 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovidex: Neural Ranking Models and Keyword Search Infrastructure for the COVID-19 Open Research Dataset
Jul 14, 2020
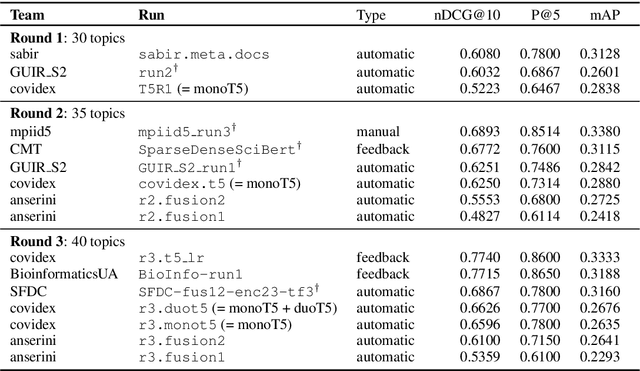
We present Covidex, a search engine that exploits the latest neural ranking models to provide information access to the COVID-19 Open Research Dataset curated by the Allen Institute for AI. Our system has been online and serving users since late March 2020. The Covidex is the user application component of our three-pronged strategy to develop technologies for helping domain experts tackle the ongoing global pandemic. In addition, we provide robust and easy-to-use keyword search infrastructure that exploits mature fusion-based methods as well as standalone neural ranking models that can be incorporated into other applications. These techniques have been evaluated in the ongoing TREC-COVID challenge: Our infrastructure and baselines have been adopted by many participants, including some of the highest-scoring runs in rounds 1, 2, and 3. In round 3, we report the highest-scoring run that takes advantage of previous training data and the second-highest fully automatic run.
MLE-guided parameter search for task loss minimization in neural sequence modeling
Jun 04, 2020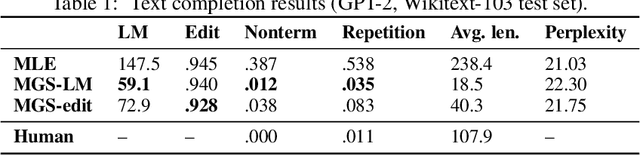
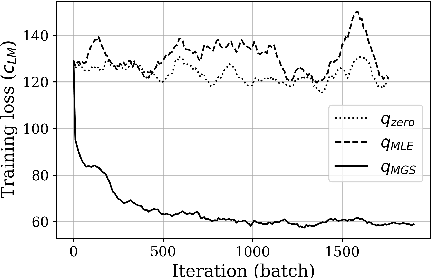


Neural autoregressive sequence models are used to generate sequences in a variety of natural language processing (NLP) tasks, where they are evaluated according to sequence-level task losses. These models are typically trained with maximum likelihood estimation, which ignores the task loss, yet empirically performs well as a surrogate objective. Typical approaches to directly optimizing the task loss such as policy gradient and minimum risk training are based around sampling in the sequence space to obtain candidate update directions that are scored based on the loss of a single sequence. In this paper, we develop an alternative method based on random search in the parameter space that leverages access to the maximum likelihood gradient. We propose maximum likelihood guided parameter search (MGS), which samples from a distribution over update directions that is a mixture of random search around the current parameters and around the maximum likelihood gradient, with each direction weighted by its improvement in the task loss. MGS shifts sampling to the parameter space, and scores candidates using losses that are pooled from multiple sequences. Our experiments show that MGS is capable of optimizing sequence-level losses, with substantial reductions in repetition and non-termination in sequence completion, and similar improvements to those of minimum risk training in machine translation.
AdapterFusion: Non-Destructive Task Composition for Transfer Learning
May 01, 2020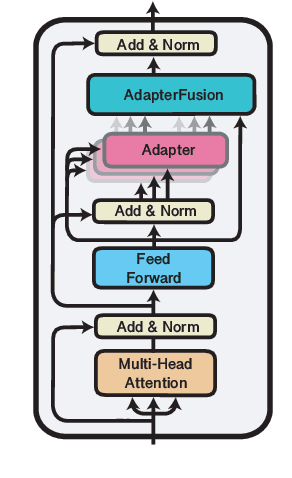
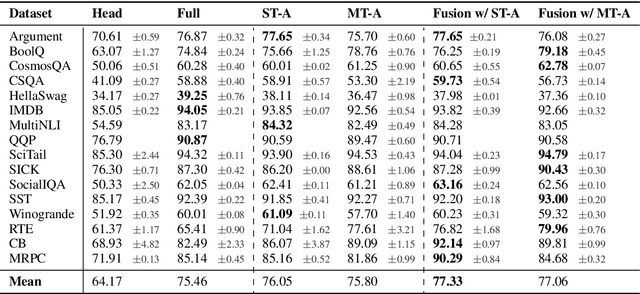
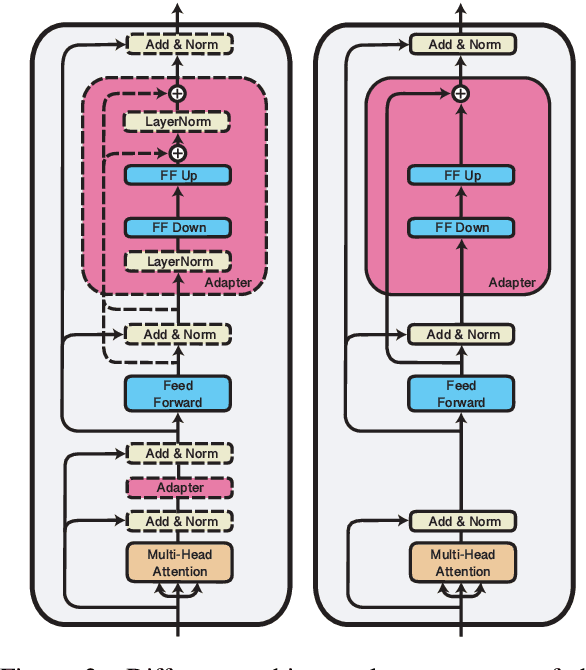
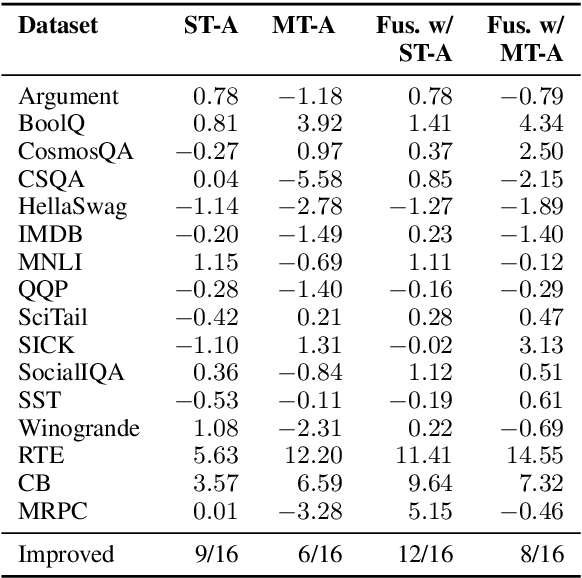
Current approaches to solving classification tasks in NLP involve fine-tuning a pre-trained language model on a single target task. This paper focuses on sharing knowledge extracted not only from a pre-trained language model, but also from several source tasks in order to achieve better performance on the target task. Sequential fine-tuning and multi-task learning are two methods for sharing information, but suffer from problems such as catastrophic forgetting and difficulties in balancing multiple tasks. Additionally, multi-task learning requires simultaneous access to data used for each of the tasks, which does not allow for easy extensions to new tasks on the fly. We propose a new architecture as well as a two-stage learning algorithm that allows us to effectively share knowledge from multiple tasks while avoiding these crucial problems. In the first stage, we learn task specific parameters that encapsulate the knowledge from each task. We then combine these learned representations in a separate combination step, termed AdapterFusion. We show that by separating the two stages, i.e., knowledge extraction and knowledge combination, the classifier can effectively exploit the representations learned from multiple tasks in a non destructive manner. We empirically evaluate our transfer learning approach on 16 diverse NLP tasks, and show that it outperforms traditional strategies such as full fine-tuning of the model as well as multi-task learning.
Learning Non-Monotonic Automatic Post-Editing of Translations from Human Orderings
Apr 29, 2020
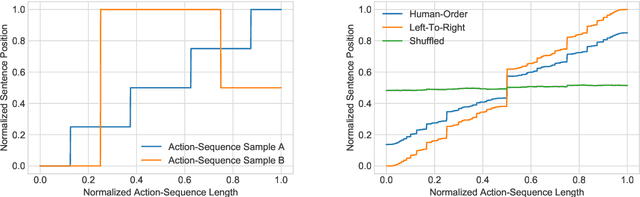
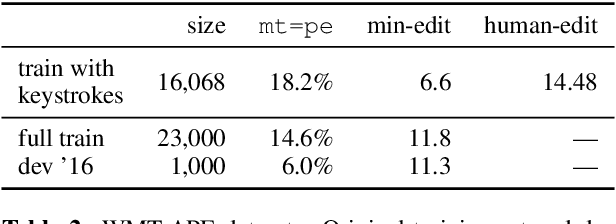
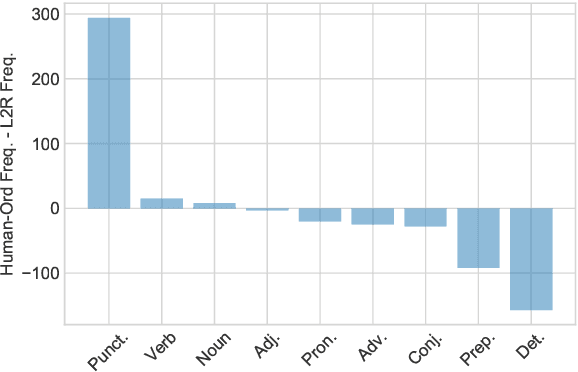
Recent research in neural machine translation has explored flexible generation orders, as an alternative to left-to-right generation. However, training non-monotonic models brings a new complication: how to search for a good ordering when there is a combinatorial explosion of orderings arriving at the same final result? Also, how do these automatic orderings compare with the actual behaviour of human translators? Current models rely on manually built biases or are left to explore all possibilities on their own. In this paper, we analyze the orderings produced by human post-editors and use them to train an automatic post-editing system. We compare the resulting system with those trained with left-to-right and random post-editing orderings. We observe that humans tend to follow a nearly left-to-right order, but with interesting deviations, such as preferring to start by correcting punctuation or verbs.
Learning to Learn Morphological Inflection for Resource-Poor Languages
Apr 28, 2020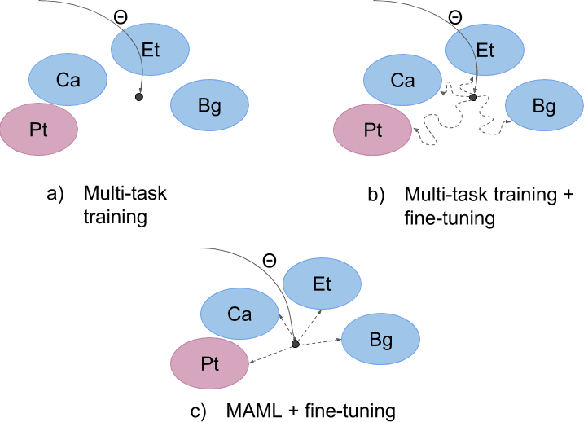
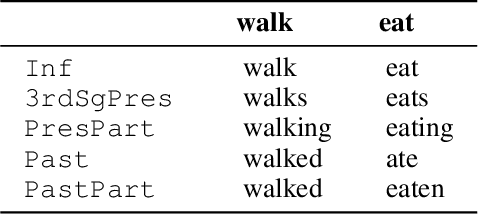
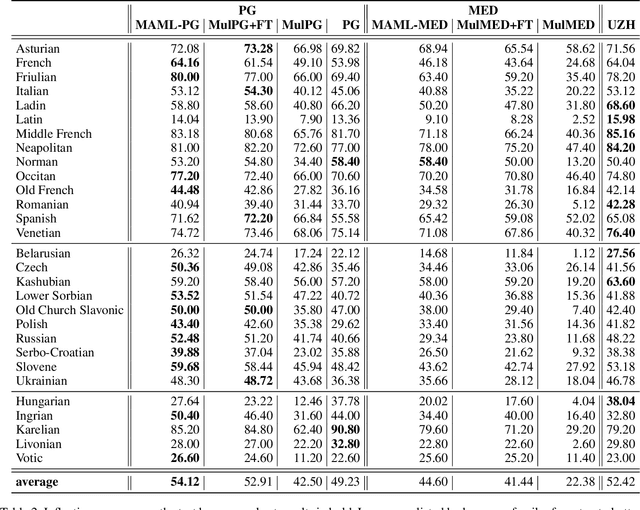
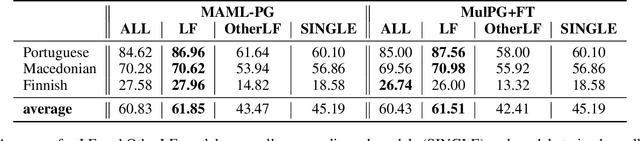
We propose to cast the task of morphological inflection - mapping a lemma to an indicated inflected form - for resource-poor languages as a meta-learning problem. Treating each language as a separate task, we use data from high-resource source languages to learn a set of model parameters that can serve as a strong initialization point for fine-tuning on a resource-poor target language. Experiments with two model architectures on 29 target languages from 3 families show that our suggested approach outperforms all baselines. In particular, it obtains a 31.7% higher absolute accuracy than a previously proposed cross-lingual transfer model and outperforms the previous state of the art by 1.7% absolute accuracy on average over languages.
Rapidly Bootstrapping a Question Answering Dataset for COVID-19
Apr 23, 2020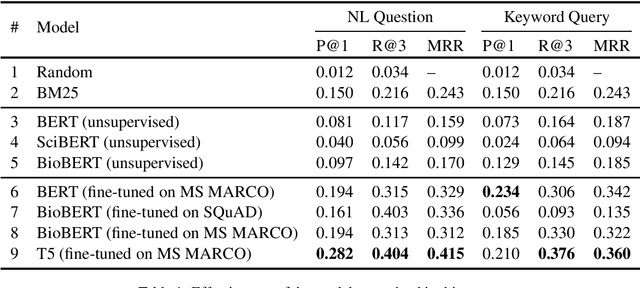
We present CovidQA, the beginnings of a question answering dataset specifically designed for COVID-19, built by hand from knowledge gathered from Kaggle's COVID-19 Open Research Dataset Challenge. To our knowledge, this is the first publicly available resource of its type, and intended as a stopgap measure for guiding research until more substantial evaluation resources become available. While this dataset, comprising 124 question-article pairs as of the present version 0.1 release, does not have sufficient examples for supervised machine learning, we believe that it can be helpful for evaluating the zero-shot or transfer capabilities of existing models on topics specifically related to COVID-19. This paper describes our methodology for constructing the dataset and presents the effectiveness of a number of baselines, including term-based techniques and various transformer-based models. The dataset is available at http://covidqa.ai/
Rapidly Deploying a Neural Search Engine for the COVID-19 Open Research Dataset: Preliminary Thoughts and Lessons Learned
Apr 10, 2020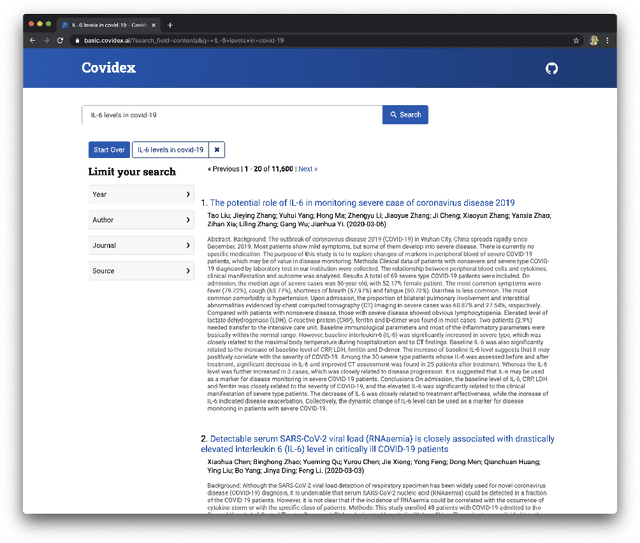
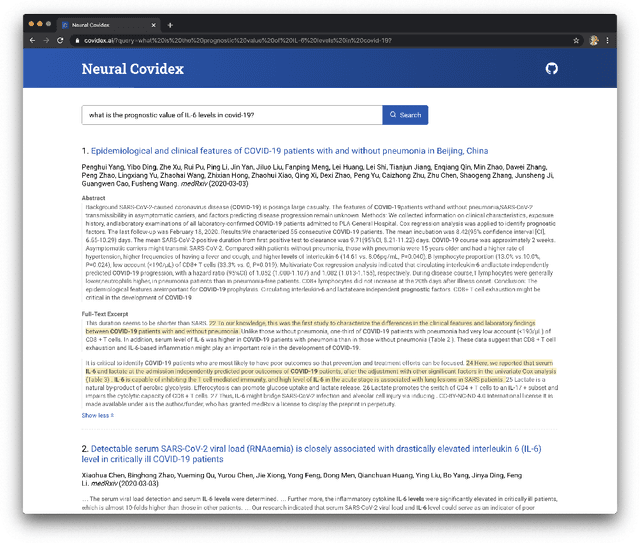
We present the Neural Covidex, a search engine that exploits the latest neural ranking architectures to provide information access to the COVID-19 Open Research Dataset curated by the Allen Institute for AI. This web application exists as part of a suite of tools that we have developed over the past few weeks to help domain experts tackle the ongoing global pandemic. We hope that improved information access capabilities to the scientific literature can inform evidence-based decision making and insight generation. This paper describes our initial efforts and offers a few thoughts about lessons we have learned along the way.
Asking and Answering Questions to Evaluate the Factual Consistency of Summaries
Apr 08, 2020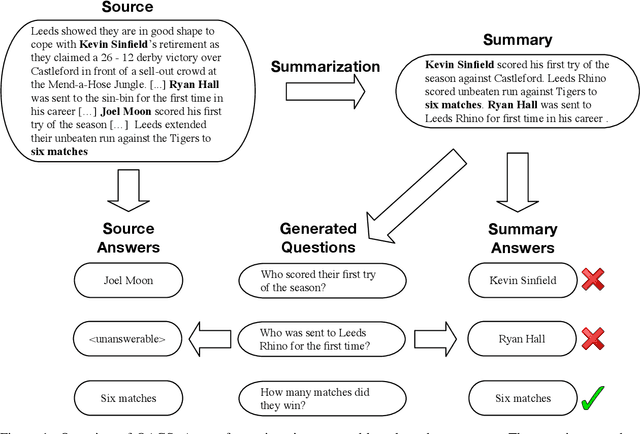
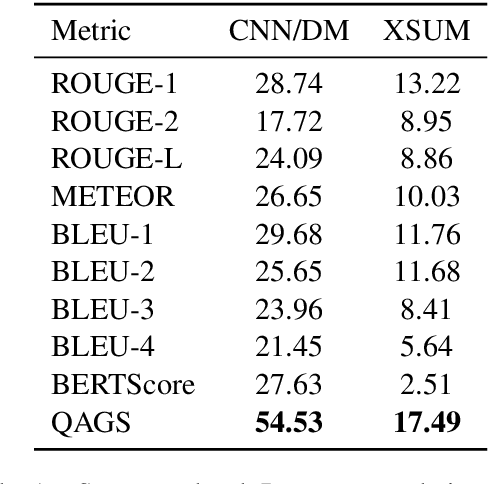
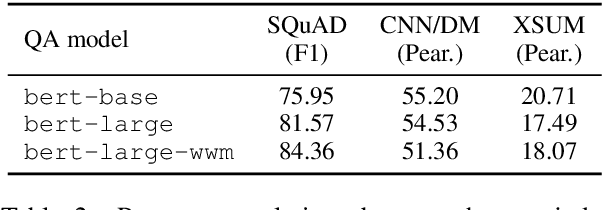

Practical applications of abstractive summarization models are limited by frequent factual inconsistencies with respect to their input. Existing automatic evaluation metrics for summarization are largely insensitive to such errors. We propose an automatic evaluation protocol called QAGS (pronounced "kags") that is designed to identify factual inconsistencies in a generated summary. QAGS is based on the intuition that if we ask questions about a summary and its source, we will receive similar answers if the summary is factually consistent with the source. To evaluate QAGS, we collect human judgments of factual consistency on model-generated summaries for the CNN/DailyMail (Hermann et al., 2015) and XSUM (Narayan et al., 2018) summarization datasets. QAGS has substantially higher correlations with these judgments than other automatic evaluation metrics. Also, QAGS offers a natural form of interpretability: The answers and questions generated while computing QAGS indicate which tokens of a summary are inconsistent and why. We believe QAGS is a promising tool in automatically generating usable and factually consistent text.
Understanding the robustness of deep neural network classifiers for breast cancer screening
Mar 23, 2020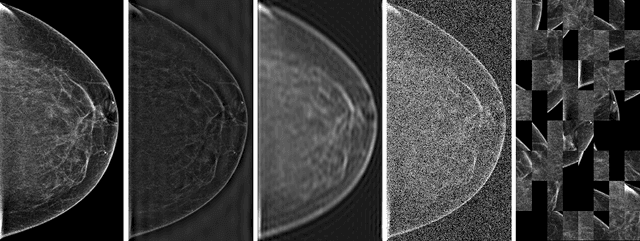

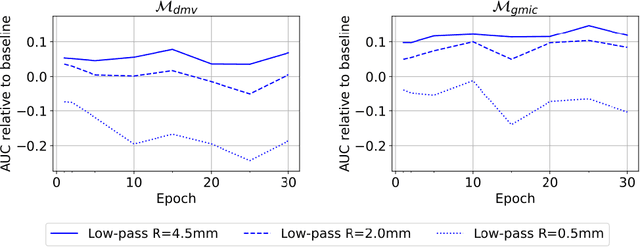
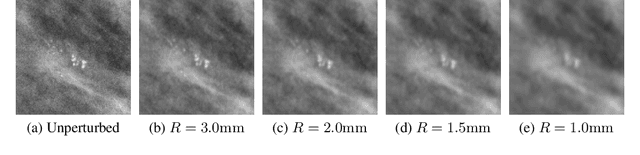
Deep neural networks (DNNs) show promise in breast cancer screening, but their robustness to input perturbations must be better understood before they can be clinically implemented. There exists extensive literature on this subject in the context of natural images that can potentially be built upon. However, it cannot be assumed that conclusions about robustness will transfer from natural images to mammogram images, due to significant differences between the two image modalities. In order to determine whether conclusions will transfer, we measure the sensitivity of a radiologist-level screening mammogram image classifier to four commonly studied input perturbations that natural image classifiers are sensitive to. We find that mammogram image classifiers are also sensitive to these perturbations, which suggests that we can build on the existing literature. We also perform a detailed analysis on the effects of low-pass filtering, and find that it degrades the visibility of clinically meaningful features called microcalcifications. Since low-pass filtering removes semantically meaningful information that is predictive of breast cancer, we argue that it is undesirable for mammogram image classifiers to be invariant to it. This is in contrast to natural images, where we do not want DNNs to be sensitive to low-pass filtering due to its tendency to remove information that is human-incomprehensible.
Unsupervised Question Decomposition for Question Answering
Feb 22, 2020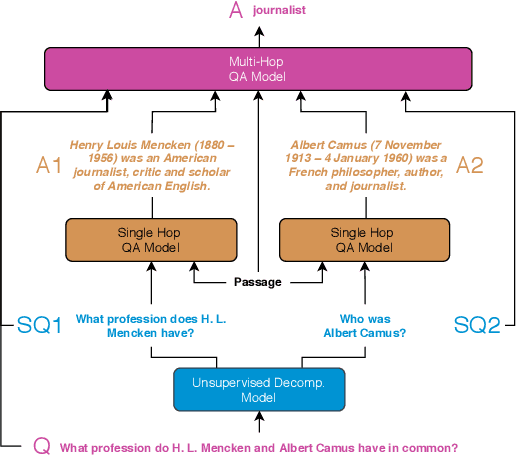
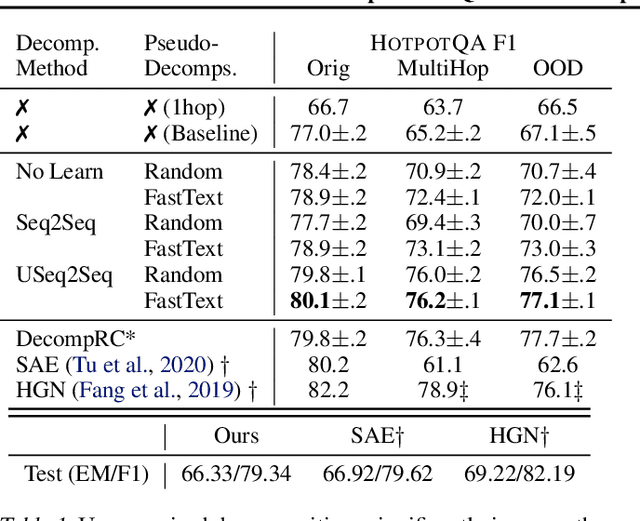
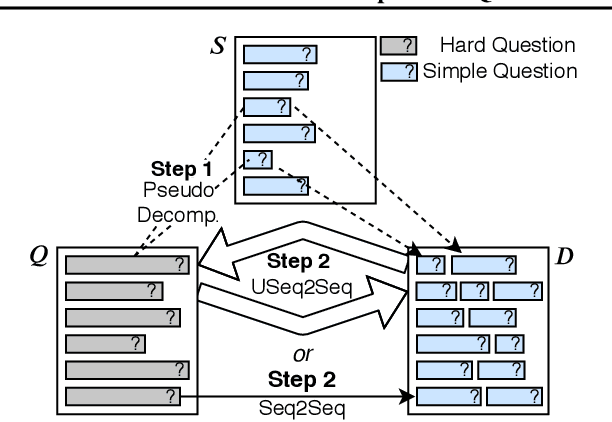

We aim to improve question answering (QA) by decomposing hard questions into easier sub-questions that existing QA systems can answer. Since collecting labeled decompositions is cumbersome, we propose an unsupervised approach to produce sub-questions. Specifically, by leveraging >10M questions from Common Crawl, we learn to map from the distribution of multi-hop questions to the distribution of single-hop sub-questions. We answer sub-questions with an off-the-shelf QA model and incorporate the resulting answers in a downstream, multi-hop QA system. On a popular multi-hop QA dataset, HotpotQA, we show large improvements over a strong baseline, especially on adversarial and out-of-domain questions. Our method is generally applicable and automatically learns to decompose questions of different classes, while matching the performance of decomposition methods that rely heavily on hand-engineering and annotation.