 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Anatomical Priors into a Causal Diffusion Model
Sep 10, 2025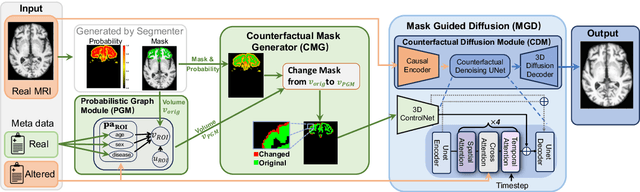
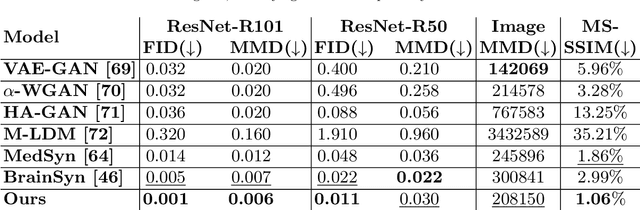
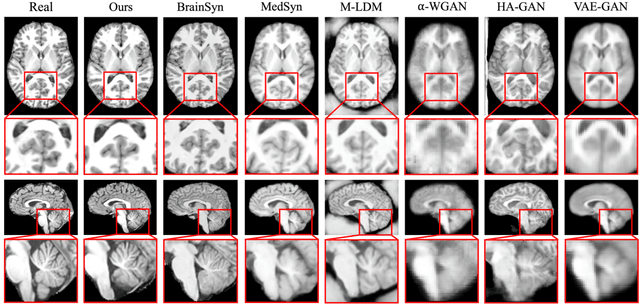
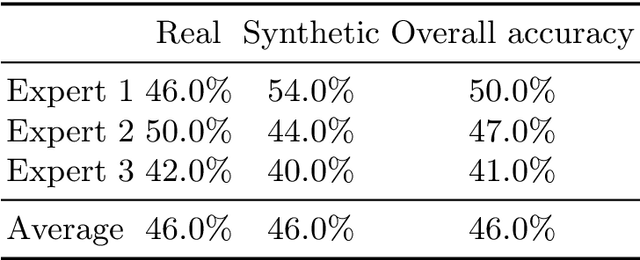
3D brain MRI studies often examine subtle morphometric differences between cohorts that are hard to detect visually. Given the high cost of MRI acquisition, these studies could greatly benefit from image syntheses, particularly counterfactual image generation, as seen in other domains, such as computer vision. However, counterfactual models struggle to produce anatomically plausible MRIs due to the lack of explicit inductive biases to preserve fine-grained anatomical details. This shortcoming arises from the training of the models aiming to optimize for the overall appearance of the images (e.g., via cross-entropy) rather than preserving subtle, yet medically relevant, local variations across subjects. To preserve subtle variations, we propose to explicitly integrate anatomical constraints on a voxel-level as prior into a generative diffusion framework. Called Probabilistic Causal Graph Model (PCGM), the approach captures anatomical constraints via a probabilistic graph module and translates those constraints into spatial binary masks of regions where subtle variations occur. The masks (encoded by a 3D extension of ControlNet) constrain a novel counterfactual denoising UNet, whose encodings are then transferred into high-quality brain MRIs via our 3D diffusion decoder. Extensive experiments on multiple datasets demonstrate that PCGM generates structural brain MRIs of higher quality than several baseline approaches. Furthermore, we show for the first time that brain measurements extracted from counterfactuals (generated by PCGM) replicate the subtle effects of a disease on cortical brain regions previously reported in the neuroscience literature. This achievement is an important milestone in the use of synthetic MRIs in studies investigating subtle morphological differences.
Brain-Cognition Fingerprinting via Graph-GCCA with Contrastive Learning
Sep 20, 2024



Many longitudinal neuroimaging studies aim to improve the understanding of brain aging and diseases by studying the dynamic interactions between brain function and cognition. Doing so requires accurate encoding of their multidimensional relationship while accounting for individual variability over time. For this purpose, we propose an unsupervised learning model (called \underline{\textbf{Co}}ntrastive Learning-based \underline{\textbf{Gra}}ph Generalized \underline{\textbf{Ca}}nonical Correlation Analysis (CoGraCa)) that encodes their relationship via Graph Attention Networks and generalized Canonical Correlational Analysis. To create brain-cognition fingerprints reflecting unique neural and cognitive phenotype of each person, the model also relies on individualized and multimodal contrastive learning. We apply CoGraCa to longitudinal dataset of healthy individuals consisting of resting-state functional MRI and cognitive measures acquired at multiple visits for each participant. The generated fingerprints effectively capture significant individual differences and outperform current single-modal and CCA-based multimodal models in identifying sex and age. More importantly, our encoding provides interpretable interactions between those two modalities.
Evaluating the Quality of Brain MRI Generators
Sep 13, 2024Deep learning models generating structural brain MRIs have the potential to significantly accelerate discovery of neuroscience studies. However, their use has been limited in part by the way their quality is evaluated. Most evaluations of generative models focus on metrics originally designed for natural images (such as structural similarity index and Frechet inception distance). As we show in a comparison of 6 state-of-the-art generative models trained and tested on over 3000 MRIs, these metrics are sensitive to the experimental setup and inadequately assess how well brain MRIs capture macrostructural properties of brain regions (i.e., anatomical plausibility). This shortcoming of the metrics results in inconclusive findings even when qualitative differences between the outputs of models are evident. We therefore propose a framework for evaluating models generating brain MRIs, which requires uniform processing of the real MRIs, standardizing the implementation of the models, and automatically segmenting the MRIs generated by the models. The segmentations are used for quantifying the plausibility of anatomy displayed in the MRIs. To ensure meaningful quantification, it is crucial that the segmentations are highly reliable. Our framework rigorously checks this reliability, a step often overlooked by prior work. Only 3 of the 6 generative models produced MRIs, of which at least 95% had highly reliable segmentations. More importantly, the assessment of each model by our framework is in line with qualitative assessments, reinforcing the validity of our approach.
Latent 3D Brain MRI Counterfactual
Sep 09, 2024



The number of samples in structural brain MRI studies is often too small to properly train deep learning models. Generative models show promise in addressing this issue by effectively learning the data distribution and generating high-fidelity MRI. However, they struggle to produce diverse, high-quality data outside the distribution defined by the training data. One way to address the issue is using causal models developed for 3D volume counterfactuals. However, accurately modeling causality in high-dimensional spaces is a challenge so that these models generally generate 3D brain MRIS of lower quality. To address these challenges, we propose a two-stage method that constructs a Structural Causal Model (SCM) within the latent space. In the first stage, we employ a VQ-VAE to learn a compact embedding of the MRI volume. Subsequently, we integrate our causal model into this latent space and execute a three-step counterfactual procedure using a closed-form Generalized Linear Model (GLM). Our experiments conducted on real-world high-resolution MRI data (1mm) demonstrate that our method can generate high-quality 3D MRI counterfactuals.
Few Shot Part Segmentation Reveals Compositional Logic for Industrial Anomaly Detection
Dec 21, 2023Logical anomalies (LA) refer to data violating underlying logical constraints e.g., the quantity, arrangement, or composition of components within an image. Detecting accurately such anomalies requires models to reason about various component types through segmentation. However, curation of pixel-level annotations for semantic segmentation is both time-consuming and expensive. Although there are some prior few-shot or unsupervised co-part segmentation algorithms, they often fail on images with industrial object. These images have components with similar textures and shapes, and a precise differentiation proves challenging. In this study, we introduce a novel component segmentation model for LA detection that leverages a few labeled samples and unlabeled images sharing logical constraints. To ensure consistent segmentation across unlabeled images, we employ a histogram matching loss in conjunction with an entropy loss. As segmentation predictions play a crucial role, we propose to enhance both local and global sample validity detection by capturing key aspects from visual semantics via three memory banks: class histograms, component composition embeddings and patch-level representations. For effective LA detection, we propose an adaptive scaling strategy to standardize anomaly scores from different memory banks in inference. Extensive experiments on the public benchmark MVTec LOCO AD reveal our method achieves 98.1% AUROC in LA detection vs. 89.6% from competing methods.
Metadata-Conditioned Generative Models to Synthesize Anatomically-Plausible 3D Brain MRIs
Oct 07, 2023



Generative AI models hold great potential in creating synthetic brain MRIs that advance neuroimaging studies by, for example, enriching data diversity. However, the mainstay of AI research only focuses on optimizing the visual quality (such as signal-to-noise ratio) of the synthetic MRIs while lacking insights into their relevance to neuroscience. To gain these insights with respect to T1-weighted MRIs, we first propose a new generative model, BrainSynth, to synthesize metadata-conditioned (e.g., age- and sex-specific) MRIs that achieve state-of-the-art visual quality. We then extend our evaluation with a novel procedure to quantify anatomical plausibility, i.e., how well the synthetic MRIs capture macrostructural properties of brain regions, and how accurately they encode the effects of age and sex. Results indicate that more than half of the brain regions in our synthetic MRIs are anatomically accurate, i.e., with a small effect size between real and synthetic MRIs. Moreover, the anatomical plausibility varies across cortical regions according to their geometric complexity. As is, our synthetic MRIs can significantly improve the training of a Convolutional Neural Network to identify accelerated aging effects in an independent study. These results highlight the opportunities of using generative AI to aid neuroimaging research and point to areas for further improvement.
LSOR: Longitudinally-Consistent Self-Organized Representation Learning
Sep 30, 2023Interpretability is a key issue when applying deep learning models to longitudinal brain MRIs. One way to address this issue is by visualizing the high-dimensional latent spaces generated by deep learning via self-organizing maps (SOM). SOM separates the latent space into clusters and then maps the cluster centers to a discrete (typically 2D) grid preserving the high-dimensional relationship between clusters. However, learning SOM in a high-dimensional latent space tends to be unstable, especially in a self-supervision setting. Furthermore, the learned SOM grid does not necessarily capture clinically interesting information, such as brain age. To resolve these issues, we propose the first self-supervised SOM approach that derives a high-dimensional, interpretable representation stratified by brain age solely based on longitudinal brain MRIs (i.e., without demographic or cognitive information). Called Longitudinally-consistent Self-Organized Representation learning (LSOR), the method is stable during training as it relies on soft clustering (vs. the hard cluster assignments used by existing SOM). Furthermore, our approach generates a latent space stratified according to brain age by aligning trajectories inferred from longitudinal MRIs to the reference vector associated with the corresponding SOM cluster. When applied to longitudinal MRIs of the Alzheimer's Disease Neuroimaging Initiative (ADNI, N=632), LSOR generates an interpretable latent space and achieves comparable or higher accuracy than the state-of-the-art representations with respect to the downstream tasks of classification (static vs. progressive mild cognitive impairment) and regression (determining ADAS-Cog score of all subjects). The code is available at https://github.com/ouyangjiahong/longitudinal-som-single-modality.
Imputing Brain Measurements Across Data Sets via Graph Neural Networks
Aug 19, 2023



Publicly available data sets of structural MRIs might not contain specific measurements of brain Regions of Interests (ROIs) that are important for training machine learning models. For example, the curvature scores computed by Freesurfer are not released by the Adolescent Brain Cognitive Development (ABCD) Study. One can address this issue by simply reapplying Freesurfer to the data set. However, this approach is generally computationally and labor intensive (e.g., requiring quality control). An alternative is to impute the missing measurements via a deep learning approach. However, the state-of-the-art is designed to estimate randomly missing values rather than entire measurements. We therefore propose to re-frame the imputation problem as a prediction task on another (public) data set that contains the missing measurements and shares some ROI measurements with the data sets of interest. A deep learning model is then trained to predict the missing measurements from the shared ones and afterwards is applied to the other data sets. Our proposed algorithm models the dependencies between ROI measurements via a graph neural network (GNN) and accounts for demographic differences in brain measurements (e.g. sex) by feeding the graph encoding into a parallel architecture. The architecture simultaneously optimizes a graph decoder to impute values and a classifier in predicting demographic factors. We test the approach, called Demographic Aware Graph-based Imputation (DAGI), on imputing those missing Freesurfer measurements of ABCD (N=3760) by training the predictor on those publicly released by the National Consortium on Alcohol and Neurodevelopment in Adolescence (NCANDA, N=540)...
An Explainable Geometric-Weighted Graph Attention Network for Identifying Functional Networks Associated with Gait Impairment
Jul 24, 2023



One of the hallmark symptoms of Parkinson's Disease (PD) is the progressive loss of postural reflexes, which eventually leads to gait difficulties and balance problems. Identifying disruptions in brain function associated with gait impairment could be crucial in better understanding PD motor progression, thus advancing the development of more effective and personalized therapeutics. In this work, we present an explainable, geometric, weighted-graph attention neural network (xGW-GAT) to identify functional networks predictive of the progression of gait difficulties in individuals with PD. xGW-GAT predicts the multi-class gait impairment on the MDS Unified PD Rating Scale (MDS-UPDRS). Our computational- and data-efficient model represents functional connectomes as symmetric positive definite (SPD) matrices on a Riemannian manifold to explicitly encode pairwise interactions of entire connectomes, based on which we learn an attention mask yielding individual- and group-level explainability. Applied to our resting-state functional MRI (rs-fMRI) dataset of individuals with PD, xGW-GAT identifies functional connectivity patterns associated with gait impairment in PD and offers interpretable explanations of functional subnetworks associated with motor impairment. Our model successfully outperforms several existing methods while simultaneously revealing clinically-relevant connectivity patterns. The source code is available at https://github.com/favour-nerrise/xGW-GAT .
Generating Realistic 3D Brain MRIs Using a Conditional Diffusion Probabilistic Model
Dec 15, 2022Training deep learning models on brain MRI is often plagued by small sample size, which can lead to biased training or overfitting. One potential solution is to synthetically generate realistic MRIs via generative models such as Generative Adversarial Network (GAN). However, existing GANs for synthesizing realistic brain MRIs largely rely on image-to-image conditioned transformations requiring extensive, well-curated pairs of MRI samples for training. On the other hand, unconditioned GAN models (i.e., those generating MRI from random noise) are unstable during training and tend to produce blurred images during inference. Here, we propose an efficient strategy that generates high fidelity 3D brain MRI via Diffusion Probabilistic Model (DPM). To this end, we train a conditional DPM with attention to generate an MRI sub-volume (a set of slices at arbitrary locations) conditioned on another subset of slices from the same MRI. By computing attention weights from slice indices and using a mask to encode the target and conditional slices, the model is able to learn the long-range dependency across distant slices with limited computational resources. After training, the model can progressively synthesize a new 3D brain MRI by generating the first subset of slices from random noise and conditionally generating subsequent slices. Based on 1262 t1-weighted MRIs from three neuroimaging studies, our experiments demonstrate that the proposed method can generate high quality 3D MRIs that share the same distribution as real MRIs and are more realistic than the ones produced by GAN-based models.