 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Bird Reconstruction: a Dataset, Model, and Shape Recovery from a Single View
Aug 13, 2020



Automated capture of animal pose is transforming how we study neuroscience and social behavior. Movements carry important social cues, but current methods are not able to robustly estimate pose and shape of animals, particularly for social animals such as birds, which are often occluded by each other and objects in the environment. To address this problem, we first introduce a model and multi-view optimization approach, which we use to capture the unique shape and pose space displayed by live birds. We then introduce a pipeline and experiments for keypoint, mask, pose, and shape regression that recovers accurate avian postures from single views. Finally, we provide extensive multi-view keypoint and mask annotations collected from a group of 15 social birds housed together in an outdoor aviary. The project website with videos, results, code, mesh model, and the Penn Aviary Dataset can be found at https://marcbadger.github.io/avian-mesh.
TLIO: Tight Learned Inertial Odometry
Jul 10, 2020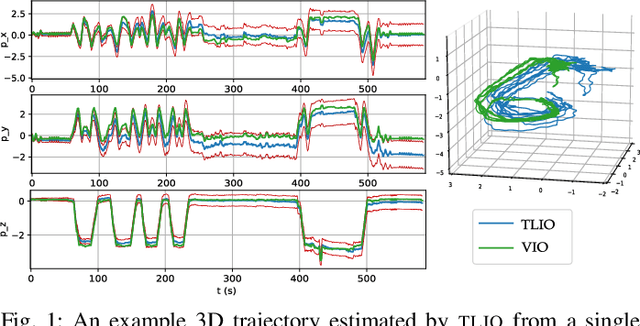
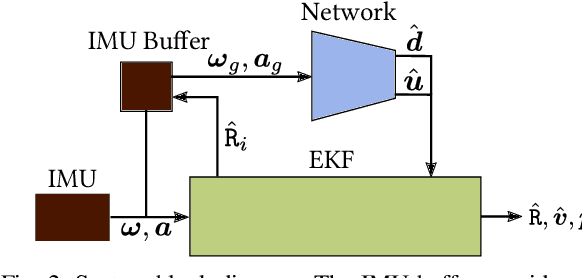
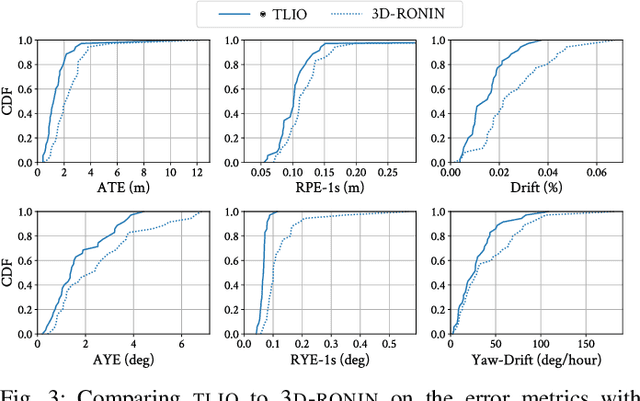
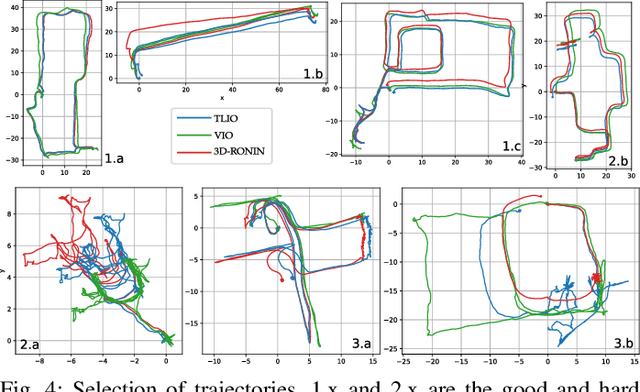
In this work we propose a tightly-coupled Extended Kalman Filter framework for IMU-only state estimation. Strap-down IMU measurements provide relative state estimates based on IMU kinematic motion model. However the integration of measurements is sensitive to sensor bias and noise, causing significant drift within seconds. Recent research by Yan et al. (RoNIN) and Chen et al. (IONet) showed the capability of using trained neural networks to obtain accurate 2D displacement estimates from segments of IMU data and obtained good position estimates from concatenating them. This paper demonstrates a network that regresses 3D displacement estimates and its uncertainty, giving us the ability to tightly fuse the relative state measurement into a stochastic cloning EKF to solve for pose, velocity and sensor biases. We show that our network, trained with pedestrian data from a headset, can produce statistically consistent measurement and uncertainty to be used as the update step in the filter, and the tightly-coupled system outperforms velocity integration approaches in position estimates, and AHRS attitude filter in orientation estimates.
Simple and Effective VAE Training with Calibrated Decoders
Jun 23, 2020


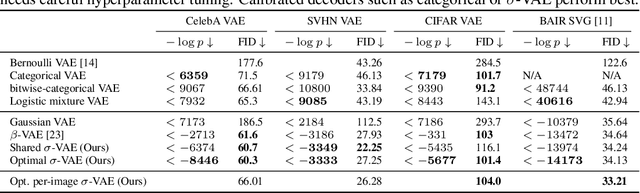
Variational autoencoders (VAEs) provide an effective and simple method for modeling complex distributions. However, training VAEs often requires considerable hyperparameter tuning, and often utilizes a heuristic weight on the prior KL-divergence term. In this work, we study how the performance of VAEs can be improved while not requiring the use of this heuristic hyperparameter, by learning calibrated decoders that accurately model the decoding distribution. While in some sense it may seem obvious that calibrated decoders should perform better than uncalibrated decoders, much of the recent literature that employs VAEs uses uncalibrated Gaussian decoders with constant variance. We observe empirically that the na\"{i}ve way of learning variance in Gaussian decoders does not lead to good results. However, {other calibrated decoders, such as discrete decoders or learning shared variance} can substantially improve performance. To further improve results, we propose a simple but novel modification to the commonly used Gaussian decoder, which represents the prediction variance non-parametrically. We observe empirically that using the heuristic weight hyperparameter is not necessary with our method. We analyze the performance of various discrete and continuous decoders on a range of datasets and several single-image and sequential VAE models. Project website: \url{https://orybkin.github.io/sigma-vae/}
Spin-Weighted Spherical CNNs
Jun 18, 2020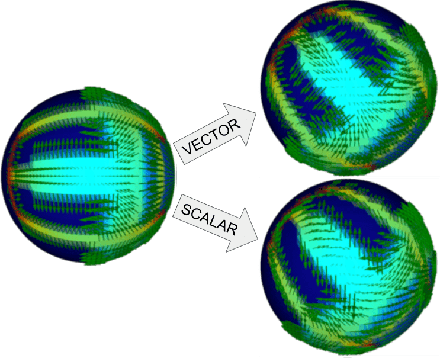
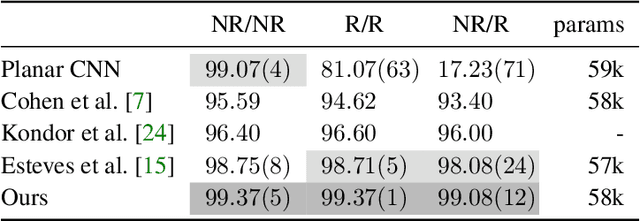
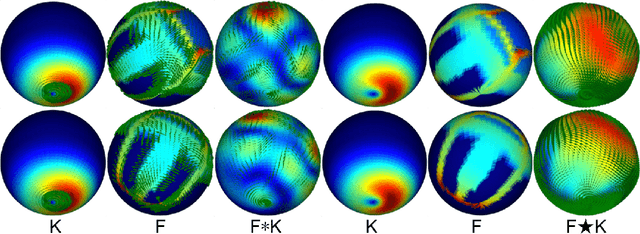
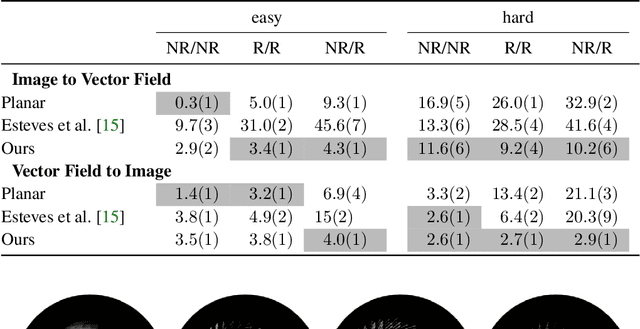
Learning equivariant representations is a promising way to reduce sample and model complexity and improve the generalization performance of deep neural networks. The spherical CNNs are successful examples, producing SO(3)-equivariant representations of spherical inputs. There are two main types of spherical CNNs. The first type lifts the inputs to functions on the rotation group SO(3) and applies convolutions on the group, which are computationally expensive since SO(3) has one extra dimension. The second type applies convolutions directly on the sphere, which are limited to zonal (isotropic) filters, and thus have limited expressivity. In this paper, we present a new type of spherical CNN that allows anisotropic filters in an efficient way, without ever leaving the spherical domain. The key idea is to consider spin-weighted spherical functions, which were introduced in physics in the study of gravitational waves. These are complex-valued functions on the sphere whose phases change upon rotation. We define a convolution between spin-weighted functions and build a CNN based on it. Experiments show that our method outperforms the isotropic spherical CNNs while still being much more efficient than using SO(3) convolutions. The spin-weighted functions can also be interpreted as spherical vector fields, allowing applications to tasks where the inputs or outputs are vector fields.
Coherent Reconstruction of Multiple Humans from a Single Image
Jun 15, 2020
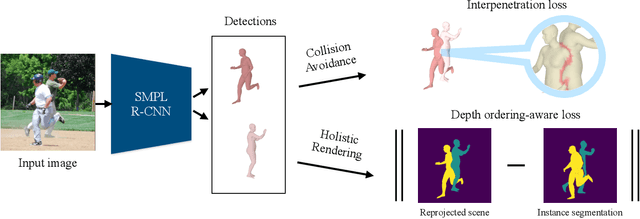
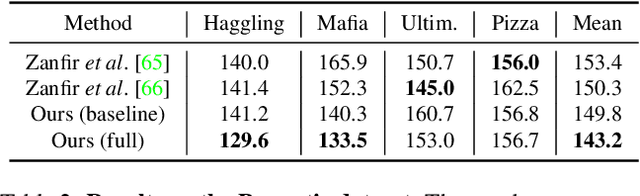
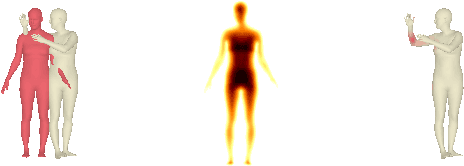
In this work, we address the problem of multi-person 3D pose estimation from a single image. A typical regression approach in the top-down setting of this problem would first detect all humans and then reconstruct each one of them independently. However, this type of prediction suffers from incoherent results, e.g., interpenetration and inconsistent depth ordering between the people in the scene. Our goal is to train a single network that learns to avoid these problems and generate a coherent 3D reconstruction of all the humans in the scene. To this end, a key design choice is the incorporation of the SMPL parametric body model in our top-down framework, which enables the use of two novel losses. First, a distance field-based collision loss penalizes interpenetration among the reconstructed people. Second, a depth ordering-aware loss reasons about occlusions and promotes a depth ordering of people that leads to a rendering which is consistent with the annotated instance segmentation. This provides depth supervision signals to the network, even if the image has no explicit 3D annotations. The experiments show that our approach outperforms previous methods on standard 3D pose benchmarks, while our proposed losses enable more coherent reconstruction in natural images. The project website with videos, results, and code can be found at: https://jiangwenpl.github.io/multiperson
Planning to Explore via Self-Supervised World Models
May 12, 2020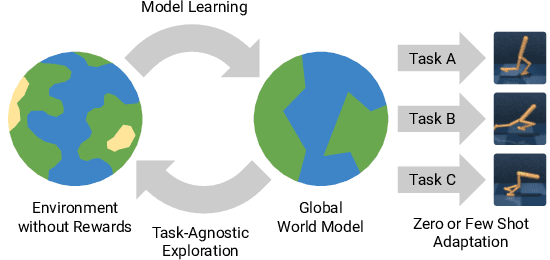
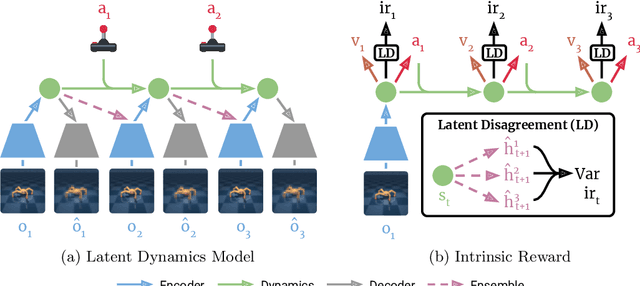
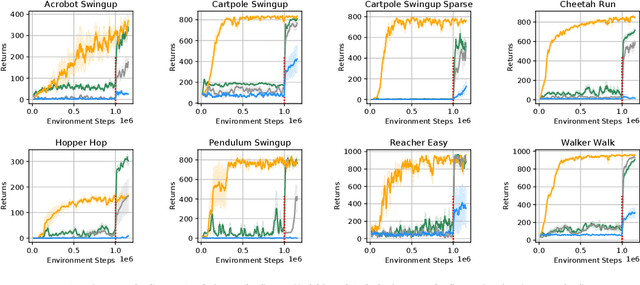
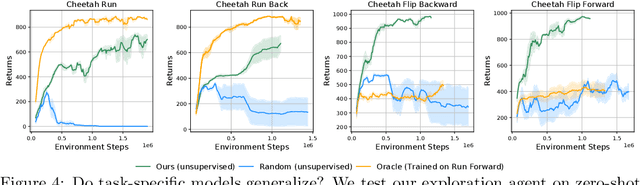
Reinforcement learning allows solving complex tasks, however, the learning tends to be task-specific and the sample efficiency remains a challenge. We present Plan2Explore, a self-supervised reinforcement learning agent that tackles both these challenges through a new approach to self-supervised exploration and fast adaptation to new tasks, which need not be known during exploration. During exploration, unlike prior methods which retrospectively compute the novelty of observations after the agent has already reached them, our agent acts efficiently by leveraging planning to seek out expected future novelty. After exploration, the agent quickly adapts to multiple downstream tasks in a zero or a few-shot manner. We evaluate on challenging control tasks from high-dimensional image inputs. Without any training supervision or task-specific interaction, Plan2Explore outperforms prior self-supervised exploration methods, and in fact, almost matches the performances oracle which has access to rewards. Videos and code at https://ramanans1.github.io/plan2explore/
Spike-FlowNet: Event-based Optical Flow Estimation with Energy-Efficient Hybrid Neural Networks
Mar 14, 2020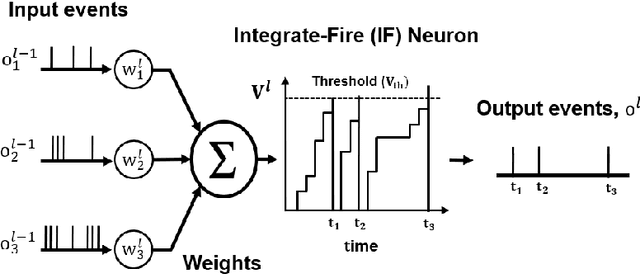
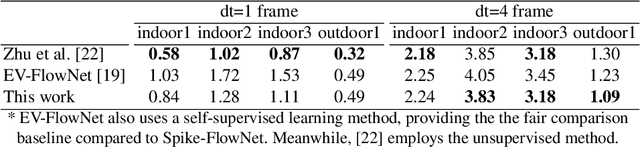
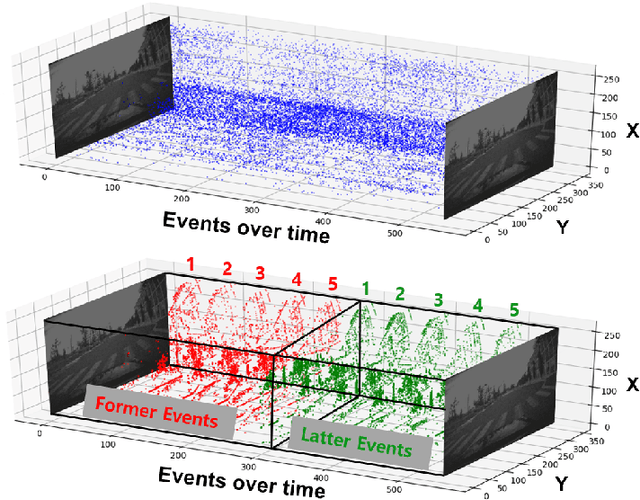
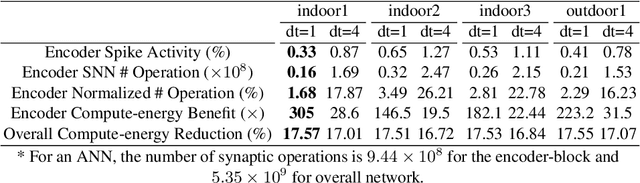
Event-based cameras display great potential for a variety of conditions such as high-speed motion detection and enabling navigation in low-light environments where conventional frame-based cameras suffer critically. This is attributed to their high temporal resolution, high dynamic range, and low-power consumption. However, conventional computer vision methods as well as deep Analog Neural Networks (ANNs) are not suited to work well with the asynchronous and discrete nature of event camera outputs. Spiking Neural Networks (SNNs) serve as ideal paradigms to handle event camera outputs, but deep SNNs suffer in terms of performance due to spike vanishing phenomenon. To overcome these issues, we present Spike-FlowNet, a deep hybrid neural network architecture integrating SNNs and ANNs for efficiently estimating optical flow from sparse event camera outputs without sacrificing the performance. The network is end-to-end trained with self-supervised learning on Multi-Vehicle Stereo Event Camera (MVSEC) dataset. Spike-FlowNet outperforms its corresponding ANN-based method in terms of the optical flow prediction capability while providing significant computational efficiency.
Action for Better Prediction
Mar 13, 2020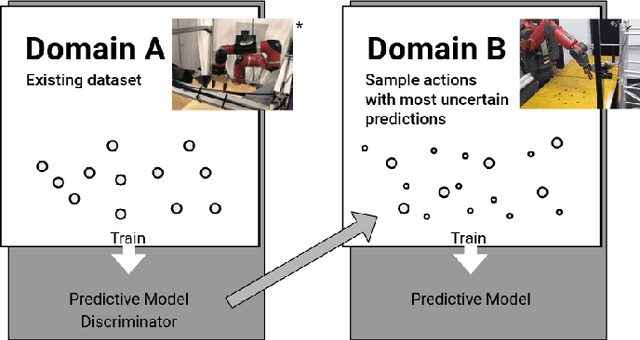


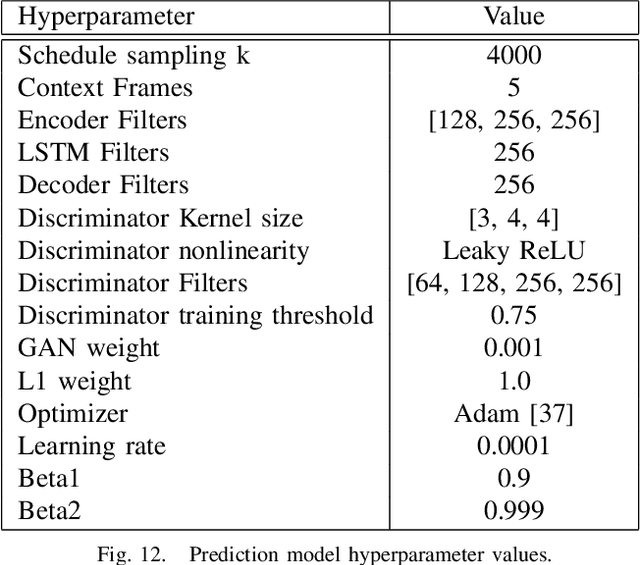
Good prediction is necessary for autonomous robotics to make informed decisions in dynamic environments. Improvements can be made to the performance of a given data-driven prediction model by using better sampling strategies when collecting training data. Active learning approaches to optimal sampling have been combined with the mathematically general approaches to incentivizing exploration presented in the curiosity literature via model-based formulations of curiosity. We present an adversarial curiosity method which maximizes a score given by a discriminator network. This score gives a measure of prediction certainty enabling our approach to sample sequences of observations and actions which result in outcomes considered the least realistic by the discriminator. We demonstrate the ability of our active sampling method to achieve higher prediction performance and higher sample efficiency in a domain transfer problem for robotic manipulation tasks. We also present a validation dataset of action-conditioned video of robotic manipulation tasks on which we test the prediction performance of our trained models.
Technical Report: Reactive Semantic Planning in Unexplored Semantic Environments Using Deep Perceptual Feedback
Feb 28, 2020
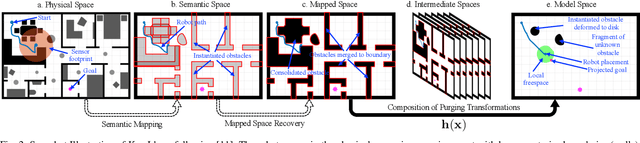


This paper presents a reactive planning system that enriches the topological representation of an environment with a tightly integrated semantic representation, achieved by incorporating and exploiting advances in deep perceptual learning and probabilistic semantic reasoning. Our architecture combines object detection with semantic SLAM, affording robust, reactive logical as well as geometric planning in unexplored environments. Moreover, by incorporating a human mesh estimation algorithm, our system is capable of reacting and responding in real time to semantically labeled human motions and gestures. New formal results allow tracking of suitably non-adversarial moving targets, while maintaining the same collision avoidance guarantees. We suggest the empirical utility of the proposed control architecture with a numerical study including comparisons with a state-of-the-art dynamic replanning algorithm, and physical implementation on both a wheeled and legged platform in different settings with both geometric and semantic goals.
Reactive Navigation in Partially Familiar Planar Environments Using Semantic Perceptual Feedback
Feb 20, 2020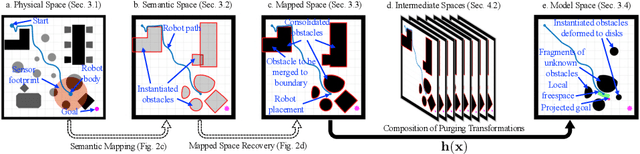

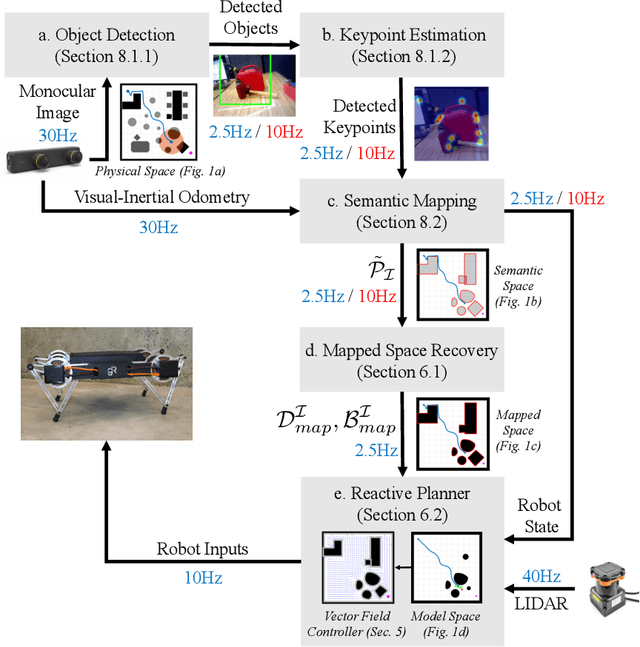

This paper solves the planar navigation problem by recourse to an online reactive scheme that exploits recent advances in SLAM and visual object recognition to recast prior geometric knowledge in terms of an offline catalogue of familiar objects. The resulting vector field planner guarantees convergence to an arbitrarily specified goal, avoiding collisions along the way with fixed but arbitrarily placed instances from the catalogue as well as completely unknown fixed obstacles so long as they are strongly convex and well separated. We illustrate the generic robustness properties of such deterministic reactive planners as well as the relatively modest computational cost of this algorithm by supplementing an extensive numerical study with physical implementation on both a wheeled and legged platform in different settings.