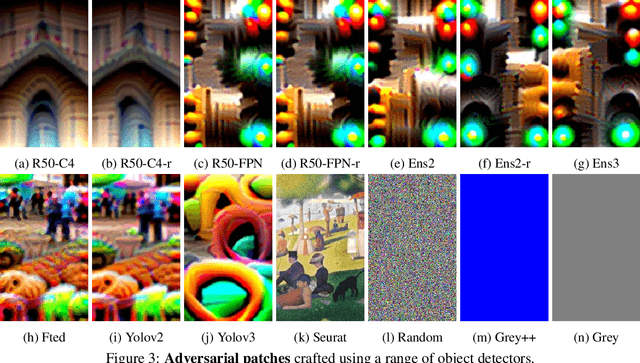
We present a systematic study of adversarial attacks on state-of-the-art object detection frameworks. Using standard detection datasets, we train patterns that suppress the objectness scores produced by a range of commonly used detectors, and ensembles of detectors. Through extensive experiments, we benchmark the effectiveness of adversarially trained patches under both white-box and black-box settings, and quantify transferability of attacks between datasets, object classes, and detector models. Finally, we present a detailed study of physical world attacks using printed posters and wearable clothes, and rigorously quantify the performance of such attacks with different metrics.
A weakly supervised adaptive triplet loss for deep metric learning
Sep 27, 2019
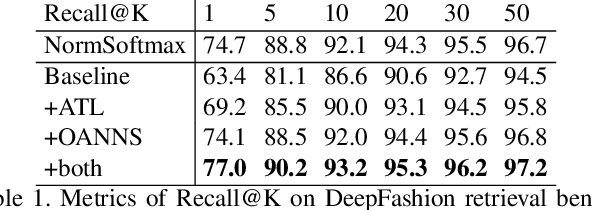
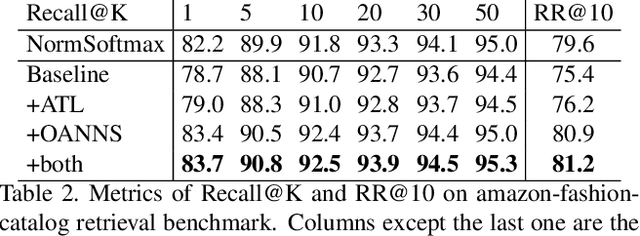
We address the problem of distance metric learning in visual similarity search, defined as learning an image embedding model which projects images into Euclidean space where semantically and visually similar images are closer and dissimilar images are further from one another. We present a weakly supervised adaptive triplet loss (ATL) capable of capturing fine-grained semantic similarity that encourages the learned image embedding models to generalize well on cross-domain data. The method uses weakly labeled product description data to implicitly determine fine grained semantic classes, avoiding the need to annotate large amounts of training data. We evaluate on the Amazon fashion retrieval benchmark and DeepFashion in-shop retrieval data. The method boosts the performance of triplet loss baseline by 10.6% on cross-domain data and out-performs the state-of-art model on all evaluation metrics.
STEP: Spatio-Temporal Progressive Learning for Video Action Detection
Apr 19, 2019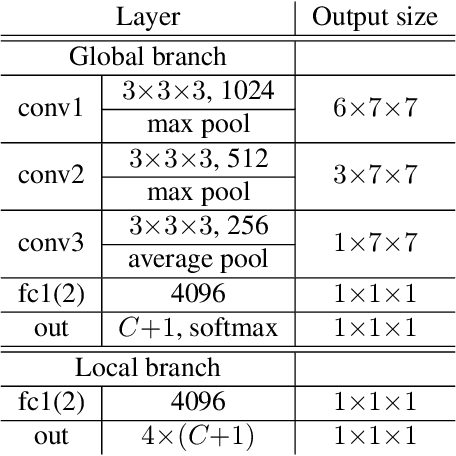

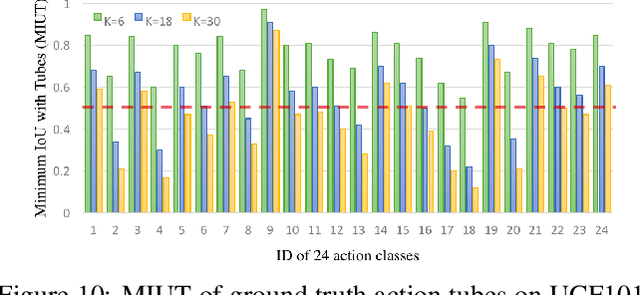
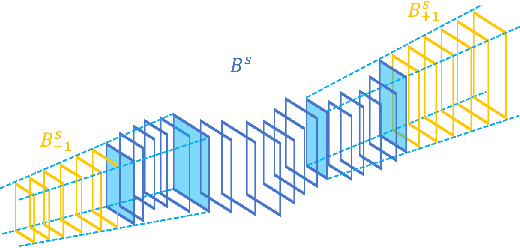
In this paper, we propose Spatio-TEmporal Progressive (STEP) action detector---a progressive learning framework for spatio-temporal action detection in videos. Starting from a handful of coarse-scale proposal cuboids, our approach progressively refines the proposals towards actions over a few steps. In this way, high-quality proposals (i.e., adhere to action movements) can be gradually obtained at later steps by leveraging the regression outputs from previous steps. At each step, we adaptively extend the proposals in time to incorporate more related temporal context. Compared to the prior work that performs action detection in one run, our progressive learning framework is able to naturally handle the spatial displacement within action tubes and therefore provides a more effective way for spatio-temporal modeling. We extensively evaluate our approach on UCF101 and AVA, and demonstrate superior detection results. Remarkably, we achieve mAP of 75.0% and 18.6% on the two datasets with 3 progressive steps and using respectively only 11 and 34 initial proposals.
Unsupervised Data Uncertainty Learning in Visual Retrieval Systems
Feb 07, 2019
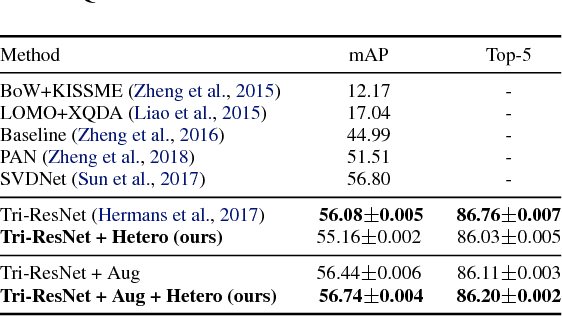
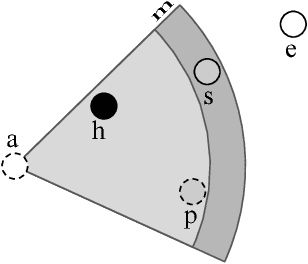

We introduce an unsupervised formulation to estimate heteroscedastic uncertainty in retrieval systems. We propose an extension to triplet loss that models data uncertainty for each input. Besides improving performance, our formulation models local noise in the embedding space. It quantifies input uncertainty and thus enhances interpretability of the system. This helps identify noisy observations in query and search databases. Evaluation on both image and video retrieval applications highlight the utility of our approach. We highlight our efficiency in modeling local noise using two real-world datasets: Clothing1M and Honda Driving datasets. Qualitative results illustrate our ability in identifying confusing scenarios in various domains. Uncertainty learning also enables data cleaning by detecting noisy training labels.
In Defense of the Triplet Loss for Visual Recognition
Jan 24, 2019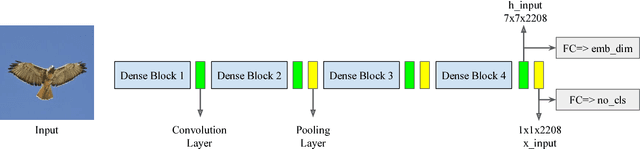
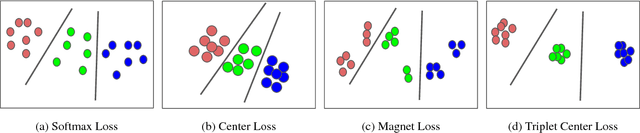

We employ triplet loss as a space embedding regularizer to boost classification performance. Standard architectures, like ResNet and DesneNet, are extended to support both losses with minimal hyper-parameter tuning. This promotes generality while fine-tuning pretrained networks. Triplet loss is a powerful surrogate for recently proposed embedding regularizers. Yet, it is avoided for large batch-size requirement and high computational cost. Through our experiments, we re-assess these assumptions. During inference, our network supports both classification and embedding tasks without any computational overhead. Quantitative evaluation highlights how our approach compares favorably to the existing state of the art on multiple fine-grained recognition datasets. Further evaluation on an imbalanced video dataset achieves significant improvement (>7%). Beyond boosting efficiency, triplet loss brings retrieval and interpretability to classification models.
Exploring Uncertainty in Conditional Multi-Modal Retrieval Systems
Jan 23, 2019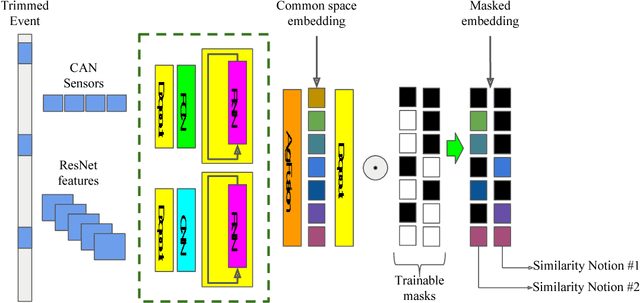
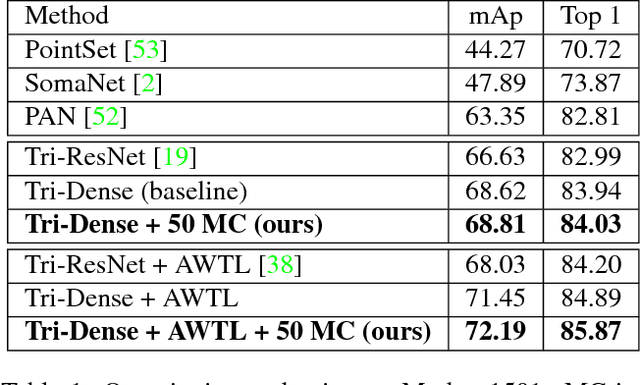
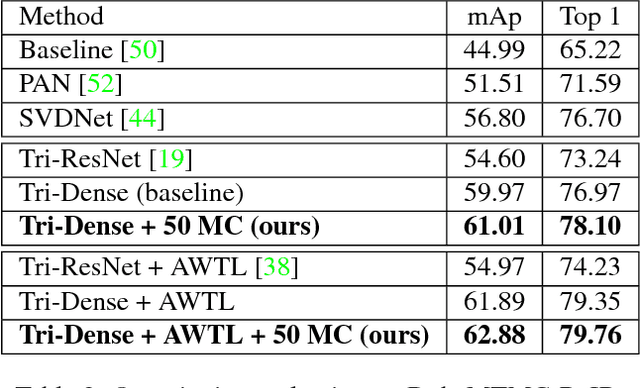
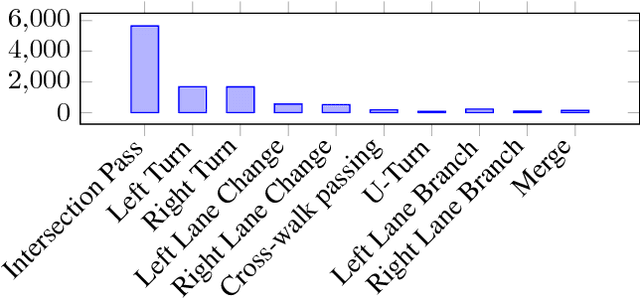
We cast visual retrieval as a regression problem by posing triplet loss as a regression loss. This enables epistemic uncertainty estimation using dropout as a Bayesian approximation framework in retrieval. Accordingly, Monte Carlo (MC) sampling is leveraged to boost retrieval performance. Our approach is evaluated on two applications: person re-identification and autonomous car driving. Comparable state-of-the-art results are achieved on multiple datasets for the former application. We leverage the Honda driving dataset (HDD) for autonomous car driving application. It provides multiple modalities and similarity notions for ego-motion action understanding. Hence, we present a multi-modal conditional retrieval network. It disentangles embeddings into separate representations to encode different similarities. This form of joint learning eliminates the need to train multiple independent networks without any performance degradation. Quantitative evaluation highlights our approach competence, achieving 6% improvement in a highly uncertain environment.
Deep Residual Learning in the JPEG Transform Domain
Jan 05, 2019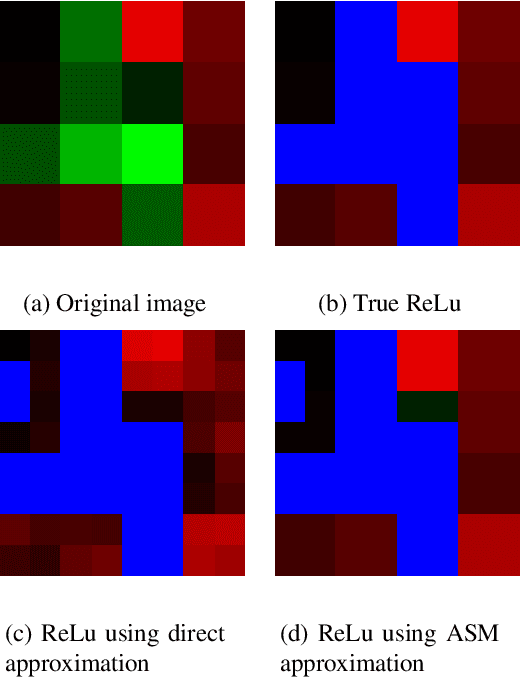
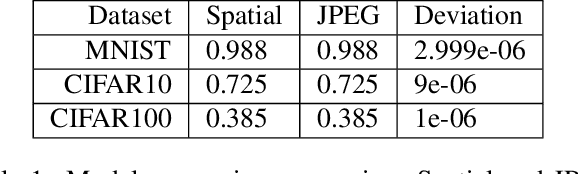
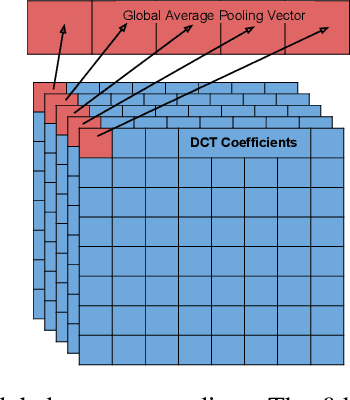
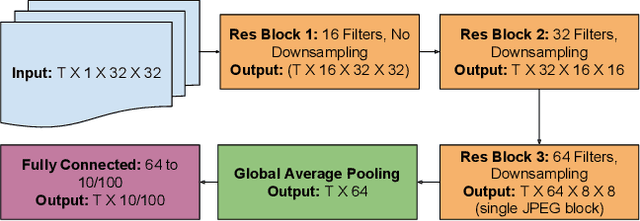
We introduce a general method of performing Residual Network inference and learning in the JPEG transform domain that allows the network to consume compressed images as input. Our formulation leverages the linearity of the JPEG transform to redefine convolution and batch normalization with a tune-able numerical approximation for ReLu. The result is mathematically equivalent to the spatial domain network up to the ReLu approximation accuracy. A formulation for image classification and a model conversion algorithm for spatial domain networks are given as examples of the method. We show that the sparsity of the JPEG format allows for faster processing of images with little to no penalty in the network accuracy.