 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Virtual Try-On with Synthetic Pairs and Error-Aware Noise Scheduling
Jan 08, 2025



Given an isolated garment image in a canonical product view and a separate image of a person, the virtual try-on task aims to generate a new image of the person wearing the target garment. Prior virtual try-on works face two major challenges in achieving this goal: a) the paired (human, garment) training data has limited availability; b) generating textures on the human that perfectly match that of the prompted garment is difficult, often resulting in distorted text and faded textures. Our work explores ways to tackle these issues through both synthetic data as well as model refinement. We introduce a garment extraction model that generates (human, synthetic garment) pairs from a single image of a clothed individual. The synthetic pairs can then be used to augment the training of virtual try-on. We also propose an Error-Aware Refinement-based Schr\"odinger Bridge (EARSB) that surgically targets localized generation errors for correcting the output of a base virtual try-on model. To identify likely errors, we propose a weakly-supervised error classifier that localizes regions for refinement, subsequently augmenting the Schr\"odinger Bridge's noise schedule with its confidence heatmap. Experiments on VITON-HD and DressCode-Upper demonstrate that our synthetic data augmentation enhances the performance of prior work, while EARSB improves the overall image quality. In user studies, our model is preferred by the users in an average of 59% of cases.
VANI: Very-lightweight Accent-controllable TTS for Native and Non-native speakers with Identity Preservation
Mar 14, 2023
We introduce VANI, a very lightweight multi-lingual accent controllable speech synthesis system. Our model builds upon disentanglement strategies proposed in RADMMM and supports explicit control of accent, language, speaker and fine-grained $F_0$ and energy features for speech synthesis. We utilize the Indic languages dataset, released for LIMMITS 2023 as part of ICASSP Signal Processing Grand Challenge, to synthesize speech in 3 different languages. Our model supports transferring the language of a speaker while retaining their voice and the native accent of the target language. We utilize the large-parameter RADMMM model for Track $1$ and lightweight VANI model for Track $2$ and $3$ of the competition.
Multilingual Multiaccented Multispeaker TTS with RADTTS
Jan 24, 2023



We work to create a multilingual speech synthesis system which can generate speech with the proper accent while retaining the characteristics of an individual voice. This is challenging to do because it is expensive to obtain bilingual training data in multiple languages, and the lack of such data results in strong correlations that entangle speaker, language, and accent, resulting in poor transfer capabilities. To overcome this, we present a multilingual, multiaccented, multispeaker speech synthesis model based on RADTTS with explicit control over accent, language, speaker and fine-grained $F_0$ and energy features. Our proposed model does not rely on bilingual training data. We demonstrate an ability to control synthesized accent for any speaker in an open-source dataset comprising of 7 accents. Human subjective evaluation demonstrates that our model can better retain a speaker's voice and accent quality than controlled baselines while synthesizing fluent speech in all target languages and accents in our dataset.
Collecting The Puzzle Pieces: Disentangled Self-Driven Human Pose Transfer by Permuting Textures
Oct 06, 2022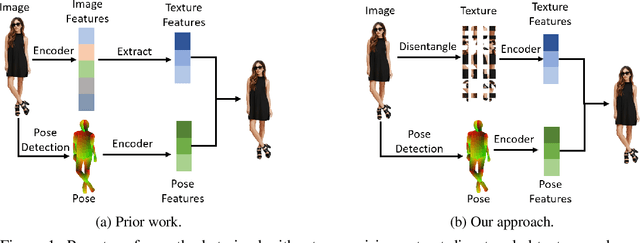
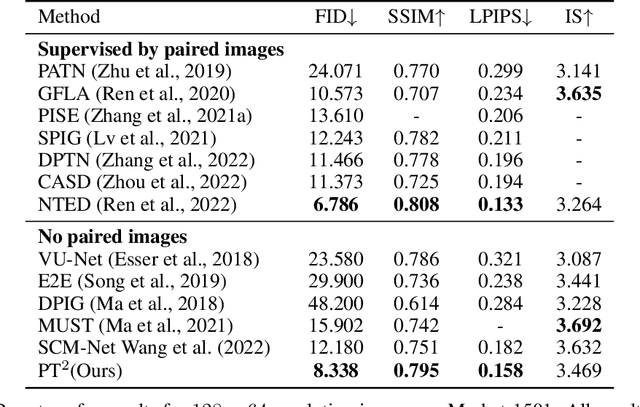
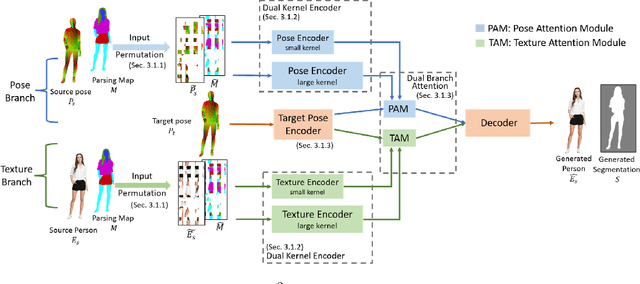
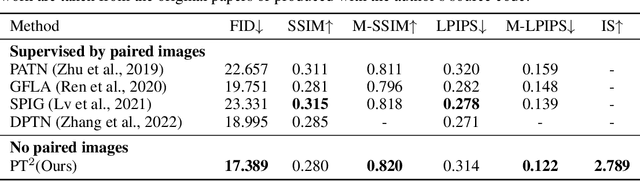
Human pose transfer aims to synthesize a new view of a person under a given pose. Recent works achieve this via self-reconstruction, which disentangles pose and texture features from the person image, then combines the two features to reconstruct the person. Such feature-level disentanglement is a difficult and ill-defined problem that could lead to loss of details and unwanted artifacts. In this paper, we propose a self-driven human pose transfer method that permutes the textures at random, then reconstructs the image with a dual branch attention to achieve image-level disentanglement and detail-preserving texture transfer. We find that compared with feature-level disentanglement, image-level disentanglement is more controllable and reliable. Furthermore, we introduce a dual kernel encoder that gives different sizes of receptive fields in order to reduce the noise caused by permutation and thus recover clothing details while aligning pose and textures. Extensive experiments on DeepFashion and Market-1501 shows that our model improves the quality of generated images in terms of FID, LPIPS and SSIM over other self-driven methods, and even outperforming some fully-supervised methods. A user study also shows that among self-driven approaches, images generated by our method are preferred in 72% of cases over prior work.
Generative Modeling for Low Dimensional Speech Attributes with Neural Spline Flows
Mar 07, 2022
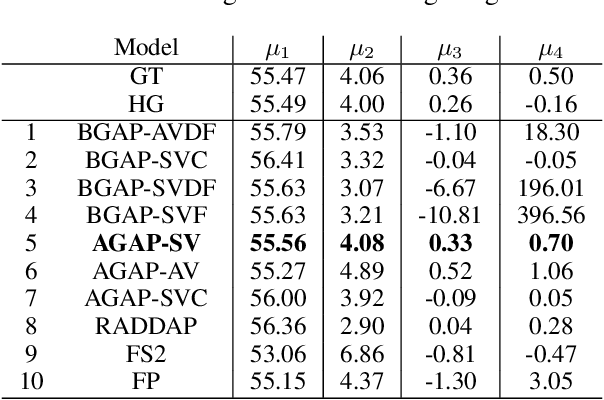
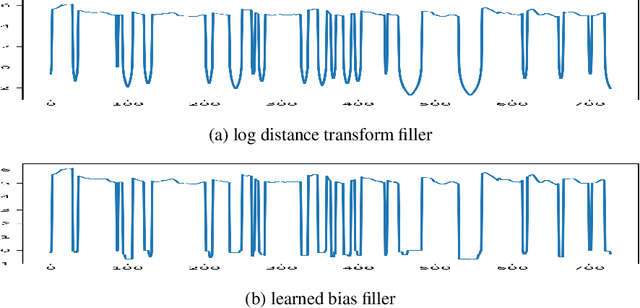
Despite recent advances in generative modeling for text-to-speech synthesis, these models do not yet have the same fine-grained adjustability of pitch-conditioned deterministic models such as FastPitch and FastSpeech2. Pitch information is not only low-dimensional, but also discontinuous, making it particularly difficult to model in a generative setting. Our work explores several techniques for handling the aforementioned issues in the context of Normalizing Flow models. We also find this problem to be very well suited for Neural Spline flows, which is a highly expressive alternative to the more common affine-coupling mechanism in Normalizing Flows.
One TTS Alignment To Rule Them All
Aug 23, 2021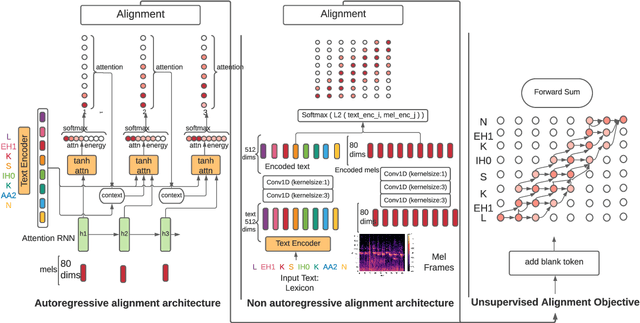
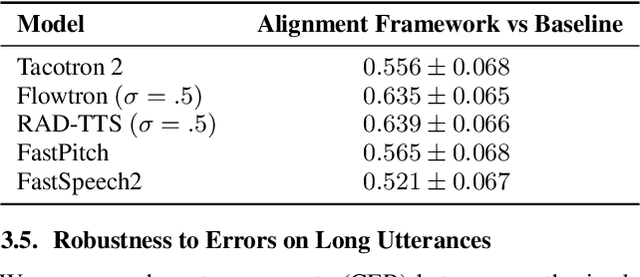
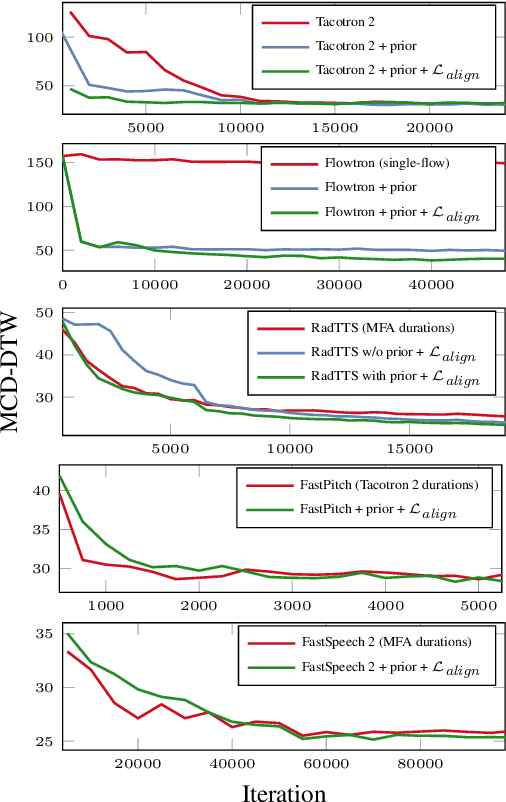
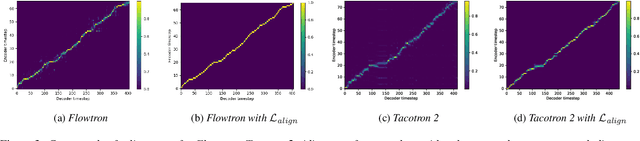
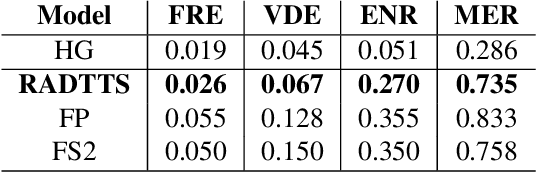
Speech-to-text alignment is a critical component of neural textto-speech (TTS) models. Autoregressive TTS models typically use an attention mechanism to learn these alignments on-line. However, these alignments tend to be brittle and often fail to generalize to long utterances and out-of-domain text, leading to missing or repeating words. Most non-autoregressive endto-end TTS models rely on durations extracted from external sources. In this paper we leverage the alignment mechanism proposed in RAD-TTS as a generic alignment learning framework, easily applicable to a variety of neural TTS models. The framework combines forward-sum algorithm, the Viterbi algorithm, and a simple and efficient static prior. In our experiments, the alignment learning framework improves all tested TTS architectures, both autoregressive (Flowtron, Tacotron 2) and non-autoregressive (FastPitch, FastSpeech 2, RAD-TTS). Specifically, it improves alignment convergence speed of existing attention-based mechanisms, simplifies the training pipeline, and makes the models more robust to errors on long utterances. Most importantly, the framework improves the perceived speech synthesis quality, as judged by human evaluators.
Unsupervised Disentanglement of Pose, Appearance and Background from Images and Videos
Jan 26, 2020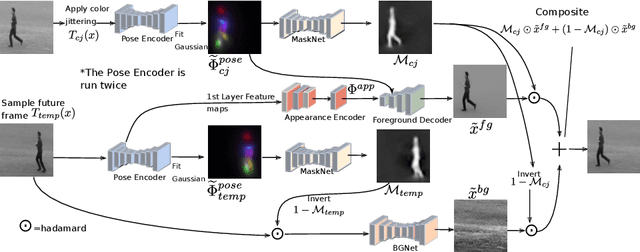

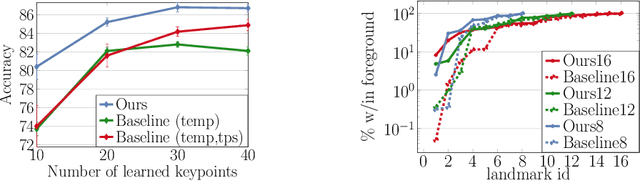
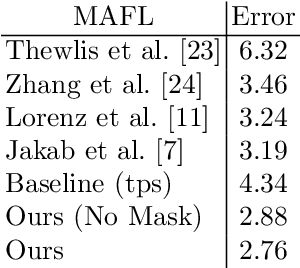
Unsupervised landmark learning is the task of learning semantic keypoint-like representations without the use of expensive input keypoint-level annotations. A popular approach is to factorize an image into a pose and appearance data stream, then to reconstruct the image from the factorized components. The pose representation should capture a set of consistent and tightly localized landmarks in order to facilitate reconstruction of the input image. Ultimately, we wish for our learned landmarks to focus on the foreground object of interest. However, the reconstruction task of the entire image forces the model to allocate landmarks to model the background. This work explores the effects of factorizing the reconstruction task into separate foreground and background reconstructions, conditioning only the foreground reconstruction on the unsupervised landmarks. Our experiments demonstrate that the proposed factorization results in landmarks that are focused on the foreground object of interest. Furthermore, the rendered background quality is also improved, as the background rendering pipeline no longer requires the ill-suited landmarks to model its pose and appearance. We demonstrate this improvement in the context of the video-prediction task.
Video Interpolation and Prediction with Unsupervised Landmarks
Sep 06, 2019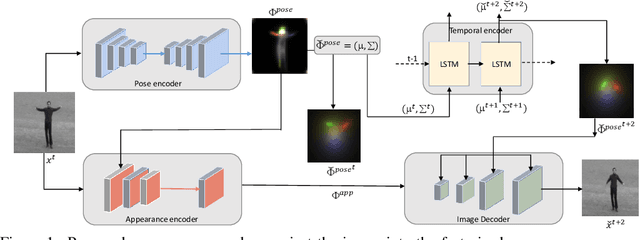
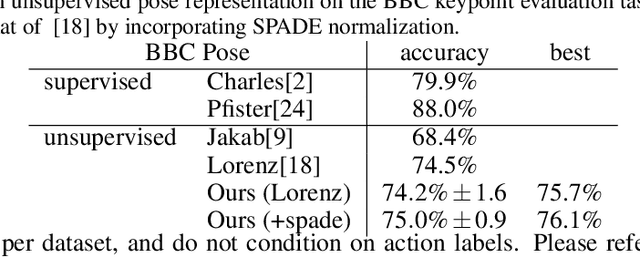
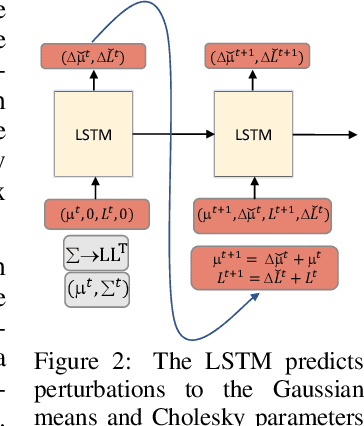
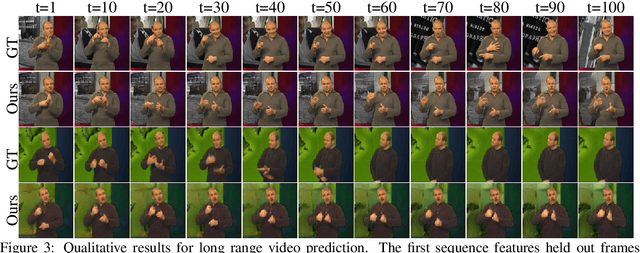
Prediction and interpolation for long-range video data involves the complex task of modeling motion trajectories for each visible object, occlusions and dis-occlusions, as well as appearance changes due to viewpoint and lighting. Optical flow based techniques generalize but are suitable only for short temporal ranges. Many methods opt to project the video frames to a low dimensional latent space, achieving long-range predictions. However, these latent representations are often non-interpretable, and therefore difficult to manipulate. This work poses video prediction and interpolation as unsupervised latent structure inference followed by a temporal prediction in this latent space. The latent representations capture foreground semantics without explicit supervision such as keypoints or poses. Further, as each landmark can be mapped to a coordinate indicating where a semantic part is positioned, we can reliably interpolate within the coordinate domain to achieve predictable motion interpolation. Given an image decoder capable of mapping these landmarks back to the image domain, we are able to achieve high-quality long-range video interpolation and extrapolation by operating on the landmark representation space.
Unsupervised Video Interpolation Using Cycle Consistency
Jun 13, 2019
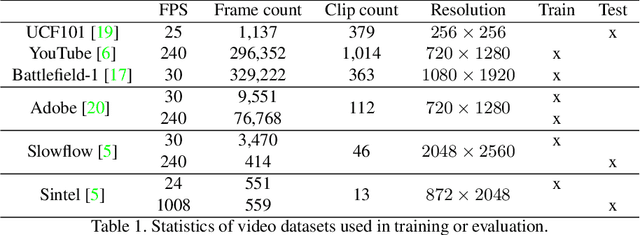
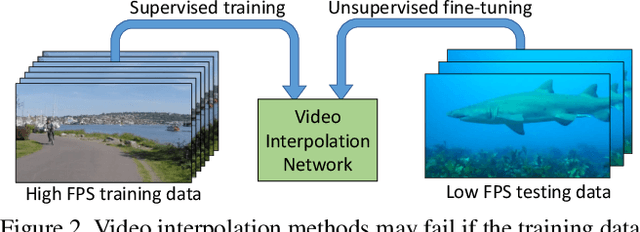
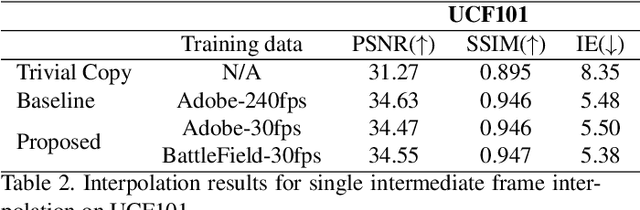
Learning to synthesize high frame rate videos via interpolation requires large quantities of high frame rate training videos, which, however, are scarce, especially at high resolutions. Here, we propose unsupervised techniques to synthesize high frame rate videos directly from low frame rate videos using cycle consistency. For a triplet of consecutive frames, we optimize models to minimize the discrepancy between the center frame and its cycle reconstruction, obtained by interpolating back from interpolated intermediate frames. This simple unsupervised constraint alone achieves results comparable with supervision using the ground truth intermediate frames. We further introduce a pseudo supervised loss term that enforces the interpolated frames to be consistent with predictions of a pre-trained interpolation model. The pseudo supervised loss term, used together with cycle consistency, can effectively adapt a pre-trained model to a new target domain. With no additional data and in a completely unsupervised fashion, our techniques significantly improve pre-trained models on new target domains, increasing PSNR values from 32.84dB to 33.05dB on the Slowflow and from 31.82dB to 32.53dB on the Sintel evaluation datasets.
Graphical Contrastive Losses for Scene Graph Generation
Mar 28, 2019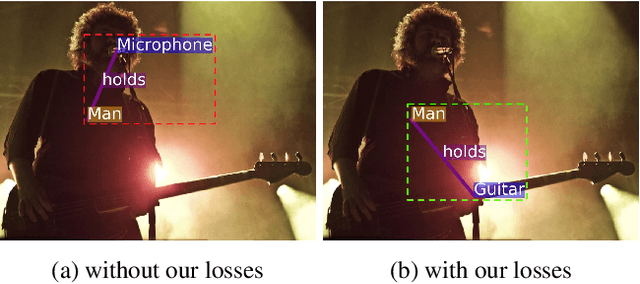
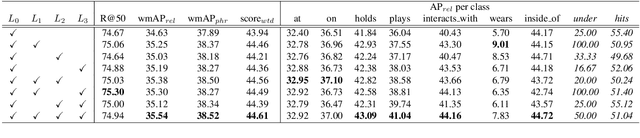
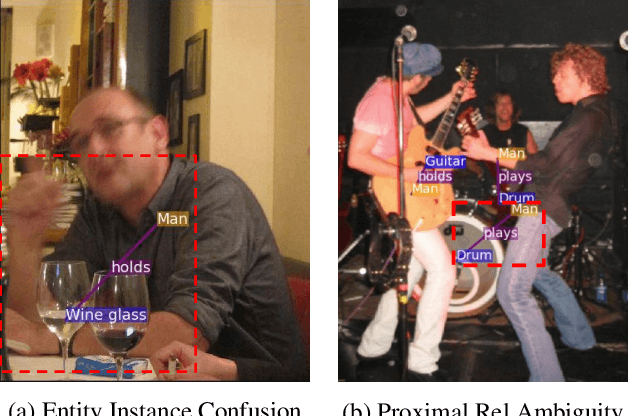

Most scene graph generators use a two-stage pipeline to detect visual relationships: the first stage detects entities, and the second predicts the predicate for each entity pair using a softmax distribution. We find that such pipelines, trained with only a cross entropy loss over predicate classes, suffer from two common errors. The first, Entity Instance Confusion, occurs when the model confuses multiple instances of the same type of entity (e.g. multiple cups). The second, Proximal Relationship Ambiguity, arises when multiple subject-predicate-object triplets appear in close proximity with the same predicate, and the model struggles to infer the correct subject-object pairings (e.g. mis-pairing musicians and their instruments). We propose a set of contrastive loss formulations that specifically target these types of errors within the scene graph generation problem, collectively termed the Graphical Contrastive Losses. These losses explicitly force the model to disambiguate related and unrelated instances through margin constraints specific to each type of confusion. We further construct a relationship detector, called RelDN, using the aforementioned pipeline to demonstrate the efficacy of our proposed losses. Our model outperforms the winning method of the OpenImages Relationship Detection Challenge by 4.7\% (16.5\% relative) on the test set. We also show improved results over the best previous methods on the Visual Genome and Visual Relationship Detection datasets.