 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDressing for Diverse Body Shapes
Dec 13, 2019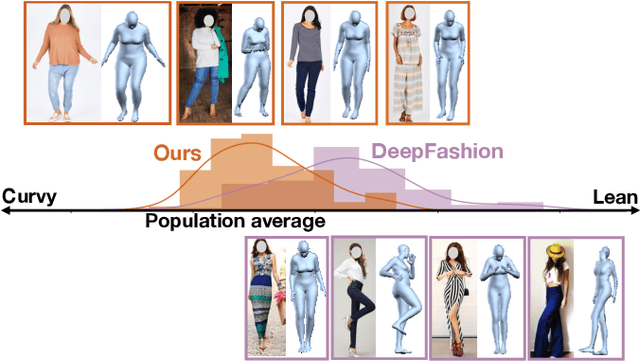
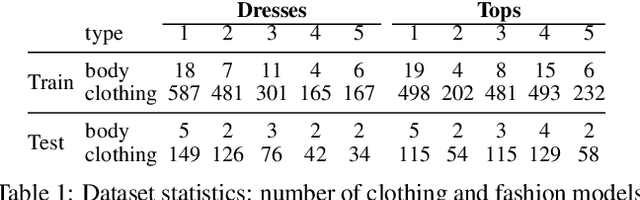
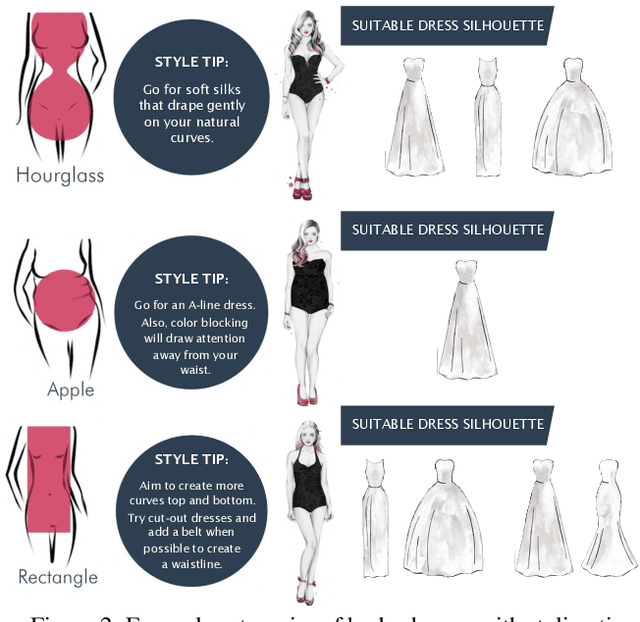

Body shape plays an important role in determining what garments will best suit a given person, yet today's clothing recommendation methods take a "one shape fits all" approach. These body-agnostic vision methods and datasets are a barrier to inclusion, ill-equipped to provide good suggestions for diverse body shapes. We introduce ViBE, a VIsual Body-aware Embedding that captures clothing's affinity with different body shapes. Given an image of a person, the proposed multi-view embedding identifies garments that will flatter her specific body shape. We show how to learn the embedding from an online catalog displaying fashion models of various shapes and sizes wearing the products, and we devise a method to explain the algorithm's suggestions for well-fitting garments. We apply our approach to a dataset of diverse subjects, and demonstrate its strong advantages over the status quo body-agnostic recommendation, both according to automated metrics and human opinion.
Listen to Look: Action Recognition by Previewing Audio
Dec 12, 2019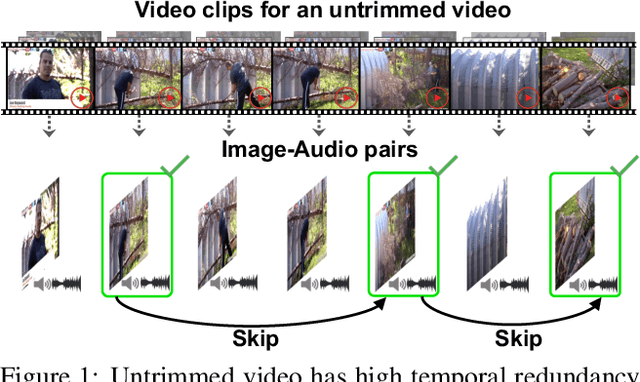

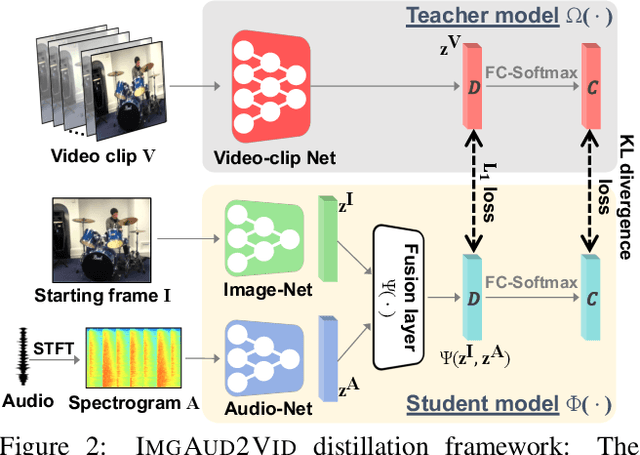

In the face of the video data deluge, today's expensive clip-level classifiers are increasingly impractical. We propose a framework for efficient action recognition in untrimmed video that uses audio as a preview mechanism to eliminate both short-term and long-term visual redundancies. First, we devise an ImgAud2Vid framework that hallucinates clip-level features by distilling from lighter modalities---a single frame and its accompanying audio---reducing short-term temporal redundancy for efficient clip-level recognition. Second, building on ImgAud2Vid, we further propose ImgAud-Skimming, an attention-based long short-term memory network that iteratively selects useful moments in untrimmed videos, reducing long-term temporal redundancy for efficient video-level recognition. Extensive experiments on four action recognition datasets demonstrate that our method achieves the state-of-the-art in terms of both recognition accuracy and speed.
Emergence of Exploratory Look-Around Behaviors through Active Observation Completion
Jun 27, 2019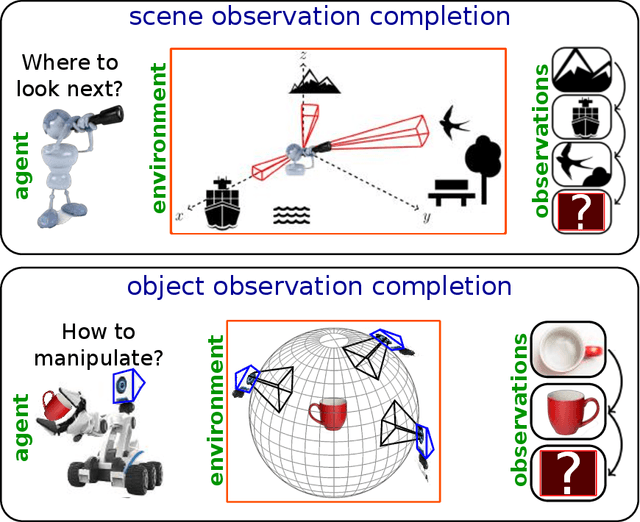
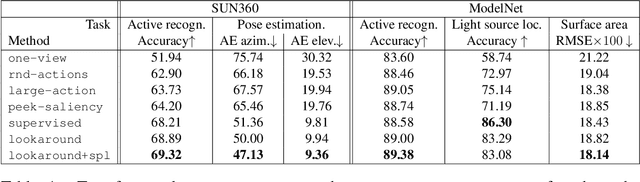
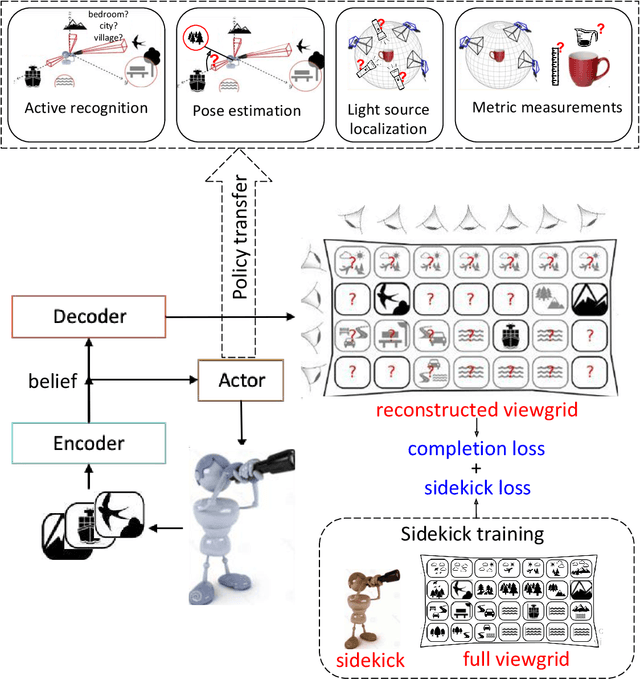
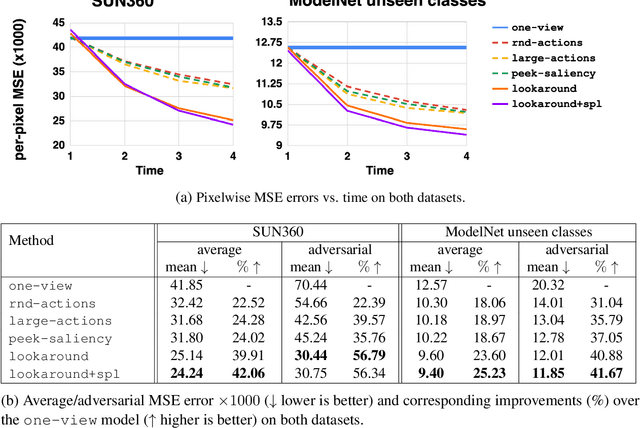
Standard computer vision systems assume access to intelligently captured inputs (e.g., photos from a human photographer), yet autonomously capturing good observations is a major challenge in itself. We address the problem of learning to look around: how can an agent learn to acquire informative visual observations? We propose a reinforcement learning solution, where the agent is rewarded for reducing its uncertainty about the unobserved portions of its environment. Specifically, the agent is trained to select a short sequence of glimpses after which it must infer the appearance of its full environment. To address the challenge of sparse rewards, we further introduce sidekick policy learning, which exploits the asymmetry in observability between training and test time. The proposed methods learn observation policies that not only perform the completion task for which they are trained, but also generalize to exhibit useful "look-around" behavior for a range of active perception tasks.
Grounded Human-Object Interaction Hotspots from Video (Extended Abstract)
Jun 03, 2019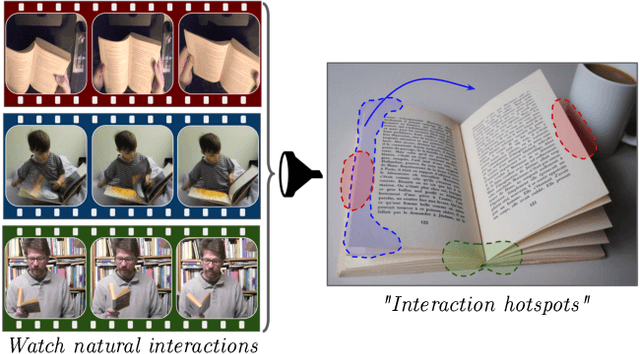
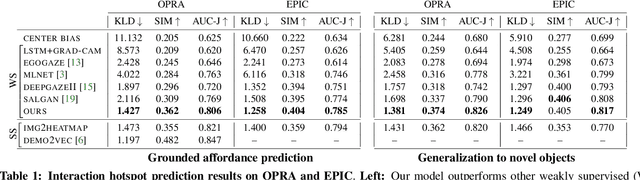
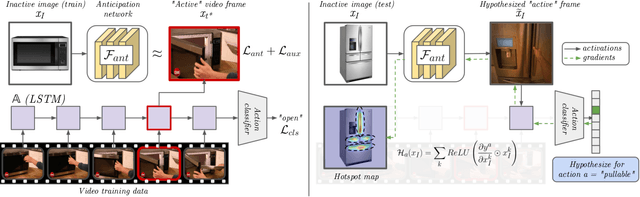

Learning how to interact with objects is an important step towards embodied visual intelligence, but existing techniques suffer from heavy supervision or sensing requirements. We propose an approach to learn human-object interaction "hotspots" directly from video. Rather than treat affordances as a manually supervised semantic segmentation task, our approach learns about interactions by watching videos of real human behavior and anticipating afforded actions. Given a novel image or video, our model infers a spatial hotspot map indicating how an object would be manipulated in a potential interaction, even if the object is currently at rest. Through results with both first and third person video, we show the value of grounding affordances in real human-object interactions. Not only are our weakly supervised hotspots competitive with strongly supervised affordance methods, but they can also anticipate object interaction for novel object categories. Project page: http://vision.cs.utexas.edu/projects/interaction-hotspots/
Predicting How to Distribute Work Between Algorithms and Humans to Segment an Image Batch
Apr 30, 2019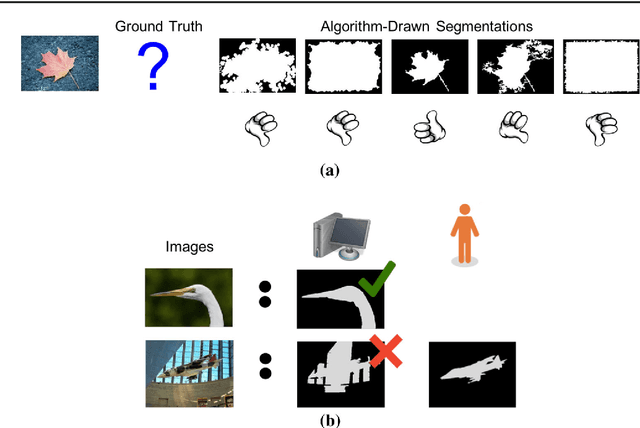
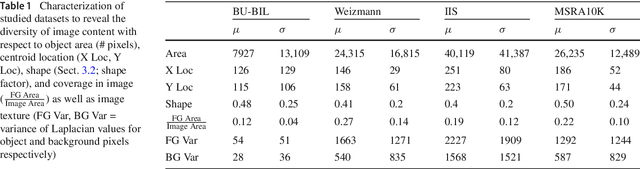
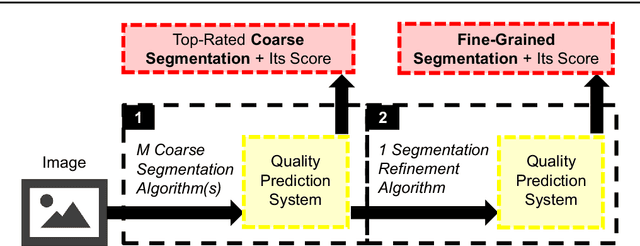

Foreground object segmentation is a critical step for many image analysis tasks. While automated methods can produce high-quality results, their failures disappoint users in need of practical solutions. We propose a resource allocation framework for predicting how best to allocate a fixed budget of human annotation effort in order to collect higher quality segmentations for a given batch of images and automated methods. The framework is based on a prediction module that estimates the quality of given algorithm-drawn segmentations. We demonstrate the value of the framework for two novel tasks related to predicting how to distribute annotation efforts between algorithms and humans. Specifically, we develop two systems that automatically decide, for a batch of images, when to recruit humans versus computers to create 1) coarse segmentations required to initialize segmentation tools and 2) final, fine-grained segmentations. Experiments demonstrate the advantage of relying on a mix of human and computer efforts over relying on either resource alone for segmenting objects in images coming from three diverse modalities (visible, phase contrast microscopy, and fluorescence microscopy).
You2Me: Inferring Body Pose in Egocentric Video via First and Second Person Interactions
Apr 22, 2019
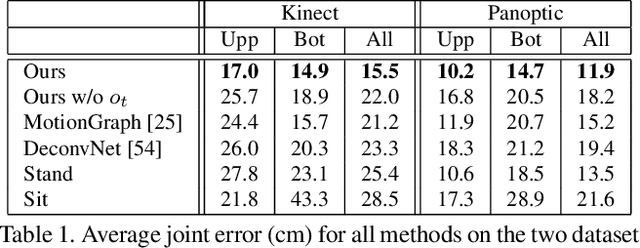
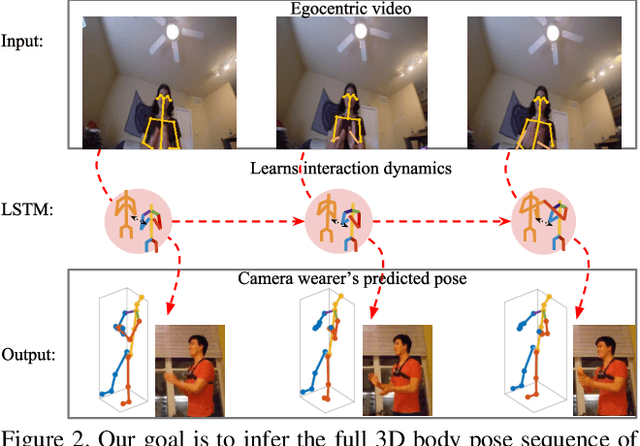
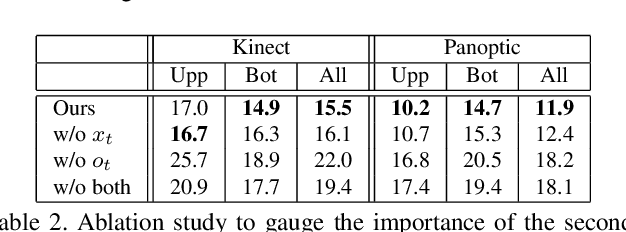
The body pose of a person wearing a camera is of great interest for applications in augmented reality, healthcare, and robotics, yet much of the person's body is out of view for a typical wearable camera. We propose a learning-based approach to estimate the camera wearer's 3D body pose from egocentric video sequences. Our key insight is to leverage interactions with another person---whose body pose we can directly observe---as a signal inherently linked to the body pose of the first-person subject. We show that since interactions between individuals often induce a well-ordered series of back-and-forth responses, it is possible to learn a temporal model of the interlinked poses even though one party is largely out of view. We demonstrate our idea on a variety of domains with dyadic interaction and show the substantial impact on egocentric body pose estimation, which improves the state of the art. Video results are available at http://vision.cs.utexas.edu/projects/you2me/
Fashion++: Minimal Edits for Outfit Improvement
Apr 19, 2019

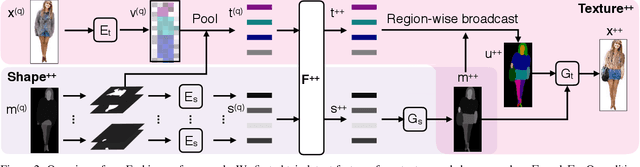
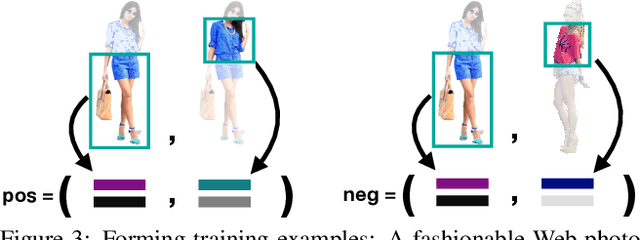
Given an outfit, what small changes would most improve its fashionability? This question presents an intriguing new vision challenge. We introduce Fashion++, an approach that proposes minimal adjustments to a full-body clothing outfit that will have maximal impact on its fashionability. Our model consists of a deep image generation neural network that learns to synthesize clothing conditioned on learned per-garment encodings. The latent encodings are explicitly factorized according to shape and texture, thereby allowing direct edits for both fit/presentation and color/patterns/material, respectively. We show how to bootstrap Web photos to automatically train a fashionability model, and develop an activation maximization-style approach to transform the input image into its more fashionable self. The edits suggested range from swapping in a new garment to tweaking its color, how it is worn (e.g., rolling up sleeves), or its fit (e.g., making pants baggier). Experiments demonstrate that Fashion++ provides successful edits, both according to automated metrics and human opinion. Project page is at http://vision.cs.utexas.edu/projects/FashionPlus.
Co-Separating Sounds of Visual Objects
Apr 16, 2019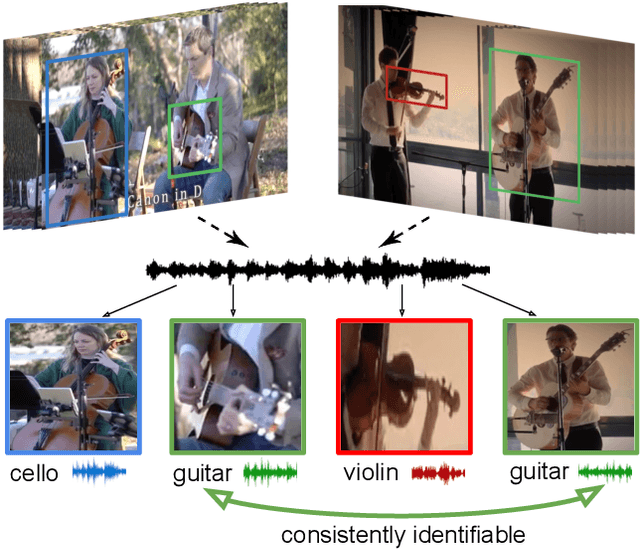
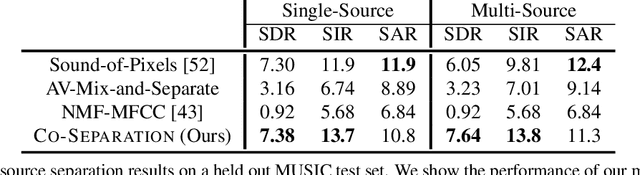
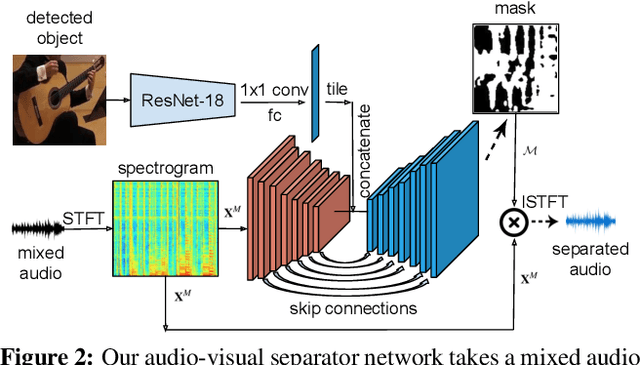
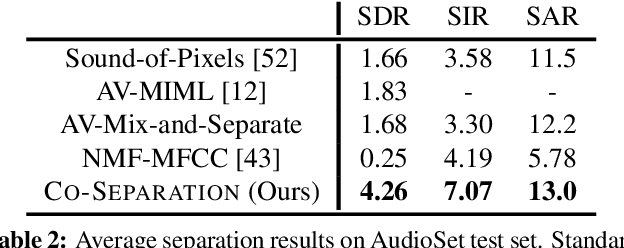
Learning how objects sound from video is challenging, since they often heavily overlap in a single audio channel. Current methods for visually-guided audio source separation sidestep the issue by training with artificially mixed video clips, but this puts unwieldy restrictions on training data collection and may even prevent learning the properties of "true" mixed sounds. We introduce a co-separation training paradigm that permits learning object-level sounds from unlabeled multi-source videos. Our novel training objective requires that the deep neural network's separated audio for similar-looking objects be consistently identifiable, while simultaneously reproducing accurate video-level audio tracks for each source training pair. Our approach disentangles sounds in realistic test videos, even in cases where an object was not observed individually during training. We obtain state-of-the-art results on visually-guided audio source separation and audio denoising for the MUSIC, AudioSet, and AV-Bench datasets. Our video results: http://vision.cs.utexas.edu/projects/coseparation/
Next-Active-Object prediction from Egocentric Videos
Apr 10, 2019
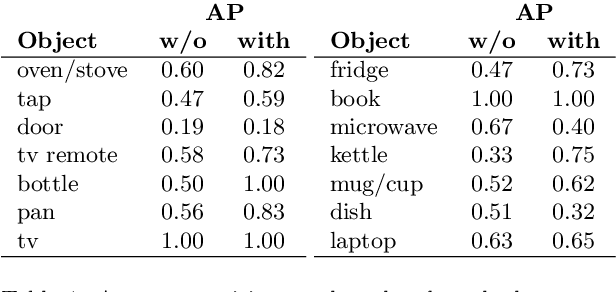
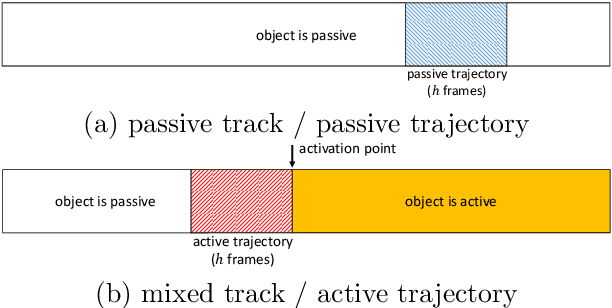
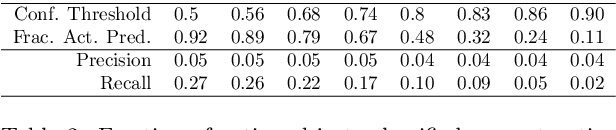
Although First Person Vision systems can sense the environment from the user's perspective, they are generally unable to predict his intentions and goals. Since human activities can be decomposed in terms of atomic actions and interactions with objects, intelligent wearable systems would benefit from the ability to anticipate user-object interactions. Even if this task is not trivial, the First Person Vision paradigm can provide important cues to address this challenge. We propose to exploit the dynamics of the scene to recognize next-active-objects before an object interaction begins. We train a classifier to discriminate trajectories leading to an object activation from all others and forecast next-active-objects by analyzing fixed-length trajectory segments within a temporal sliding window. The proposed method compares favorably with respect to several baselines on the Activity of Daily Living (ADL) egocentric dataset comprising 10 hours of videos acquired by 20 subjects while performing unconstrained interactions with several objects.
Less is More: Learning Highlight Detection from Video Duration
Mar 03, 2019
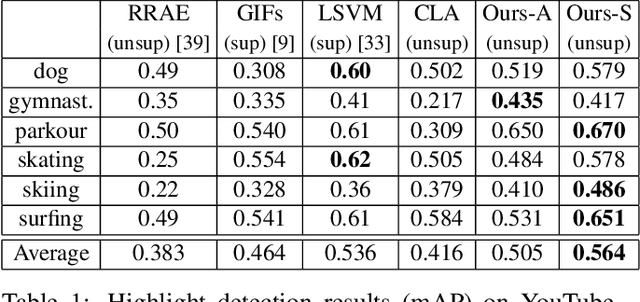
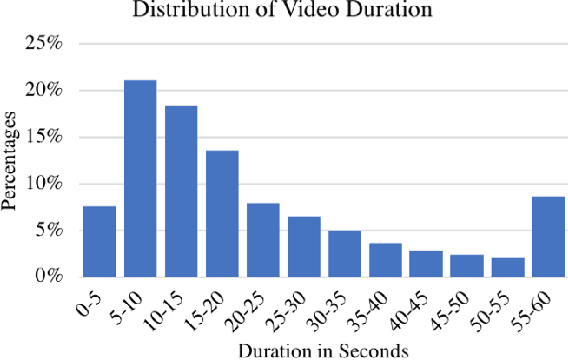
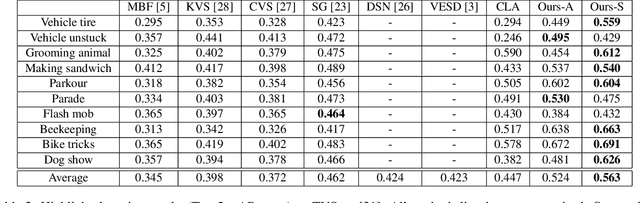
Highlight detection has the potential to significantly ease video browsing, but existing methods often suffer from expensive supervision requirements, where human viewers must manually identify highlights in training videos. We propose a scalable unsupervised solution that exploits video duration as an implicit supervision signal. Our key insight is that video segments from shorter user-generated videos are more likely to be highlights than those from longer videos, since users tend to be more selective about the content when capturing shorter videos. Leveraging this insight, we introduce a novel ranking framework that prefers segments from shorter videos, while properly accounting for the inherent noise in the (unlabeled) training data. We use it to train a highlight detector with 10M hashtagged Instagram videos. In experiments on two challenging public video highlight detection benchmarks, our method substantially improves the state-of-the-art for unsupervised highlight detection.