 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrelated Noise Provably Beats Independent Noise for Differentially Private Learning
Oct 10, 2023



Differentially private learning algorithms inject noise into the learning process. While the most common private learning algorithm, DP-SGD, adds independent Gaussian noise in each iteration, recent work on matrix factorization mechanisms has shown empirically that introducing correlations in the noise can greatly improve their utility. We characterize the asymptotic learning utility for any choice of the correlation function, giving precise analytical bounds for linear regression and as the solution to a convex program for general convex functions. We show, using these bounds, how correlated noise provably improves upon vanilla DP-SGD as a function of problem parameters such as the effective dimension and condition number. Moreover, our analytical expression for the near-optimal correlation function circumvents the cubic complexity of the semi-definite program used to optimize the noise correlation matrix in previous work. We validate our theory with experiments on private deep learning. Our work matches or outperforms prior work while being efficient both in terms of compute and memory.
Learning to Receive Help: Intervention-Aware Concept Embedding Models
Sep 29, 2023



Concept Bottleneck Models (CBMs) tackle the opacity of neural architectures by constructing and explaining their predictions using a set of high-level concepts. A special property of these models is that they permit concept interventions, wherein users can correct mispredicted concepts and thus improve the model's performance. Recent work, however, has shown that intervention efficacy can be highly dependent on the order in which concepts are intervened on and on the model's architecture and training hyperparameters. We argue that this is rooted in a CBM's lack of train-time incentives for the model to be appropriately receptive to concept interventions. To address this, we propose Intervention-aware Concept Embedding models (IntCEMs), a novel CBM-based architecture and training paradigm that improves a model's receptiveness to test-time interventions. Our model learns a concept intervention policy in an end-to-end fashion from where it can sample meaningful intervention trajectories at train-time. This conditions IntCEMs to effectively select and receive concept interventions when deployed at test-time. Our experiments show that IntCEMs significantly outperform state-of-the-art concept-interpretable models when provided with test-time concept interventions, demonstrating the effectiveness of our approach.
Selective Concept Models: Permitting Stakeholder Customisation at Test-Time
Jun 14, 2023Concept-based models perform prediction using a set of concepts that are interpretable to stakeholders. However, such models often involve a fixed, large number of concepts, which may place a substantial cognitive load on stakeholders. We propose Selective COncept Models (SCOMs) which make predictions using only a subset of concepts and can be customised by stakeholders at test-time according to their preferences. We show that SCOMs only require a fraction of the total concepts to achieve optimal accuracy on multiple real-world datasets. Further, we collect and release a new dataset, CUB-Sel, consisting of human concept set selections for 900 bird images from the popular CUB dataset. Using CUB-Sel, we show that humans have unique individual preferences for the choice of concepts they prefer to reason about, and struggle to identify the most theoretically informative concepts. The customisation and concept selection provided by SCOM improves the efficiency of interpretation and intervention for stakeholders.
Training Private Models That Know What They Don't Know
May 28, 2023Training reliable deep learning models which avoid making overconfident but incorrect predictions is a longstanding challenge. This challenge is further exacerbated when learning has to be differentially private: protection provided to sensitive data comes at the price of injecting additional randomness into the learning process. In this work, we conduct a thorough empirical investigation of selective classifiers -- that can abstain when they are unsure -- under a differential privacy constraint. We find that several popular selective prediction approaches are ineffective in a differentially private setting as they increase the risk of privacy leakage. At the same time, we identify that a recent approach that only uses checkpoints produced by an off-the-shelf private learning algorithm stands out as particularly suitable under DP. Further, we show that differential privacy does not just harm utility but also degrades selective classification performance. To analyze this effect across privacy levels, we propose a novel evaluation mechanism which isolate selective prediction performance across model utility levels. Our experimental results show that recovering the performance level attainable by non-private models is possible but comes at a considerable coverage cost as the privacy budget decreases.
Expressive Losses for Verified Robustness via Convex Combinations
May 23, 2023



In order to train networks for verified adversarial robustness, previous work typically over-approximates the worst-case loss over (subsets of) perturbation regions or induces verifiability on top of adversarial training. The key to state-of-the-art performance lies in the expressivity of the employed loss function, which should be able to match the tightness of the verifiers to be employed post-training. We formalize a definition of expressivity, and show that it can be satisfied via simple convex combinations between adversarial attacks and IBP bounds. We then show that the resulting algorithms, named CC-IBP and MTL-IBP, yield state-of-the-art results across a variety of settings in spite of their conceptual simplicity. In particular, for $\ell_\infty$ perturbations of radius $\frac{1}{255}$ on TinyImageNet and downscaled ImageNet, MTL-IBP improves on the best standard and verified accuracies from the literature by from $1.98\%$ to $3.92\%$ points while only relying on single-step adversarial attacks.
Human Uncertainty in Concept-Based AI Systems
Mar 22, 2023Placing a human in the loop may abate the risks of deploying AI systems in safety-critical settings (e.g., a clinician working with a medical AI system). However, mitigating risks arising from human error and uncertainty within such human-AI interactions is an important and understudied issue. In this work, we study human uncertainty in the context of concept-based models, a family of AI systems that enable human feedback via concept interventions where an expert intervenes on human-interpretable concepts relevant to the task. Prior work in this space often assumes that humans are oracles who are always certain and correct. Yet, real-world decision-making by humans is prone to occasional mistakes and uncertainty. We study how existing concept-based models deal with uncertain interventions from humans using two novel datasets: UMNIST, a visual dataset with controlled simulated uncertainty based on the MNIST dataset, and CUB-S, a relabeling of the popular CUB concept dataset with rich, densely-annotated soft labels from humans. We show that training with uncertain concept labels may help mitigate weaknesses of concept-based systems when handling uncertain interventions. These results allow us to identify several open challenges, which we argue can be tackled through future multidisciplinary research on building interactive uncertainty-aware systems. To facilitate further research, we release a new elicitation platform, UElic, to collect uncertain feedback from humans in collaborative prediction tasks.
Provably Bounding Neural Network Preimages
Feb 07, 2023Most work on the formal verification of neural networks has focused on bounding forward images of neural networks, i.e., the set of outputs of a neural network that correspond to a given set of inputs (for example, bounded perturbations of a nominal input). However, many use cases of neural network verification require solving the inverse problem, i.e, over-approximating the set of inputs that lead to certain outputs. In this work, we present the first efficient bound propagation algorithm, INVPROP, for verifying properties over the preimage of a linearly constrained output set of a neural network, which can be combined with branch-and-bound to achieve completeness. Our efficient algorithm allows multiple passes of intermediate bound refinements, which are crucial for tight inverse verification because the bounds of an intermediate layer depend on relaxations both before and after this layer. We demonstrate our algorithm on applications related to quantifying safe control regions for a dynamical system and detecting out-of-distribution inputs to a neural network. Our results show that in certain settings, we can find over-approximations that are over 2500 times tighter than prior work while being 2.5 times faster on the same hardware.
Interactive Concept Bottleneck Models
Dec 26, 2022



Concept bottleneck models (CBMs) (Koh et al. 2020) are interpretable neural networks that first predict labels for human-interpretable concepts relevant to the prediction task, and then predict the final label based on the concept label predictions.We extend CBMs to interactive prediction settings where the model can query a human collaborator for the label to some concepts. We develop an interaction policy that, at prediction time, chooses which concepts to request a label for so as to maximally improve the final prediction. We demonstrate thata simple policy combining concept prediction uncertainty and influence of the concept on the final prediction achieves strong performance and outperforms a static approach proposed in Koh et al. (2020) as well as active feature acquisition methods proposed in the literature. We show that the interactiveCBM can achieve accuracy gains of 5-10% with only 5 interactions over competitive baselines on the Caltech-UCSDBirds, CheXpert and OAI datasets.
IBP Regularization for Verified Adversarial Robustness via Branch-and-Bound
Jun 29, 2022
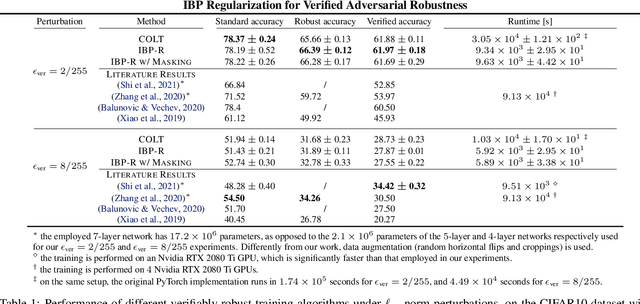
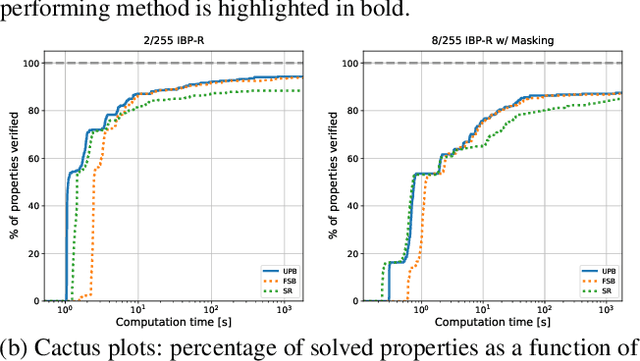
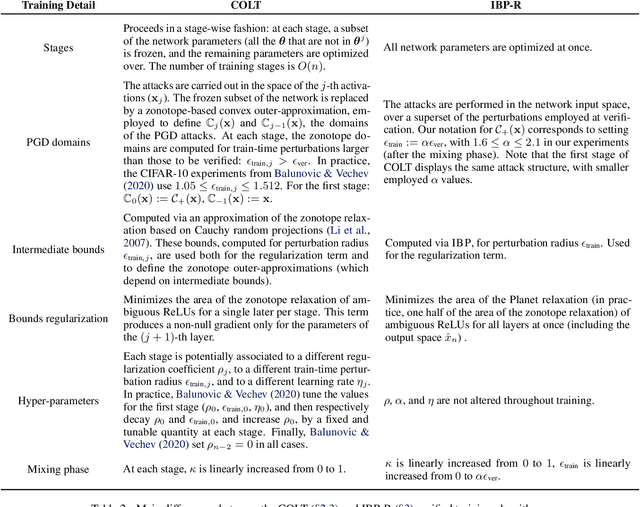
Recent works have tried to increase the verifiability of adversarially trained networks by running the attacks over domains larger than the original perturbations and adding various regularization terms to the objective. However, these algorithms either underperform or require complex and expensive stage-wise training procedures, hindering their practical applicability. We present IBP-R, a novel verified training algorithm that is both simple and effective. IBP-R induces network verifiability by coupling adversarial attacks on enlarged domains with a regularization term, based on inexpensive interval bound propagation, that minimizes the gap between the non-convex verification problem and its approximations. By leveraging recent branch-and-bound frameworks, we show that IBP-R obtains state-of-the-art verified robustness-accuracy trade-offs for small perturbations on CIFAR-10 while training significantly faster than relevant previous work. Additionally, we present UPB, a novel branching strategy that, relying on a simple heuristic based on $\beta$-CROWN, reduces the cost of state-of-the-art branching algorithms while yielding splits of comparable quality.
Role of Human-AI Interaction in Selective Prediction
Dec 13, 2021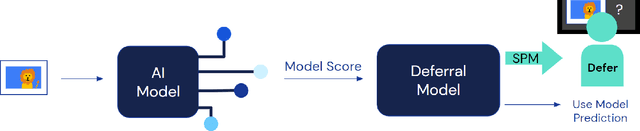
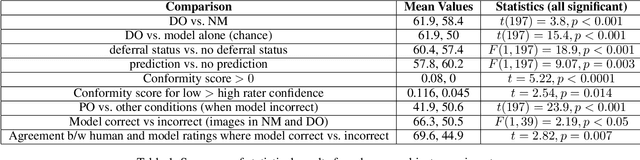

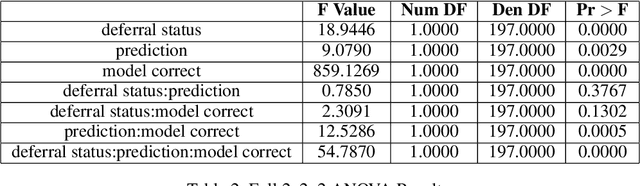
Recent work has shown the potential benefit of selective prediction systems that can learn to defer to a human when the predictions of the AI are unreliable, particularly to improve the reliability of AI systems in high-stakes applications like healthcare or conservation. However, most prior work assumes that human behavior remains unchanged when they solve a prediction task as part of a human-AI team as opposed to by themselves. We show that this is not the case by performing experiments to quantify human-AI interaction in the context of selective prediction. In particular, we study the impact of communicating different types of information to humans about the AI system's decision to defer. Using real-world conservation data and a selective prediction system that improves expected accuracy over that of the human or AI system working individually, we show that this messaging has a significant impact on the accuracy of human judgements. Our results study two components of the messaging strategy: 1) Whether humans are informed about the prediction of the AI system and 2) Whether they are informed about the decision of the selective prediction system to defer. By manipulating these messaging components, we show that it is possible to significantly boost human performance by informing the human of the decision to defer, but not revealing the prediction of the AI. We therefore show that it is vital to consider how the decision to defer is communicated to a human when designing selective prediction systems, and that the composite accuracy of a human-AI team must be carefully evaluated using a human-in-the-loop framework.