 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA optimization framework for herbal prescription planning based on deep reinforcement learning
Apr 25, 2023



Treatment planning for chronic diseases is a critical task in medical artificial intelligence, particularly in traditional Chinese medicine (TCM). However, generating optimized sequential treatment strategies for patients with chronic diseases in different clinical encounters remains a challenging issue that requires further exploration. In this study, we proposed a TCM herbal prescription planning framework based on deep reinforcement learning for chronic disease treatment (PrescDRL). PrescDRL is a sequential herbal prescription optimization model that focuses on long-term effectiveness rather than achieving maximum reward at every step, thereby ensuring better patient outcomes. We constructed a high-quality benchmark dataset for sequential diagnosis and treatment of diabetes and evaluated PrescDRL against this benchmark. Our results showed that PrescDRL achieved a higher curative effect, with the single-step reward improving by 117% and 153% compared to doctors. Furthermore, PrescDRL outperformed the benchmark in prescription prediction, with precision improving by 40.5% and recall improving by 63%. Overall, our study demonstrates the potential of using artificial intelligence to improve clinical intelligent diagnosis and treatment in TCM.
Knowledge Graph Completion based on Tensor Decomposition for Disease Gene Prediction
Feb 18, 2023



Accurate identification of disease genes has consistently been one of the keys to decoding a disease's molecular mechanism. Most current approaches focus on constructing biological networks and utilizing machine learning, especially, deep learning to identify disease genes, but ignore the complex relations between entities in the biological knowledge graph. In this paper, we construct a biological knowledge graph centered on diseases and genes, and develop an end-to-end Knowledge graph completion model for Disease Gene Prediction using interactional tensor decomposition (called KDGene). KDGene introduces an interaction module between the embeddings of entities and relations to tensor decomposition, which can effectively enhance the information interaction in biological knowledge. Experimental results show that KDGene significantly outperforms state-of-the-art algorithms. Furthermore, the comprehensive biological analysis of the case of diabetes mellitus confirms KDGene's ability for identifying new and accurate candidate genes. This work proposes a scalable knowledge graph completion framework to identify disease candidate genes, from which the results are promising to provide valuable references for further wet experiments.
A Pre-training Framework for Knowledge Graph Completion
Feb 06, 2023Knowledge graph completion (KGC) is one of the effective methods to identify new facts in knowledge graph. Except for a few methods based on graph network, most of KGC methods trend to be trained based on independent triples, while are difficult to take a full account of the information of global network connection contained in knowledge network. To address these issues, in this study, we propose a simple and effective Network-based Pre-training framework for knowledge graph completion (termed NetPeace), which takes into account the information of global network connection and local triple relationships in knowledge graph. Experiments show that in NetPeace framework, multiple KGC models yields consistent and significant improvements on benchmarks (e.g., 36.45% Hits@1 and 27.40% MRR improvements for TuckER on FB15k-237), especially dense knowledge graph. On the challenging low-resource task, NetPeace that benefits from the global features of KG achieves higher performance (104.03% MRR and 143.89% Hit@1 improvements at most) than original models.
CLAD: A realistic Continual Learning benchmark for Autonomous Driving
Oct 07, 2022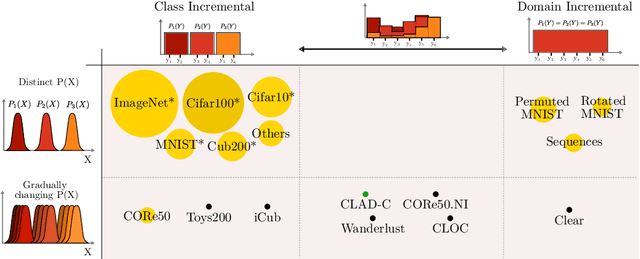

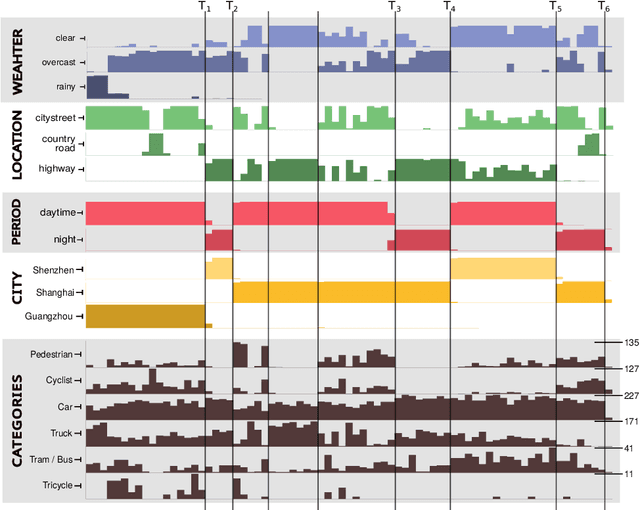
In this paper we describe the design and the ideas motivating a new Continual Learning benchmark for Autonomous Driving (CLAD), that focuses on the problems of object classification and object detection. The benchmark utilises SODA10M, a recently released large-scale dataset that concerns autonomous driving related problems. First, we review and discuss existing continual learning benchmarks, how they are related, and show that most are extreme cases of continual learning. To this end, we survey the benchmarks used in continual learning papers at three highly ranked computer vision conferences. Next, we introduce CLAD-C, an online classification benchmark realised through a chronological data stream that poses both class and domain incremental challenges; and CLAD-D, a domain incremental continual object detection benchmark. We examine the inherent difficulties and challenges posed by the benchmark, through a survey of the techniques and methods used by the top-3 participants in a CLAD-challenge workshop at ICCV 2021. We conclude with possible pathways to improve the current continual learning state of the art, and which directions we deem promising for future research.
Re-examining Distillation For Continual Object Detection
Apr 04, 2022
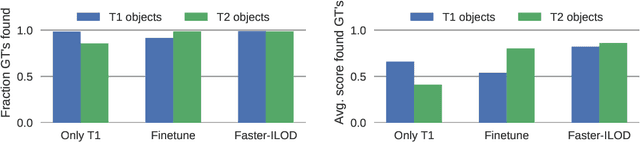


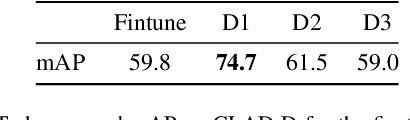
Training models continually to detect and classify objects, from new classes and new domains, remains an open problem. In this work, we conduct a thorough analysis of why and how object detection models forget catastrophically. We focus on distillation-based approaches in two-stage networks; the most-common strategy employed in contemporary continual object detection work.Distillation aims to transfer the knowledge of a model trained on previous tasks -- the teacher -- to a new model -- the student -- while it learns the new task. We show that this works well for the region proposal network, but that wrong, yet overly confident teacher predictions prevent student models from effective learning of the classification head. Our analysis provides a foundation that allows us to propose improvements for existing techniques by detecting incorrect teacher predictions, based on current ground-truth labels, and by employing an adaptive Huber loss as opposed to the mean squared error for the distillation loss in the classification heads. We evidence that our strategy works not only in a class incremental setting, but also in domain incremental settings, which constitute a realistic context, likely to be the setting of representative real-world problems.
Memory Replay with Data Compression for Continual Learning
Mar 09, 2022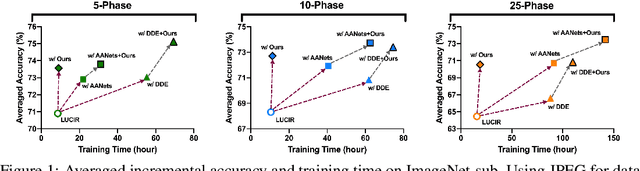
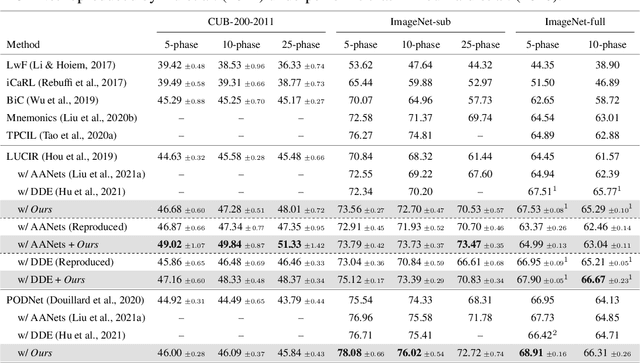
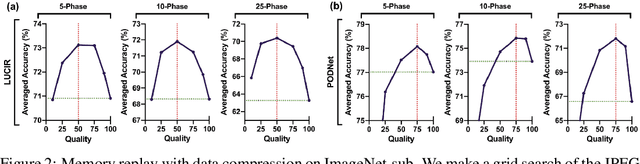
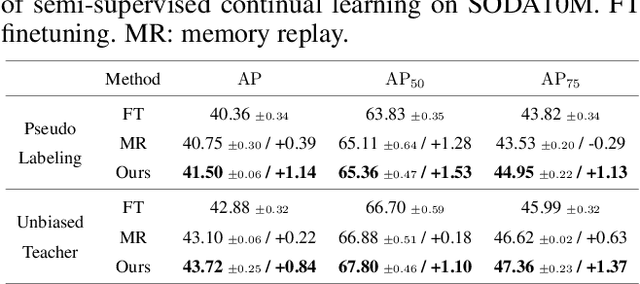
Continual learning needs to overcome catastrophic forgetting of the past. Memory replay of representative old training samples has been shown as an effective solution, and achieves the state-of-the-art (SOTA) performance. However, existing work is mainly built on a small memory buffer containing a few original data, which cannot fully characterize the old data distribution. In this work, we propose memory replay with data compression (MRDC) to reduce the storage cost of old training samples and thus increase their amount that can be stored in the memory buffer. Observing that the trade-off between the quality and quantity of compressed data is highly nontrivial for the efficacy of memory replay, we propose a novel method based on determinantal point processes (DPPs) to efficiently determine an appropriate compression quality for currently-arrived training samples. In this way, using a naive data compression algorithm with a properly selected quality can largely boost recent strong baselines by saving more compressed data in a limited storage space. We extensively validate this across several benchmarks of class-incremental learning and in a realistic scenario of object detection for autonomous driving.
* arXiv admin note: text overlap with arXiv:1207.6083 by other authors
Detection of Alzheimer's Disease Using Graph-Regularized Convolutional Neural Network Based on Structural Similarity Learning of Brain Magnetic Resonance Images
Feb 25, 2021
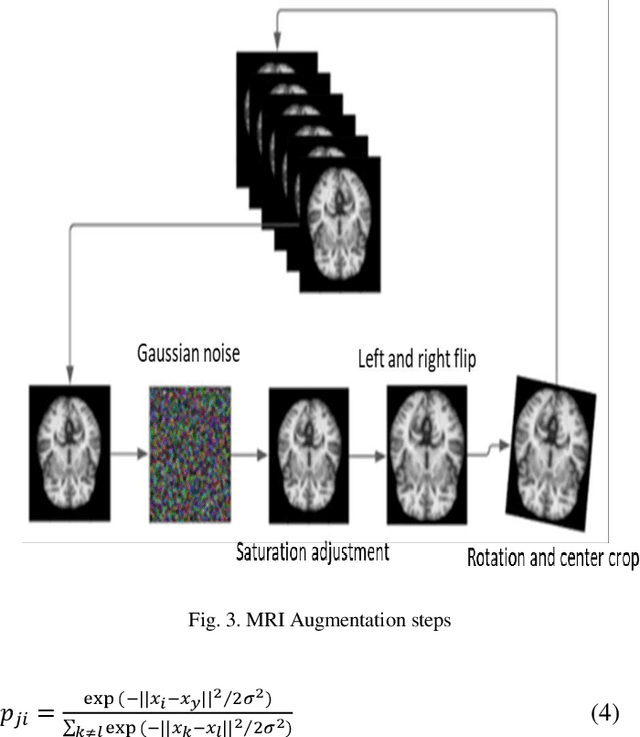
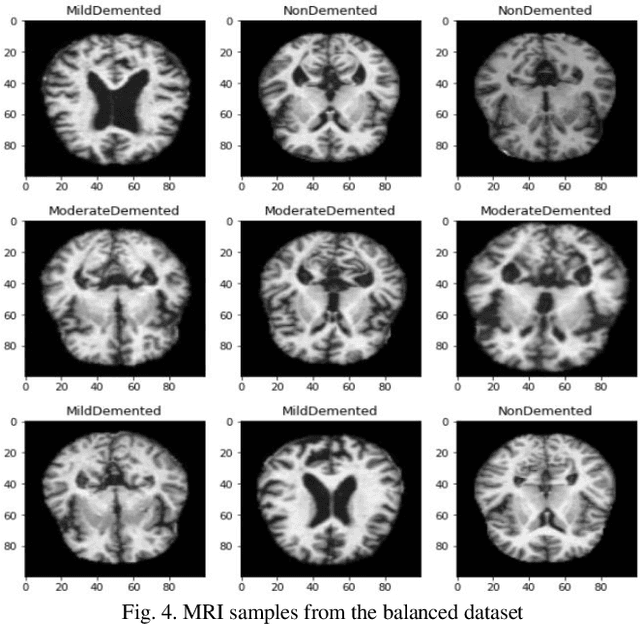
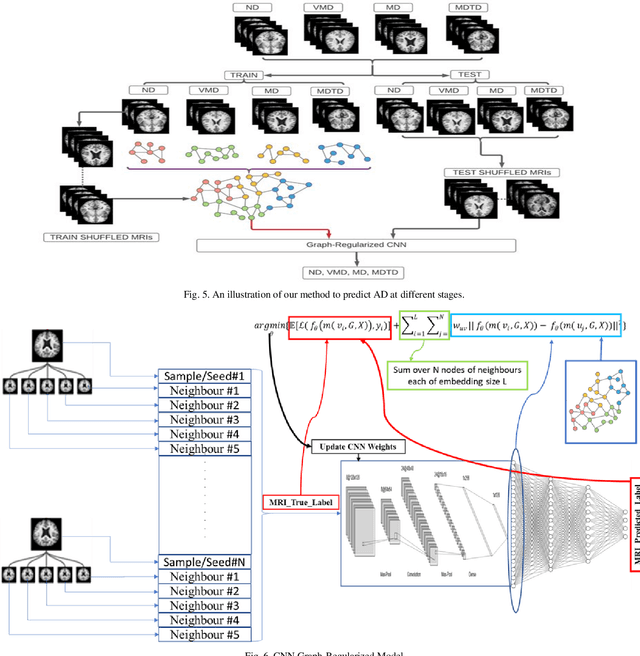
Objective: This paper presents an Alzheimer's disease (AD) detection method based on learning structural similarity between Magnetic Resonance Images (MRIs) and representing this similarity as a graph. Methods: We construct the similarity graph using embedded features of the input image (i.e., Non-Demented (ND), Very Mild Demented (VMD), Mild Demented (MD), and Moderated Demented (MDTD)). We experiment and compare different dimension-reduction and clustering algorithms to construct the best similarity graph to capture the similarity between the same class images using the cosine distance as a similarity measure. We utilize the similarity graph to present (sample) the training data to a convolutional neural network (CNN). We use the similarity graph as a regularizer in the loss function of a CNN model to minimize the distance between the input images and their k-nearest neighbours in the similarity graph while minimizing the categorical cross-entropy loss between the training image predictions and the actual image class labels. Results: We conduct extensive experiments with several pre-trained CNN models and compare the results to other recent methods. Conclusion: Our method achieves superior performance on the testing dataset (accuracy = 0.986, area under receiver operating characteristics curve = 0.998, F1 measure = 0.987). Significance: The classification results show an improvement in the prediction accuracy compared to the other methods. We release all the code used in our experiments to encourage reproducible research in this area
Relaxed Conditional Image Transfer for Semi-supervised Domain Adaptation
Jan 05, 2021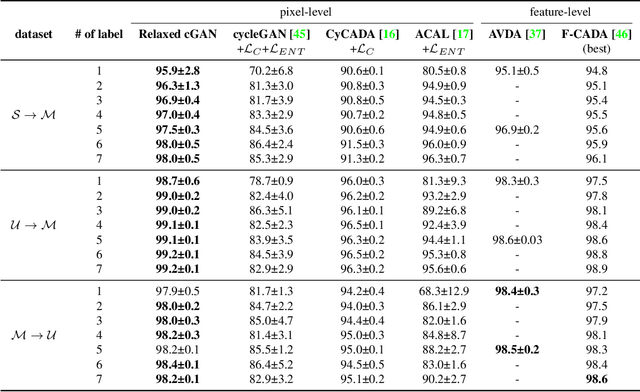
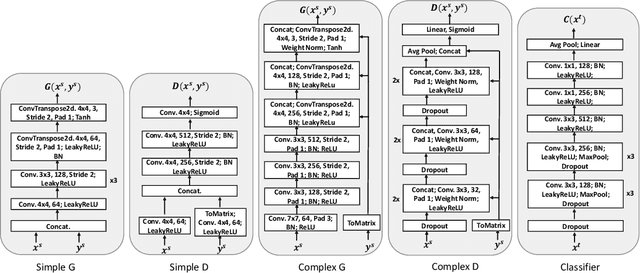
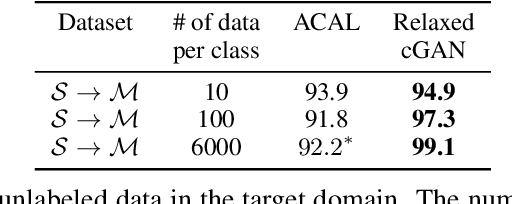
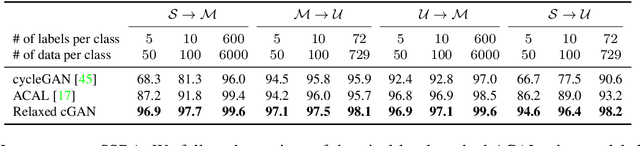
Semi-supervised domain adaptation (SSDA), which aims to learn models in a partially labeled target domain with the assistance of the fully labeled source domain, attracts increasing attention in recent years. To explicitly leverage the labeled data in both domains, we naturally introduce a conditional GAN framework to transfer images without changing the semantics in SSDA. However, we identify a label-domination problem in such an approach. In fact, the generator tends to overlook the input source image and only memorizes prototypes of each class, which results in unsatisfactory adaptation performance. To this end, we propose a simple yet effective Relaxed conditional GAN (Relaxed cGAN) framework. Specifically, we feed the image without its label to our generator. In this way, the generator has to infer the semantic information of input data. We formally prove that its equilibrium is desirable and empirically validate its practical convergence and effectiveness in image transfer. Additionally, we propose several techniques to make use of unlabeled data in the target domain, enhancing the model in SSDA settings. We validate our method on the well-adopted datasets: Digits, DomainNet, and Office-Home. We achieve state-of-the-art performance on DomainNet, Office-Home and most digit benchmarks in low-resource and high-resource settings.
ORDisCo: Effective and Efficient Usage of Incremental Unlabeled Data for Semi-supervised Continual Learning
Jan 02, 2021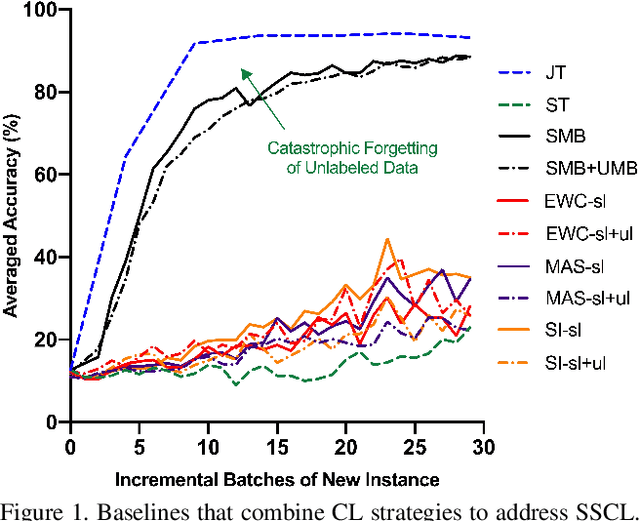

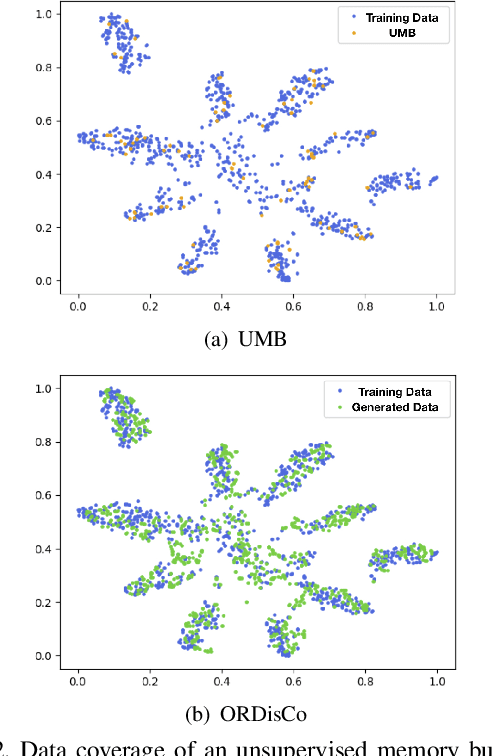
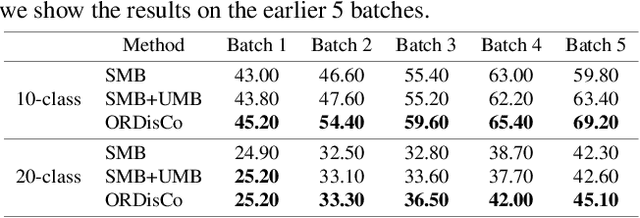
Continual learning usually assumes the incoming data are fully labeled, which might not be applicable in real applications. In this work, we consider semi-supervised continual learning (SSCL) that incrementally learns from partially labeled data. Observing that existing continual learning methods lack the ability to continually exploit the unlabeled data, we propose deep Online Replay with Discriminator Consistency (ORDisCo) to interdependently learn a classifier with a conditional generative adversarial network (GAN), which continually passes the learned data distribution to the classifier. In particular, ORDisCo replays data sampled from the conditional generator to the classifier in an online manner, exploiting unlabeled data in a time- and storage-efficient way. Further, to explicitly overcome the catastrophic forgetting of unlabeled data, we selectively stabilize parameters of the discriminator that are important for discriminating the pairs of old unlabeled data and their pseudo-labels predicted by the classifier. We extensively evaluate ORDisCo on various semi-supervised learning benchmark datasets for SSCL, and show that ORDisCo achieves significant performance improvement on SVHN, CIFAR10 and Tiny-ImageNet, compared to strong baselines.
A Review of Artificial Intelligence Technologies for Early Prediction of Alzheimer's Disease
Dec 22, 2020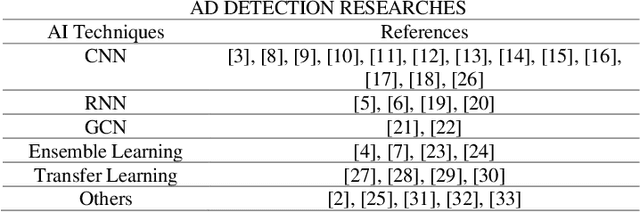
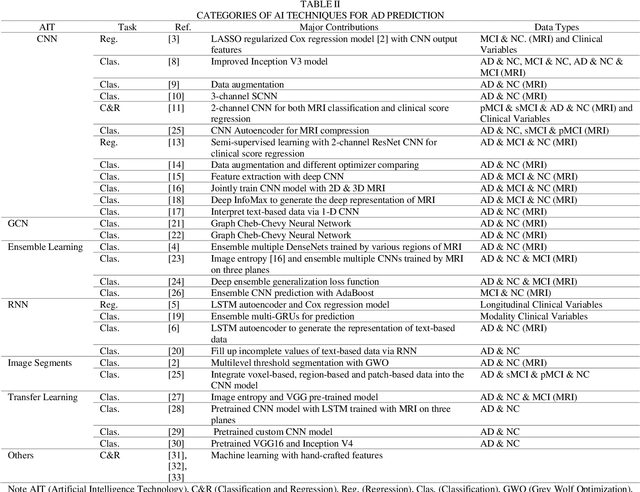

Alzheimer's Disease (AD) is a severe brain disorder, destroying memories and brain functions. AD causes chronically, progressively, and irreversibly cognitive declination and brain damages. The reliable and effective evaluation of early dementia has become essential research with medical imaging technologies and computer-aided algorithms. This trend has moved to modern Artificial Intelligence (AI) technologies motivated by deeplearning success in image classification and natural language processing. The purpose of this review is to provide an overview of the latest research involving deep-learning algorithms in evaluating the process of dementia, diagnosing the early stage of AD, and discussing an outlook for this research. This review introduces various applications of modern AI algorithms in AD diagnosis, including Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), Automatic Image Segmentation, Autoencoder, Graph CNN (GCN), Ensemble Learning, and Transfer Learning. The advantages and disadvantages of the proposed methods and their performance are discussed. The conclusion section summarizes the primary contributions and medical imaging preprocessing techniques applied in the reviewed research. Finally, we discuss the limitations and future outlooks.