 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse, Dense, and Attentional Representations for Text Retrieval
May 01, 2020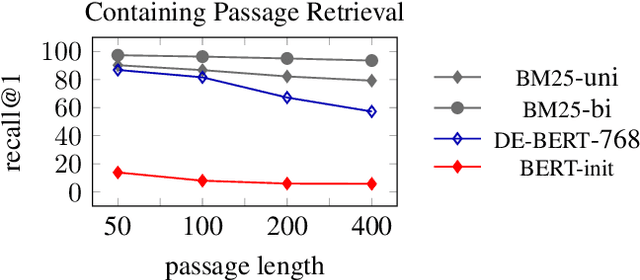
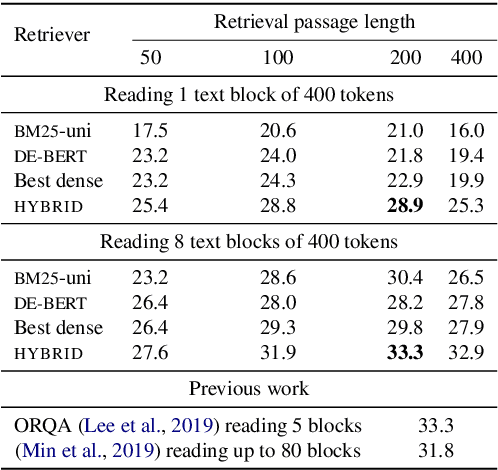
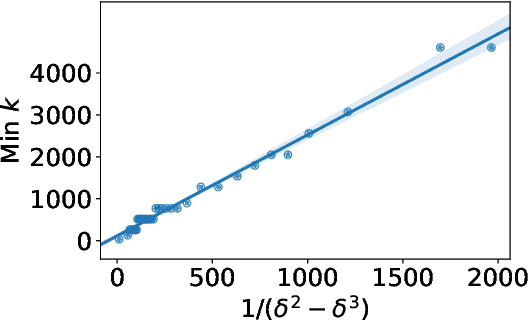
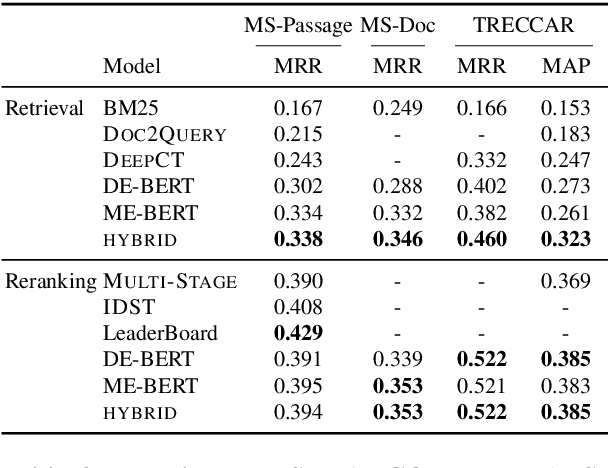
Dual encoder architectures perform retrieval by encoding documents and queries into dense low-dimensional vectors, and selecting the document that has the highest inner product with the query. We investigate the capacity of this architecture relative to sparse bag-of-words retrieval models and attentional neural networks. We establish new connections between the encoding dimension and the number of unique terms in each document and query, using both theoretical and empirical analysis. We show an upper bound on the encoding size, which may be unsustainably large for long documents. For cross-attention models, we show an upper bound using much smaller encodings per token, but such models are difficult to scale to realistic retrieval problems due to computational cost. Building on these insights, we propose a simple neural model that combines the efficiency of dual encoders with some of the expressiveness of attentional architectures, and explore a sparse-dense hybrid to capitalize on the precision of sparse retrieval. These models outperform strong alternatives in open retrieval.
Contextualized Representations Using Textual Encyclopedic Knowledge
Apr 24, 2020
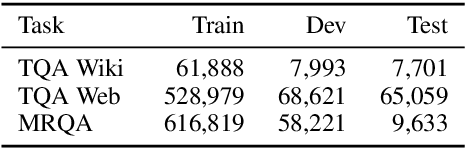

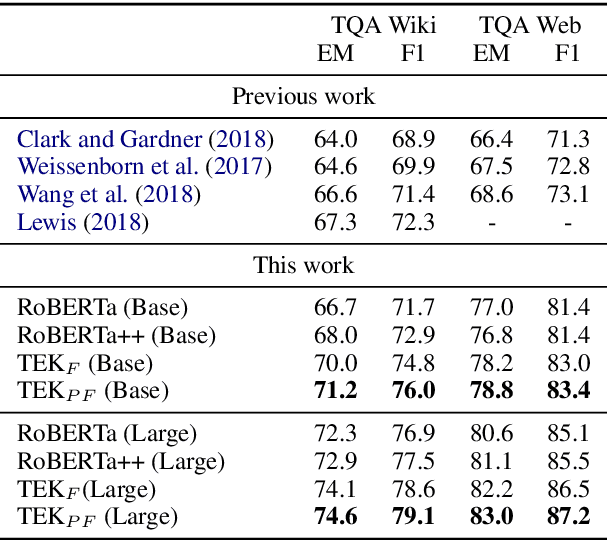
We present a method to represent input texts by contextualizing them jointly with dynamically retrieved textual encyclopedic background knowledge from multiple documents. We apply our method to reading comprehension tasks by encoding questions and passages together with background sentences about the entities they mention. We show that integrating background knowledge from text is effective for tasks focusing on factual reasoning and allows direct reuse of powerful pretrained BERT-style encoders. Moreover, knowledge integration can be further improved with suitable pretraining via a self-supervised masked language model objective over words in background-augmented input text. On TriviaQA, our approach obtains improvements of 1.6 to 3.1 F1 over comparable RoBERTa models which do not integrate background knowledge dynamically. On MRQA, a large collection of diverse QA datasets, we see consistent gains in-domain along with large improvements out-of-domain on BioASQ (2.1 to 4.2 F1), TextbookQA (1.6 to 2.0 F1), and DuoRC (1.1 to 2.0 F1).
Well-Read Students Learn Better: On the Importance of Pre-training Compact Models
Sep 25, 2019

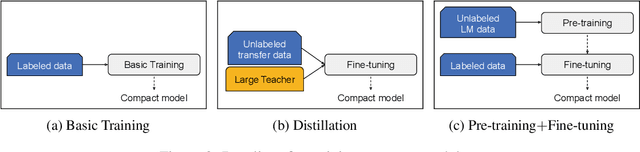
Recent developments in natural language representations have been accompanied by large and expensive models that leverage vast amounts of general-domain text through self-supervised pre-training. Due to the cost of applying such models to down-stream tasks, several model compression techniques on pre-trained language representations have been proposed (Sun et al., 2019; Sanh, 2019). However, surprisingly, the simple baseline of just pre-training and fine-tuning compact models has been overlooked. In this paper, we first show that pre-training remains important in the context of smaller architectures, and fine-tuning pre-trained compact models can be competitive to more elaborate methods proposed in concurrent work. Starting with pre-trained compact models, we then explore transferring task knowledge from large fine-tuned models through standard knowledge distillation. The resulting simple, yet effective and general algorithm, Pre-trained Distillation, brings further improvements. Through extensive experiments, we more generally explore the interaction between pre-training and distillation under two variables that have been under-studied: model size and properties of unlabeled task data. One surprising observation is that they have a compound effect even when sequentially applied on the same data. To accelerate future research, we will make our 24 pre-trained miniature BERT models publicly available.
Zero-Shot Entity Linking by Reading Entity Descriptions
Jun 18, 2019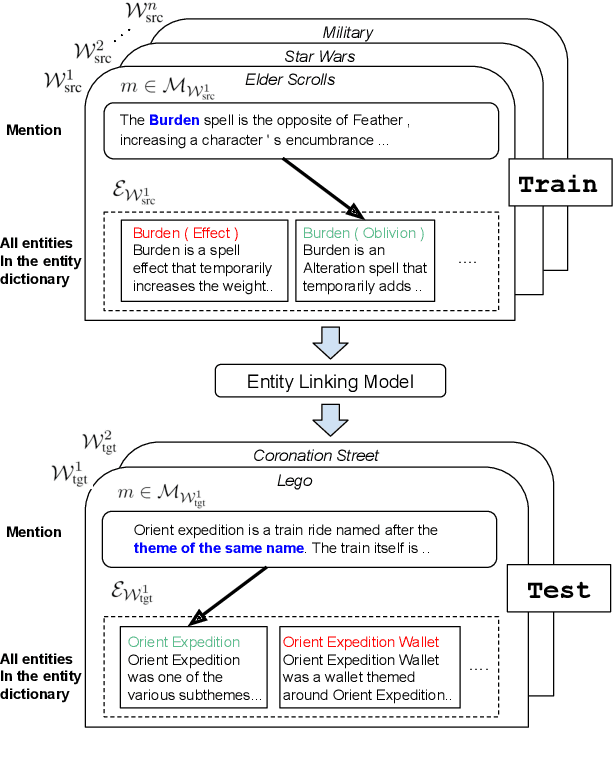

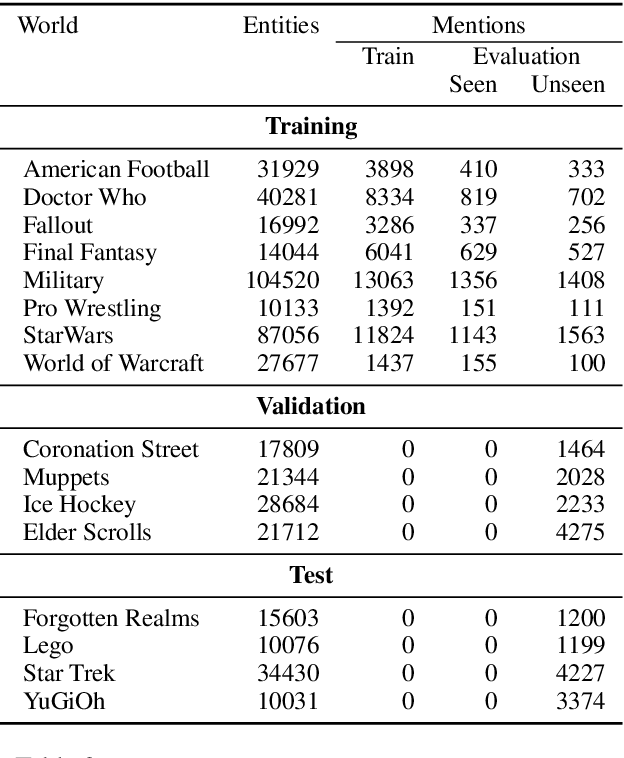
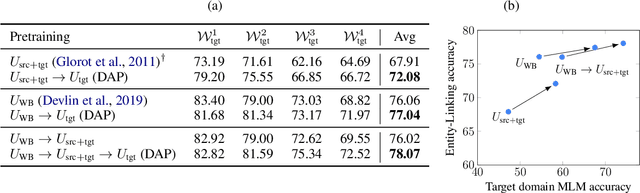
We present the zero-shot entity linking task, where mentions must be linked to unseen entities without in-domain labeled data. The goal is to enable robust transfer to highly specialized domains, and so no metadata or alias tables are assumed. In this setting, entities are only identified by text descriptions, and models must rely strictly on language understanding to resolve the new entities. First, we show that strong reading comprehension models pre-trained on large unlabeled data can be used to generalize to unseen entities. Second, we propose a simple and effective adaptive pre-training strategy, which we term domain-adaptive pre-training (DAP), to address the domain shift problem associated with linking unseen entities in a new domain. We present experiments on a new dataset that we construct for this task and show that DAP improves over strong pre-training baselines, including BERT. The data and code are available at https://github.com/lajanugen/zeshel.
Latent Retrieval for Weakly Supervised Open Domain Question Answering
Jun 06, 2019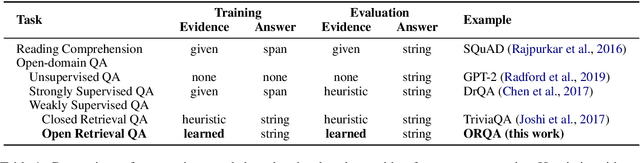
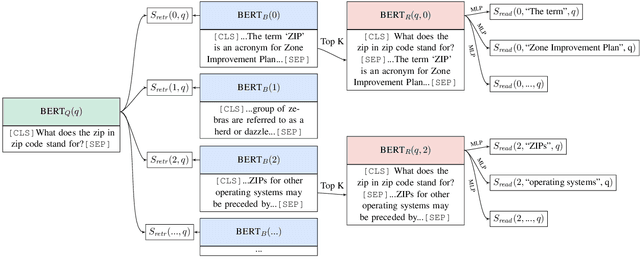
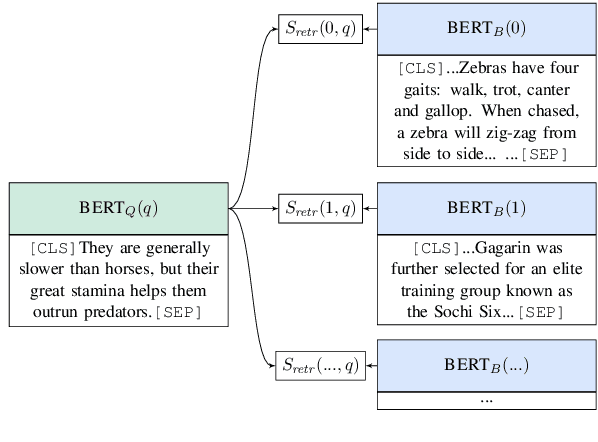
Recent work on open domain question answering (QA) assumes strong supervision of the supporting evidence and/or assumes a blackbox information retrieval (IR) system to retrieve evidence candidates. We argue that both are suboptimal, since gold evidence is not always available, and QA is fundamentally different from IR. We show for the first time that it is possible to jointly learn the retriever and reader from question-answer string pairs and without any IR system. In this setting, evidence retrieval from all of Wikipedia is treated as a latent variable. Since this is impractical to learn from scratch, we pre-train the retriever with an Inverse Cloze Task. We evaluate on open versions of five QA datasets. On datasets where the questioner already knows the answer, a traditional IR system such as BM25 is sufficient. On datasets where a user is genuinely seeking an answer, we show that learned retrieval is crucial, outperforming BM25 by up to 19 points in exact match.
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
May 24, 2019

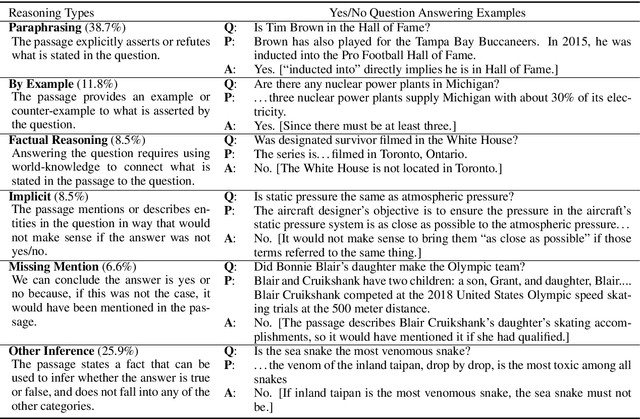
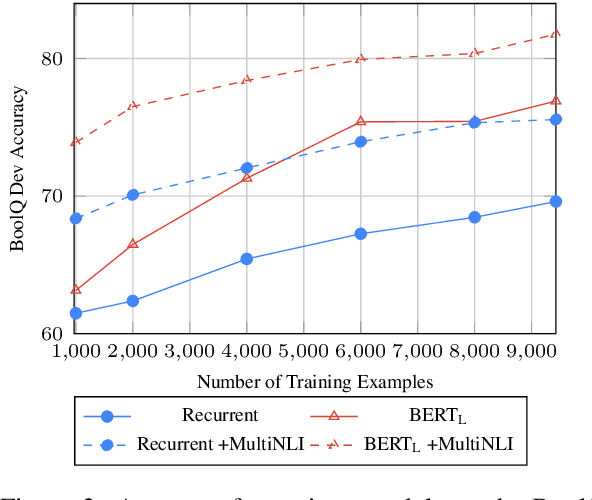
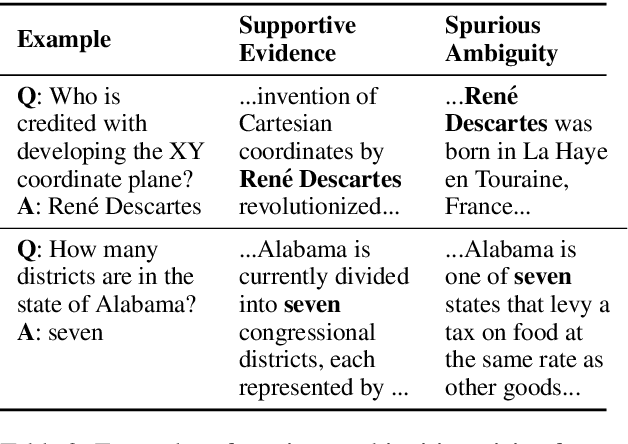
In this paper we study yes/no questions that are naturally occurring --- meaning that they are generated in unprompted and unconstrained settings. We build a reading comprehension dataset, BoolQ, of such questions, and show that they are unexpectedly challenging. They often query for complex, non-factoid information, and require difficult entailment-like inference to solve. We also explore the effectiveness of a range of transfer learning baselines. We find that transferring from entailment data is more effective than transferring from paraphrase or extractive QA data, and that it, surprisingly, continues to be very beneficial even when starting from massive pre-trained language models such as BERT. Our best method trains BERT on MultiNLI and then re-trains it on our train set. It achieves 80.4% accuracy compared to 90% accuracy of human annotators (and 62% majority-baseline), leaving a significant gap for future work.
Language Model Pre-training for Hierarchical Document Representations
Jan 26, 2019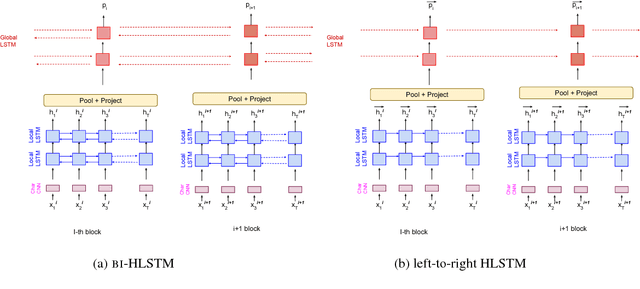

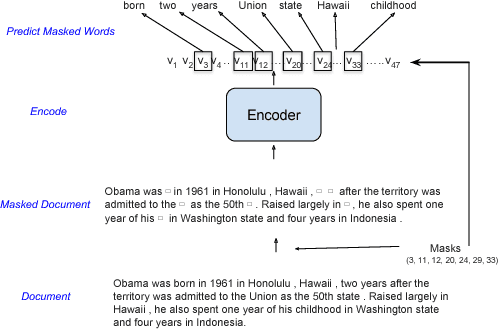

Hierarchical neural architectures are often used to capture long-distance dependencies and have been applied to many document-level tasks such as summarization, document segmentation, and sentiment analysis. However, effective usage of such a large context can be difficult to learn, especially in the case where there is limited labeled data available. Building on the recent success of language model pretraining methods for learning flat representations of text, we propose algorithms for pre-training hierarchical document representations from unlabeled data. Unlike prior work, which has focused on pre-training contextual token representations or context-independent {sentence/paragraph} representations, our hierarchical document representations include fixed-length sentence/paragraph representations which integrate contextual information from the entire documents. Experiments on document segmentation, document-level question answering, and extractive document summarization demonstrate the effectiveness of the proposed pre-training algorithms.
Improving Span-based Question Answering Systems with Coarsely Labeled Data
Nov 05, 2018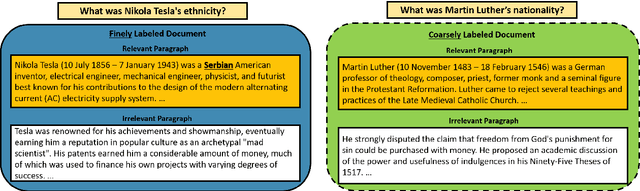
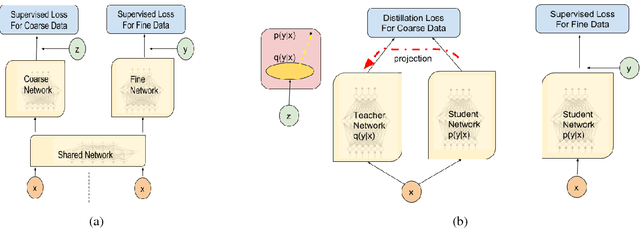
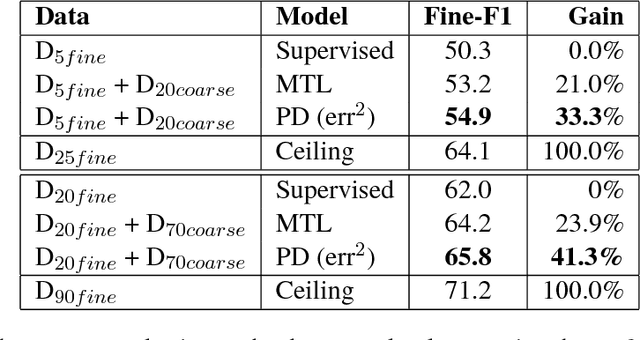
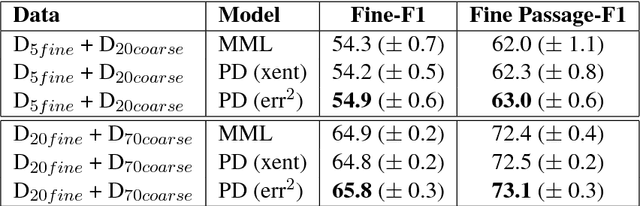
We study approaches to improve fine-grained short answer Question Answering models by integrating coarse-grained data annotated for paragraph-level relevance and show that coarsely annotated data can bring significant performance gains. Experiments demonstrate that the standard multi-task learning approach of sharing representations is not the most effective way to leverage coarse-grained annotations. Instead, we can explicitly model the latent fine-grained short answer variables and optimize the marginal log-likelihood directly or use a newly proposed \emph{posterior distillation} learning objective. Since these latent-variable methods have explicit access to the relationship between the fine and coarse tasks, they result in significantly larger improvements from coarse supervision.
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Oct 11, 2018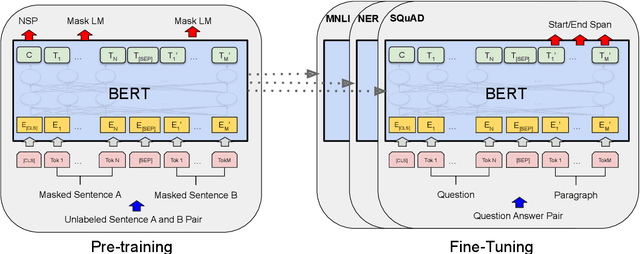
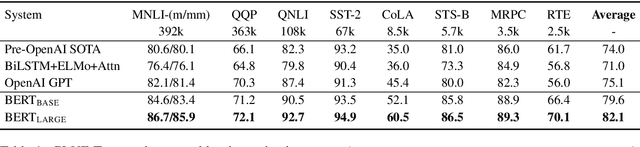
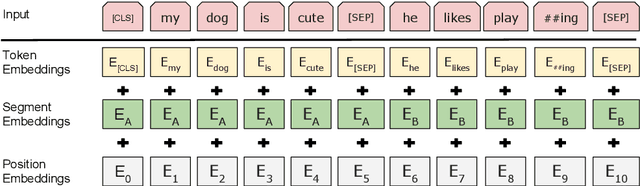
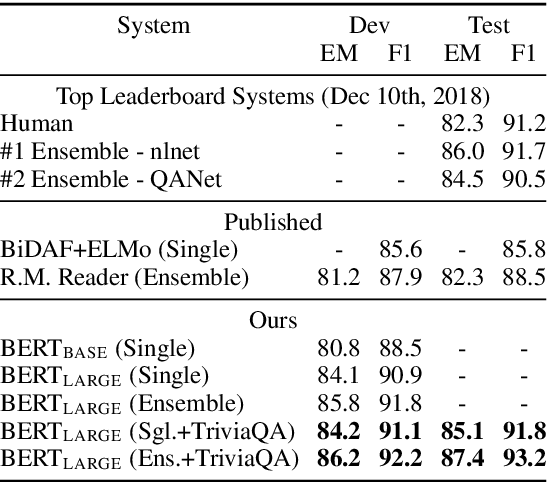
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT representations can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications. BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE benchmark to 80.4% (7.6% absolute improvement), MultiNLI accuracy to 86.7 (5.6% absolute improvement) and the SQuAD v1.1 question answering Test F1 to 93.2 (1.5% absolute improvement), outperforming human performance by 2.0%.
Cross-Sentence N-ary Relation Extraction with Graph LSTMs
Aug 12, 2017Past work in relation extraction has focused on binary relations in single sentences. Recent NLP inroads in high-value domains have sparked interest in the more general setting of extracting n-ary relations that span multiple sentences. In this paper, we explore a general relation extraction framework based on graph long short-term memory networks (graph LSTMs) that can be easily extended to cross-sentence n-ary relation extraction. The graph formulation provides a unified way of exploring different LSTM approaches and incorporating various intra-sentential and inter-sentential dependencies, such as sequential, syntactic, and discourse relations. A robust contextual representation is learned for the entities, which serves as input to the relation classifier. This simplifies handling of relations with arbitrary arity, and enables multi-task learning with related relations. We evaluate this framework in two important precision medicine settings, demonstrating its effectiveness with both conventional supervised learning and distant supervision. Cross-sentence extraction produced larger knowledge bases. and multi-task learning significantly improved extraction accuracy. A thorough analysis of various LSTM approaches yielded useful insight the impact of linguistic analysis on extraction accuracy.
* Conditional accepted by TACL in December 2016; published in April 2017; presented at ACL in August 2017