 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable One-shot Neural Head Avatar
Jun 14, 2023



We present a method that reconstructs and animates a 3D head avatar from a single-view portrait image. Existing methods either involve time-consuming optimization for a specific person with multiple images, or they struggle to synthesize intricate appearance details beyond the facial region. To address these limitations, we propose a framework that not only generalizes to unseen identities based on a single-view image without requiring person-specific optimization, but also captures characteristic details within and beyond the face area (e.g. hairstyle, accessories, etc.). At the core of our method are three branches that produce three tri-planes representing the coarse 3D geometry, detailed appearance of a source image, as well as the expression of a target image. By applying volumetric rendering to the combination of the three tri-planes followed by a super-resolution module, our method yields a high fidelity image of the desired identity, expression and pose. Once trained, our model enables efficient 3D head avatar reconstruction and animation via a single forward pass through a network. Experiments show that the proposed approach generalizes well to unseen validation datasets, surpassing SOTA baseline methods by a large margin on head avatar reconstruction and animation.
Avatar Fingerprinting for Authorized Use of Synthetic Talking-Head Videos
May 05, 2023



Modern generators render talking-head videos with impressive levels of photorealism, ushering in new user experiences such as videoconferencing under constrained bandwidth budgets. Their safe adoption, however, requires a mechanism to verify if the rendered video is trustworthy. For instance, for videoconferencing we must identify cases in which a synthetic video portrait uses the appearance of an individual without their consent. We term this task avatar fingerprinting. We propose to tackle it by leveraging facial motion signatures unique to each person. Specifically, we learn an embedding in which the motion signatures of one identity are grouped together, and pushed away from those of other identities, regardless of the appearance in the synthetic video. Avatar fingerprinting algorithms will be critical as talking head generators become more ubiquitous, and yet no large scale datasets exist for this new task. Therefore, we contribute a large dataset of people delivering scripted and improvised short monologues, accompanied by synthetic videos in which we render videos of one person using the facial appearance of another. Project page: https://research.nvidia.com/labs/nxp/avatar-fingerprinting/.
Single-Shot Implicit Morphable Faces with Consistent Texture Parameterization
May 04, 2023There is a growing demand for the accessible creation of high-quality 3D avatars that are animatable and customizable. Although 3D morphable models provide intuitive control for editing and animation, and robustness for single-view face reconstruction, they cannot easily capture geometric and appearance details. Methods based on neural implicit representations, such as signed distance functions (SDF) or neural radiance fields, approach photo-realism, but are difficult to animate and do not generalize well to unseen data. To tackle this problem, we propose a novel method for constructing implicit 3D morphable face models that are both generalizable and intuitive for editing. Trained from a collection of high-quality 3D scans, our face model is parameterized by geometry, expression, and texture latent codes with a learned SDF and explicit UV texture parameterization. Once trained, we can reconstruct an avatar from a single in-the-wild image by leveraging the learned prior to project the image into the latent space of our model. Our implicit morphable face models can be used to render an avatar from novel views, animate facial expressions by modifying expression codes, and edit textures by directly painting on the learned UV-texture maps. We demonstrate quantitatively and qualitatively that our method improves upon photo-realism, geometry, and expression accuracy compared to state-of-the-art methods.
Real-Time Radiance Fields for Single-Image Portrait View Synthesis
May 03, 2023



We present a one-shot method to infer and render a photorealistic 3D representation from a single unposed image (e.g., face portrait) in real-time. Given a single RGB input, our image encoder directly predicts a canonical triplane representation of a neural radiance field for 3D-aware novel view synthesis via volume rendering. Our method is fast (24 fps) on consumer hardware, and produces higher quality results than strong GAN-inversion baselines that require test-time optimization. To train our triplane encoder pipeline, we use only synthetic data, showing how to distill the knowledge from a pretrained 3D GAN into a feedforward encoder. Technical contributions include a Vision Transformer-based triplane encoder, a camera data augmentation strategy, and a well-designed loss function for synthetic data training. We benchmark against the state-of-the-art methods, demonstrating significant improvements in robustness and image quality in challenging real-world settings. We showcase our results on portraits of faces (FFHQ) and cats (AFHQ), but our algorithm can also be applied in the future to other categories with a 3D-aware image generator.
Intriguing properties of synthetic images: from generative adversarial networks to diffusion models
Apr 13, 2023Detecting fake images is becoming a major goal of computer vision. This need is becoming more and more pressing with the continuous improvement of synthesis methods based on Generative Adversarial Networks (GAN), and even more with the appearance of powerful methods based on Diffusion Models (DM). Towards this end, it is important to gain insight into which image features better discriminate fake images from real ones. In this paper we report on our systematic study of a large number of image generators of different families, aimed at discovering the most forensically relevant characteristics of real and generated images. Our experiments provide a number of interesting observations and shed light on some intriguing properties of synthetic images: (1) not only the GAN models but also the DM and VQ-GAN (Vector Quantized Generative Adversarial Networks) models give rise to visible artifacts in the Fourier domain and exhibit anomalous regular patterns in the autocorrelation; (2) when the dataset used to train the model lacks sufficient variety, its biases can be transferred to the generated images; (3) synthetic and real images exhibit significant differences in the mid-high frequency signal content, observable in their radial and angular spectral power distributions.
Generative Novel View Synthesis with 3D-Aware Diffusion Models
Apr 05, 2023We present a diffusion-based model for 3D-aware generative novel view synthesis from as few as a single input image. Our model samples from the distribution of possible renderings consistent with the input and, even in the presence of ambiguity, is capable of rendering diverse and plausible novel views. To achieve this, our method makes use of existing 2D diffusion backbones but, crucially, incorporates geometry priors in the form of a 3D feature volume. This latent feature field captures the distribution over possible scene representations and improves our method's ability to generate view-consistent novel renderings. In addition to generating novel views, our method has the ability to autoregressively synthesize 3D-consistent sequences. We demonstrate state-of-the-art results on synthetic renderings and room-scale scenes; we also show compelling results for challenging, real-world objects.
RANA: Relightable Articulated Neural Avatars
Dec 06, 2022



We propose RANA, a relightable and articulated neural avatar for the photorealistic synthesis of humans under arbitrary viewpoints, body poses, and lighting. We only require a short video clip of the person to create the avatar and assume no knowledge about the lighting environment. We present a novel framework to model humans while disentangling their geometry, texture, and also lighting environment from monocular RGB videos. To simplify this otherwise ill-posed task we first estimate the coarse geometry and texture of the person via SMPL+D model fitting and then learn an articulated neural representation for photorealistic image generation. RANA first generates the normal and albedo maps of the person in any given target body pose and then uses spherical harmonics lighting to generate the shaded image in the target lighting environment. We also propose to pretrain RANA using synthetic images and demonstrate that it leads to better disentanglement between geometry and texture while also improving robustness to novel body poses. Finally, we also present a new photorealistic synthetic dataset, Relighting Humans, to quantitatively evaluate the performance of the proposed approach.
On the detection of synthetic images generated by diffusion models
Nov 01, 2022



Over the past decade, there has been tremendous progress in creating synthetic media, mainly thanks to the development of powerful methods based on generative adversarial networks (GAN). Very recently, methods based on diffusion models (DM) have been gaining the spotlight. In addition to providing an impressive level of photorealism, they enable the creation of text-based visual content, opening up new and exciting opportunities in many different application fields, from arts to video games. On the other hand, this property is an additional asset in the hands of malicious users, who can generate and distribute fake media perfectly adapted to their attacks, posing new challenges to the media forensic community. With this work, we seek to understand how difficult it is to distinguish synthetic images generated by diffusion models from pristine ones and whether current state-of-the-art detectors are suitable for the task. To this end, first we expose the forensics traces left by diffusion models, then study how current detectors, developed for GAN-generated images, perform on these new synthetic images, especially in challenging social-networks scenarios involving image compression and resizing. Datasets and code are available at github.com/grip-unina/DMimageDetection.
Learning to Relight Portrait Images via a Virtual Light Stage and Synthetic-to-Real Adaptation
Sep 21, 2022



Given a portrait image of a person and an environment map of the target lighting, portrait relighting aims to re-illuminate the person in the image as if the person appeared in an environment with the target lighting. To achieve high-quality results, recent methods rely on deep learning. An effective approach is to supervise the training of deep neural networks with a high-fidelity dataset of desired input-output pairs, captured with a light stage. However, acquiring such data requires an expensive special capture rig and time-consuming efforts, limiting access to only a few resourceful laboratories. To address the limitation, we propose a new approach that can perform on par with the state-of-the-art (SOTA) relighting methods without requiring a light stage. Our approach is based on the realization that a successful relighting of a portrait image depends on two conditions. First, the method needs to mimic the behaviors of physically-based relighting. Second, the output has to be photorealistic. To meet the first condition, we propose to train the relighting network with training data generated by a virtual light stage that performs physically-based rendering on various 3D synthetic humans under different environment maps. To meet the second condition, we develop a novel synthetic-to-real approach to bring photorealism to the relighting network output. In addition to achieving SOTA results, our approach offers several advantages over the prior methods, including controllable glares on glasses and more temporally-consistent results for relighting videos.
* To appear in ACM Transactions on Graphics (SIGGRAPH Asia 2022). 21 pages, 25 figures, 7 tables. Project page: https://deepimagination.cc/Lumos/
RTMV: A Ray-Traced Multi-View Synthetic Dataset for Novel View Synthesis
May 14, 2022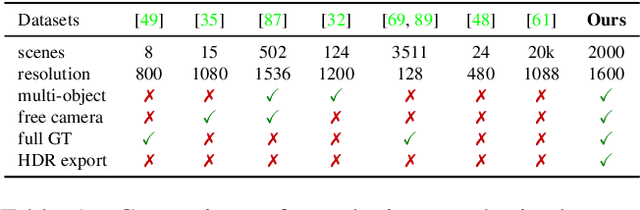


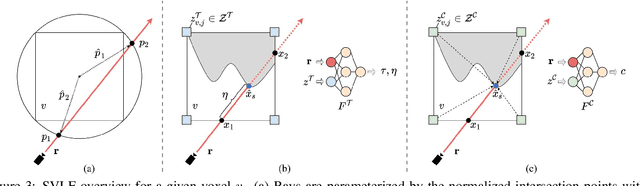
We present a large-scale synthetic dataset for novel view synthesis consisting of ~300k images rendered from nearly 2000 complex scenes using high-quality ray tracing at high resolution (1600 x 1600 pixels). The dataset is orders of magnitude larger than existing synthetic datasets for novel view synthesis, thus providing a large unified benchmark for both training and evaluation. Using 4 distinct sources of high-quality 3D meshes, the scenes of our dataset exhibit challenging variations in camera views, lighting, shape, materials, and textures. Because our dataset is too large for existing methods to process, we propose Sparse Voxel Light Field (SVLF), an efficient voxel-based light field approach for novel view synthesis that achieves comparable performance to NeRF on synthetic data, while being an order of magnitude faster to train and two orders of magnitude faster to render. SVLF achieves this speed by relying on a sparse voxel octree, careful voxel sampling (requiring only a handful of queries per ray), and reduced network structure; as well as ground truth depth maps at training time. Our dataset is generated by NViSII, a Python-based ray tracing renderer, which is designed to be simple for non-experts to use and share, flexible and powerful through its use of scripting, and able to create high-quality and physically-based rendered images. Experiments with a subset of our dataset allow us to compare standard methods like NeRF and mip-NeRF for single-scene modeling, and pixelNeRF for category-level modeling, pointing toward the need for future improvements in this area.