 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiview Pseudo-Labeling for Semi-supervised Learning from Video
Apr 01, 2021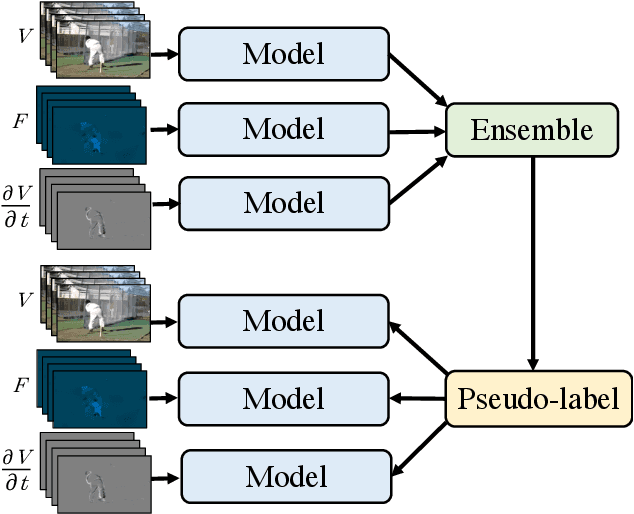
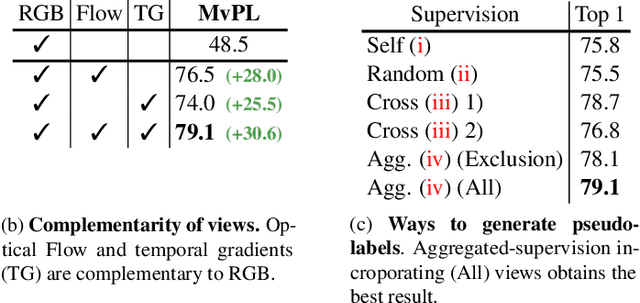
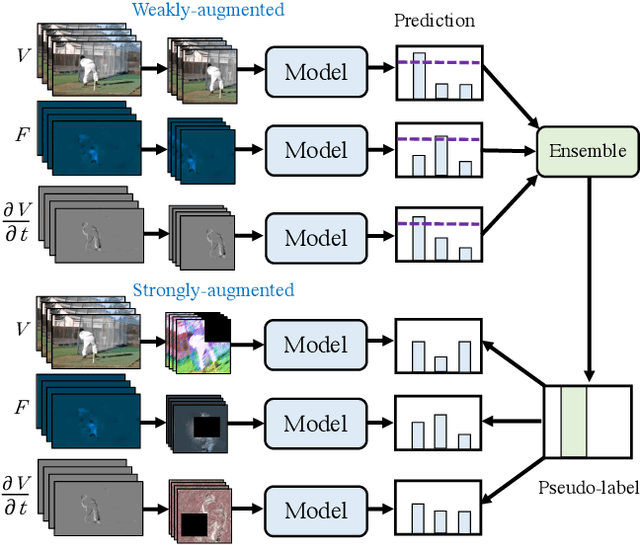

We present a multiview pseudo-labeling approach to video learning, a novel framework that uses complementary views in the form of appearance and motion information for semi-supervised learning in video. The complementary views help obtain more reliable pseudo-labels on unlabeled video, to learn stronger video representations than from purely supervised data. Though our method capitalizes on multiple views, it nonetheless trains a model that is shared across appearance and motion input and thus, by design, incurs no additional computation overhead at inference time. On multiple video recognition datasets, our method substantially outperforms its supervised counterpart, and compares favorably to previous work on standard benchmarks in self-supervised video representation learning.
Environment Predictive Coding for Embodied Agents
Feb 03, 2021
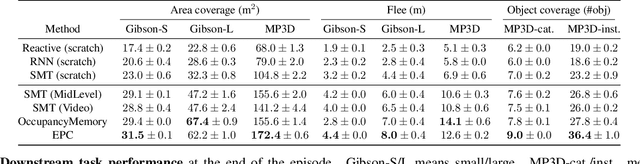
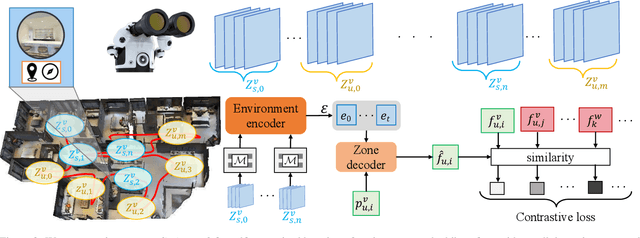

We introduce environment predictive coding, a self-supervised approach to learn environment-level representations for embodied agents. In contrast to prior work on self-supervised learning for images, we aim to jointly encode a series of images gathered by an agent as it moves about in 3D environments. We learn these representations via a zone prediction task, where we intelligently mask out portions of an agent's trajectory and predict them from the unmasked portions, conditioned on the agent's camera poses. By learning such representations on a collection of videos, we demonstrate successful transfer to multiple downstream navigation-oriented tasks. Our experiments on the photorealistic 3D environments of Gibson and Matterport3D show that our method outperforms the state-of-the-art on challenging tasks with only a limited budget of experience.
From Culture to Clothing: Discovering the World Events Behind A Century of Fashion Images
Feb 02, 2021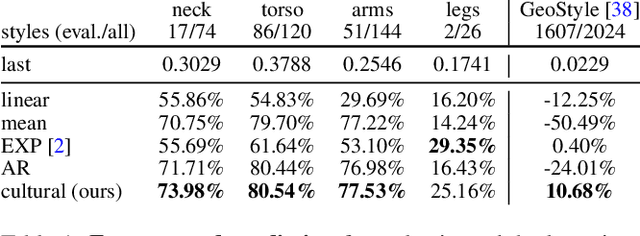


Fashion is intertwined with external cultural factors, but identifying these links remains a manual process limited to only the most salient phenomena. We propose a data-driven approach to identify specific cultural factors affecting the clothes people wear. Using large-scale datasets of news articles and vintage photos spanning a century, we introduce a multi-modal statistical model to detect influence relationships between happenings in the world and people's choice of clothing. Furthermore, we apply our model to improve the concrete vision tasks of visual style forecasting and photo timestamping on two datasets. Our work is a first step towards a computational, scalable, and easily refreshable approach to link culture to clothing.
VisualVoice: Audio-Visual Speech Separation with Cross-Modal Consistency
Jan 08, 2021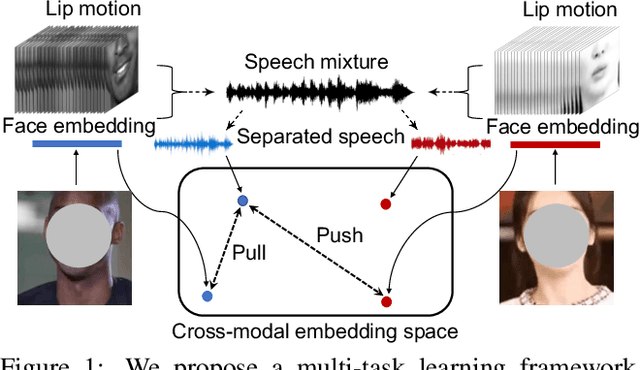
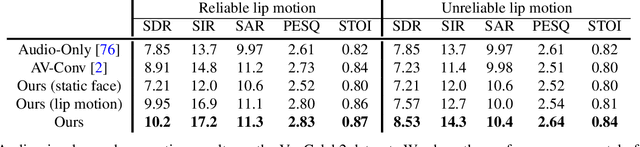
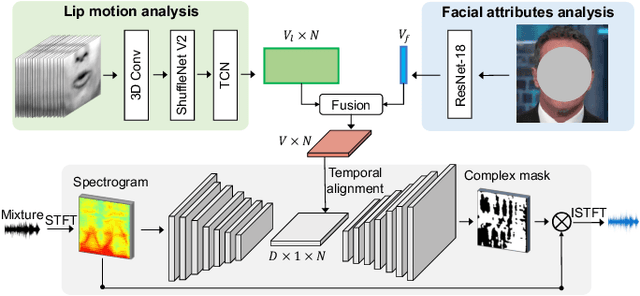
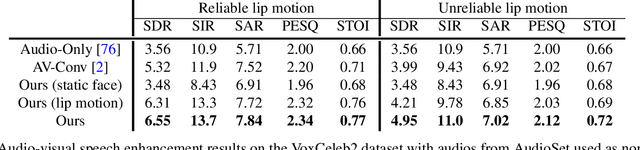
We introduce a new approach for audio-visual speech separation. Given a video, the goal is to extract the speech associated with a face in spite of simultaneous background sounds and/or other human speakers. Whereas existing methods focus on learning the alignment between the speaker's lip movements and the sounds they generate, we propose to leverage the speaker's face appearance as an additional prior to isolate the corresponding vocal qualities they are likely to produce. Our approach jointly learns audio-visual speech separation and cross-modal speaker embeddings from unlabeled video. It yields state-of-the-art results on five benchmark datasets for audio-visual speech separation and enhancement, and generalizes well to challenging real-world videos of diverse scenarios. Our video results and code: http://vision.cs.utexas.edu/projects/VisualVoice/.
Audio-Visual Floorplan Reconstruction
Dec 31, 2020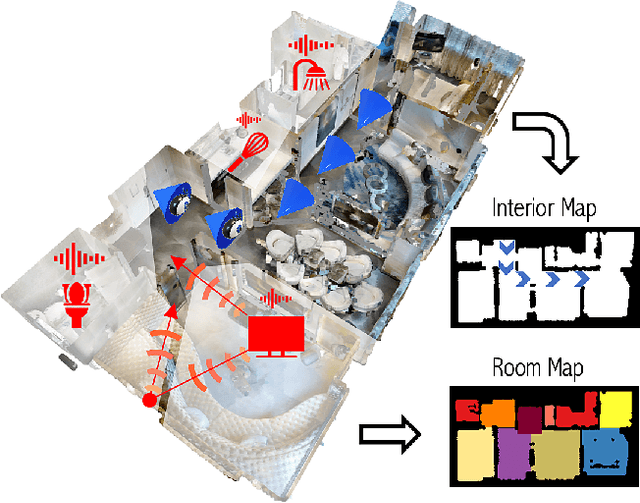
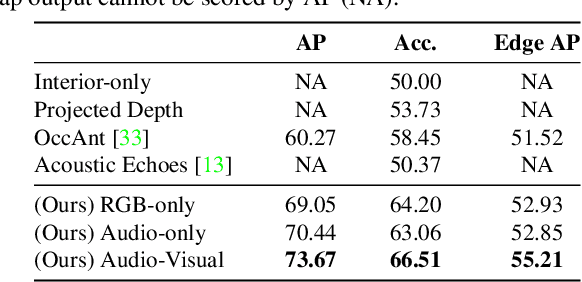
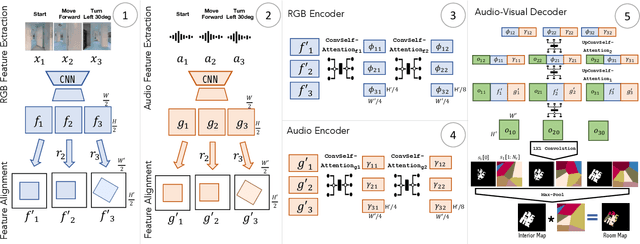
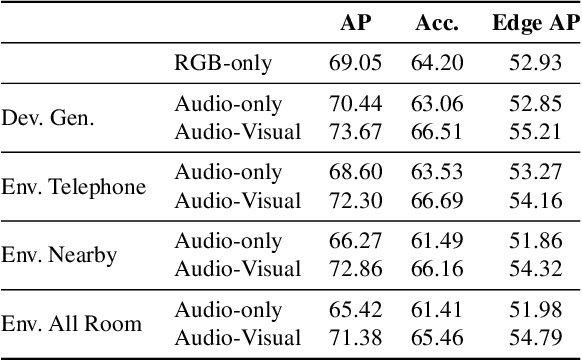
Given only a few glimpses of an environment, how much can we infer about its entire floorplan? Existing methods can map only what is visible or immediately apparent from context, and thus require substantial movements through a space to fully map it. We explore how both audio and visual sensing together can provide rapid floorplan reconstruction from limited viewpoints. Audio not only helps sense geometry outside the camera's field of view, but it also reveals the existence of distant freespace (e.g., a dog barking in another room) and suggests the presence of rooms not visible to the camera (e.g., a dishwasher humming in what must be the kitchen to the left). We introduce AV-Map, a novel multi-modal encoder-decoder framework that reasons jointly about audio and vision to reconstruct a floorplan from a short input video sequence. We train our model to predict both the interior structure of the environment and the associated rooms' semantic labels. Our results on 85 large real-world environments show the impact: with just a few glimpses spanning 26% of an area, we can estimate the whole area with 66% accuracy -- substantially better than the state of the art approach for extrapolating visual maps.
Semantic Audio-Visual Navigation
Dec 21, 2020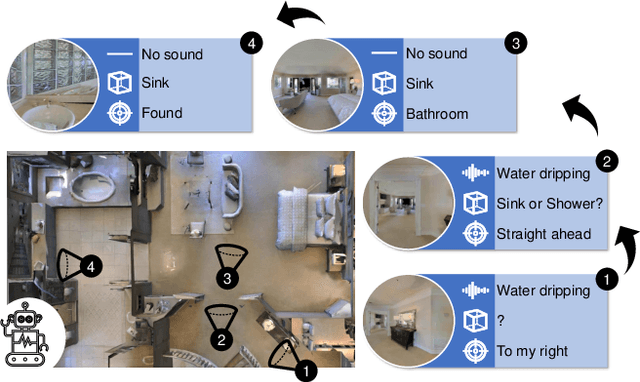
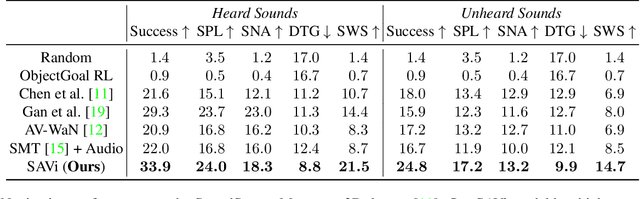
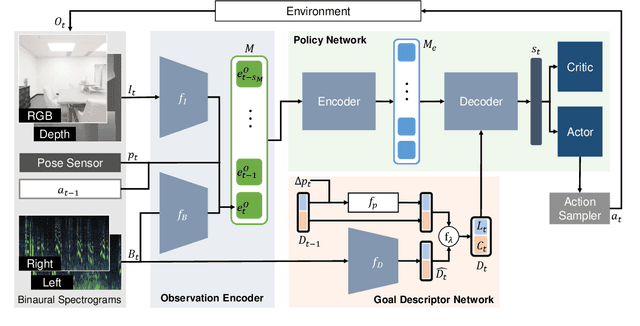
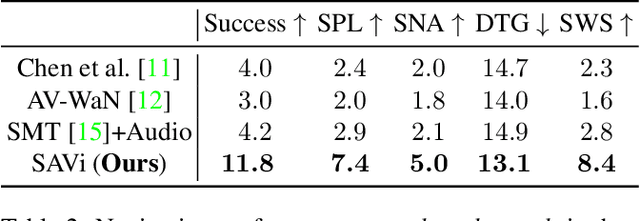
Recent work on audio-visual navigation assumes a constantly-sounding target and restricts the role of audio to signaling the target's spatial placement. We introduce semantic audio-visual navigation, where objects in the environment make sounds consistent with their semantic meanings (e.g., toilet flushing, door creaking) and acoustic envents are sporadic or short in duration. We propose a transformer-based model to tackle this new semantic AudioGoal task, incorporating an inferred goal descriptor that captures both spatial and semantic properties of the target. Our model's persistent multimodal memory enables it to reach the goal even long after the acoustic event stops. In support of the new task, we also expand the SoundSpaces audio simulation platform to provide semantically grounded object sounds for an array of objects in Matterport3D. Our method strongly outperforms existing audio-visual navigation methods by learning to associate semantic, acoustic, and visual cues.
Discovering Underground Maps from Fashion
Dec 04, 2020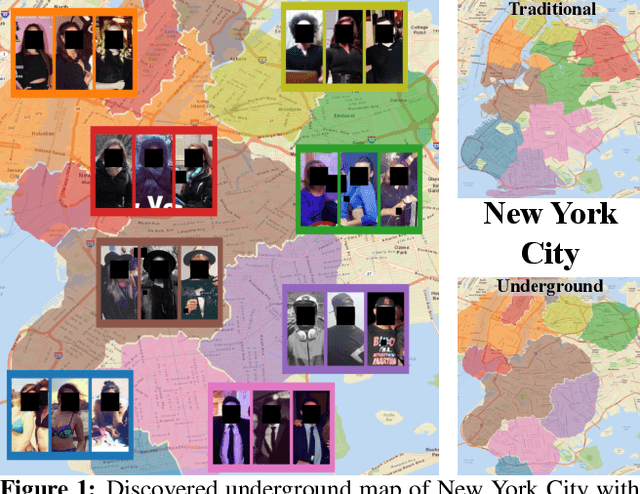
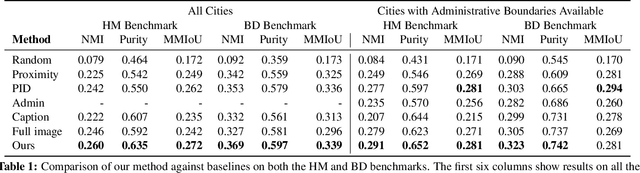
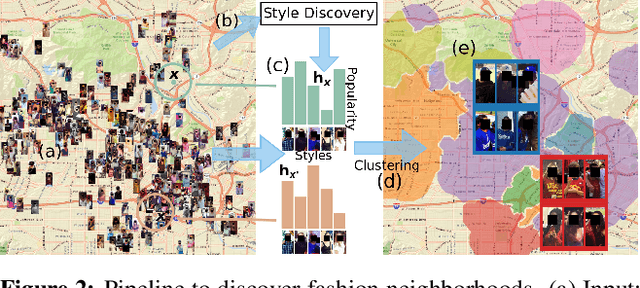
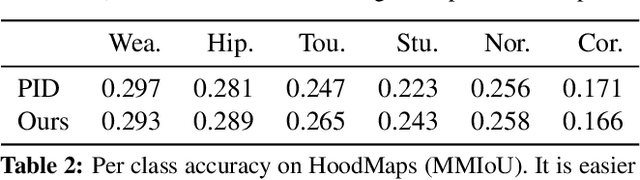
The fashion sense -- meaning the clothing styles people wear -- in a geographical region can reveal information about that region. For example, it can reflect the kind of activities people do there, or the type of crowds that frequently visit the region (e.g., tourist hot spot, student neighborhood, business center). We propose a method to automatically create underground neighborhood maps of cities by analyzing how people dress. Using publicly available images from across a city, our method finds neighborhoods with a similar fashion sense and segments the map without supervision. For 37 cities worldwide, we show promising results in creating good underground maps, as evaluated using experiments with human judges and underground map benchmarks derived from non-image data. Our approach further allows detecting distinct neighborhoods (what is the most unique region of LA?) and answering analogy questions between cities (what is the "Downtown LA" of Bogota?).
Modeling Fashion Influence from Photos
Nov 17, 2020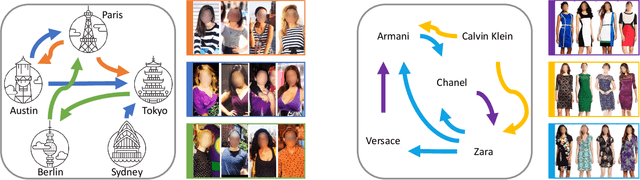
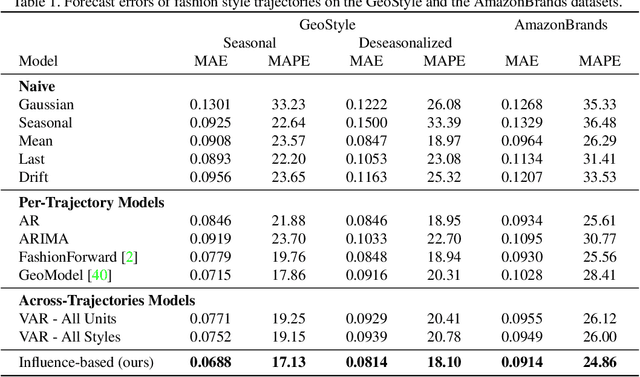

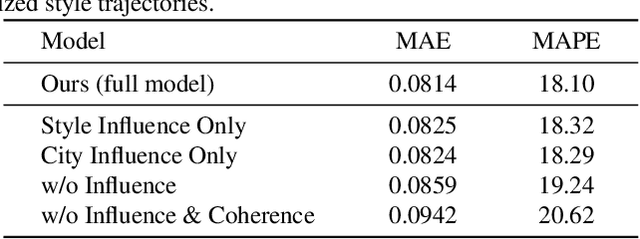
The evolution of clothing styles and their migration across the world is intriguing, yet difficult to describe quantitatively. We propose to discover and quantify fashion influences from catalog and social media photos. We explore fashion influence along two channels: geolocation and fashion brands. We introduce an approach that detects which of these entities influence which other entities in terms of propagating their styles. We then leverage the discovered influence patterns to inform a novel forecasting model that predicts the future popularity of any given style within any given city or brand. To demonstrate our idea, we leverage public large-scale datasets of 7.7M Instagram photos from 44 major world cities (where styles are worn with variable frequency) as well as 41K Amazon product photos (where styles are purchased with variable frequency). Our model learns directly from the image data how styles move between locations and how certain brands affect each other's designs in a predictable way. The discovered influence relationships reveal how both cities and brands exert and receive fashion influence for an array of visual styles inferred from the images. Furthermore, the proposed forecasting model achieves state-of-the-art results for challenging style forecasting tasks. Our results indicate the advantage of grounding visual style evolution both spatially and temporally, and for the first time, they quantify the propagation of inter-brand and inter-city influences.
Dexterous Robotic Grasping with Object-Centric Visual Affordances
Sep 03, 2020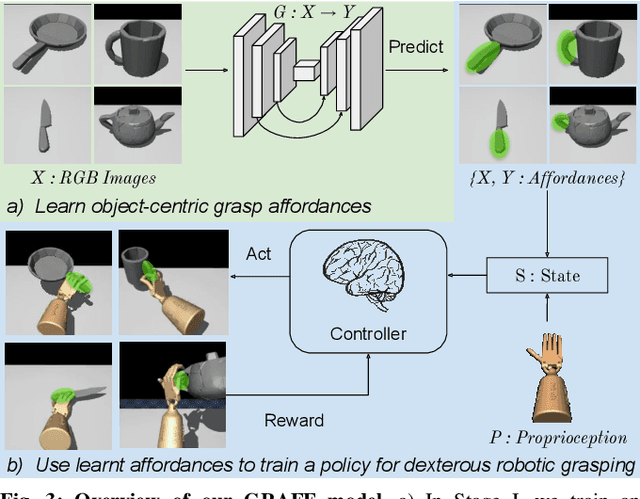
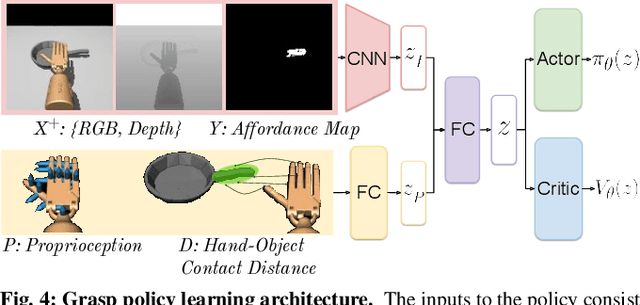

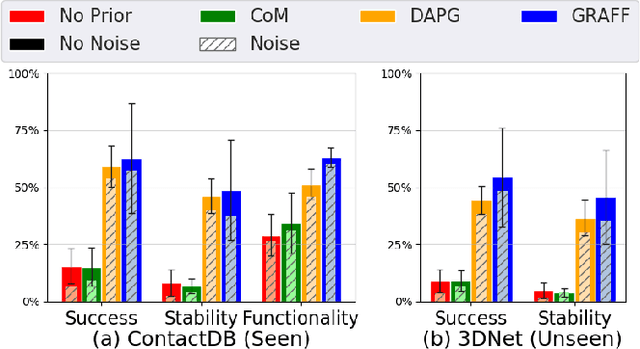
Dexterous robotic hands are appealing for their agility and human-like morphology, yet their high degree of freedom makes learning to manipulate challenging. We introduce an approach for learning dexterous grasping. Our key idea is to embed an object-centric visual affordance model within a deep reinforcement learning loop to learn grasping policies that favor the same object regions favored by people. Unlike traditional approaches that learn from human demonstration trajectories (e.g., hand joint sequences captured with a glove), the proposed prior is object-centric and image-based, allowing the agent to anticipate useful affordance regions for objects unseen during policy learning. We demonstrate our idea with a 30-DoF five-fingered robotic hand simulator on 40 objects from two datasets, where it successfully and efficiently learns policies for stable grasps. Our affordance-guided policies are significantly more effective, generalize better to novel objects, and train 3 X faster than the baselines. Our work offers a step towards manipulation agents that learn by watching how people use objects, without requiring state and action information about the human body. Project website: http://vision.cs.utexas.edu/projects/graff-dexterous-affordance-grasp
Occupancy Anticipation for Efficient Exploration and Navigation
Aug 25, 2020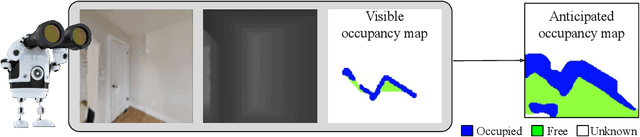
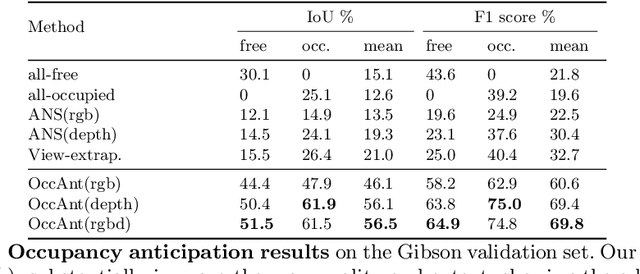
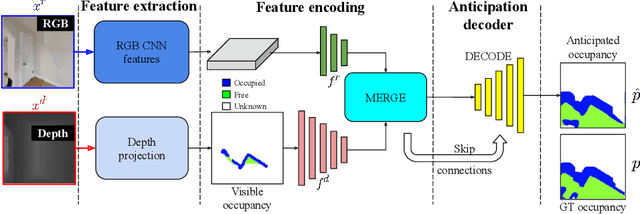
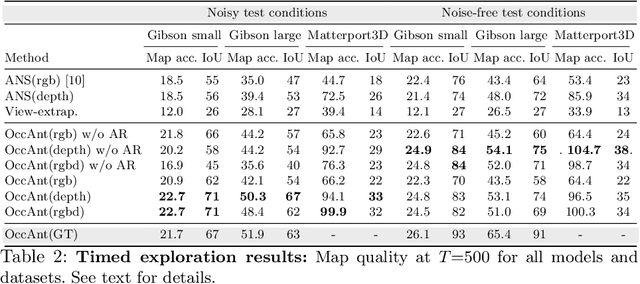
State-of-the-art navigation methods leverage a spatial memory to generalize to new environments, but their occupancy maps are limited to capturing the geometric structures directly observed by the agent. We propose occupancy anticipation, where the agent uses its egocentric RGB-D observations to infer the occupancy state beyond the visible regions. In doing so, the agent builds its spatial awareness more rapidly, which facilitates efficient exploration and navigation in 3D environments. By exploiting context in both the egocentric views and top-down maps our model successfully anticipates a broader map of the environment, with performance significantly better than strong baselines. Furthermore, when deployed for the sequential decision-making tasks of exploration and navigation, our model outperforms state-of-the-art methods on the Gibson and Matterport3D datasets. Our approach is the winning entry in the 2020 Habitat PointNav Challenge. Project page: http://vision.cs.utexas.edu/projects/occupancy_anticipation/