 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision Transformer: Reinforcement Learning via Sequence Modeling
Jun 24, 2021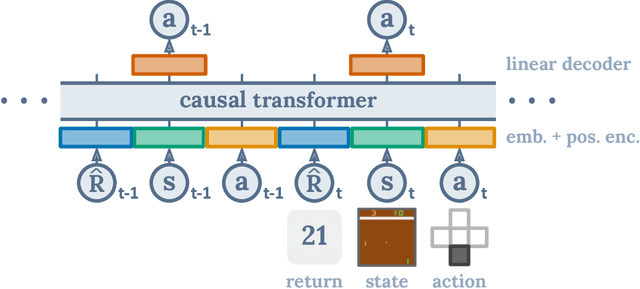
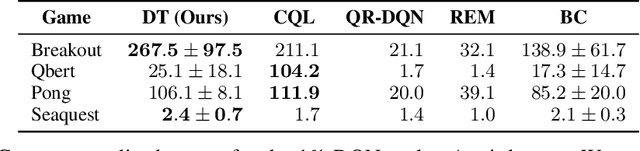

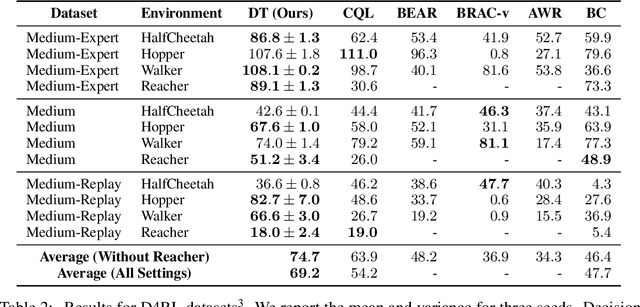
We introduce a framework that abstracts Reinforcement Learning (RL) as a sequence modeling problem. This allows us to draw upon the simplicity and scalability of the Transformer architecture, and associated advances in language modeling such as GPT-x and BERT. In particular, we present Decision Transformer, an architecture that casts the problem of RL as conditional sequence modeling. Unlike prior approaches to RL that fit value functions or compute policy gradients, Decision Transformer simply outputs the optimal actions by leveraging a causally masked Transformer. By conditioning an autoregressive model on the desired return (reward), past states, and actions, our Decision Transformer model can generate future actions that achieve the desired return. Despite its simplicity, Decision Transformer matches or exceeds the performance of state-of-the-art model-free offline RL baselines on Atari, OpenAI Gym, and Key-to-Door tasks.
Pretrained Transformers as Universal Computation Engines
Mar 09, 2021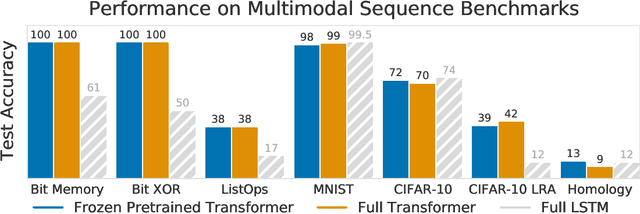


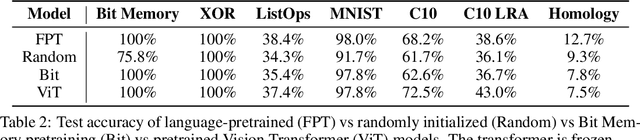
We investigate the capability of a transformer pretrained on natural language to generalize to other modalities with minimal finetuning -- in particular, without finetuning of the self-attention and feedforward layers of the residual blocks. We consider such a model, which we call a Frozen Pretrained Transformer (FPT), and study finetuning it on a variety of sequence classification tasks spanning numerical computation, vision, and protein fold prediction. In contrast to prior works which investigate finetuning on the same modality as the pretraining dataset, we show that pretraining on natural language improves performance and compute efficiency on non-language downstream tasks. In particular, we find that such pretraining enables FPT to generalize in zero-shot to these modalities, matching the performance of a transformer fully trained on these tasks.
Reset-Free Lifelong Learning with Skill-Space Planning
Jan 01, 2021

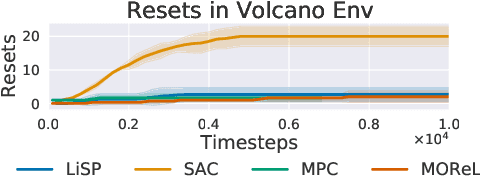

The objective of lifelong reinforcement learning (RL) is to optimize agents which can continuously adapt and interact in changing environments. However, current RL approaches fail drastically when environments are non-stationary and interactions are non-episodic. We propose Lifelong Skill Planning (LiSP), an algorithmic framework for non-episodic lifelong RL based on planning in an abstract space of higher-order skills. We learn the skills in an unsupervised manner using intrinsic rewards and plan over the learned skills using a learned dynamics model. Moreover, our framework permits skill discovery even from offline data, thereby reducing the need for excessive real-world interactions. We demonstrate empirically that LiSP successfully enables long-horizon planning and learns agents that can avoid catastrophic failures even in challenging non-stationary and non-episodic environments derived from gridworld and MuJoCo benchmarks.
Weakly supervised one-stage vision and language disease detection using large scale pneumonia and pneumothorax studies
Jul 31, 2020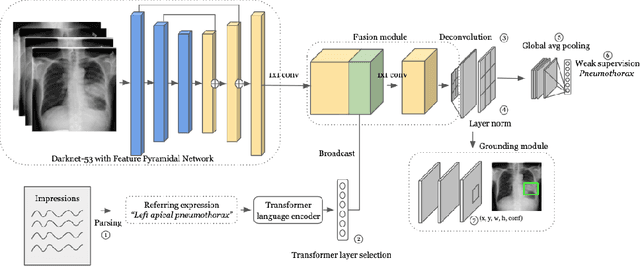
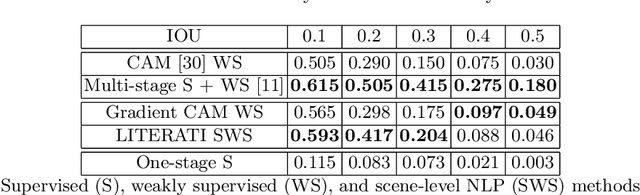
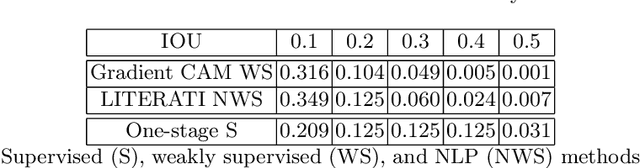
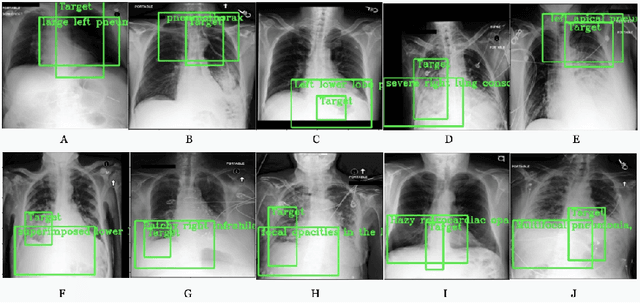
Detecting clinically relevant objects in medical images is a challenge despite large datasets due to the lack of detailed labels. To address the label issue, we utilize the scene-level labels with a detection architecture that incorporates natural language information. We present a challenging new set of radiologist paired bounding box and natural language annotations on the publicly available MIMIC-CXR dataset especially focussed on pneumonia and pneumothorax. Along with the dataset, we present a joint vision language weakly supervised transformer layer-selected one-stage dual head detection architecture (LITERATI) alongside strong baseline comparisons with class activation mapping (CAM), gradient CAM, and relevant implementations on the NIH ChestXray-14 and MIMIC-CXR dataset. Borrowing from advances in vision language architectures, the LITERATI method demonstrates joint image and referring expression (objects localized in the image using natural language) input for detection that scales in a purely weakly supervised fashion. The architectural modifications address three obstacles -- implementing a supervised vision and language detection method in a weakly supervised fashion, incorporating clinical referring expression natural language information, and generating high fidelity detections with map probabilities. Nevertheless, the challenging clinical nature of the radiologist annotations including subtle references, multi-instance specifications, and relatively verbose underlying medical reports, ensures the vision language detection task at scale remains stimulating for future investigation.
Adaptive Online Planning for Continual Lifelong Learning
Dec 03, 2019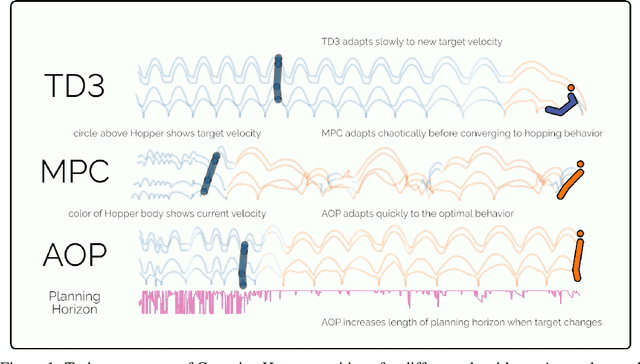
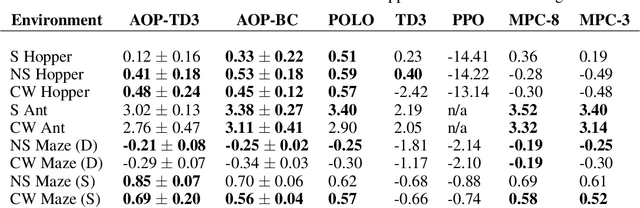
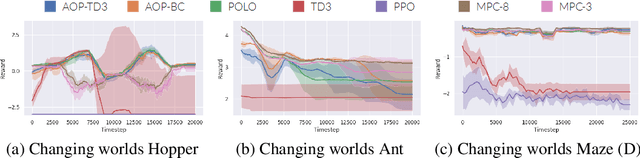

We study learning control in an online lifelong learning scenario, where mistakes can compound catastrophically into the future and the underlying dynamics of the environment may change. Traditional model-free policy learning methods have achieved successes in difficult tasks due to their broad flexibility, and capably condense broad experiences into compact networks, but struggle in this setting, as they can activate failure modes early in their lifetimes which are difficult to recover from and face performance degradation as dynamics change. On the other hand, model-based planning methods learn and adapt quickly, but require prohibitive levels of computational resources. Under constrained computation limits, the agent must allocate its resources wisely, which requires the agent to understand both its own performance and the current state of the environment: knowing that its mastery over control in the current dynamics is poor, the agent should dedicate more time to planning. We present a new algorithm, Adaptive Online Planning (AOP), that achieves strong performance in this setting by combining model-based planning with model-free learning. By measuring the performance of the planner and the uncertainty of the model-free components, AOP is able to call upon more extensive planning only when necessary, leading to reduced computation times. We show that AOP gracefully deals with novel situations, adapting behaviors and policies effectively in the face of unpredictable changes in the world -- challenges that a continual learning agent naturally faces over an extended lifetime -- even when traditional reinforcement learning methods fail.