 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Swapping as A Simple Arithmetic Operation
Nov 19, 2022



We propose a novel high-fidelity face swapping method called "Arithmetic Face Swapping" (AFS) that explicitly disentangles the intermediate latent space W+ of a pretrained StyleGAN into the "identity" and "style" subspaces so that a latent code in W+ is the sum of an "identity" code and a "style" code in the corresponding subspaces. Via our disentanglement, face swapping (FS) can be regarded as a simple arithmetic operation in W+, i.e., the summation of a source "identity" code and a target "style" code. This makes AFS more intuitive and elegant than other FS methods. In addition, our method can generalize over the standard face swapping to support other interesting operations, e.g., combining the identity of one source with styles of multiple targets and vice versa. We implement our identity-style disentanglement by learning a neural network that maps a latent code to a "style" code. We provide a condition for this network which theoretically guarantees identity preservation of the source face even after a sequence of face swapping operations. Extensive experiments demonstrate the advantage of our method over state-of-the-art FS methods in producing high-quality swapped faces.
From Implicit to Explicit feedback: A deep neural network for modeling sequential behaviours and long-short term preferences of online users
Jul 26, 2021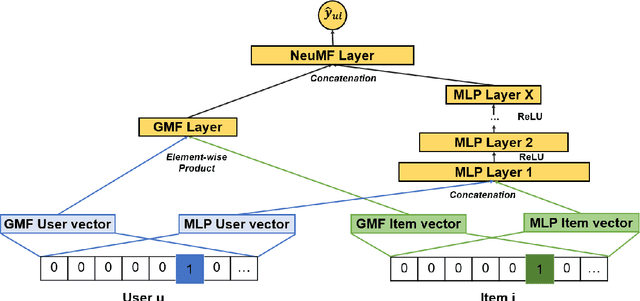
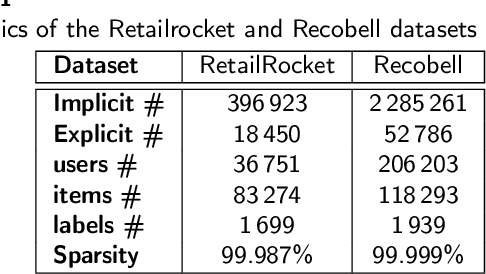
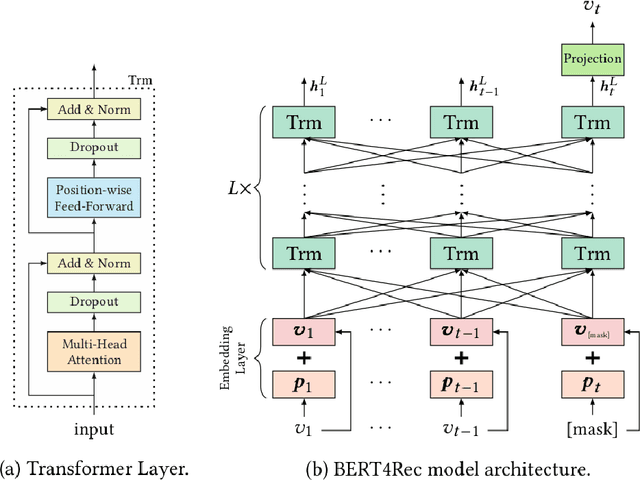
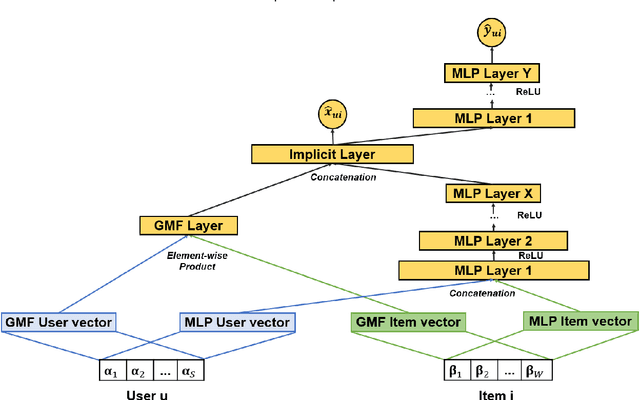
In this work, we examine the advantages of using multiple types of behaviour in recommendation systems. Intuitively, each user has to do some implicit actions (e.g., click) before making an explicit decision (e.g., purchase). Previous studies showed that implicit and explicit feedback have different roles for a useful recommendation. However, these studies either exploit implicit and explicit behaviour separately or ignore the semantic of sequential interactions between users and items. In addition, we go from the hypothesis that a user's preference at a time is a combination of long-term and short-term interests. In this paper, we propose some Deep Learning architectures. The first one is Implicit to Explicit (ITE), to exploit users' interests through the sequence of their actions. And two versions of ITE with Bidirectional Encoder Representations from Transformers based (BERT-based) architecture called BERT-ITE and BERT-ITE-Si, which combine users' long- and short-term preferences without and with side information to enhance user representation. The experimental results show that our models outperform previous state-of-the-art ones and also demonstrate our views on the effectiveness of exploiting the implicit to explicit order as well as combining long- and short-term preferences in two large-scale datasets.
Generalization of GANs under Lipschitz continuity and data augmentation
Apr 06, 2021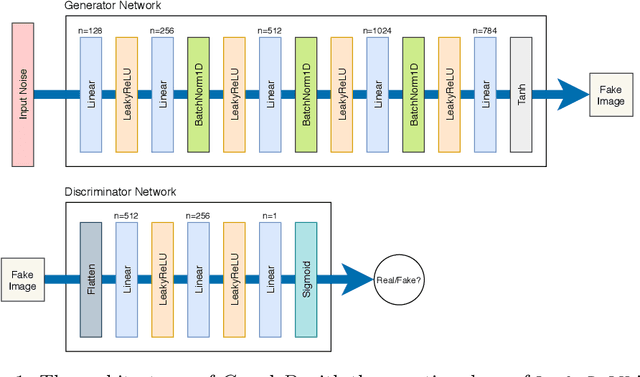
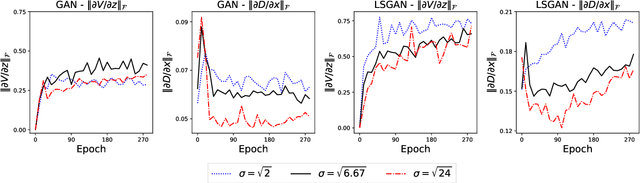
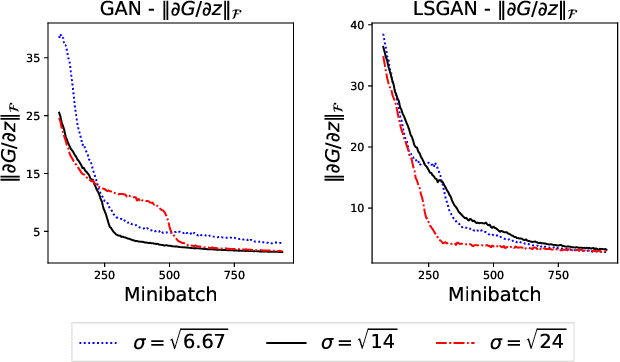
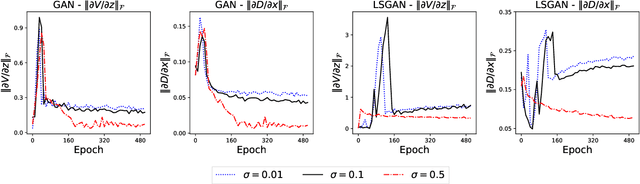
Generative adversarial networks (GANs) have been being widely used in various applications. Arguably, GANs are really complex, and little has been known about their generalization. In this paper, we make a comprehensive analysis about generalization of GANs. We decompose the generalization error into an explicit composition: generator error + discriminator error + optimization error. The first two errors show the capacity of the player's families, are irreducible and optimizer-independent. We then provide both uniform and non-uniform generalization bounds in different scenarios, thanks to our new bridge between Lipschitz continuity and generalization. Our bounds overcome some major limitations of existing ones. In particular, our bounds show that penalizing the zero- and first-order informations of the GAN loss will improve generalization, answering the long mystery of why imposing a Lipschitz constraint can help GANs perform better in practice. Finally, we show why data augmentation penalizes the zero- and first-order informations of the loss, helping the players generalize better, and hence explaining the highly successful use of data augmentation for GANs.
Improving Bayesian Inference in Deep Neural Networks with Variational Structured Dropout
Feb 16, 2021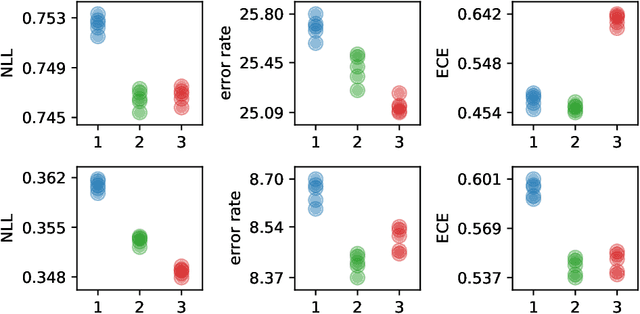
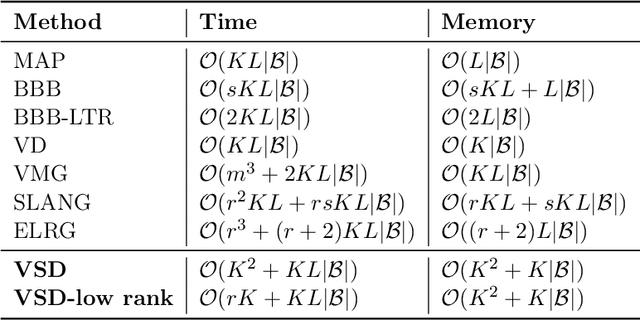
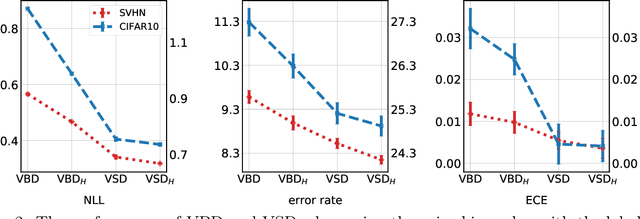
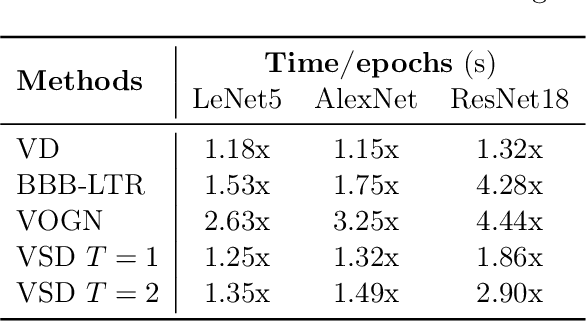
Approximate inference in deep Bayesian networks exhibits a dilemma of how to yield high fidelity posterior approximations while maintaining computational efficiency and scalability. We tackle this challenge by introducing a new variational structured approximation inspired by the interpretation of Dropout training as approximate inference in Bayesian probabilistic models. Concretely, we focus on restrictions of the factorized structure of Dropout posterior which is inflexible to capture rich correlations among weight parameters of the true posterior, and we then propose a novel method called Variational Structured Dropout (VSD) to overcome this limitation. VSD employs an orthogonal transformation to learn a structured representation on the variational Dropout noise and consequently induces statistical dependencies in the approximate posterior. We further gain expressive Bayesian modeling for VSD via proposing a hierarchical Dropout procedure that corresponds to the joint inference in a Bayesian network. Moreover, we can scale up VSD to modern deep convolutional networks in a direct way with a low computational cost. Finally, we conduct extensive experiments on standard benchmarks to demonstrate the effectiveness of VSD over state-of-the-art methods on both predictive accuracy and uncertainty estimation.
Bag of biterms modeling for short texts
Mar 26, 2020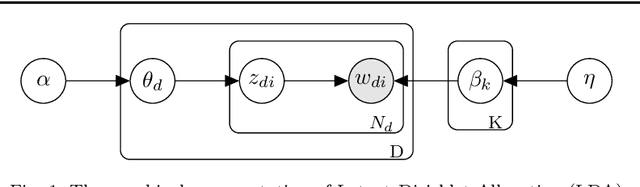


Analyzing texts from social media encounters many challenges due to their unique characteristics of shortness, massiveness, and dynamic. Short texts do not provide enough context information, causing the failure of the traditional statistical models. Furthermore, many applications often face with massive and dynamic short texts, causing various computational challenges to the current batch learning algorithms. This paper presents a novel framework, namely Bag of Biterms Modeling (BBM), for modeling massive, dynamic, and short text collections. BBM comprises of two main ingredients: (1) the concept of Bag of Biterms (BoB) for representing documents, and (2) a simple way to help statistical models to include BoB. Our framework can be easily deployed for a large class of probabilistic models, and we demonstrate its usefulness with two well-known models: Latent Dirichlet Allocation (LDA) and Hierarchical Dirichlet Process (HDP). By exploiting both terms (words) and biterms (pairs of words), the major advantages of BBM are: (1) it enhances the length of the documents and makes the context more coherent by emphasizing the word connotation and co-occurrence via Bag of Biterms, (2) it inherits inference and learning algorithms from the primitive to make it straightforward to design online and streaming algorithms for short texts. Extensive experiments suggest that BBM outperforms several state-of-the-art models. We also point out that the BoB representation performs better than the traditional representations (e.g, Bag of Words, tf-idf) even for normal texts.
Graph Convolutional Topic Model for Data Streams
Mar 17, 2020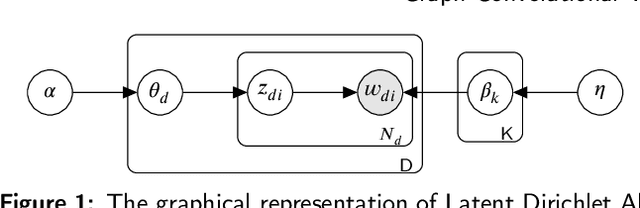
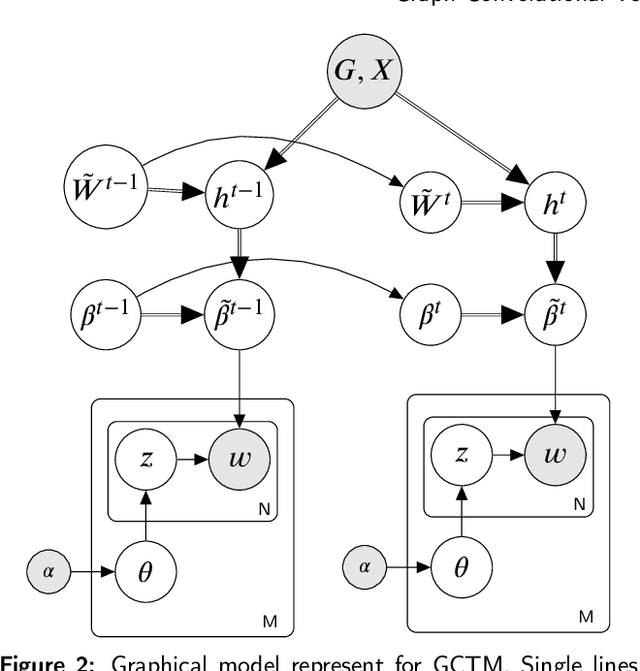
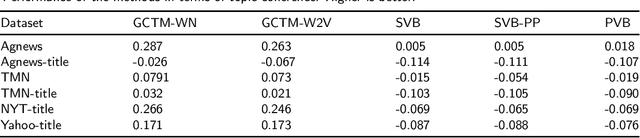
Learning hidden topics in data streams has been paid a great deal of attention by researchers with a lot of proposed methods, but exploiting prior knowledge in general and a knowledge graph in particular has not been taken into adequate consideration in these methods. Prior knowledge that is derived from human knowledge (e.g. Wordnet) or a pre-trained model (e.g.Word2vec) is very valuable and useful to help topic models work better, especially on short texts. However, previous work often ignores this resource, or it can only utilize prior knowledge of a vector form in a simple way. In this paper, we propose a novel graph convolutional topic model (GCTM) which integrates graph convolutional networks (GCN) into a topic model and a learning method which learns the networks and the topic model simultaneously for data streams. In each minibatch, our method not only can exploit an external knowledge graph but also can balance between the external and old knowledge to perform well on new data. We conduct extensive experiments to evaluate our method with both human graph knowledge(Wordnet) and a graph built from pre-trained word embeddings (Word2vec). The experimental results show that our method achieves significantly better performances than the state-of-the-art baselines in terms of probabilistic predictive measure and topic coherence. In particular, our method can work well when dealing with short texts as well as concept drift. The implementation of GCTM is available at https://github.com/bachtranxuan/GCTM.git.
Dynamic transformation of prior knowledge into Bayesian models for data streams
Mar 17, 2020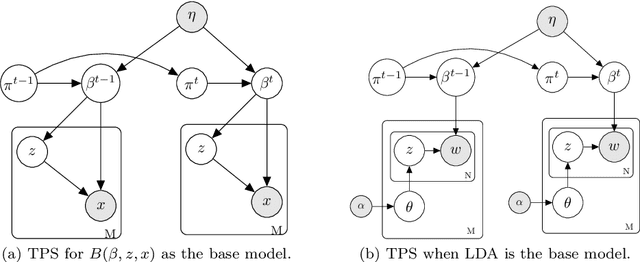
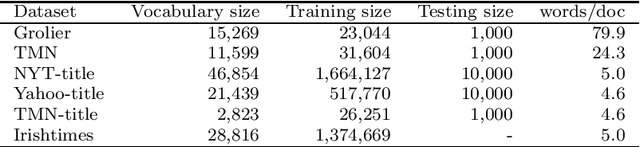
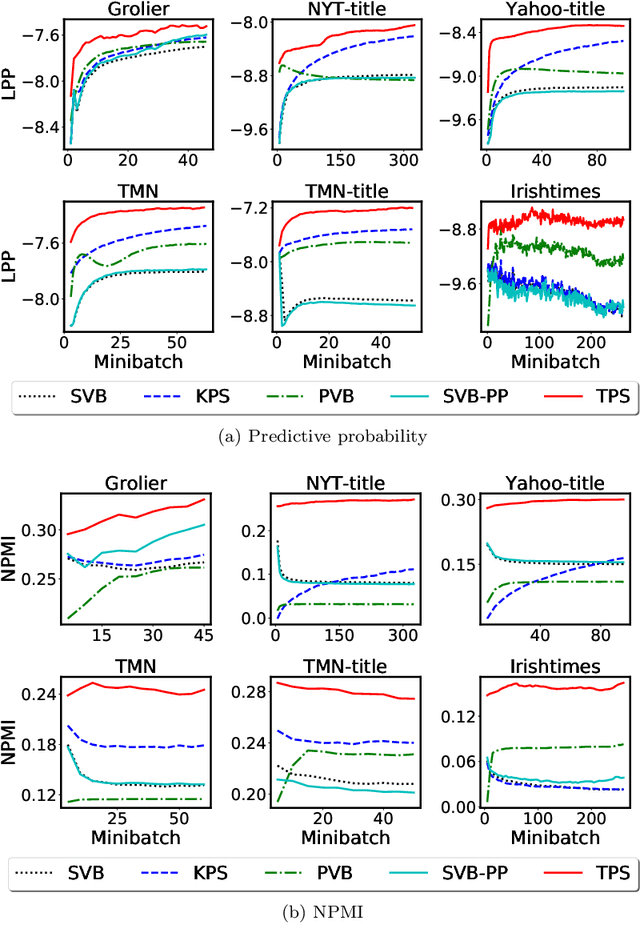

We consider how to effectively use prior knowledge when learning a Bayesian model from streaming environments where the data come infinitely and sequentially. This problem is highly important in the era of data explosion and rich sources of precious external knowledge such as pre-trained models, ontologies, Wikipedia, etc. We show that some existing approaches can forget any knowledge very fast. We then propose a novel framework that enables to incorporate the prior knowledge of different forms into a base Bayesian model for data streams. Our framework subsumes some existing popular models for time-series/dynamic data. Extensive experiments show that our framework outperforms existing methods with a large margin. In particular, our framework can help Bayesian models generalize well on extremely short text while other methods overfit. The implementation of our framework is available at https://github.com/bachtranxuan/TPS.git.
Predictive Coding for Locally-Linear Control
Mar 02, 2020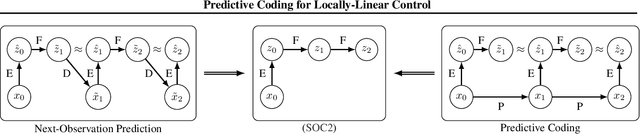
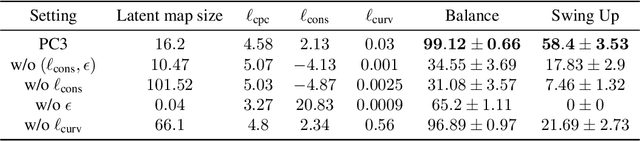


High-dimensional observations and unknown dynamics are major challenges when applying optimal control to many real-world decision making tasks. The Learning Controllable Embedding (LCE) framework addresses these challenges by embedding the observations into a lower dimensional latent space, estimating the latent dynamics, and then performing control directly in the latent space. To ensure the learned latent dynamics are predictive of next-observations, all existing LCE approaches decode back into the observation space and explicitly perform next-observation prediction---a challenging high-dimensional task that furthermore introduces a large number of nuisance parameters (i.e., the decoder) which are discarded during control. In this paper, we propose a novel information-theoretic LCE approach and show theoretically that explicit next-observation prediction can be replaced with predictive coding. We then use predictive coding to develop a decoder-free LCE model whose latent dynamics are amenable to locally-linear control. Extensive experiments on benchmark tasks show that our model reliably learns a controllable latent space that leads to superior performance when compared with state-of-the-art LCE baselines.
Guaranteed inference in topic models
Aug 17, 2016
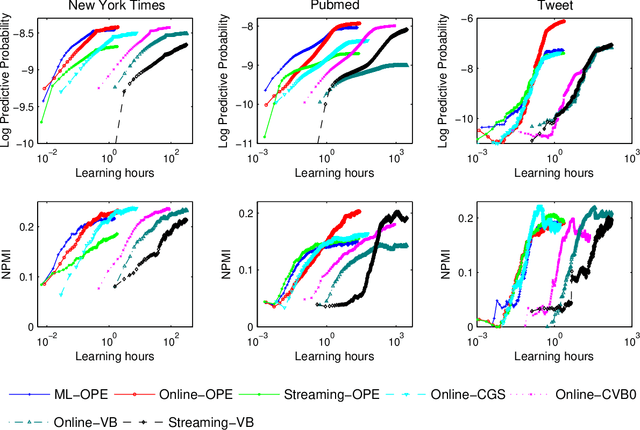
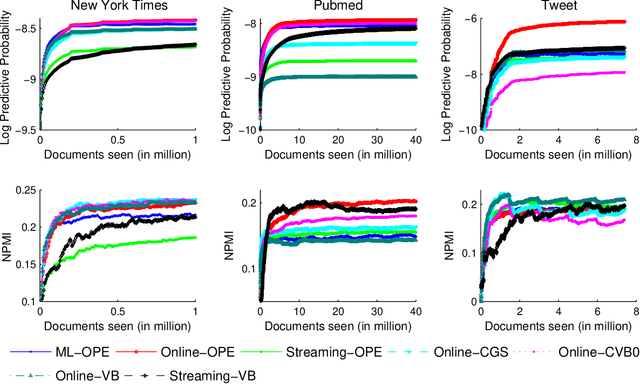
One of the core problems in statistical models is the estimation of a posterior distribution. For topic models, the problem of posterior inference for individual texts is particularly important, especially when dealing with data streams, but is often intractable in the worst case. As a consequence, existing methods for posterior inference are approximate and do not have any guarantee on neither quality nor convergence rate. In this paper, we introduce a provably fast algorithm, namely Online Maximum a Posteriori Estimation (OPE), for posterior inference in topic models. OPE has more attractive properties than existing inference approaches, including theoretical guarantees on quality and fast rate of convergence to a local maximal/stationary point of the inference problem. The discussions about OPE are very general and hence can be easily employed in a wide range of contexts. Finally, we employ OPE to design three methods for learning Latent Dirichlet Allocation from text streams or large corpora. Extensive experiments demonstrate some superior behaviors of OPE and of our new learning methods.
Inference in topic models: sparsity and trade-off
Dec 10, 2015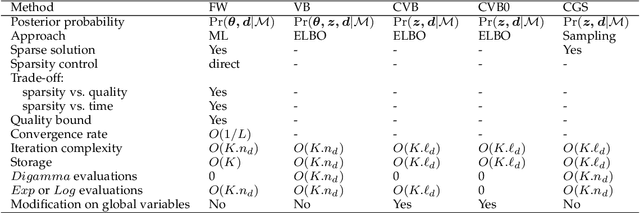
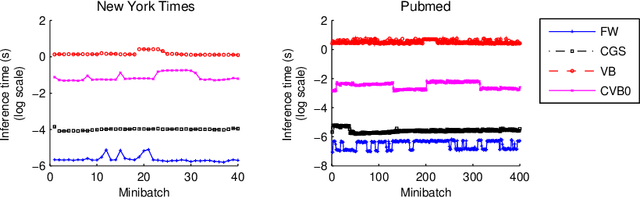
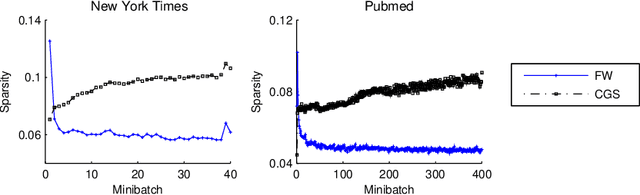
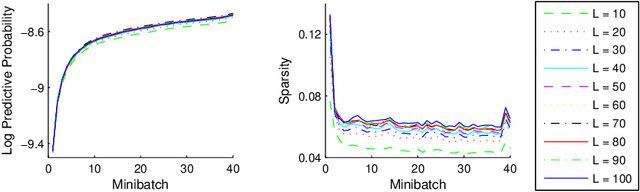
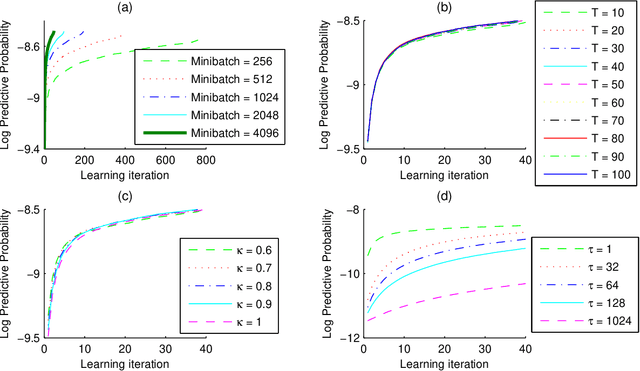
Topic models are popular for modeling discrete data (e.g., texts, images, videos, links), and provide an efficient way to discover hidden structures/semantics in massive data. One of the core problems in this field is the posterior inference for individual data instances. This problem is particularly important in streaming environments, but is often intractable. In this paper, we investigate the use of the Frank-Wolfe algorithm (FW) for recovering sparse solutions to posterior inference. From detailed elucidation of both theoretical and practical aspects, FW exhibits many interesting properties which are beneficial to topic modeling. We then employ FW to design fast methods, including ML-FW, for learning latent Dirichlet allocation (LDA) at large scales. Extensive experiments show that to reach the same predictiveness level, ML-FW can perform tens to thousand times faster than existing state-of-the-art methods for learning LDA from massive/streaming data.