 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Dec 23, 2025Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
Safe reinforcement learning of dynamic high-dimensional robotic tasks: navigation, manipulation, interaction
Sep 27, 2022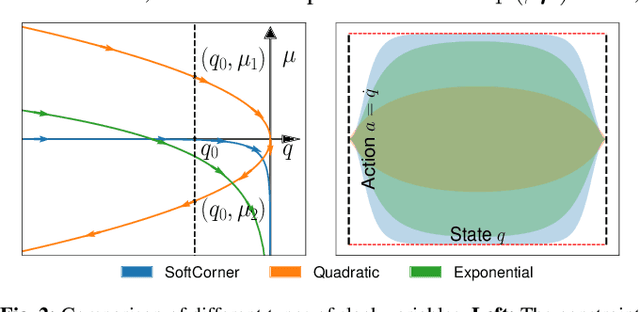

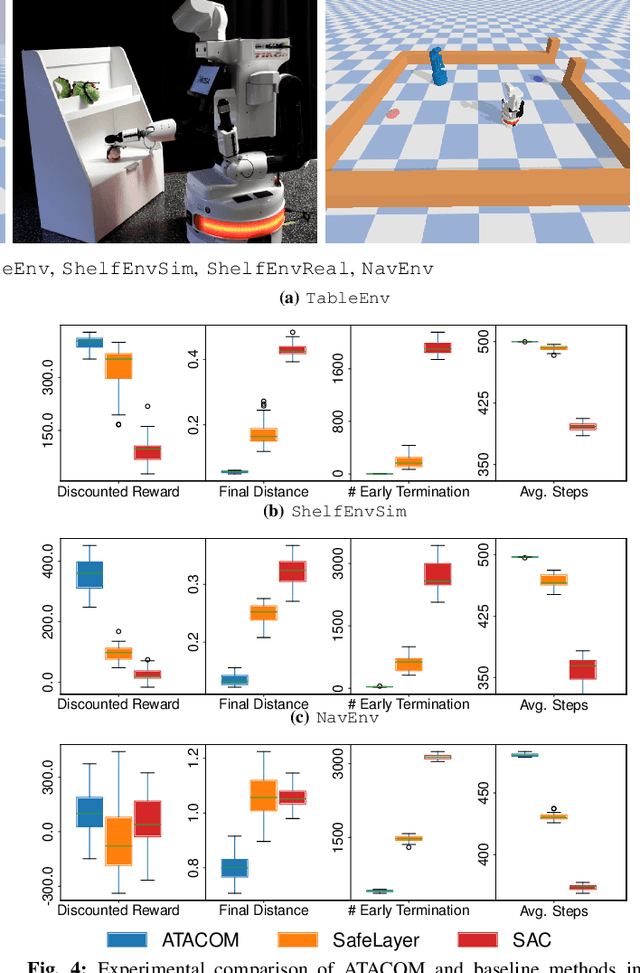
Safety is a crucial property of every robotic platform: any control policy should always comply with actuator limits and avoid collisions with the environment and humans. In reinforcement learning, safety is even more fundamental for exploring an environment without causing any damage. While there are many proposed solutions to the safe exploration problem, only a few of them can deal with the complexity of the real world. This paper introduces a new formulation of safe exploration for reinforcement learning of various robotic tasks. Our approach applies to a wide class of robotic platforms and enforces safety even under complex collision constraints learned from data by exploring the tangent space of the constraint manifold. Our proposed approach achieves state-of-the-art performance in simulated high-dimensional and dynamic tasks while avoiding collisions with the environment. We show safe real-world deployment of our learned controller on a TIAGo++ robot, achieving remarkable performance in manipulation and human-robot interaction tasks.
Regularized Deep Signed Distance Fields for Reactive Motion Generation
Mar 09, 2022
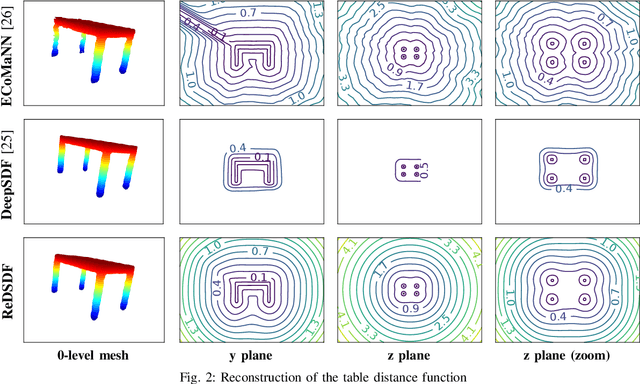
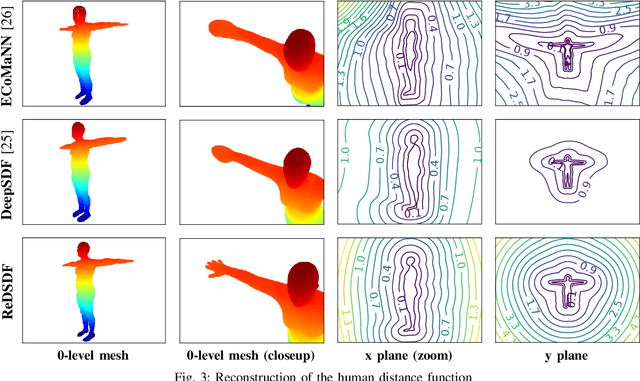
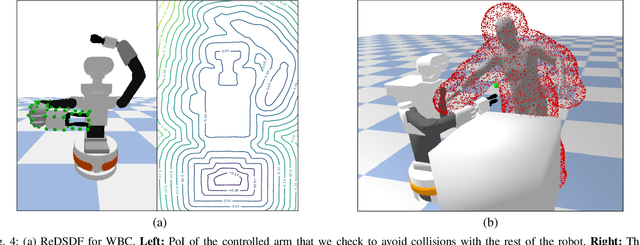
Autonomous robots should operate in real-world dynamic environments and collaborate with humans in tight spaces. A key component for allowing robots to leave structured lab and manufacturing settings is their ability to evaluate online and real-time collisions with the world around them. Distance-based constraints are fundamental for enabling robots to plan their actions and act safely, protecting both humans and their hardware. However, different applications require different distance resolutions, leading to various heuristic approaches for measuring distance fields w.r.t. obstacles, which are computationally expensive and hinder their application in dynamic obstacle avoidance use-cases. We propose Regularized Deep Signed Distance Fields (ReDSDF), a single neural implicit function that can compute smooth distance fields at any scale, with fine-grained resolution over high-dimensional manifolds and articulated bodies like humans, thanks to our effective data generation and a simple inductive bias during training. We demonstrate the effectiveness of our approach in representative simulated tasks for whole-body control (WBC) and safe Human-Robot Interaction (HRI) in shared workspaces. Finally, we provide proof of concept of a real-world application in a HRI handover task with a mobile manipulator robot.