 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Deep Classifiers using Generative Models
Jun 07, 2020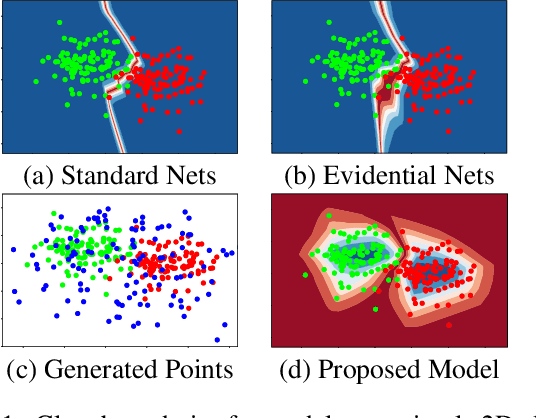
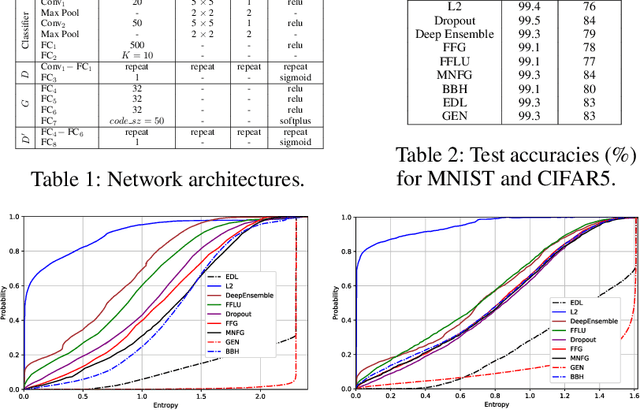

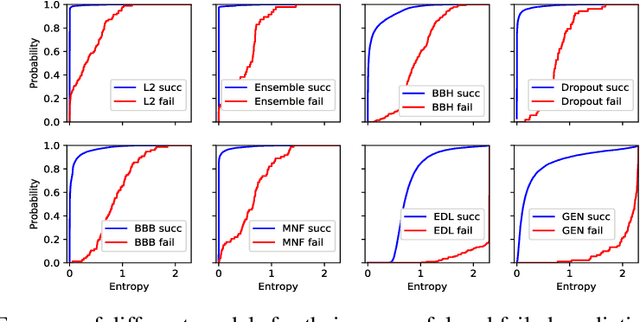
Deep neural networks are often ignorant about what they do not know and overconfident when they make uninformed predictions. Some recent approaches quantify classification uncertainty directly by training the model to output high uncertainty for the data samples close to class boundaries or from the outside of the training distribution. These approaches use an auxiliary data set during training to represent out-of-distribution samples. However, selection or creation of such an auxiliary data set is non-trivial, especially for high dimensional data such as images. In this work we develop a novel neural network model that is able to express both aleatoric and epistemic uncertainty to distinguish decision boundary and out-of-distribution regions of the feature space. To this end, variational autoencoders and generative adversarial networks are incorporated to automatically generate out-of-distribution exemplars for training. Through extensive analysis, we demonstrate that the proposed approach provides better estimates of uncertainty for in- and out-of-distribution samples, and adversarial examples on well-known data sets against state-of-the-art approaches including recent Bayesian approaches for neural networks and anomaly detection methods.
Spherical Text Embedding
Nov 04, 2019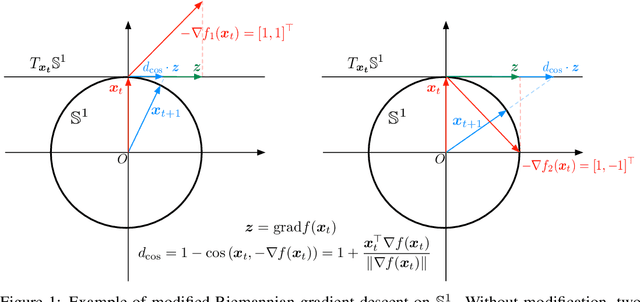
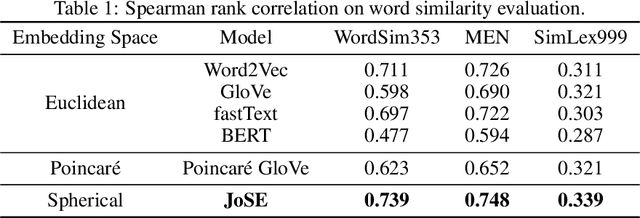
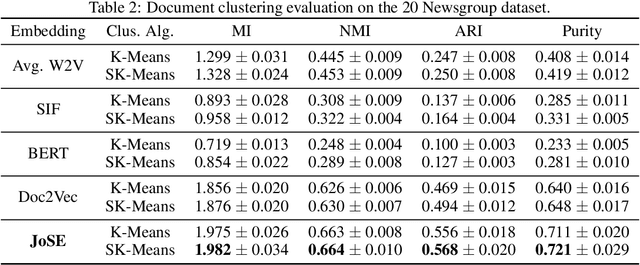
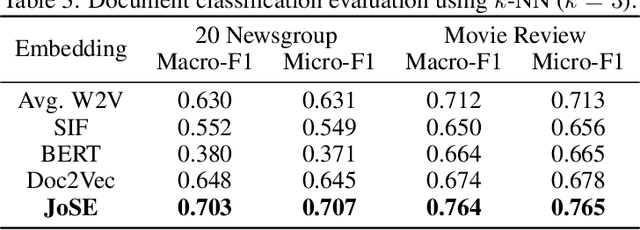
Unsupervised text embedding has shown great power in a wide range of NLP tasks. While text embeddings are typically learned in the Euclidean space, directional similarity is often more effective in tasks such as word similarity and document clustering, which creates a gap between the training stage and usage stage of text embedding. To close this gap, we propose a spherical generative model based on which unsupervised word and paragraph embeddings are jointly learned. To learn text embeddings in the spherical space, we develop an efficient optimization algorithm with convergence guarantee based on Riemannian optimization. Our model enjoys high efficiency and achieves state-of-the-art performances on various text embedding tasks including word similarity and document clustering.
Quantifying Classification Uncertainty using Regularized Evidential Neural Networks
Oct 15, 2019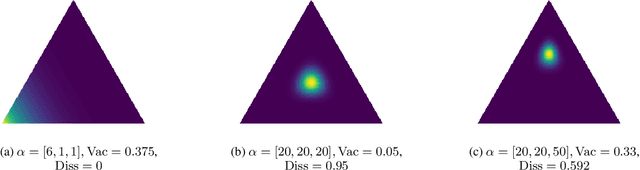
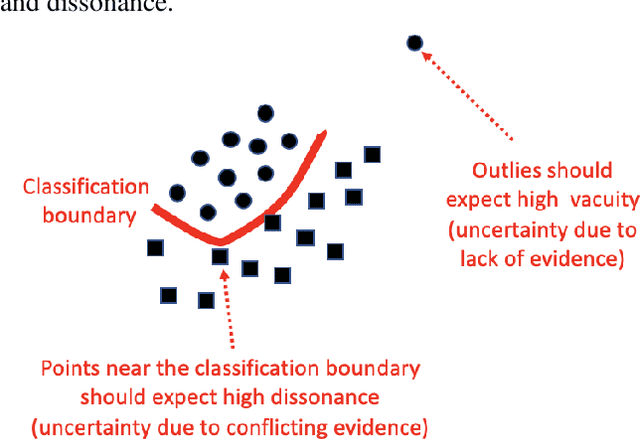
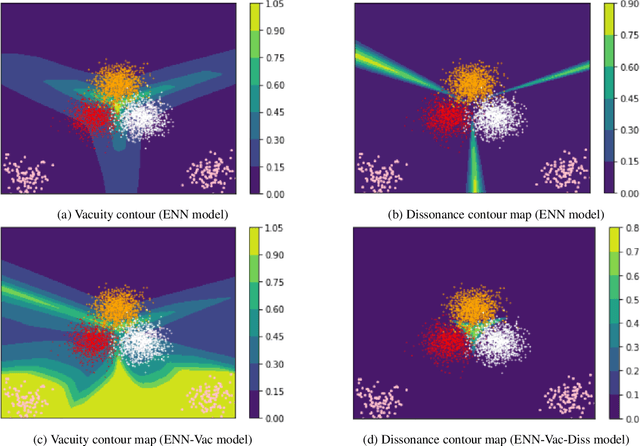
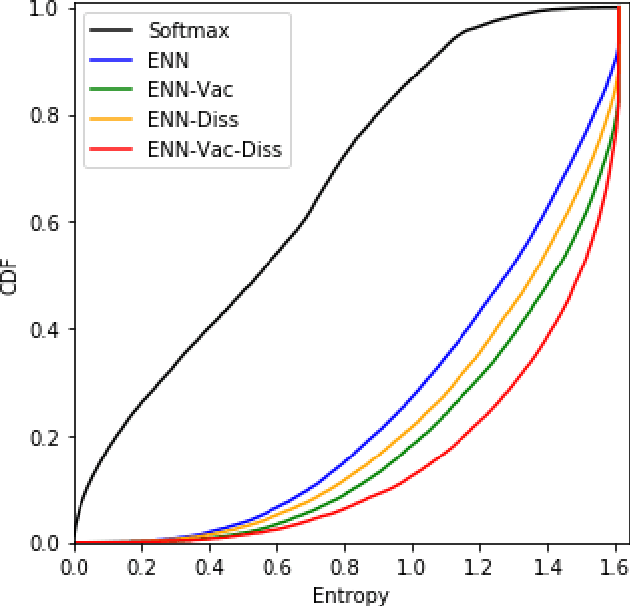
Traditional deep neural nets (NNs) have shown the state-of-the-art performance in the task of classification in various applications. However, NNs have not considered any types of uncertainty associated with the class probabilities to minimize risk due to misclassification under uncertainty in real life. Unlike Bayesian neural nets indirectly infering uncertainty through weight uncertainties, evidential neural networks (ENNs) have been recently proposed to support explicit modeling of the uncertainty of class probabilities. It treats predictions of an NN as subjective opinions and learns the function by collecting the evidence leading to these opinions by a deterministic NN from data. However, an ENN is trained as a black box without explicitly considering different types of inherent data uncertainty, such as vacuity (uncertainty due to a lack of evidence) or dissonance (uncertainty due to conflicting evidence). This paper presents a new approach, called a {\em regularized ENN}, that learns an ENN based on regularizations related to different characteristics of inherent data uncertainty. Via the experiments with both synthetic and real-world datasets, we demonstrate that the proposed regularized ENN can better learn of an ENN modeling different types of uncertainty in the class probabilities for classification tasks.
Non-Bayesian Social Learning with Uncertain Models
Sep 27, 2019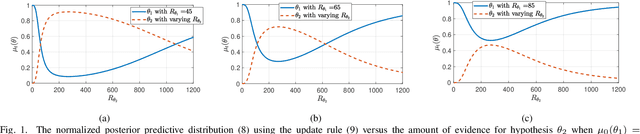
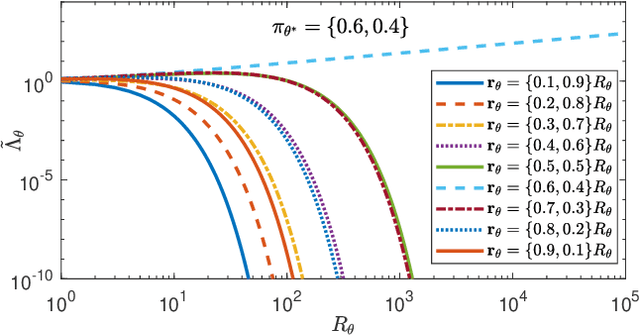
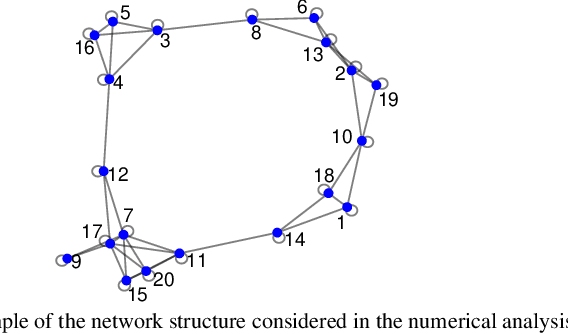
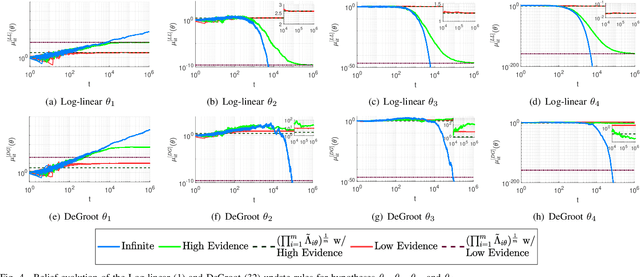
Non-Bayesian social learning theory provides a framework that models distributed inference for a group of agents interacting over a social network. In this framework, each agent iteratively forms and communicates beliefs about an unknown state of the world with their neighbors using a learning rule. Existing approaches assume agents have access to precise statistical models (in the form of likelihoods) for the state of the world. However in many situations, such models must be learned from finite data. We propose a social learning rule that takes into account uncertainty in the statistical models using second-order probabilities. Therefore, beliefs derived from uncertain models are sensitive to the amount of past evidence collected for each hypothesis. We characterize how well the hypotheses can be tested on a social network, as consistent or not with the state of the world. We explicitly show the dependency of the generated beliefs with respect to the amount of prior evidence. Moreover, as the amount of prior evidence goes to infinity, learning occurs and is consistent with traditional social learning theory.
Prior Activation Distribution (PAD): A Versatile Representation to Utilize DNN Hidden Units
Jul 05, 2019
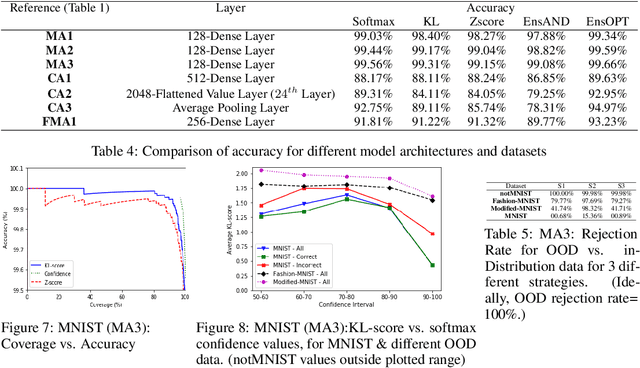
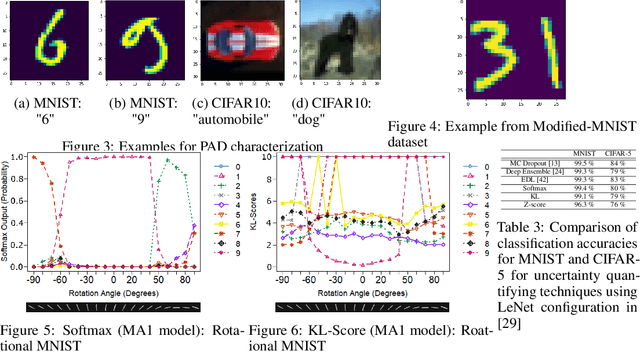
In this paper, we introduce the concept of Prior Activation Distribution (PAD) as a versatile and general technique to capture the typical activation patterns of hidden layer units of a Deep Neural Network used for classification tasks. We show that the combined neural activations of such a hidden layer have class-specific distributional properties, and then define multiple statistical measures to compute how far a test sample's activations deviate from such distributions. Using a variety of benchmark datasets (including MNIST, CIFAR10, Fashion-MNIST & notMNIST), we show how such PAD-based measures can be used, independent of any training technique, to (a) derive fine-grained uncertainty estimates for inferences; (b) provide inferencing accuracy competitive with alternatives that require execution of the full pipeline, and (c) reliably isolate out-of-distribution test samples.
Evidential Deep Learning to Quantify Classification Uncertainty
Oct 31, 2018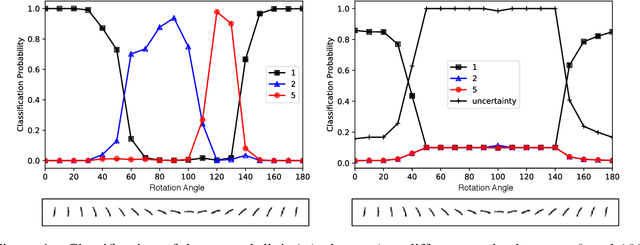
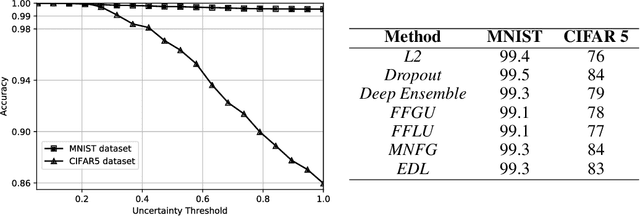
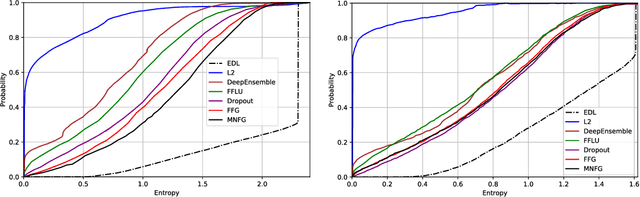
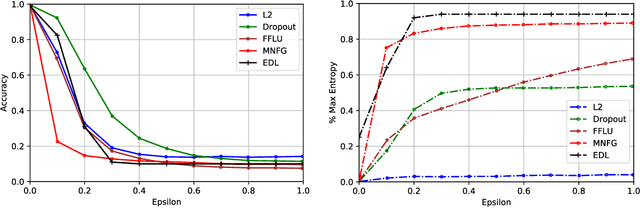
Deterministic neural nets have been shown to learn effective predictors on a wide range of machine learning problems. However, as the standard approach is to train the network to minimize a prediction loss, the resultant model remains ignorant to its prediction confidence. Orthogonally to Bayesian neural nets that indirectly infer prediction uncertainty through weight uncertainties, we propose explicit modeling of the same using the theory of subjective logic. By placing a Dirichlet distribution on the class probabilities, we treat predictions of a neural net as subjective opinions and learn the function that collects the evidence leading to these opinions by a deterministic neural net from data. The resultant predictor for a multi-class classification problem is another Dirichlet distribution whose parameters are set by the continuous output of a neural net. We provide a preliminary analysis on how the peculiarities of our new loss function drive improved uncertainty estimation. We observe that our method achieves unprecedented success on detection of out-of-distribution queries and endurance against adversarial perturbations.
Probabilistic Logic Programming with Beta-Distributed Random Variables
Oct 31, 2018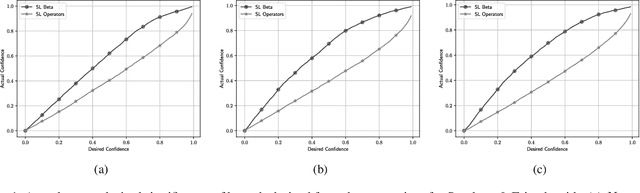
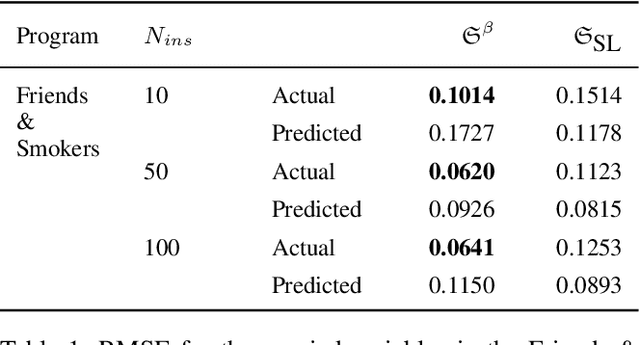
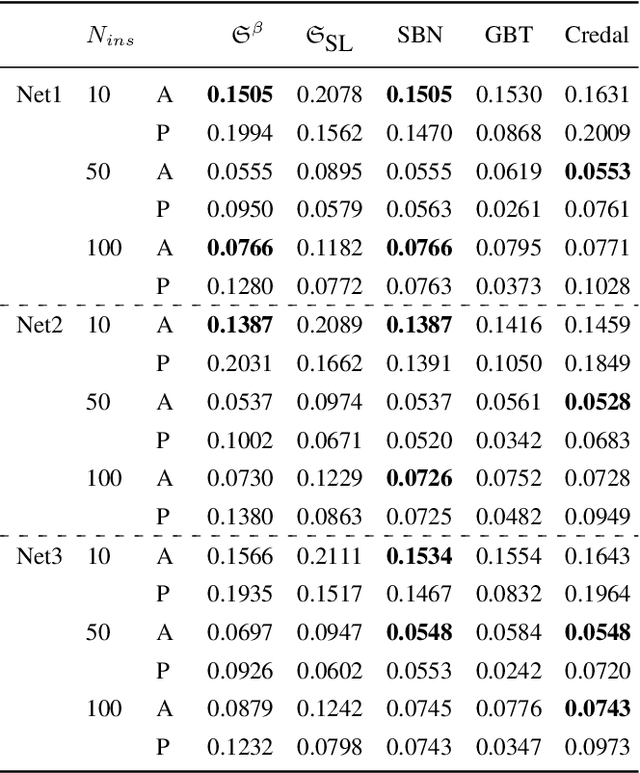
We enable aProbLog---a probabilistic logical programming approach---to reason in presence of uncertain probabilities represented as Beta-distributed random variables. We achieve the same performance of state-of-the-art algorithms for highly specified and engineered domains, while simultaneously we maintain the flexibility offered by aProbLog in handling complex relational domains. Our motivation is that faithfully capturing the distribution of probabilities is necessary to compute an expected utility for effective decision making under uncertainty: unfortunately, these probability distributions can be highly uncertain due to sparse data. To understand and accurately manipulate such probability distributions we need a well-defined theoretical framework that is provided by the Beta distribution, which specifies a distribution of probabilities representing all the possible values of a probability when the exact value is unknown.
Uncertainty Aware AI ML: Why and How
Sep 20, 2018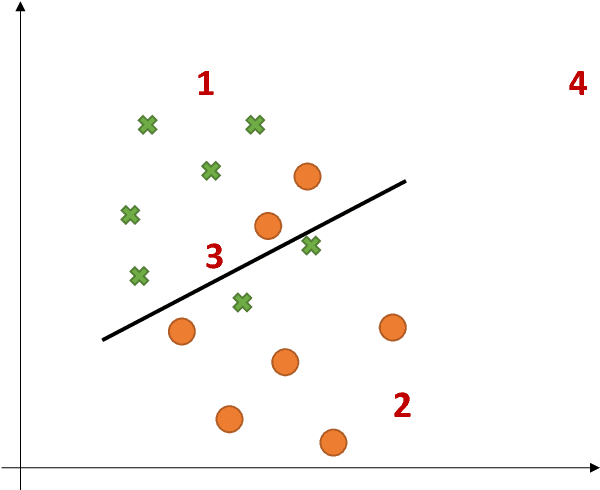
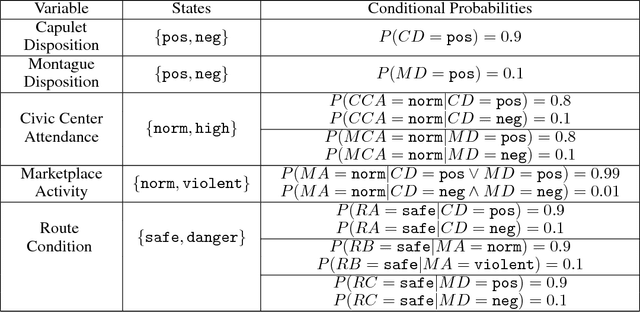
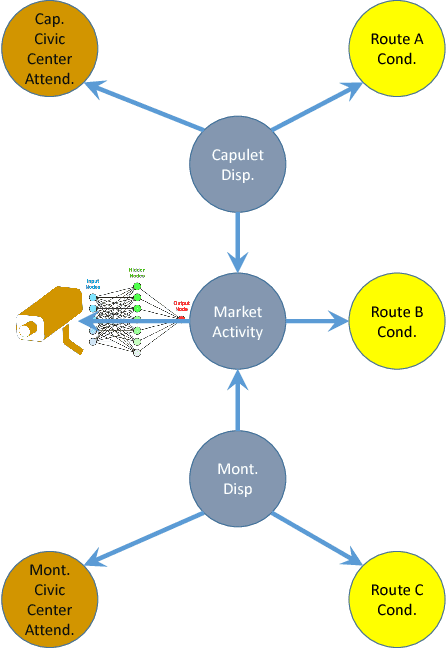
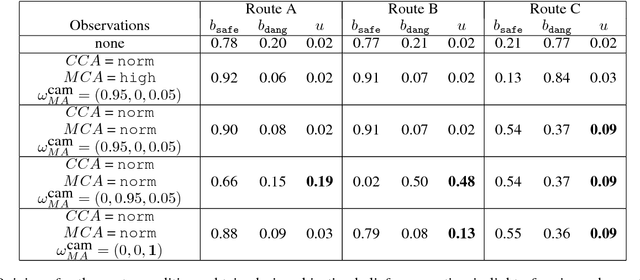
This paper argues the need for research to realize uncertainty-aware artificial intelligence and machine learning (AI\&ML) systems for decision support by describing a number of motivating scenarios. Furthermore, the paper defines uncertainty-awareness and lays out the challenges along with surveying some promising research directions. A theoretical demonstration illustrates how two emerging uncertainty-aware ML and AI technologies could be integrated and be of value for a route planning operation.
AspEm: Embedding Learning by Aspects in Heterogeneous Information Networks
Mar 05, 2018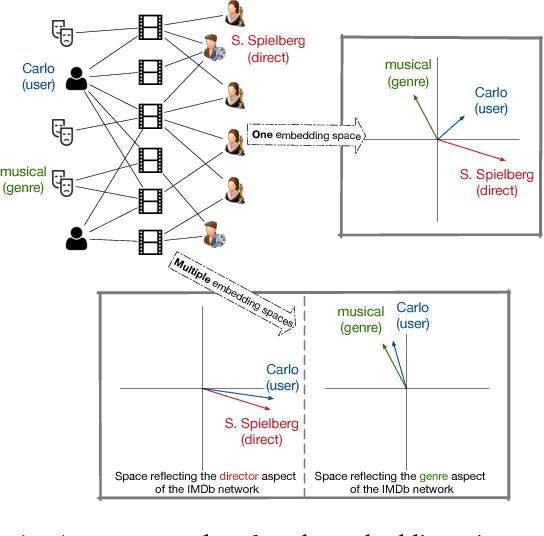
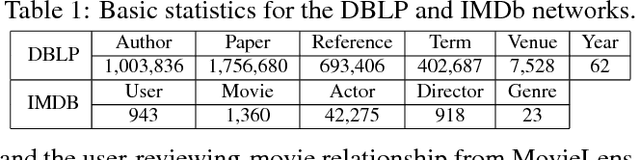
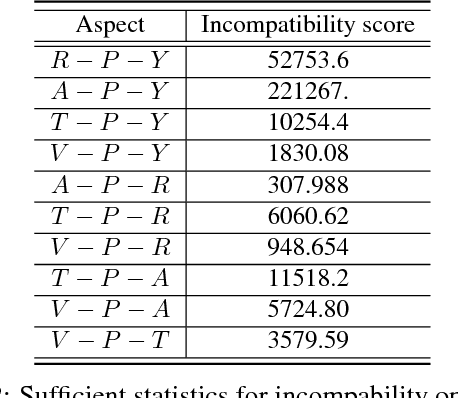
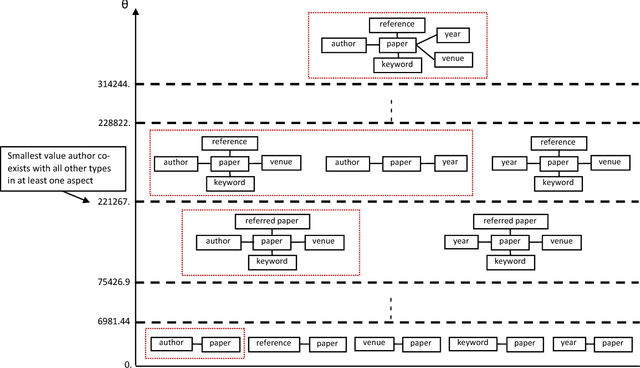
Heterogeneous information networks (HINs) are ubiquitous in real-world applications. Due to the heterogeneity in HINs, the typed edges may not fully align with each other. In order to capture the semantic subtlety, we propose the concept of aspects with each aspect being a unit representing one underlying semantic facet. Meanwhile, network embedding has emerged as a powerful method for learning network representation, where the learned embedding can be used as features in various downstream applications. Therefore, we are motivated to propose a novel embedding learning framework---AspEm---to preserve the semantic information in HINs based on multiple aspects. Instead of preserving information of the network in one semantic space, AspEm encapsulates information regarding each aspect individually. In order to select aspects for embedding purpose, we further devise a solution for AspEm based on dataset-wide statistics. To corroborate the efficacy of AspEm, we conducted experiments on two real-words datasets with two types of applications---classification and link prediction. Experiment results demonstrate that AspEm can outperform baseline network embedding learning methods by considering multiple aspects, where the aspects can be selected from the given HIN in an unsupervised manner.