 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Unconditional Language Models Recover Arbitrary Sentences?
Jul 10, 2019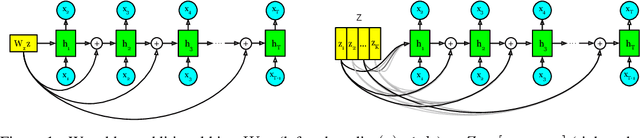
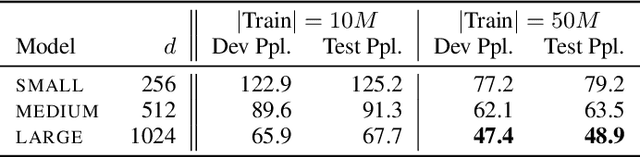
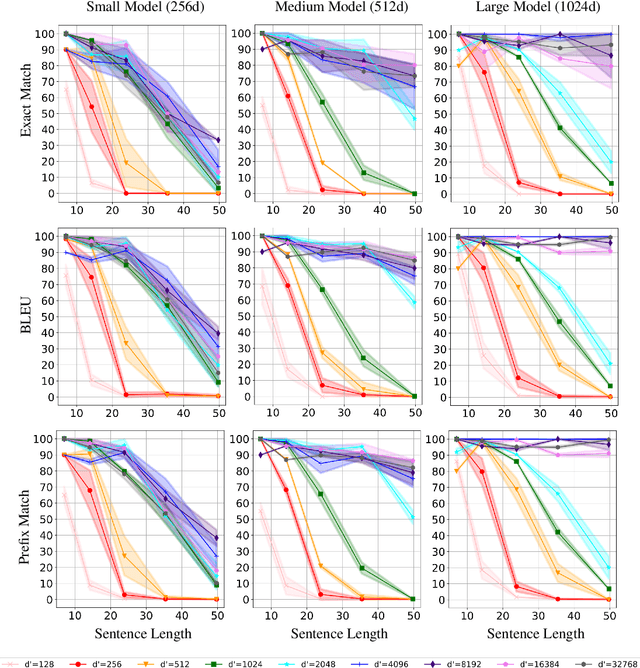
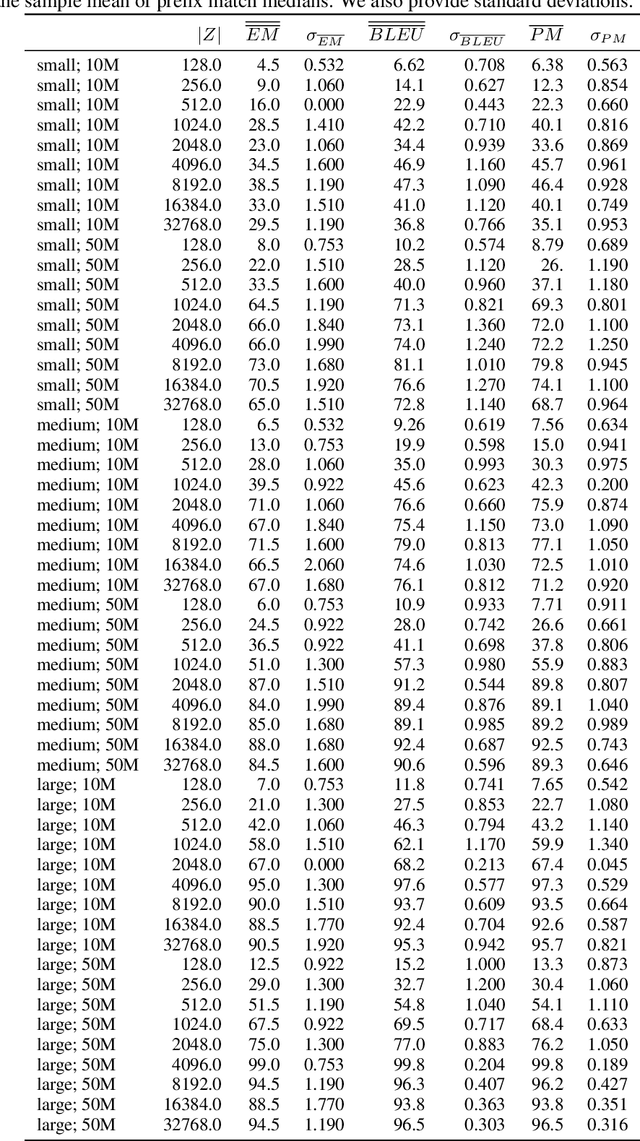
Neural network-based generative language models like ELMo and BERT can work effectively as general purpose sentence encoders in text classification without further fine-tuning. Is it possible to adapt them in a similar way for use as general-purpose decoders? For this to be possible, it would need to be the case that for any target sentence of interest, there is some continuous representation that can be passed to the language model to cause it to reproduce that sentence. We set aside the difficult problem of designing an encoder that can produce such representations and instead ask directly whether such representations exist at all. To do this, we introduce a pair of effective complementary methods for feeding representations into pretrained unconditional language models and a corresponding set of methods to map sentences into and out of this representation space, the \textit{reparametrized sentence space}. We then investigate the conditions under which a language model can be made to generate a sentence through the identification of a point in such a space and find that it is possible to recover arbitrary sentences nearly perfectly with language models and representations of moderate size.
A Unified Framework of Online Learning Algorithms for Training Recurrent Neural Networks
Jul 05, 2019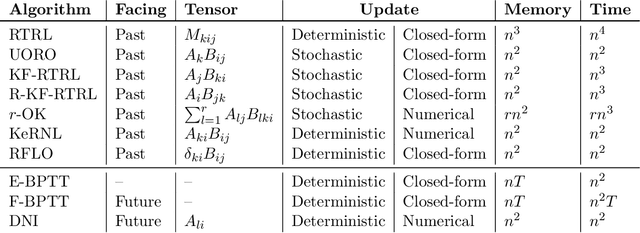
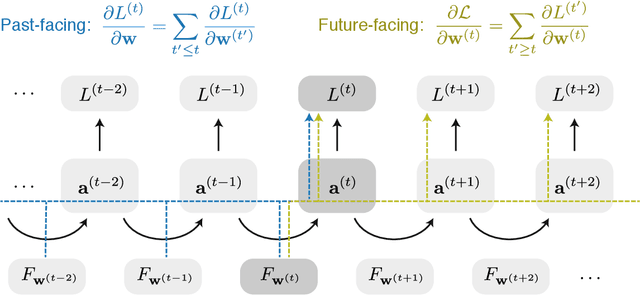
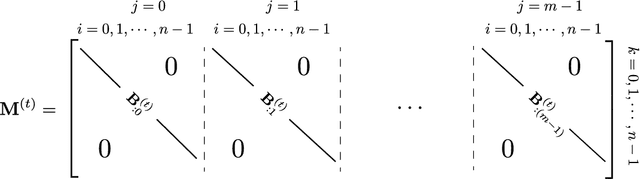
We present a framework for compactly summarizing many recent results in efficient and/or biologically plausible online training of recurrent neural networks (RNN). The framework organizes algorithms according to several criteria: (a) past vs. future facing, (b) tensor structure, (c) stochastic vs. deterministic, and (d) closed form vs. numerical. These axes reveal latent conceptual connections among several recent advances in online learning. Furthermore, we provide novel mathematical intuitions for their degree of success. Testing various algorithms on two synthetic tasks shows that performances cluster according to our criteria. Although a similar clustering is also observed for gradient alignment, alignment with exact methods does not alone explain ultimate performance, especially for stochastic algorithms. This suggests the need for better comparison metrics.
Globally-Aware Multiple Instance Classifier for Breast Cancer Screening
Jun 07, 2019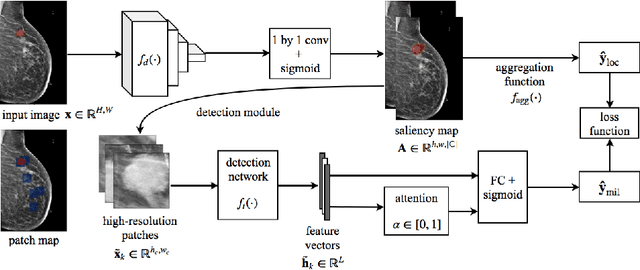
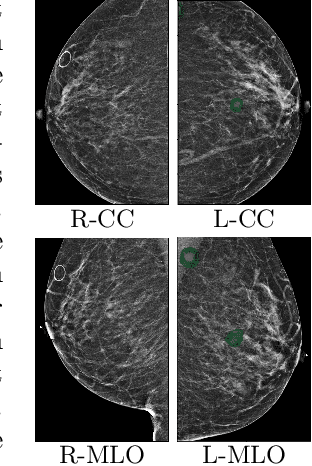
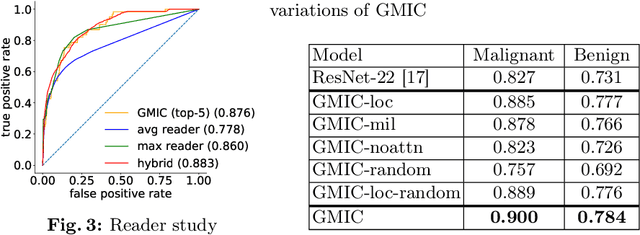
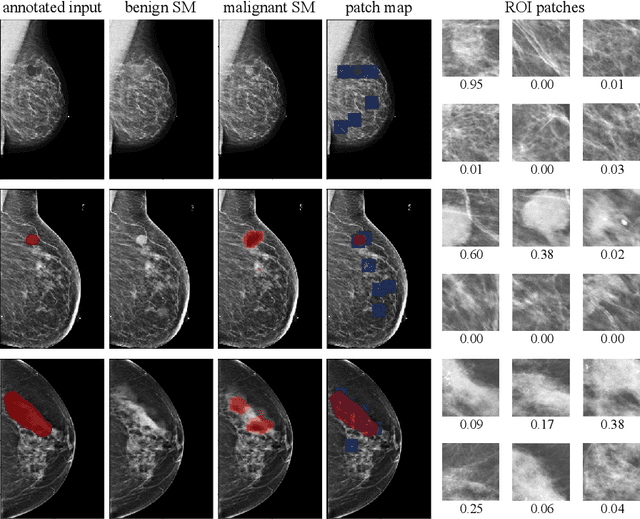
Deep learning models designed for visual classification tasks on natural images have become prevalent in medical image analysis. However, medical images differ from typical natural images in many ways, such as significantly higher resolutions and smaller regions of interest. Moreover, both the global structure and local details play important roles in medical image analysis tasks. To address these unique properties of medical images, we propose a neural network that is able to classify breast cancer lesions utilizing information from both a global saliency map and multiple local patches. The proposed model outperforms the ResNet-based baseline and achieves radiologist-level performance in the interpretation of screening mammography. Although our model is trained only with image-level labels, it is able to generate pixel-level saliency maps that provide localization of possible malignant findings.
Improved Zero-shot Neural Machine Translation via Ignoring Spurious Correlations
Jun 04, 2019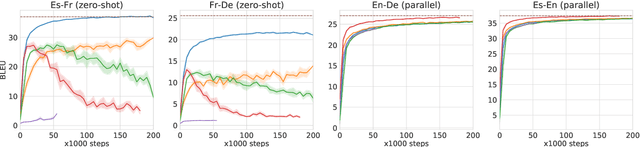

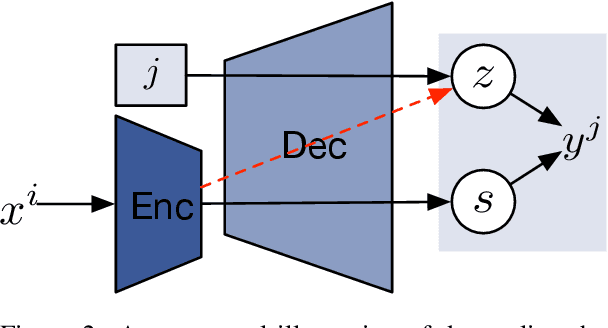
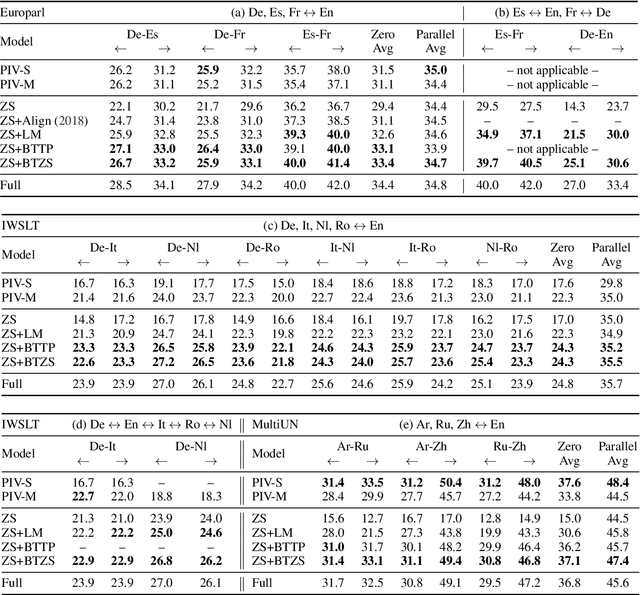
Zero-shot translation, translating between language pairs on which a Neural Machine Translation (NMT) system has never been trained, is an emergent property when training the system in multilingual settings. However, naive training for zero-shot NMT easily fails, and is sensitive to hyper-parameter setting. The performance typically lags far behind the more conventional pivot-based approach which translates twice using a third language as a pivot. In this work, we address the degeneracy problem due to capturing spurious correlations by quantitatively analyzing the mutual information between language IDs of the source and decoded sentences. Inspired by this analysis, we propose to use two simple but effective approaches: (1) decoder pre-training; (2) back-translation. These methods show significant improvement (4~22 BLEU points) over the vanilla zero-shot translation on three challenging multilingual datasets, and achieve similar or better results than the pivot-based approach.
Multi-Turn Beam Search for Neural Dialogue Modeling
Jun 01, 2019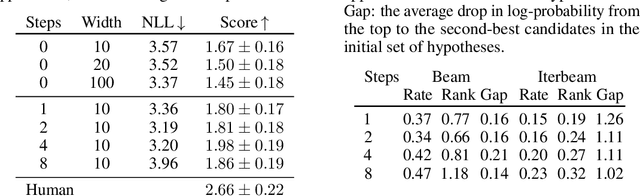
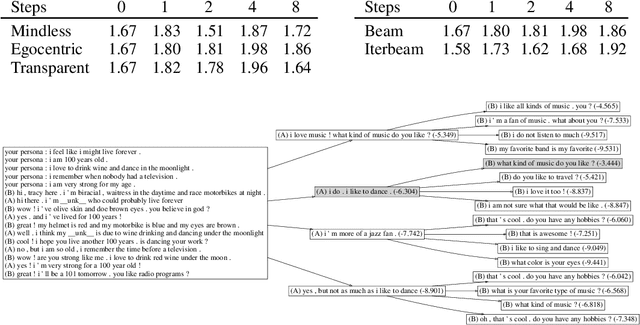
In neural dialogue modeling, a neural network is trained to predict the next utterance, and at inference time, an approximate decoding algorithm is used to generate next utterances given previous ones. While this autoregressive framework allows us to model the whole conversation during training, inference is highly suboptimal, as a wrong utterance can affect future utterances. While beam search yields better results than greedy search does, we argue that it is still greedy in the context of the entire conversation, in that it does not consider future utterances. We propose a novel approach for conversation-level inference by explicitly modeling the dialogue partner and running beam search across multiple conversation turns. Given a set of candidates for next utterance, we unroll the conversation for a number of turns and identify the candidate utterance in the initial hypothesis set that gives rise to the most likely sequence of future utterances. We empirically validate our approach by conducting human evaluation using the Persona-Chat dataset, and find that our multi-turn beam search generates significantly better dialogue responses. We propose three approximations to the partner model, and observe that more informed partner models give better performance.
A Generalized Framework of Sequence Generation with Application to Undirected Sequence Models
May 29, 2019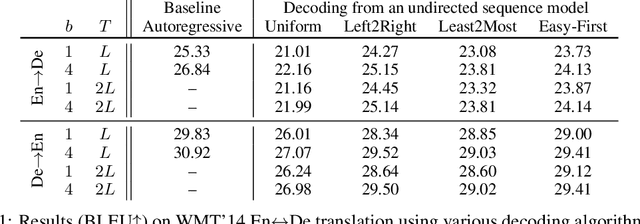
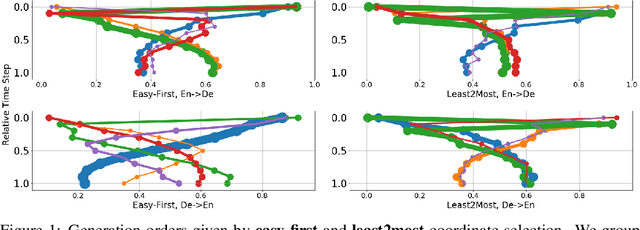
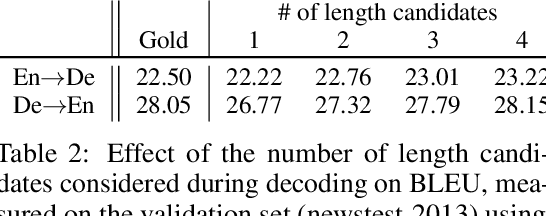
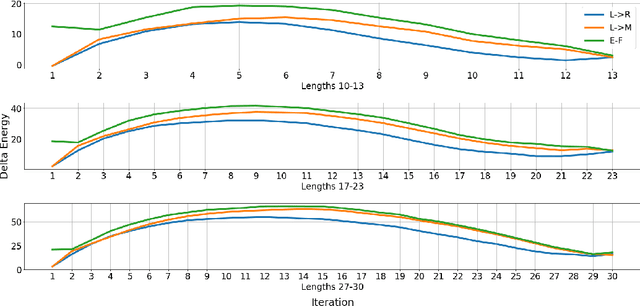
Undirected neural sequence models such as BERT have received renewed interest due to their success on discriminative natural language understanding tasks such as question-answering and natural language inference. The problem of generating sequences directly from these models has received relatively little attention, in part because generating from such models departs significantly from the conventional approach of monotonic generation in directed sequence models. We investigate this problem by first proposing a generalized model of sequence generation that unifies decoding in directed and undirected models. The proposed framework models the process of generation rather than a resulting sequence, and under this framework, we derive various neural sequence models as special cases, such as autoregressive, semi-autoregressive, and refinement-based non-autoregressive models. This unification enables us to adapt decoding algorithms originally developed for directed sequence models to undirected models. We demonstrate this by evaluating various decoding strategies for the recently proposed cross-lingual masked translation model. Our experiments reveal that generation from undirected sequence models, under our framework, is competitive against the state of the art on WMT'14 English-German translation. We furthermore observe that the proposed approach enables constant-time translation while losing only 1 BLEU score compared to linear-time translation from the same undirected neural sequence model.
Using local plasticity rules to train recurrent neural networks
May 28, 2019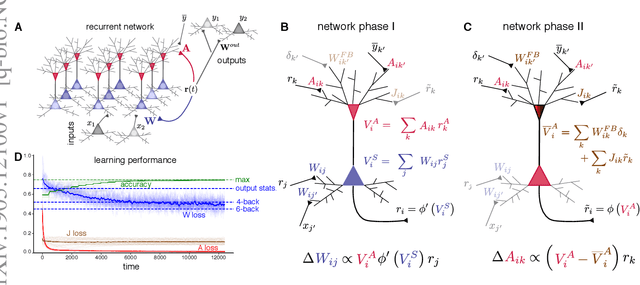
To learn useful dynamics on long time scales, neurons must use plasticity rules that account for long-term, circuit-wide effects of synaptic changes. In other words, neural circuits must solve a credit assignment problem to appropriately assign responsibility for global network behavior to individual circuit components. Furthermore, biological constraints demand that plasticity rules are spatially and temporally local; that is, synaptic changes can depend only on variables accessible to the pre- and postsynaptic neurons. While artificial intelligence offers a computational solution for credit assignment, namely backpropagation through time (BPTT), this solution is wildly biologically implausible. It requires both nonlocal computations and unlimited memory capacity, as any synaptic change is a complicated function of the entire history of network activity. Similar nonlocality issues plague other approaches such as FORCE (Sussillo et al. 2009). Overall, we are still missing a model for learning in recurrent circuits that both works computationally and uses only local updates. Leveraging recent advances in machine learning on approximating gradients for BPTT, we derive biologically plausible plasticity rules that enable recurrent networks to accurately learn long-term dependencies in sequential data. The solution takes the form of neurons with segregated voltage compartments, with several synaptic sub-populations that have different functional properties. The network operates in distinct phases during which each synaptic sub-population is updated by its own local plasticity rule. Our results provide new insights into the potential roles of segregated dendritic compartments, branch-specific inhibition, and global circuit phases in learning.
Sequential Graph Dependency Parser
May 27, 2019
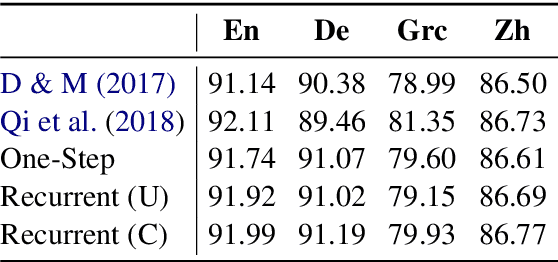
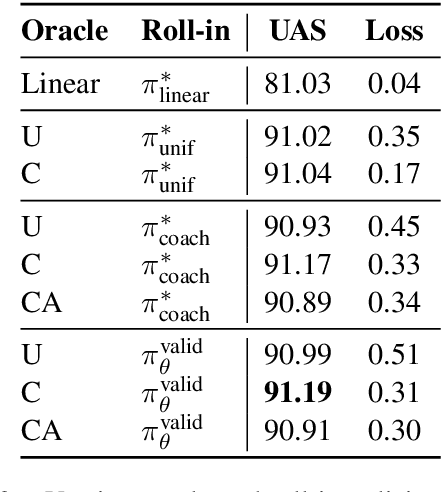

We propose a method for non-projective dependency parsing by incrementally predicting a set of edges. Since the edges do not have a pre-specified order, we propose a set-based learning method. Our method blends graph, transition, and easy-first parsing, including a prior state of the parser as a special case. The proposed transition-based method successfully parses near the state of the art on both projective and non-projective languages, without assuming a certain parsing order.
Automatic Machine Learning by Pipeline Synthesis using Model-Based Reinforcement Learning and a Grammar
May 24, 2019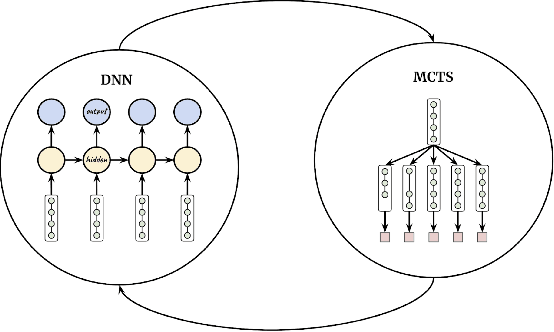

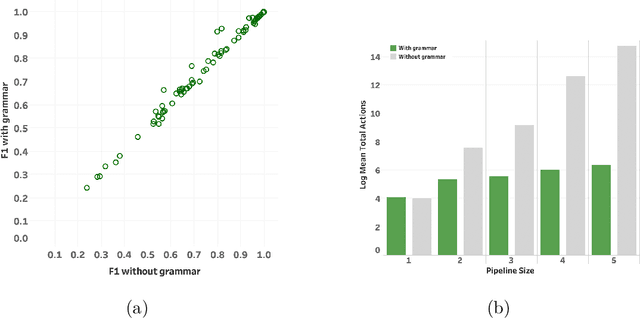
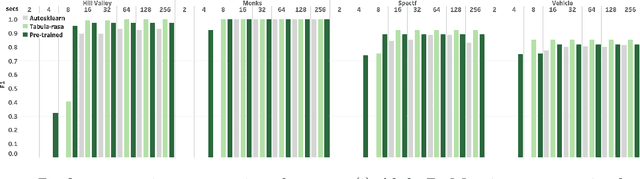
Automatic machine learning is an important problem in the forefront of machine learning. The strongest AutoML systems are based on neural networks, evolutionary algorithms, and Bayesian optimization. Recently AlphaD3M reached state-of-the-art results with an order of magnitude speedup using reinforcement learning with self-play. In this work we extend AlphaD3M by using a pipeline grammar and a pre-trained model which generalizes from many different datasets and similar tasks. Our results demonstrate improved performance compared with our earlier work and existing methods on AutoML benchmark datasets for classification and regression tasks. In the spirit of reproducible research we make our data, models, and code publicly available.
Task-Driven Data Verification via Gradient Descent
May 14, 2019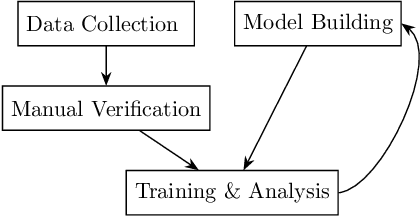
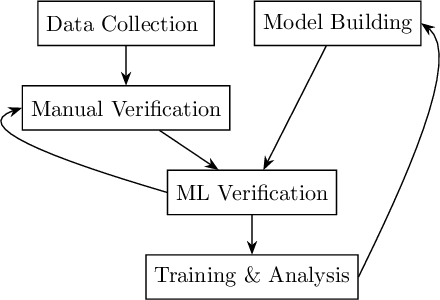
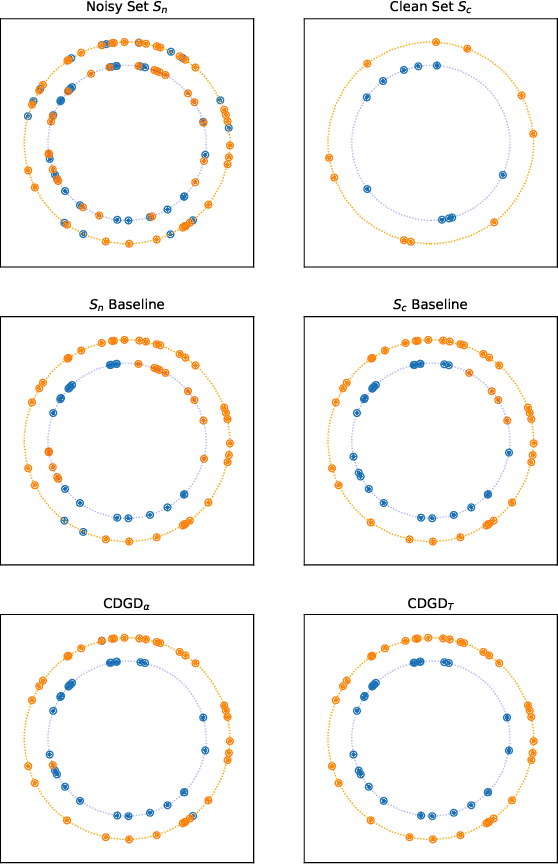
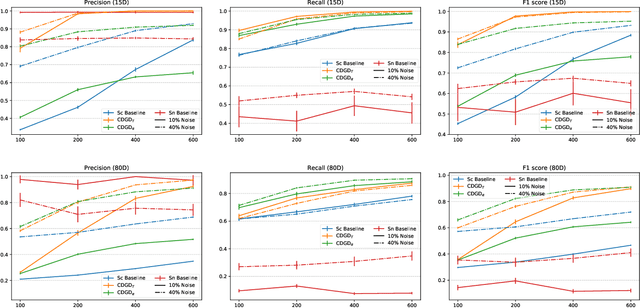
We introduce a novel algorithm for the detection of possible sample corruption such as mislabeled samples in a training dataset given a small clean validation set. We use a set of inclusion variables which determine whether or not any element of the noisy training set should be included in the training of a network. We compute these inclusion variables by optimizing the performance of the network on the clean validation set via "gradient descent on gradient descent" based learning. The inclusion variables as well as the network trained in such a way form the basis of our methods, which we call Corruption Detection via Gradient Descent (CDGD). This algorithm can be applied to any supervised machine learning task and is not limited to classification problems. We provide a quantitative comparison of these methods on synthetic and real world datasets.