 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of Soft and Hard Target RNN-T Distillation for Large-scale ASR
Oct 11, 2022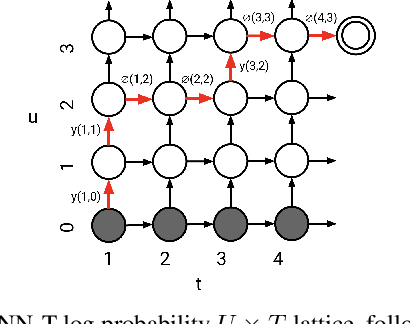
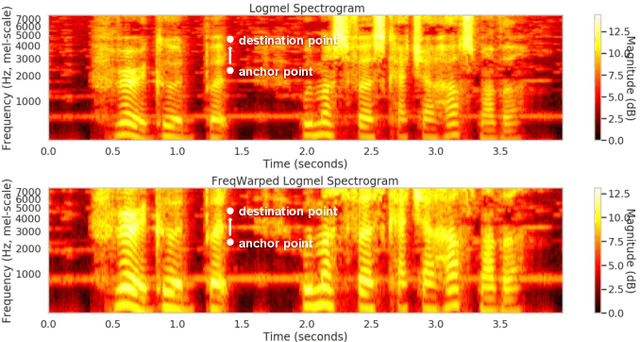

Knowledge distillation is an effective machine learning technique to transfer knowledge from a teacher model to a smaller student model, especially with unlabeled data. In this paper, we focus on knowledge distillation for the RNN-T model, which is widely used in state-of-the-art (SoTA) automatic speech recognition (ASR). Specifically, we compared using soft and hard target distillation to train large-scaleRNN-T models on the LibriSpeech/LibriLight public dataset (60k hours) and our in-house data (600k hours). We found that hard tar-gets are more effective when the teacher and student have different architecture, such as large teacher and small streaming student. On the other hand, soft target distillation works better in self-training scenario like iterative large teacher training. For a large model with0.6B weights, we achieve a new SoTA word error rate (WER) on LibriSpeech (8% relative improvement on dev-other) using Noisy Student Training with soft target distillation. It also allows our production teacher to adapt new data domain continuously.
Large vocabulary speech recognition for languages of Africa: multilingual modeling and self-supervised learning
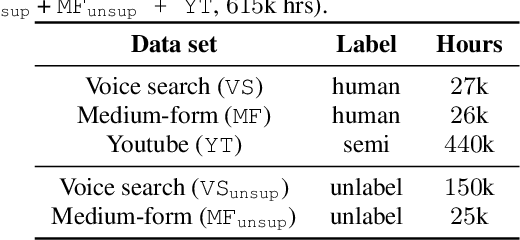
Aug 05, 2022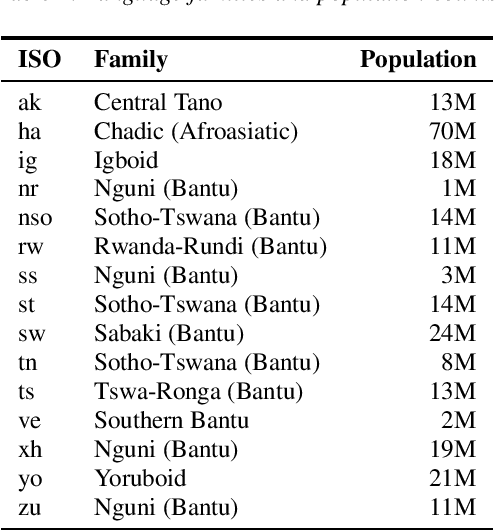
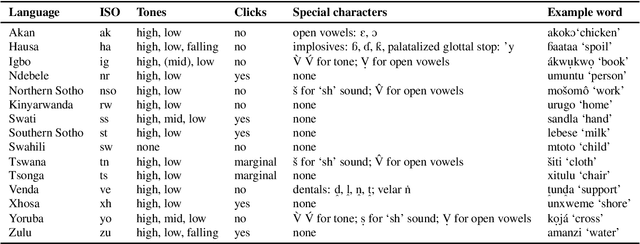
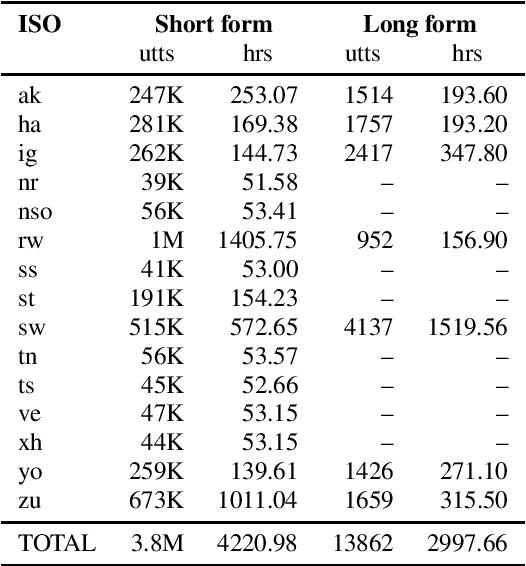
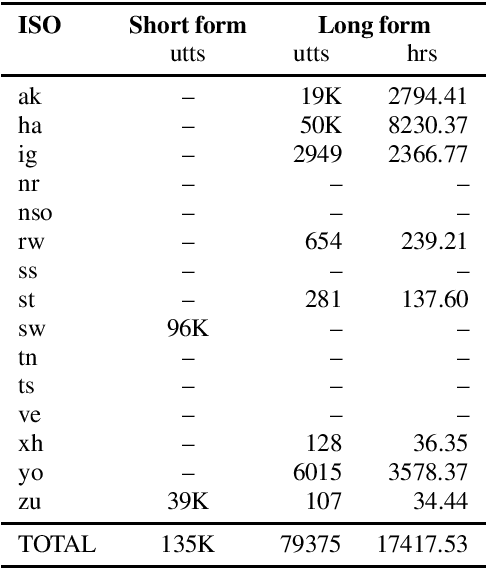
Almost none of the 2,000+ languages spoken in Africa have widely available automatic speech recognition systems, and the required data is also only available for a few languages. We have experimented with two techniques which may provide pathways to large vocabulary speech recognition for African languages: multilingual modeling and self-supervised learning. We gathered available open source data and collected data for 15 languages, and trained experimental models using these techniques. Our results show that pooling the small amounts of data available in multilingual end-to-end models, and pre-training on unsupervised data can help improve speech recognition quality for many African languages.
UserLibri: A Dataset for ASR Personalization Using Only Text
Jul 02, 2022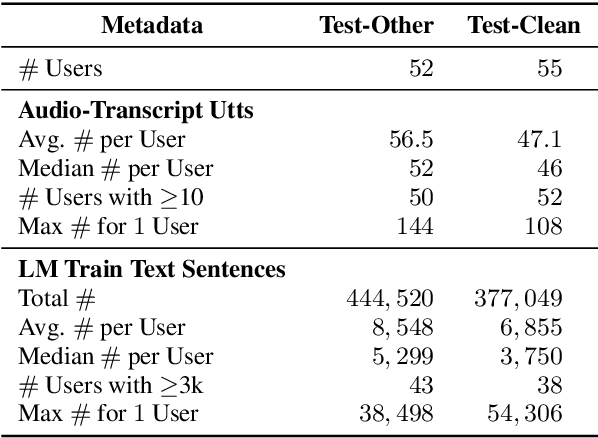
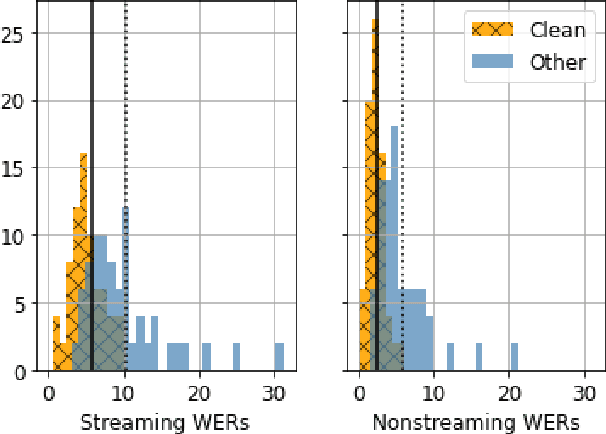
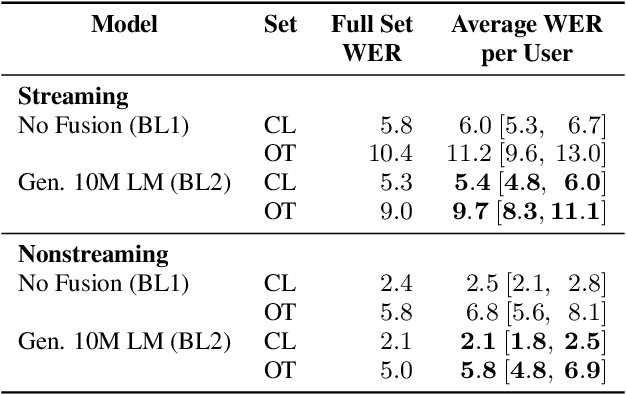
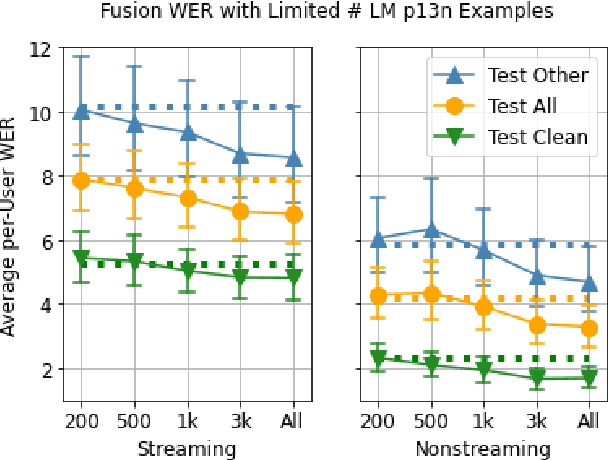
Personalization of speech models on mobile devices (on-device personalization) is an active area of research, but more often than not, mobile devices have more text-only data than paired audio-text data. We explore training a personalized language model on text-only data, used during inference to improve speech recognition performance for that user. We experiment on a user-clustered LibriSpeech corpus, supplemented with personalized text-only data for each user from Project Gutenberg. We release this User-Specific LibriSpeech (UserLibri) dataset to aid future personalization research. LibriSpeech audio-transcript pairs are grouped into 55 users from the test-clean dataset and 52 users from test-other. We are able to lower the average word error rate per user across both sets in streaming and nonstreaming models, including an improvement of 2.5 for the harder set of test-other users when streaming.
Pseudo Label Is Better Than Human Label
Mar 28, 2022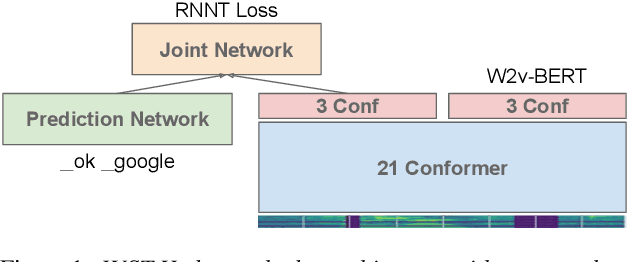

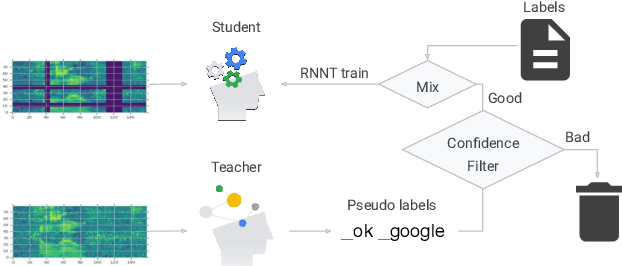
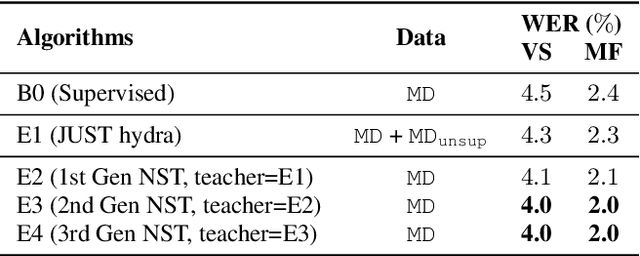
State-of-the-art automatic speech recognition (ASR) systems are trained with tens of thousands of hours of labeled speech data. Human transcription is expensive and time consuming. Factors such as the quality and consistency of the transcription can greatly affect the performance of the ASR models trained with these data. In this paper, we show that we can train a strong teacher model to produce high quality pseudo labels by utilizing recent self-supervised and semi-supervised learning techniques. Specifically, we use JUST (Joint Unsupervised/Supervised Training) and iterative noisy student teacher training to train a 600 million parameter bi-directional teacher model. This model achieved 4.0% word error rate (WER) on a voice search task, 11.1% relatively better than a baseline. We further show that by using this strong teacher model to generate high-quality pseudo labels for training, we can achieve 13.6% relative WER reduction (5.9% to 5.1%) for a streaming model compared to using human labels.
Joint Unsupervised and Supervised Training for Multilingual ASR
Nov 15, 2021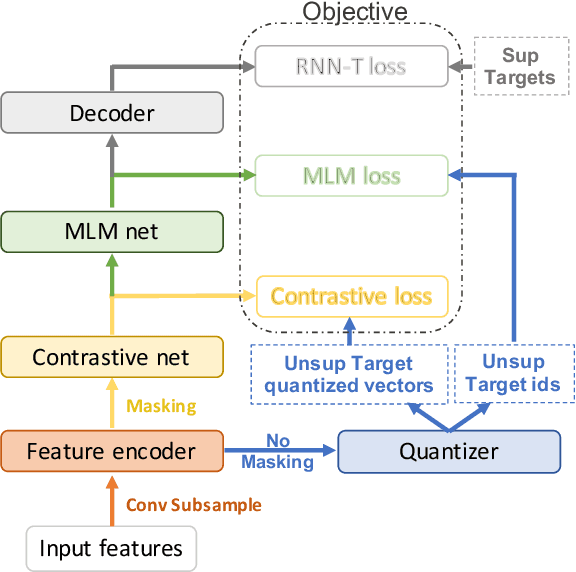
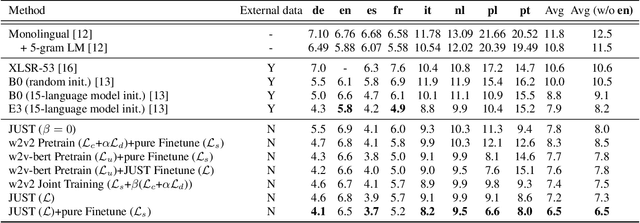
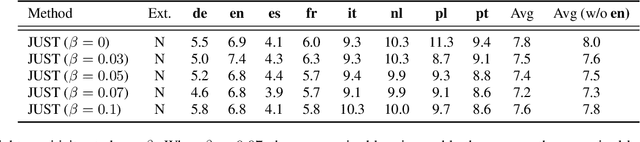
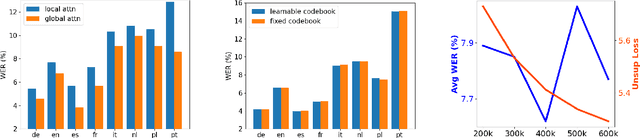
Self-supervised training has shown promising gains in pretraining models and facilitating the downstream finetuning for speech recognition, like multilingual ASR. Most existing methods adopt a 2-stage scheme where the self-supervised loss is optimized in the first pretraining stage, and the standard supervised finetuning resumes in the second stage. In this paper, we propose an end-to-end (E2E) Joint Unsupervised and Supervised Training (JUST) method to combine the supervised RNN-T loss and the self-supervised contrastive and masked language modeling (MLM) losses. We validate its performance on the public dataset Multilingual LibriSpeech (MLS), which includes 8 languages and is extremely imbalanced. On MLS, we explore (1) JUST trained from scratch, and (2) JUST finetuned from a pretrained checkpoint. Experiments show that JUST can consistently outperform other existing state-of-the-art methods, and beat the monolingual baseline by a significant margin, demonstrating JUST's capability of handling low-resource languages in multilingual ASR. Our average WER of all languages outperforms average monolingual baseline by 33.3%, and the state-of-the-art 2-stage XLSR by 32%. On low-resource languages like Polish, our WER is less than half of the monolingual baseline and even beats the supervised transfer learning method which uses external supervision.
Large-scale ASR Domain Adaptation using Self- and Semi-supervised Learning
Oct 13, 2021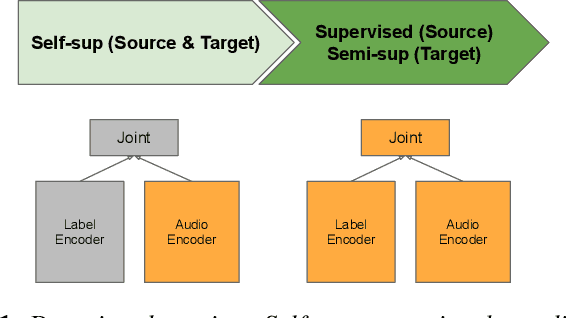

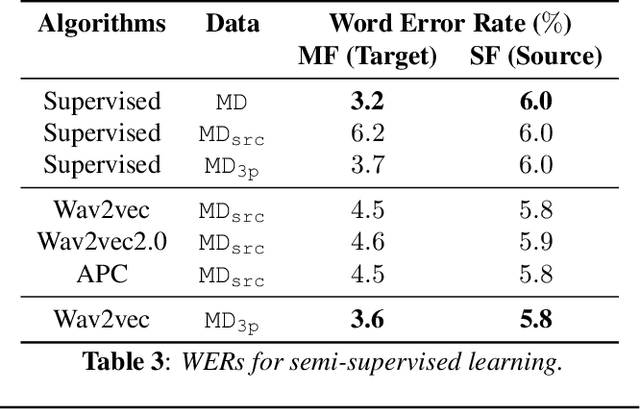
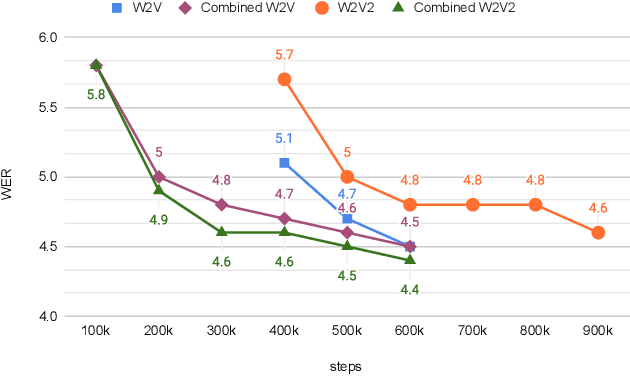
Self- and semi-supervised learning methods have been actively investigated to reduce labeled training data or enhance the model performance. However, the approach mostly focus on in-domain performance for public datasets. In this study, we utilize the combination of self- and semi-supervised learning methods to solve unseen domain adaptation problem in a large-scale production setting for online ASR model. This approach demonstrates that using the source domain data with a small fraction of the target domain data (3%) can recover the performance gap compared to a full data baseline: relative 13.5% WER improvement for target domain data.
Fast Contextual Adaptation with Neural Associative Memory for On-Device Personalized Speech Recognition
Oct 07, 2021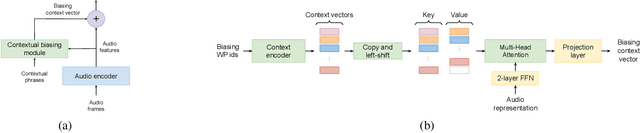
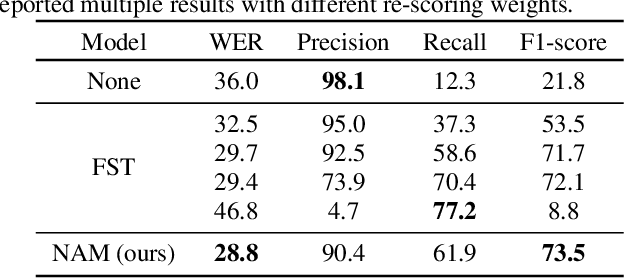
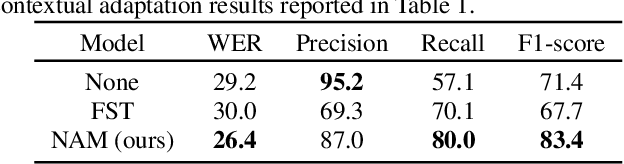

Fast contextual adaptation has shown to be effective in improving Automatic Speech Recognition (ASR) of rare words and when combined with an on-device personalized training, it can yield an even better recognition result. However, the traditional re-scoring approaches based on an external language model is prone to diverge during the personalized training. In this work, we introduce a model-based end-to-end contextual adaptation approach that is decoder-agnostic and amenable to on-device personalization. Our on-device simulation experiments demonstrate that the proposed approach outperforms the traditional re-scoring technique by 12% relative WER and 15.7% entity mention specific F1-score in a continues personalization scenario.
BigSSL: Exploring the Frontier of Large-Scale Semi-Supervised Learning for Automatic Speech Recognition
Oct 01, 2021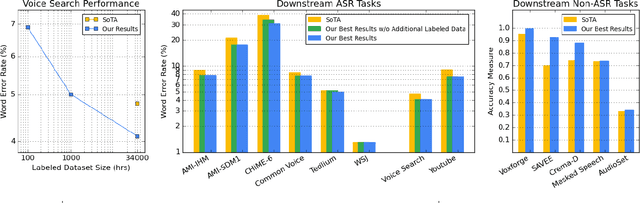
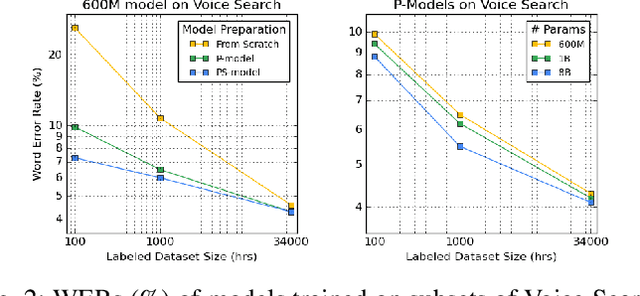
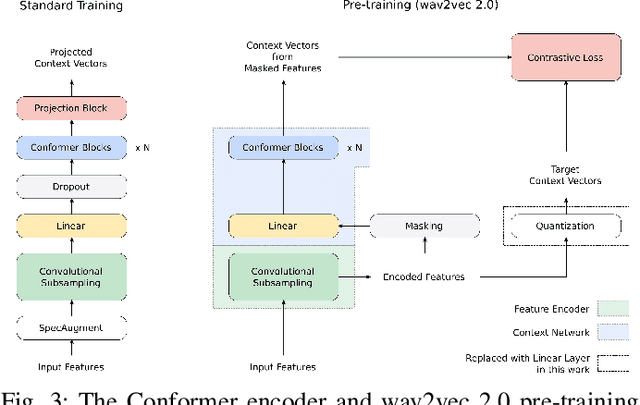
We summarize the results of a host of efforts using giant automatic speech recognition (ASR) models pre-trained using large, diverse unlabeled datasets containing approximately a million hours of audio. We find that the combination of pre-training, self-training and scaling up model size greatly increases data efficiency, even for extremely large tasks with tens of thousands of hours of labeled data. In particular, on an ASR task with 34k hours of labeled data, by fine-tuning an 8 billion parameter pre-trained Conformer model we can match state-of-the-art (SoTA) performance with only 3% of the training data and significantly improve SoTA with the full training set. We also report on the universal benefits gained from using big pre-trained and self-trained models for a large set of downstream tasks that cover a wide range of speech domains and span multiple orders of magnitudes of dataset sizes, including obtaining SoTA performance on many public benchmarks. In addition, we utilize the learned representation of pre-trained networks to achieve SoTA results on non-ASR tasks.
Incremental Layer-wise Self-Supervised Learning for Efficient Speech Domain Adaptation On Device
Oct 01, 2021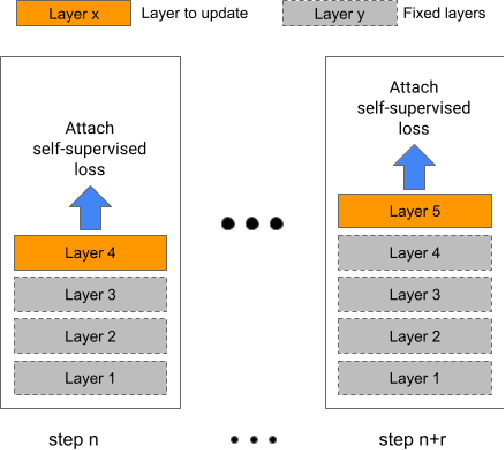
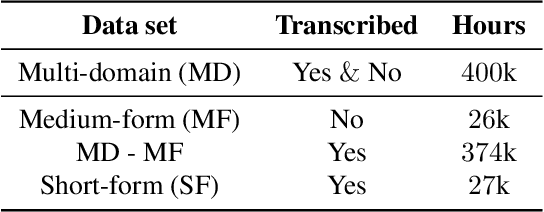
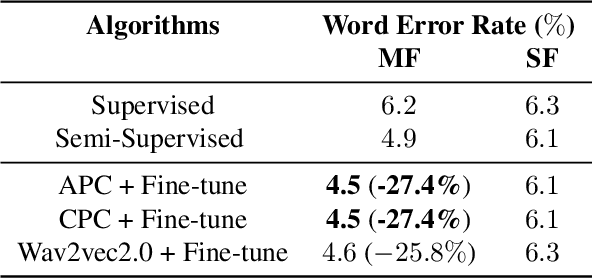
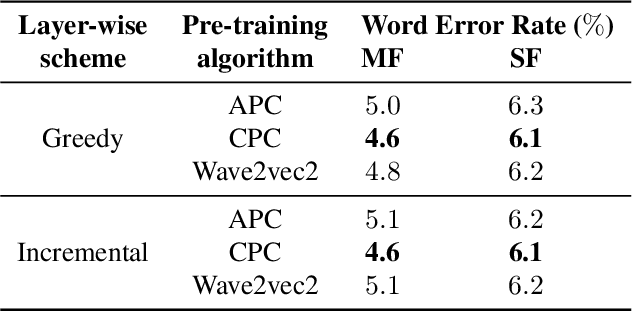
Streaming end-to-end speech recognition models have been widely applied to mobile devices and show significant improvement in efficiency. These models are typically trained on the server using transcribed speech data. However, the server data distribution can be very different from the data distribution on user devices, which could affect the model performance. There are two main challenges for on device training, limited reliable labels and limited training memory. While self-supervised learning algorithms can mitigate the mismatch between domains using unlabeled data, they are not applicable on mobile devices directly because of the memory constraint. In this paper, we propose an incremental layer-wise self-supervised learning algorithm for efficient speech domain adaptation on mobile devices, in which only one layer is updated at a time. Extensive experimental results demonstrate that the proposed algorithm obtains a Word Error Rate (WER) on the target domain $24.2\%$ better than supervised baseline and costs $89.7\%$ less training memory than the end-to-end self-supervised learning algorithm.
On-Device Personalization of Automatic Speech Recognition Models for Disordered Speech
Jun 18, 2021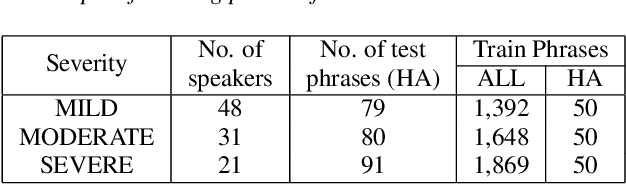
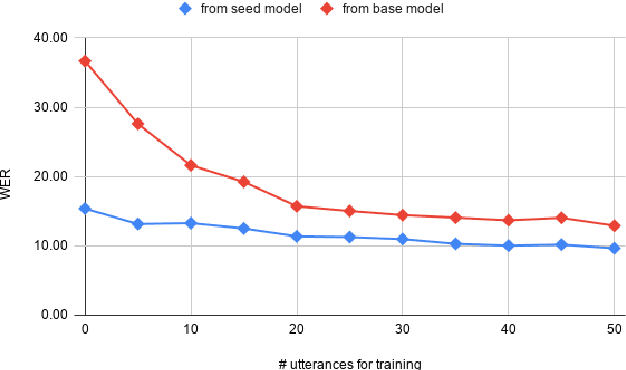
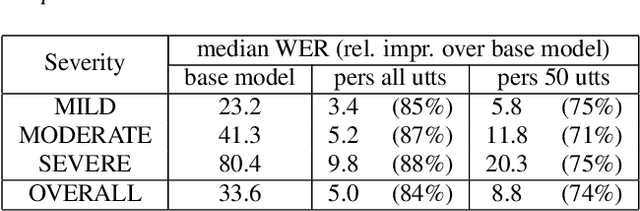
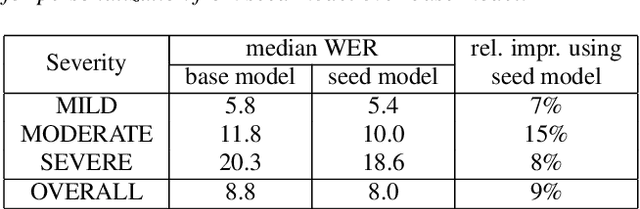
While current state-of-the-art Automatic Speech Recognition (ASR) systems achieve high accuracy on typical speech, they suffer from significant performance degradation on disordered speech and other atypical speech patterns. Personalization of ASR models, a commonly applied solution to this problem, is usually performed in a server-based training environment posing problems around data privacy, delayed model-update times, and communication cost for copying data and models between mobile device and server infrastructure. In this paper, we present an approach to on-device based ASR personalization with very small amounts of speaker-specific data. We test our approach on a diverse set of 100 speakers with disordered speech and find median relative word error rate improvement of 71% with only 50 short utterances required per speaker. When tested on a voice-controlled home automation platform, on-device personalized models show a median task success rate of 81%, compared to only 40% of the unadapted models.