 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models that Seek for Knowledge: Modular Search & Generation for Dialogue and Prompt Completion
Mar 29, 2022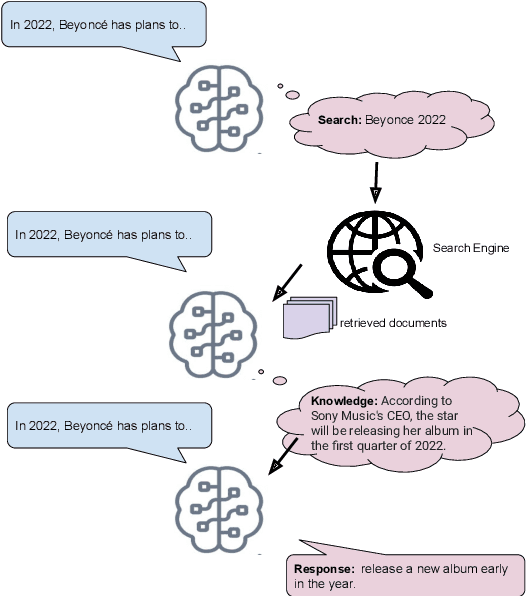

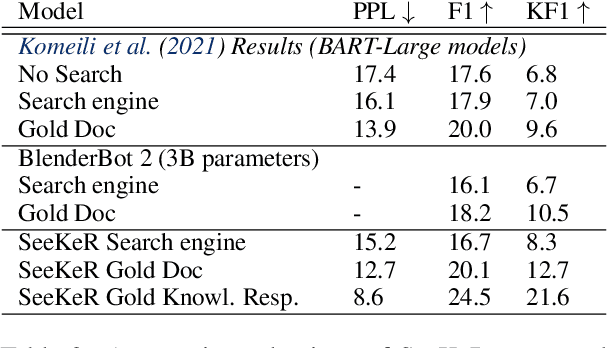

Language models (LMs) have recently been shown to generate more factual responses by employing modularity (Zhou et al., 2021) in combination with retrieval (Adolphs et al., 2021). We extend the recent approach of Adolphs et al. (2021) to include internet search as a module. Our SeeKeR (Search engine->Knowledge->Response) method thus applies a single LM to three modular tasks in succession: search, generating knowledge, and generating a final response. We show that, when using SeeKeR as a dialogue model, it outperforms the state-of-the-art model BlenderBot 2 (Chen et al., 2021) on open-domain knowledge-grounded conversations for the same number of parameters, in terms of consistency, knowledge and per-turn engagingness. SeeKeR applied to topical prompt completions as a standard language model outperforms GPT2 (Radford et al., 2019) and GPT3 (Brown et al., 2020) in terms of factuality and topicality, despite GPT3 being a vastly larger model. Our code and models are made publicly available.
Am I Me or You? State-of-the-Art Dialogue Models Cannot Maintain an Identity
Dec 10, 2021
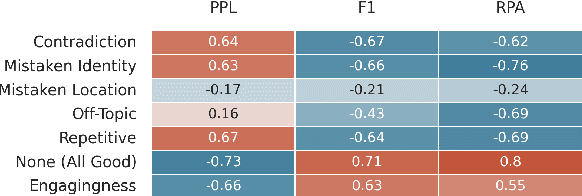
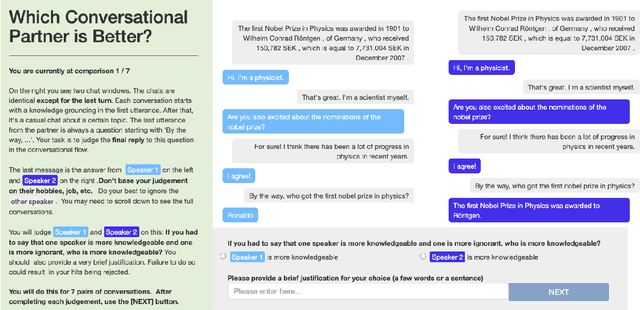
State-of-the-art dialogue models still often stumble with regards to factual accuracy and self-contradiction. Anecdotally, they have been observed to fail to maintain character identity throughout discourse; and more specifically, may take on the role of their interlocutor. In this work we formalize and quantify this deficiency, and show experimentally through human evaluations that this is indeed a problem. In contrast, we show that discriminative models trained specifically to recognize who is speaking can perform well; and further, these can be used as automated metrics. Finally, we evaluate a wide variety of mitigation methods, including changes to model architecture, training protocol, and decoding strategy. Our best models reduce mistaken identity issues by nearly 65% according to human annotators, while simultaneously improving engagingness. Despite these results, we find that maintaining character identity still remains a challenging problem.
Reason first, then respond: Modular Generation for Knowledge-infused Dialogue
Nov 09, 2021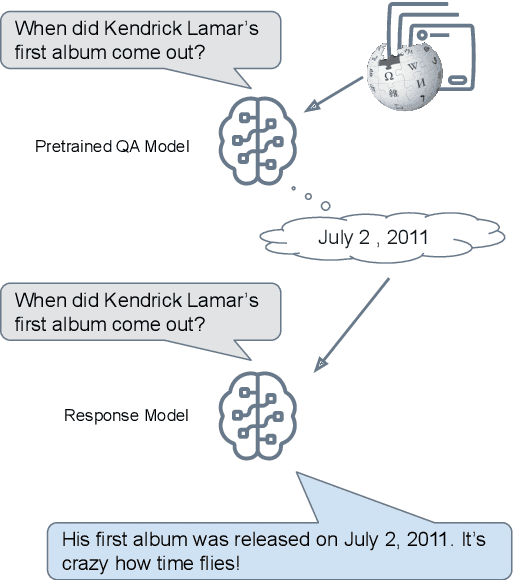
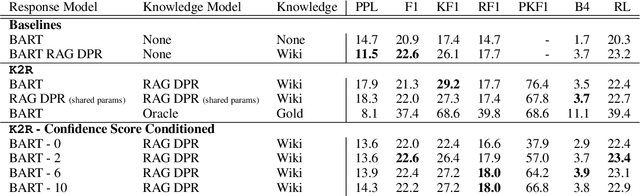

Large language models can produce fluent dialogue but often hallucinate factual inaccuracies. While retrieval-augmented models help alleviate this issue, they still face a difficult challenge of both reasoning to provide correct knowledge and generating conversation simultaneously. In this work, we propose a modular model, Knowledge to Response (K2R), for incorporating knowledge into conversational agents, which breaks down this problem into two easier steps. K2R first generates a knowledge sequence, given a dialogue context, as an intermediate step. After this "reasoning step", the model then attends to its own generated knowledge sequence, as well as the dialogue context, to produce a final response. In detailed experiments, we find that such a model hallucinates less in knowledge-grounded dialogue tasks, and has advantages in terms of interpretability and modularity. In particular, it can be used to fuse QA and dialogue systems together to enable dialogue agents to give knowledgeable answers, or QA models to give conversational responses in a zero-shot setting.
Internet-Augmented Dialogue Generation
Jul 15, 2021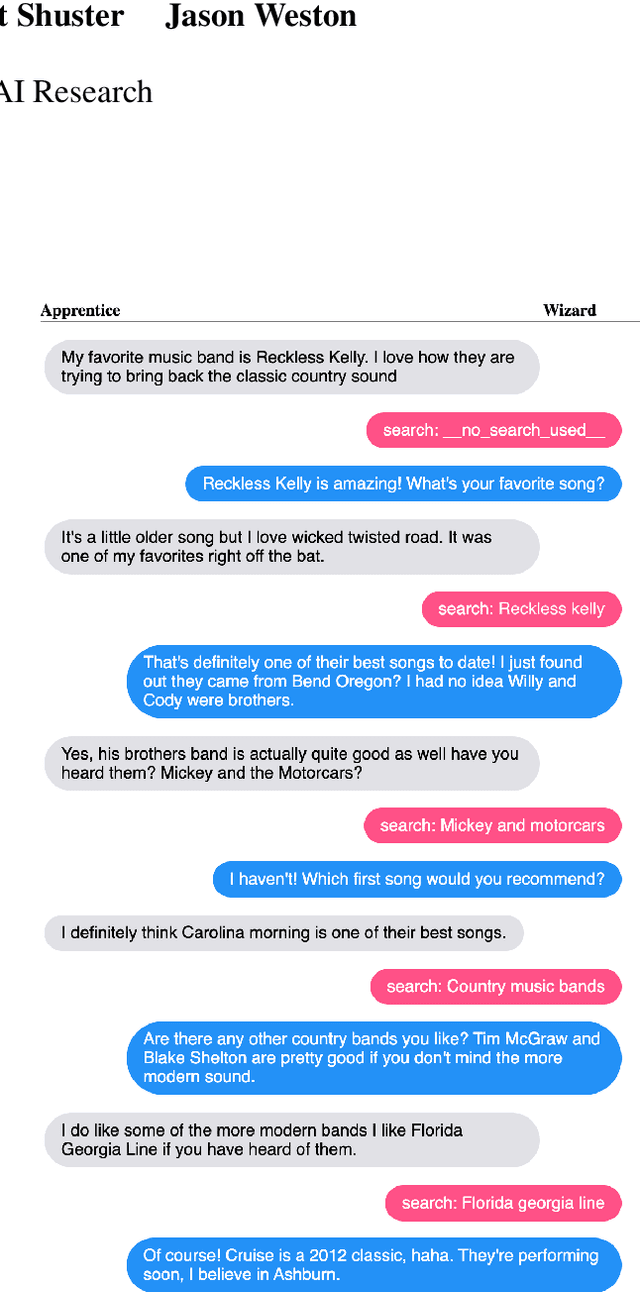
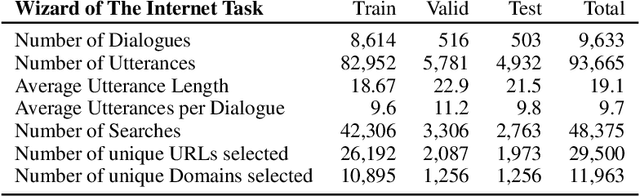
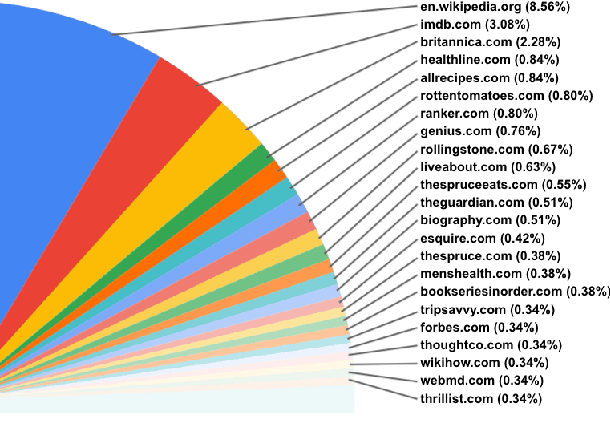
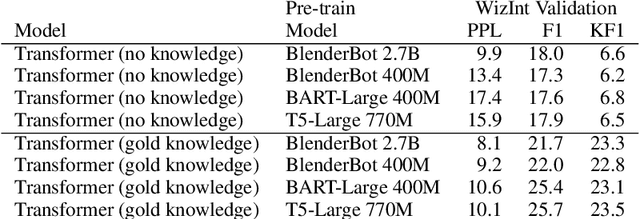
The largest store of continually updating knowledge on our planet can be accessed via internet search. In this work we study giving access to this information to conversational agents. Large language models, even though they store an impressive amount of knowledge within their weights, are known to hallucinate facts when generating dialogue (Shuster et al., 2021); moreover, those facts are frozen in time at the point of model training. In contrast, we propose an approach that learns to generate an internet search query based on the context, and then conditions on the search results to finally generate a response, a method that can employ up-to-the-minute relevant information. We train and evaluate such models on a newly collected dataset of human-human conversations whereby one of the speakers is given access to internet search during knowledgedriven discussions in order to ground their responses. We find that search-query based access of the internet in conversation provides superior performance compared to existing approaches that either use no augmentation or FAISS-based retrieval (Lewis et al., 2020).
Retrieval Augmentation Reduces Hallucination in Conversation
Apr 15, 2021
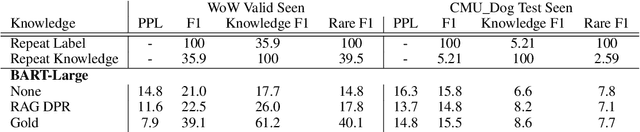
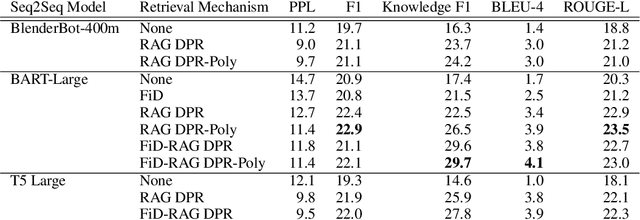
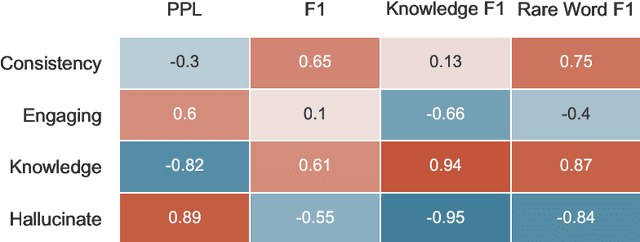
Despite showing increasingly human-like conversational abilities, state-of-the-art dialogue models often suffer from factual incorrectness and hallucination of knowledge (Roller et al., 2020). In this work we explore the use of neural-retrieval-in-the-loop architectures - recently shown to be effective in open-domain QA (Lewis et al., 2020b; Izacard and Grave, 2020) - for knowledge-grounded dialogue, a task that is arguably more challenging as it requires querying based on complex multi-turn dialogue context and generating conversationally coherent responses. We study various types of architectures with multiple components - retrievers, rankers, and encoder-decoders - with the goal of maximizing knowledgeability while retaining conversational ability. We demonstrate that our best models obtain state-of-the-art performance on two knowledge-grounded conversational tasks. The models exhibit open-domain conversational capabilities, generalize effectively to scenarios not within the training data, and, as verified by human evaluations, substantially reduce the well-known problem of knowledge hallucination in state-of-the-art chatbots.
Multi-Modal Open-Domain Dialogue
Oct 02, 2020
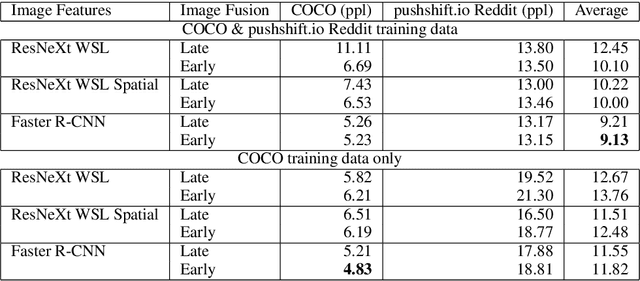
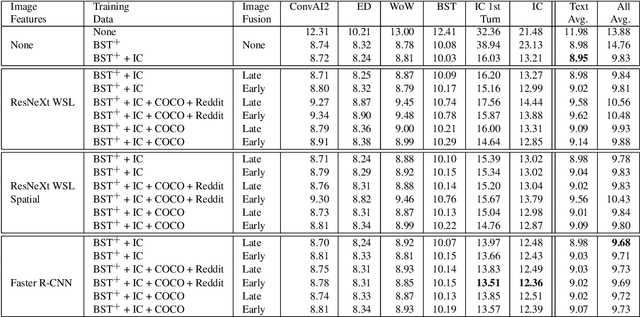

Recent work in open-domain conversational agents has demonstrated that significant improvements in model engagingness and humanness metrics can be achieved via massive scaling in both pre-training data and model size (Adiwardana et al., 2020; Roller et al., 2020). However, if we want to build agents with human-like abilities, we must expand beyond handling just text. A particularly important topic is the ability to see images and communicate about what is perceived. With the goal of engaging humans in multi-modal dialogue, we investigate combining components from state-of-the-art open-domain dialogue agents with those from state-of-the-art vision models. We study incorporating different image fusion schemes and domain-adaptive pre-training and fine-tuning strategies, and show that our best resulting model outperforms strong existing models in multi-modal dialogue while simultaneously performing as well as its predecessor (text-only) BlenderBot (Roller et al., 2020) in text-based conversation. We additionally investigate and incorporate safety components in our final model, and show that such efforts do not diminish model performance with respect to engagingness metrics.
Deploying Lifelong Open-Domain Dialogue Learning
Aug 19, 2020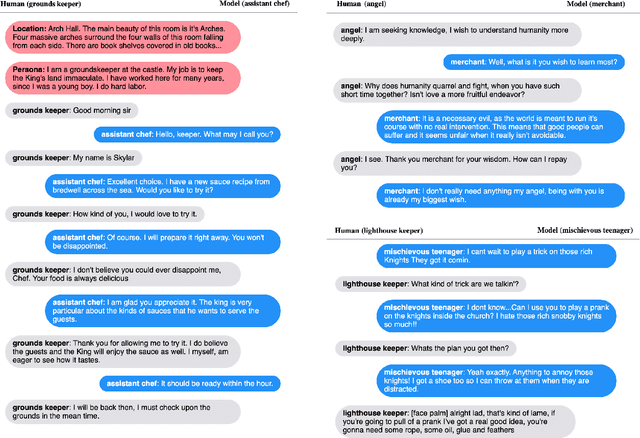

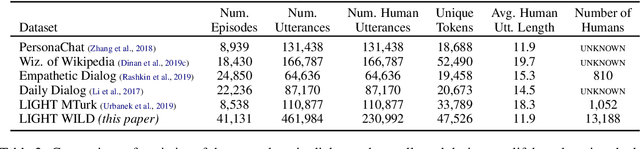
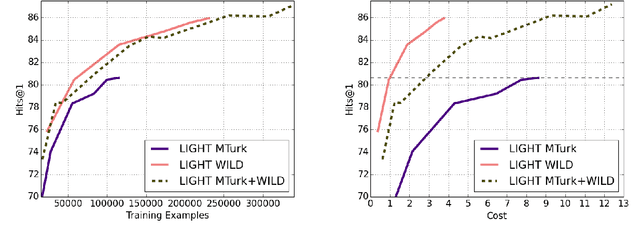
Much of NLP research has focused on crowdsourced static datasets and the supervised learning paradigm of training once and then evaluating test performance. As argued in de Vries et al. (2020), crowdsourced data has the issues of lack of naturalness and relevance to real-world use cases, while the static dataset paradigm does not allow for a model to learn from its experiences of using language (Silver et al., 2013). In contrast, one might hope for machine learning systems that become more useful as they interact with people. In this work, we build and deploy a role-playing game, whereby human players converse with learning agents situated in an open-domain fantasy world. We show that by training models on the conversations they have with humans in the game the models progressively improve, as measured by automatic metrics and online engagement scores. This learning is shown to be more efficient than crowdsourced data when applied to conversations with real users, as well as being far cheaper to collect.
Open-Domain Conversational Agents: Current Progress, Open Problems, and Future Directions
Jul 13, 2020We present our view of what is necessary to build an engaging open-domain conversational agent: covering the qualities of such an agent, the pieces of the puzzle that have been built so far, and the gaping holes we have not filled yet. We present a biased view, focusing on work done by our own group, while citing related work in each area. In particular, we discuss in detail the properties of continual learning, providing engaging content, and being well-behaved -- and how to measure success in providing them. We end with a discussion of our experience and learnings, and our recommendations to the community.
Recipes for building an open-domain chatbot
Apr 30, 2020
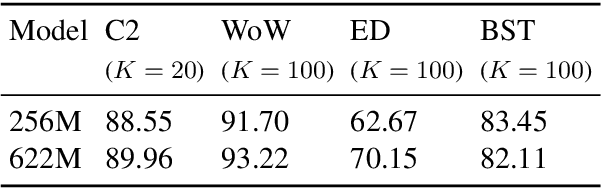
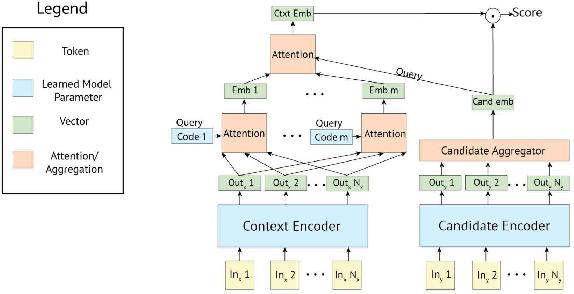
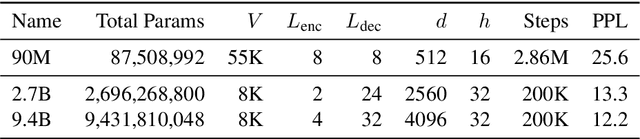
Building open-domain chatbots is a challenging area for machine learning research. While prior work has shown that scaling neural models in the number of parameters and the size of the data they are trained on gives improved results, we show that other ingredients are important for a high-performing chatbot. Good conversation requires a number of skills that an expert conversationalist blends in a seamless way: providing engaging talking points and listening to their partners, and displaying knowledge, empathy and personality appropriately, while maintaining a consistent persona. We show that large scale models can learn these skills when given appropriate training data and choice of generation strategy. We build variants of these recipes with 90M, 2.7B and 9.4B parameter models, and make our models and code publicly available. Human evaluations show our best models are superior to existing approaches in multi-turn dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing failure cases of our models.
Can You Put it All Together: Evaluating Conversational Agents' Ability to Blend Skills
Apr 17, 2020

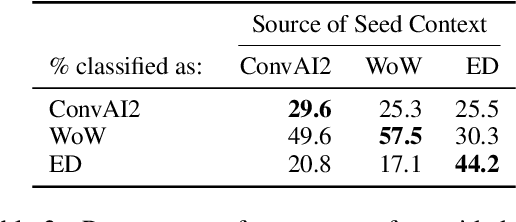
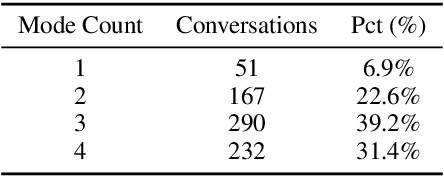
Being engaging, knowledgeable, and empathetic are all desirable general qualities in a conversational agent. Previous work has introduced tasks and datasets that aim to help agents to learn those qualities in isolation and gauge how well they can express them. But rather than being specialized in one single quality, a good open-domain conversational agent should be able to seamlessly blend them all into one cohesive conversational flow. In this work, we investigate several ways to combine models trained towards isolated capabilities, ranging from simple model aggregation schemes that require minimal additional training, to various forms of multi-task training that encompass several skills at all training stages. We further propose a new dataset, BlendedSkillTalk, to analyze how these capabilities would mesh together in a natural conversation, and compare the performance of different architectures and training schemes. Our experiments show that multi-tasking over several tasks that focus on particular capabilities results in better blended conversation performance compared to models trained on a single skill, and that both unified or two-stage approaches perform well if they are constructed to avoid unwanted bias in skill selection or are fine-tuned on our new task.