 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Contrastive Loss and Attention for GANs
Mar 31, 2021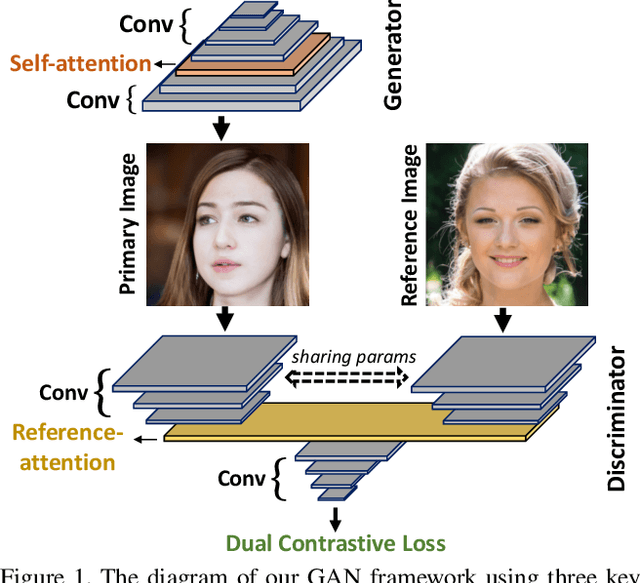
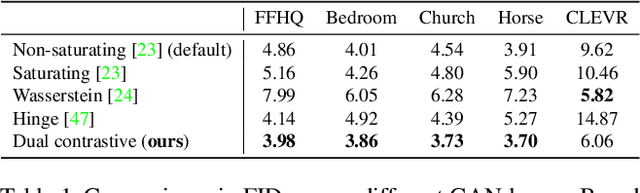
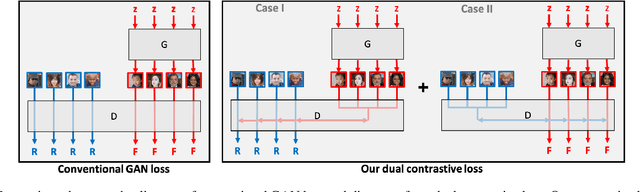

Generative Adversarial Networks (GANs) produce impressive results on unconditional image generation when powered with large-scale image datasets. Yet generated images are still easy to spot especially on datasets with high variance (e.g. bedroom, church). In this paper, we propose various improvements to further push the boundaries in image generation. Specifically, we propose a novel dual contrastive loss and show that, with this loss, discriminator learns more generalized and distinguishable representations to incentivize generation. In addition, we revisit attention and extensively experiment with different attention blocks in the generator. We find attention to be still an important module for successful image generation even though it was not used in the recent state-of-the-art models. Lastly, we study different attention architectures in the discriminator, and propose a reference attention mechanism. By combining the strengths of these remedies, we improve the compelling state-of-the-art Fr\'{e}chet Inception Distance (FID) by at least 17.5% on several benchmark datasets. We obtain even more significant improvements on compositional synthetic scenes (up to 47.5% in FID).
Knowledge Evolution in Neural Networks
Mar 09, 2021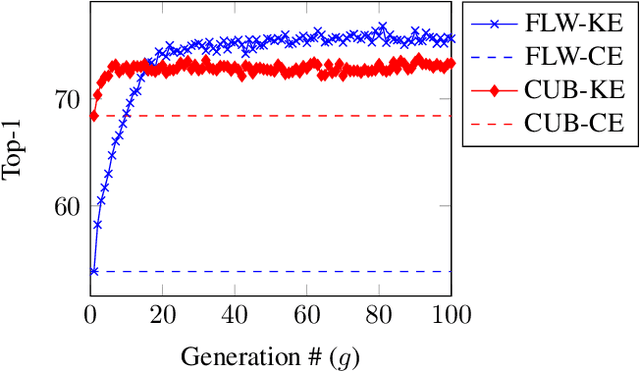
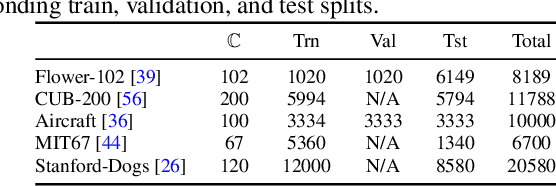
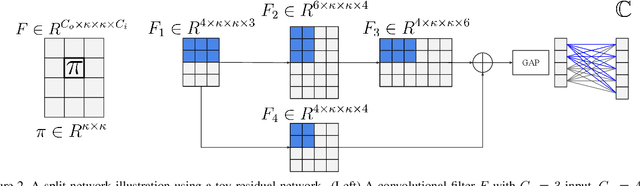
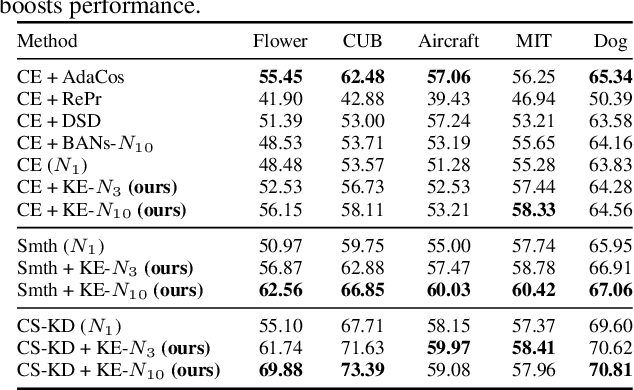
Deep learning relies on the availability of a large corpus of data (labeled or unlabeled). Thus, one challenging unsettled question is: how to train a deep network on a relatively small dataset? To tackle this question, we propose an evolution-inspired training approach to boost performance on relatively small datasets. The knowledge evolution (KE) approach splits a deep network into two hypotheses: the fit-hypothesis and the reset-hypothesis. We iteratively evolve the knowledge inside the fit-hypothesis by perturbing the reset-hypothesis for multiple generations. This approach not only boosts performance, but also learns a slim network with a smaller inference cost. KE integrates seamlessly with both vanilla and residual convolutional networks. KE reduces both overfitting and the burden for data collection. We evaluate KE on various network architectures and loss functions. We evaluate KE using relatively small datasets (e.g., CUB-200) and randomly initialized deep networks. KE achieves an absolute 21% improvement margin on a state-of-the-art baseline. This performance improvement is accompanied by a relative 73% reduction in inference cost. KE achieves state-of-the-art results on classification and metric learning benchmarks. Code available at http://bit.ly/3uLgwYb
SVMax: A Feature Embedding Regularizer
Mar 04, 2021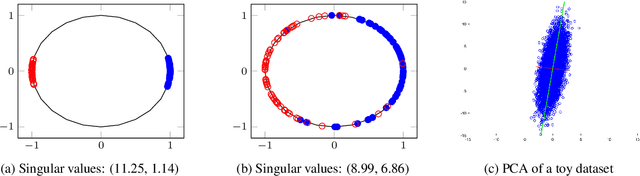
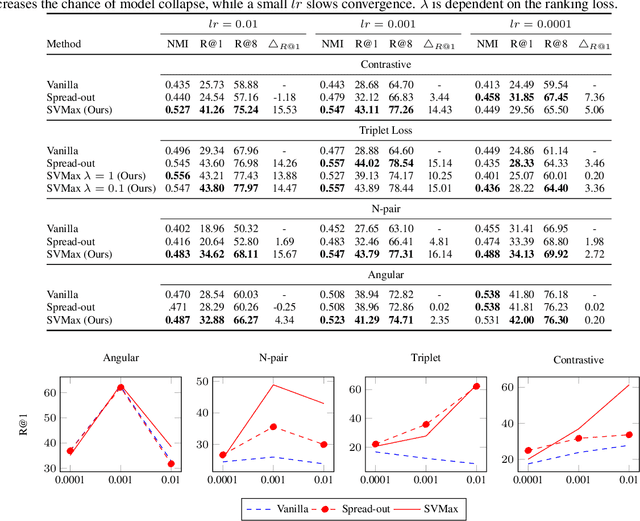
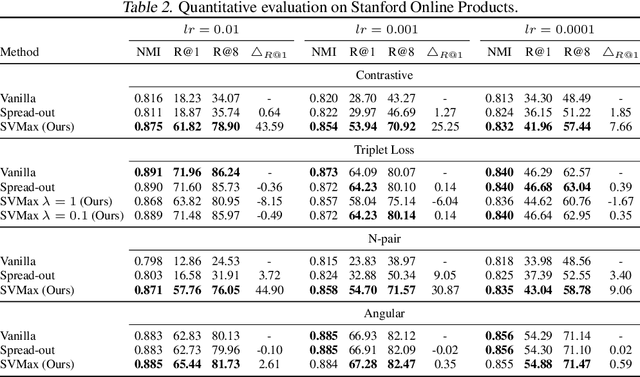
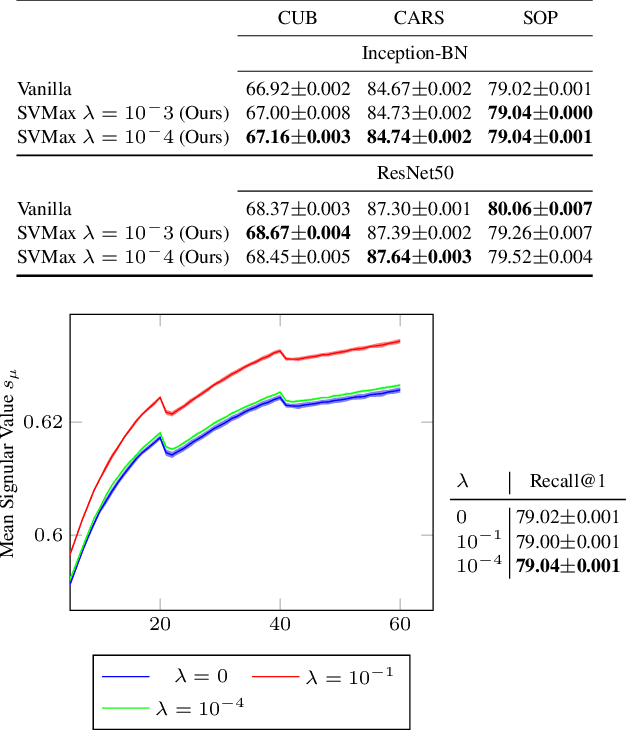
A neural network regularizer (e.g., weight decay) boosts performance by explicitly penalizing the complexity of a network. In this paper, we penalize inferior network activations -- feature embeddings -- which in turn regularize the network's weights implicitly. We propose singular value maximization (SVMax) to learn a more uniform feature embedding. The SVMax regularizer supports both supervised and unsupervised learning. Our formulation mitigates model collapse and enables larger learning rates. We evaluate the SVMax regularizer using both retrieval and generative adversarial networks. We leverage a synthetic mixture of Gaussians dataset to evaluate SVMax in an unsupervised setting. For retrieval networks, SVMax achieves significant improvement margins across various ranking losses. Code available at https://bit.ly/3jNkgDt
Responsible Disclosure of Generative Models Using Scalable Fingerprinting
Dec 16, 2020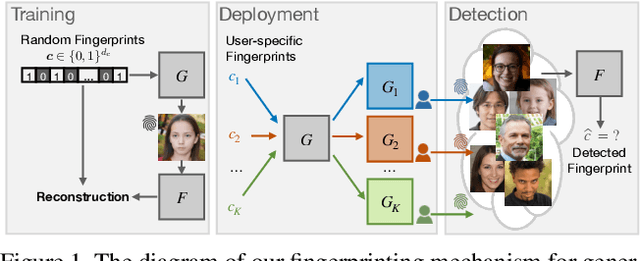
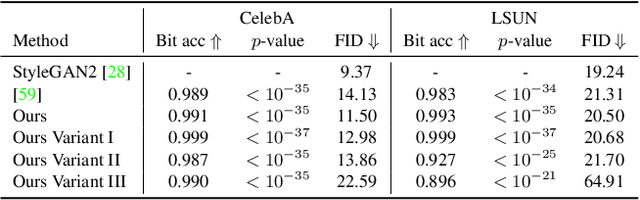
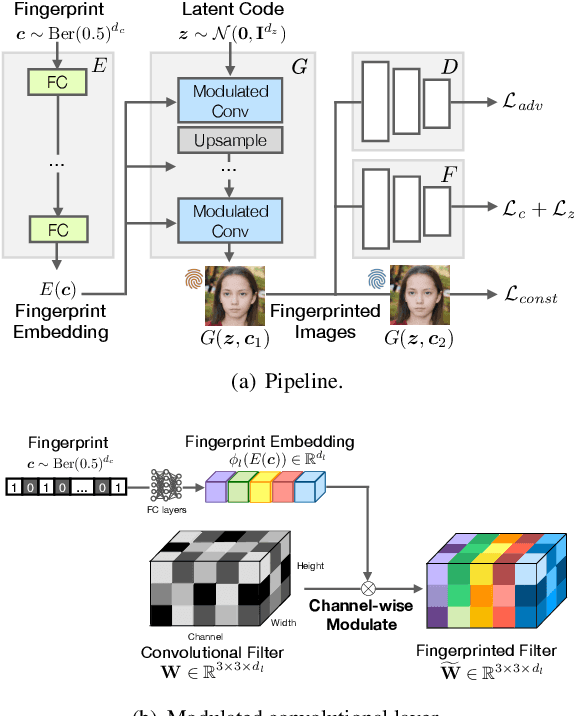
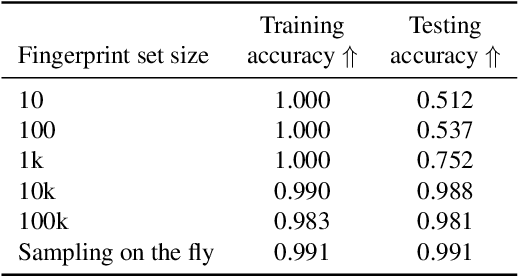
Over the past five years, deep generative models have achieved a qualitative new level of performance. Generated data has become difficult, if not impossible, to be distinguished from real data. While there are plenty of use cases that benefit from this technology, there are also strong concerns on how this new technology can be misused to spoof sensors, generate deep fakes, and enable misinformation at scale. Unfortunately, current deep fake detection methods are not sustainable, as the gap between real and fake continues to close. In contrast, our work enables a responsible disclosure of such state-of-the-art generative models, that allows researchers and companies to fingerprint their models, so that the generated samples containing a fingerprint can be accurately detected and attributed to a source. Our technique achieves this by an efficient and scalable ad-hoc generation of a large population of models with distinct fingerprints. Our recommended operation point uses a 128-bit fingerprint which in principle results in more than $10^{36}$ identifiable models. Experimental results show that our method fulfills key properties of a fingerprinting mechanism and achieves effectiveness in deep fake detection and attribution.
The Lottery Ticket Hypothesis for Object Recognition
Dec 08, 2020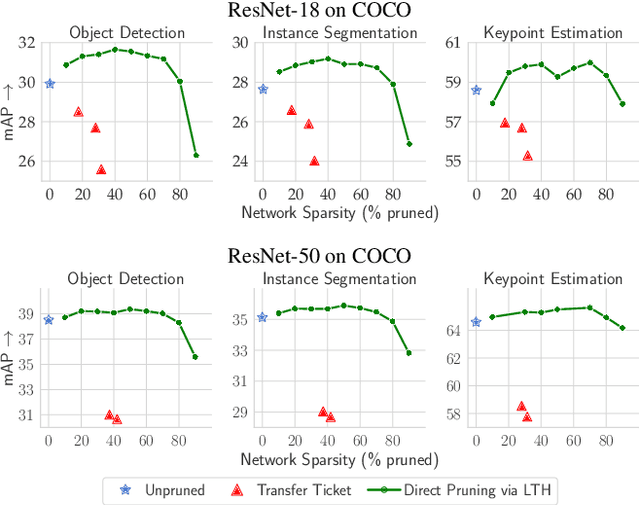
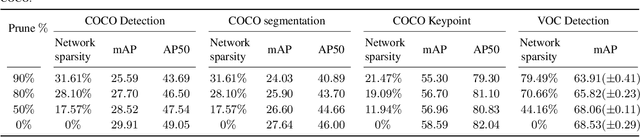

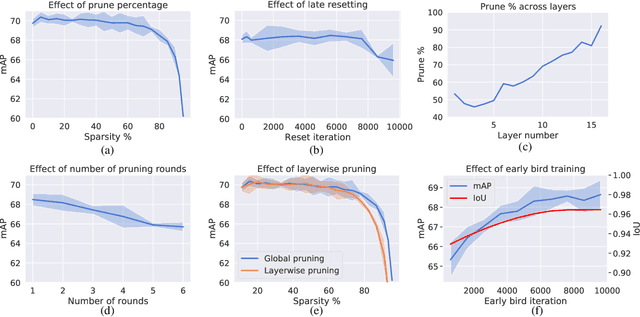
Recognition tasks, such as object recognition and keypoint estimation, have seen widespread adoption in recent years. Most state-of-the-art methods for these tasks use deep networks that are computationally expensive and have huge memory footprints. This makes it exceedingly difficult to deploy these systems on low power embedded devices. Hence, the importance of decreasing the storage requirements and the amount of computation in such models is paramount. The recently proposed Lottery Ticket Hypothesis (LTH) states that deep neural networks trained on large datasets contain smaller subnetworks that achieve on par performance as the dense networks. In this work, we perform the first empirical study investigating LTH for model pruning in the context of object detection, instance segmentation, and keypoint estimation. Our studies reveal that lottery tickets obtained from ImageNet pretraining do not transfer well to the downstream tasks. We provide guidance on how to find lottery tickets with up to 80% overall sparsity on different sub-tasks without incurring any drop in the performance. Finally, we analyse the behavior of trained tickets with respect to various task attributes such as object size, frequency, and difficulty of detection.
SLADE: A Self-Training Framework For Distance Metric Learning
Nov 20, 2020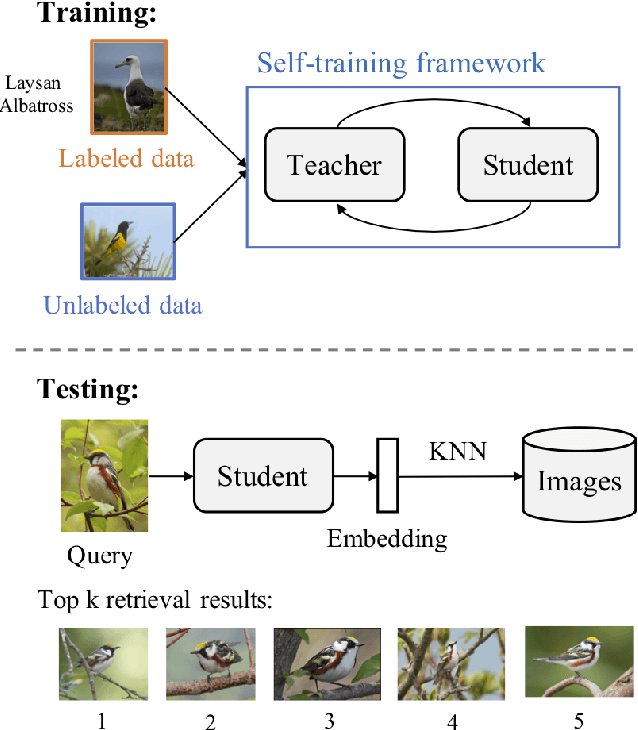
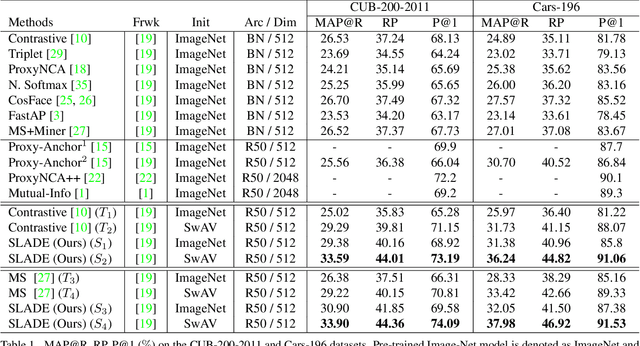
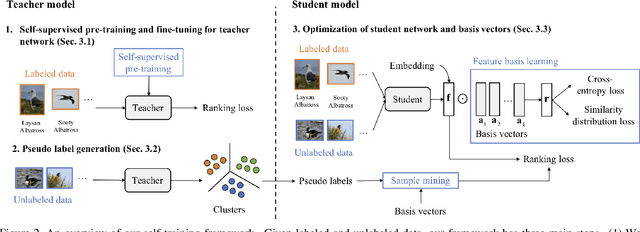
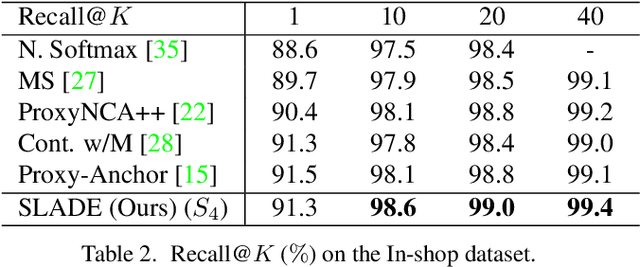
Most existing distance metric learning approaches use fully labeled data to learn the sample similarities in an embedding space. We present a self-training framework, SLADE, to improve retrieval performance by leveraging additional unlabeled data. We first train a teacher model on the labeled data and use it to generate pseudo labels for the unlabeled data. We then train a student model on both labels and pseudo labels to generate final feature embeddings. We use self-supervised representation learning to initialize the teacher model. To better deal with noisy pseudo labels generated by the teacher network, we design a new feature basis learning component for the student network, which learns basis functions of feature representations for unlabeled data. The learned basis vectors better measure the pairwise similarity and are used to select high-confident samples for training the student network. We evaluate our method on standard retrieval benchmarks: CUB-200, Cars-196 and In-shop. Experimental results demonstrate that our approach significantly improves the performance over the state-of-the-art methods.
Analyzing and Mitigating Compression Defects in Deep Learning
Nov 17, 2020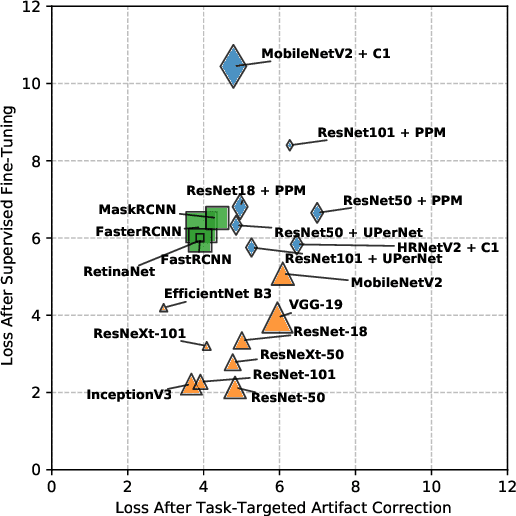
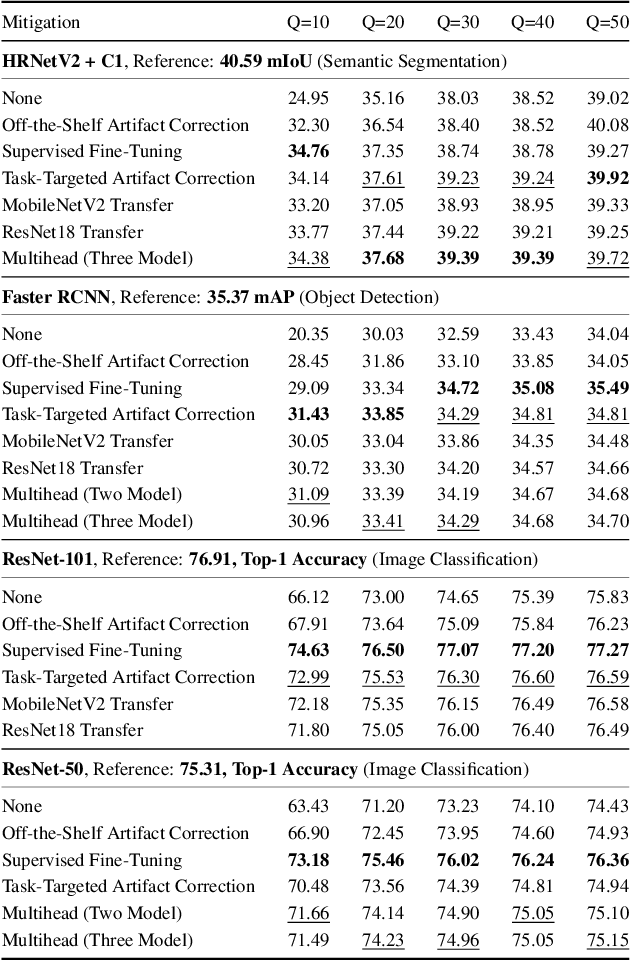
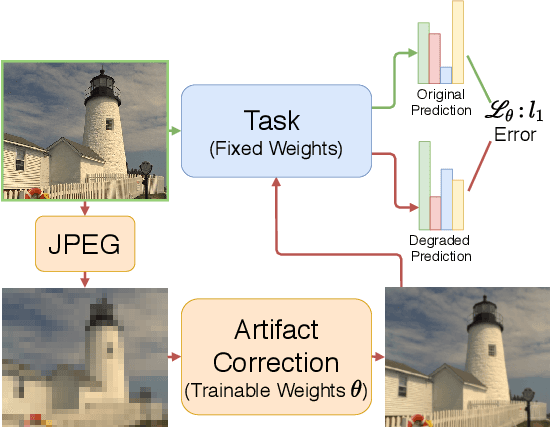
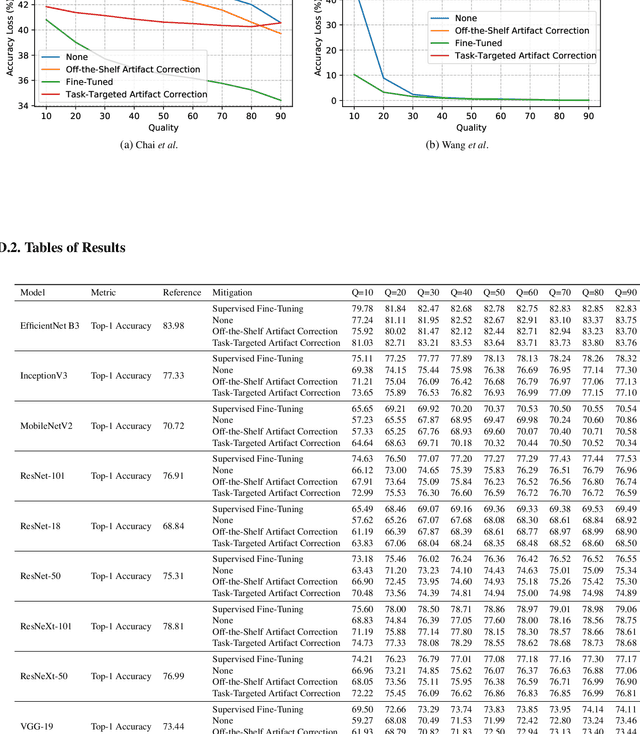
With the proliferation of deep learning methods, many computer vision problems which were considered academic are now viable in the consumer setting. One drawback of consumer applications is lossy compression, which is necessary from an engineering standpoint to efficiently and cheaply store and transmit user images. Despite this, there has been little study of the effect of compression on deep neural networks and benchmark datasets are often losslessly compressed or compressed at high quality. Here we present a unified study of the effects of JPEG compression on a range of common tasks and datasets. We show that there is a significant penalty on common performance metrics for high compression. We test several methods for mitigating this penalty, including a novel method based on artifact correction which requires no labels to train.
ASAP-NMS: Accelerating Non-Maximum Suppression Using Spatially Aware Priors
Aug 21, 2020

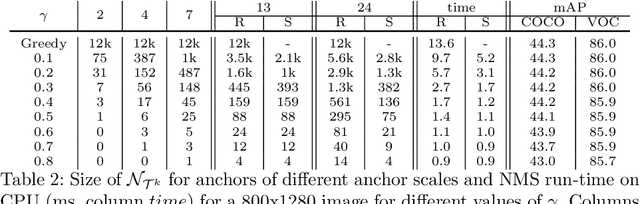

The widely adopted sequential variant of Non Maximum Suppression (or Greedy-NMS) is a crucial module for object-detection pipelines. Unfortunately, for the region proposal stage of two/multi-stage detectors, NMS is turning out to be a latency bottleneck due to its sequential nature. In this article, we carefully profile Greedy-NMS iterations to find that a major chunk of computation is wasted in comparing proposals that are already far-away and have a small chance of suppressing each other. We address this issue by comparing only those proposals that are generated from nearby anchors. The translation-invariant property of the anchor lattice affords generation of a lookup table, which provides an efficient access to nearby proposals, during NMS. This leads to an Accelerated NMS algorithm which leverages Spatially Aware Priors, or ASAP-NMS, and improves the latency of the NMS step from 13.6ms to 1.2 ms on a CPU without sacrificing the accuracy of a state-of-the-art two-stage detector on COCO and VOC datasets. Importantly, ASAP-NMS is agnostic to image resolution and can be used as a simple drop-in module during inference. Using ASAP-NMS at run-time only, we obtain an mAP of 44.2\%@25Hz on the COCO dataset with a V100 GPU.
Hierarchical Contrastive Motion Learning for Video Action Recognition
Jul 20, 2020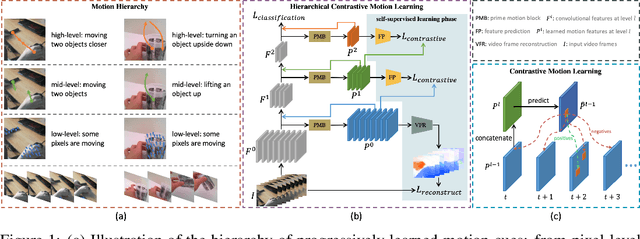
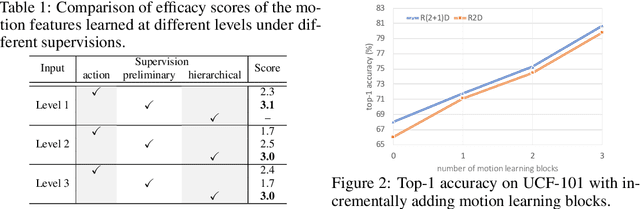
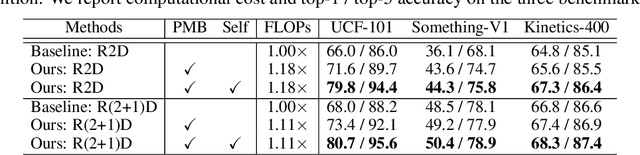

One central question for video action recognition is how to model motion. In this paper, we present hierarchical contrastive motion learning, a new self-supervised learning framework to extract effective motion representations from raw video frames. Our approach progressively learns a hierarchy of motion features that correspond to different abstraction levels in a network. This hierarchical design bridges the semantic gap between low-level motion cues and high-level recognition tasks, and promotes the fusion of appearance and motion information at multiple levels. At each level, an explicit motion self-supervision is provided via contrastive learning to enforce the motion features at the current level to predict the future ones at the previous level. Thus, the motion features at higher levels are trained to gradually capture semantic dynamics and evolve more discriminative for action recognition. Our motion learning module is lightweight and flexible to be embedded into various backbone networks. Extensive experiments on four benchmarks show that the proposed approach consistently achieves superior results.
A Generic Visualization Approach for Convolutional Neural Networks
Jul 19, 2020
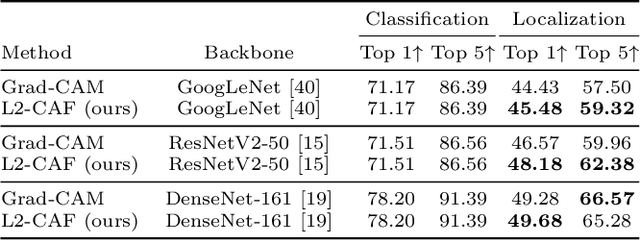

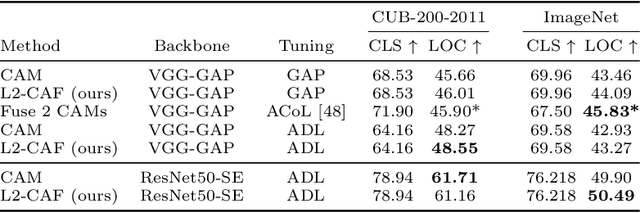
Retrieval networks are essential for searching and indexing. Compared to classification networks, attention visualization for retrieval networks is hardly studied. We formulate attention visualization as a constrained optimization problem. We leverage the unit L2-Norm constraint as an attention filter (L2-CAF) to localize attention in both classification and retrieval networks. Unlike recent literature, our approach requires neither architectural changes nor fine-tuning. Thus, a pre-trained network's performance is never undermined L2-CAF is quantitatively evaluated using weakly supervised object localization. State-of-the-art results are achieved on classification networks. For retrieval networks, significant improvement margins are achieved over a Grad-CAM baseline. Qualitative evaluation demonstrates how the L2-CAF visualizes attention per frame for a recurrent retrieval network. Further ablation studies highlight the computational cost of our approach and compare L2-CAF with other feasible alternatives. Code available at https://bit.ly/3iDBLFv