 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Classifier is Secretly an Energy Based Model and You Should Treat it Like One
Dec 11, 2019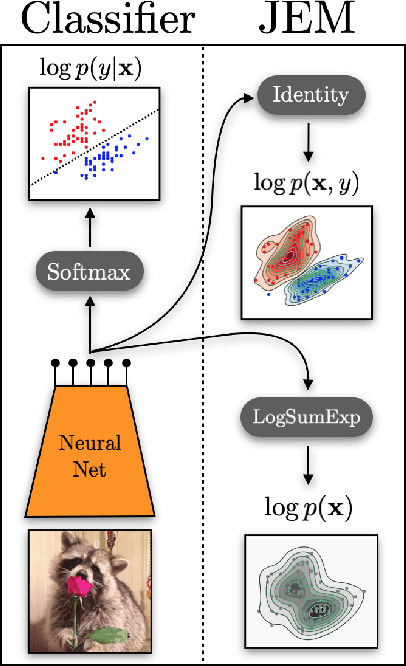
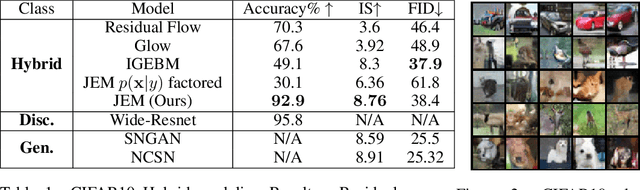
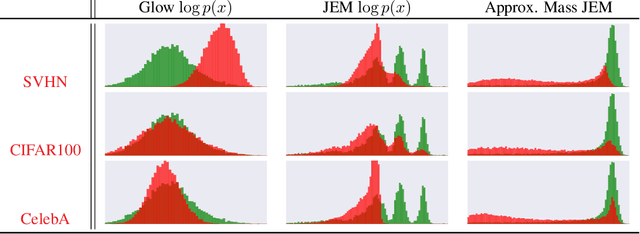

We propose to reinterpret a standard discriminative classifier of p(y|x) as an energy based model for the joint distribution p(x,y). In this setting, the standard class probabilities can be easily computed as well as unnormalized values of p(x) and p(x|y). Within this framework, standard discriminative architectures may beused and the model can also be trained on unlabeled data. We demonstrate that energy based training of the joint distribution improves calibration, robustness, andout-of-distribution detection while also enabling our models to generate samplesrivaling the quality of recent GAN approaches. We improve upon recently proposed techniques for scaling up the training of energy based models and presentan approach which adds little overhead compared to standard classification training. Our approach is the first to achieve performance rivaling the state-of-the-artin both generative and discriminative learning within one hybrid model.
MIM: Mutual Information Machine
Oct 14, 2019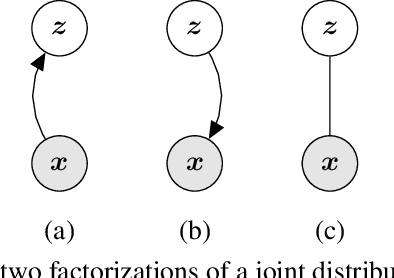
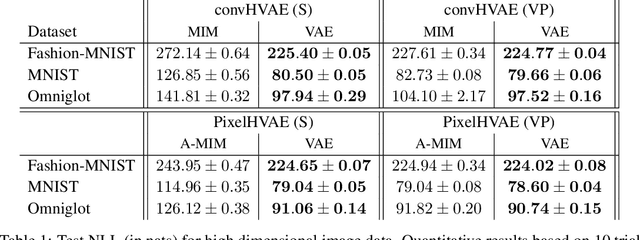
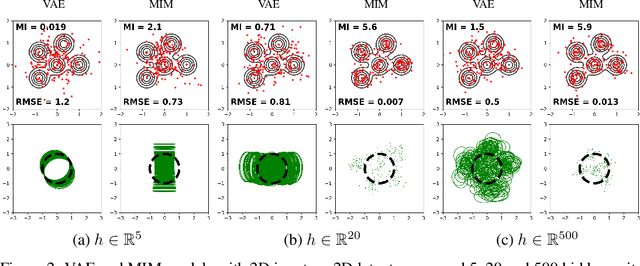

We introduce the Mutual Information Machine (MIM), an autoencoder model for learning joint distributions over observations and latent states. The model formulation reflects two key design principles: 1) symmetry, to encourage the encoder and decoder to learn consistent factorizations of the same underlying distribution; and 2) mutual information, to encourage the learning of useful representations for downstream tasks. The objective comprises the Jensen-Shannon divergence between the encoding and decoding joint distributions, plus a mutual information term. We show that this objective can be bounded by a tractable cross-entropy loss between the true model and a parameterized approximation, and relate this to maximum likelihood estimation and variational autoencoders. Experiments show that MIM is capable of learning a latent representation with high mutual information, and good unsupervised clustering, while providing data log likelihood comparable to VAE (with a sufficiently expressive architecture).
High Mutual Information in Representation Learning with Symmetric Variational Inference
Oct 04, 2019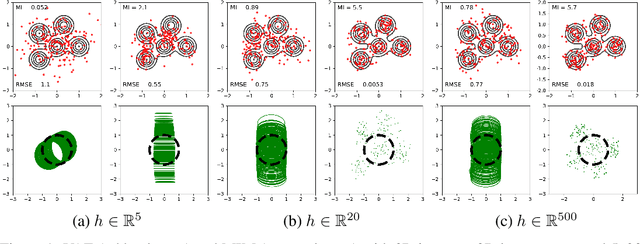

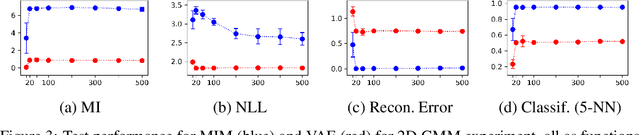

We introduce the Mutual Information Machine (MIM), a novel formulation of representation learning, using a joint distribution over the observations and latent state in an encoder/decoder framework. Our key principles are symmetry and mutual information, where symmetry encourages the encoder and decoder to learn different factorizations of the same underlying distribution, and mutual information, to encourage the learning of useful representations for downstream tasks. Our starting point is the symmetric Jensen-Shannon divergence between the encoding and decoding joint distributions, plus a mutual information encouraging regularizer. We show that this can be bounded by a tractable cross entropy loss function between the true model and a parameterized approximation, and relate this to the maximum likelihood framework. We also relate MIM to variational autoencoders (VAEs) and demonstrate that MIM is capable of learning symmetric factorizations, with high mutual information that avoids posterior collapse.
Learning Execution through Neural Code Fusion
Jun 17, 2019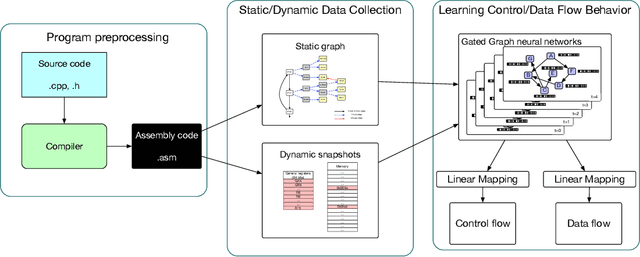
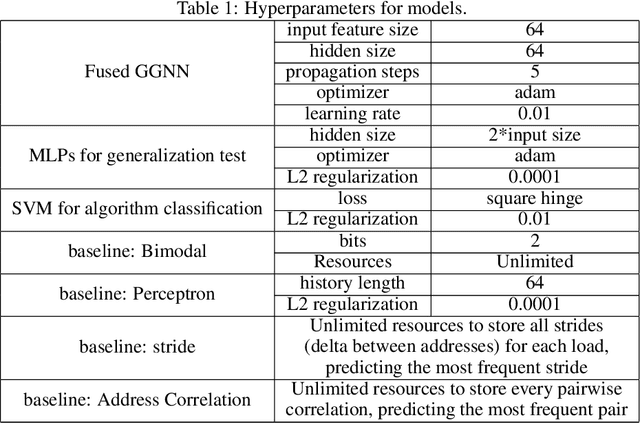
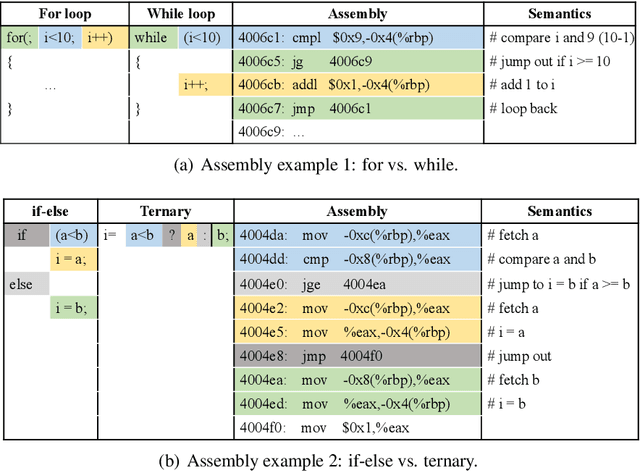
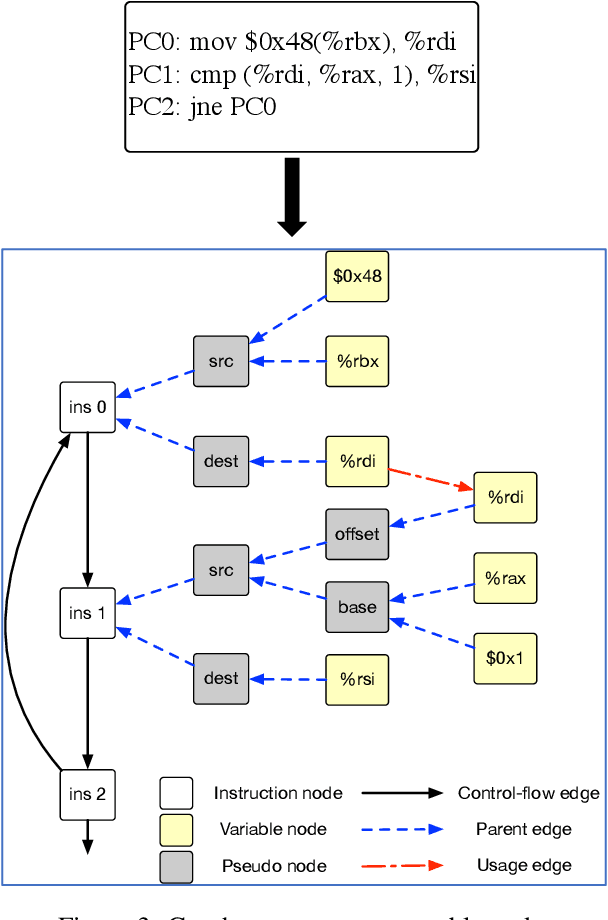
As the performance of computer systems stagnates due to the end of Moore's Law, there is a need for new models that can understand and optimize the execution of general purpose code. While there is a growing body of work on using Graph Neural Networks (GNNs) to learn representations of source code, these representations do not understand how code dynamically executes. In this work, we propose a new approach to use GNNs to learn fused representations of general source code and its execution. Our approach defines a multi-task GNN over low-level representations of source code and program state (i.e., assembly code and dynamic memory states), converting complex source code constructs and complex data structures into a simpler, more uniform format. We show that this leads to improved performance over similar methods that do not use execution and it opens the door to applying GNN models to new tasks that would not be feasible from static code alone. As an illustration of this, we apply the new model to challenging dynamic tasks (branch prediction and prefetching) from the SPEC CPU benchmark suite, outperforming the state-of-the-art by 26% and 45% respectively. Moreover, we use the learned fused graph embeddings to demonstrate transfer learning with high performance on an indirectly related task (algorithm classification).
Flexibly Fair Representation Learning by Disentanglement
Jun 06, 2019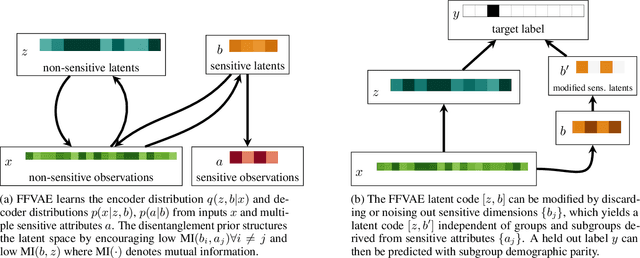
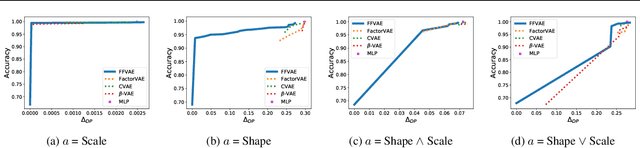
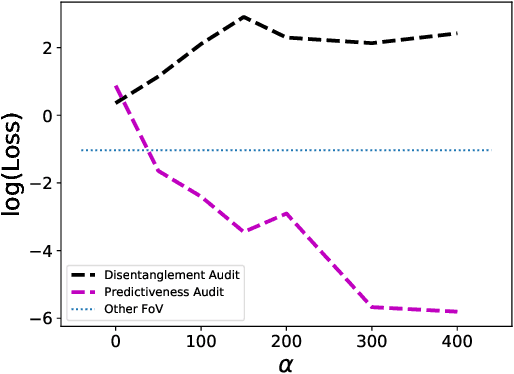
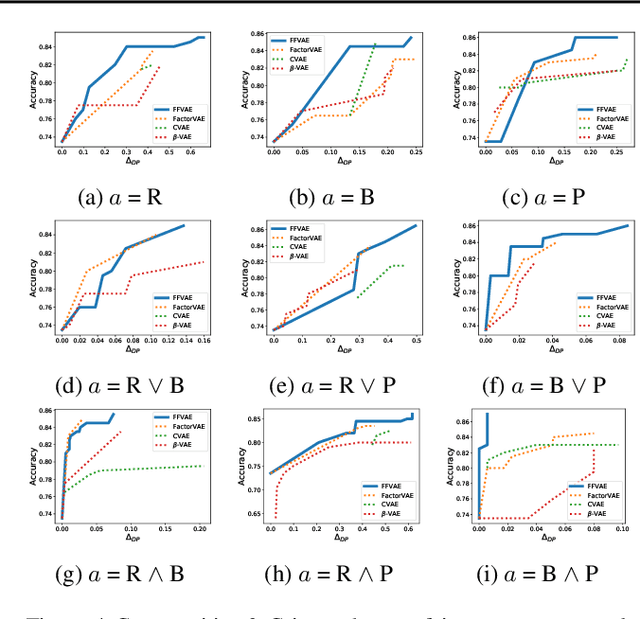
We consider the problem of learning representations that achieve group and subgroup fairness with respect to multiple sensitive attributes. Taking inspiration from the disentangled representation learning literature, we propose an algorithm for learning compact representations of datasets that are useful for reconstruction and prediction, but are also \emph{flexibly fair}, meaning they can be easily modified at test time to achieve subgroup demographic parity with respect to multiple sensitive attributes and their conjunctions. We show empirically that the resulting encoder---which does not require the sensitive attributes for inference---enables the adaptation of a single representation to a variety of fair classification tasks with new target labels and subgroup definitions.
Learning Sparse Networks Using Targeted Dropout
Jun 05, 2019

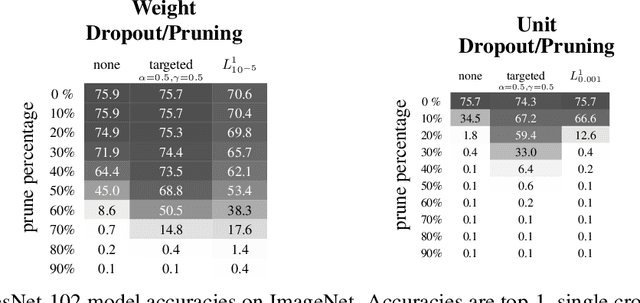
Neural networks are easier to optimise when they have many more weights than are required for modelling the mapping from inputs to outputs. This suggests a two-stage learning procedure that first learns a large net and then prunes away connections or hidden units. But standard training does not necessarily encourage nets to be amenable to pruning. We introduce targeted dropout, a method for training a neural network so that it is robust to subsequent pruning. Before computing the gradients for each weight update, targeted dropout stochastically selects a set of units or weights to be dropped using a simple self-reinforcing sparsity criterion and then computes the gradients for the remaining weights. The resulting network is robust to post hoc pruning of weights or units that frequently occur in the dropped sets. The method improves upon more complicated sparsifying regularisers while being simple to implement and easy to tune.
Graph Normalizing Flows
May 30, 2019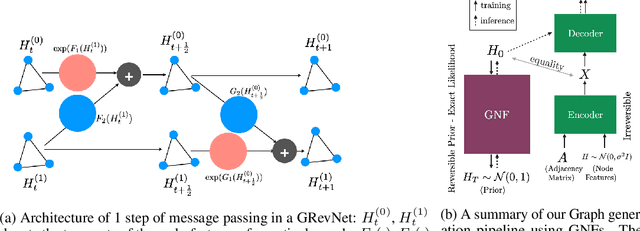
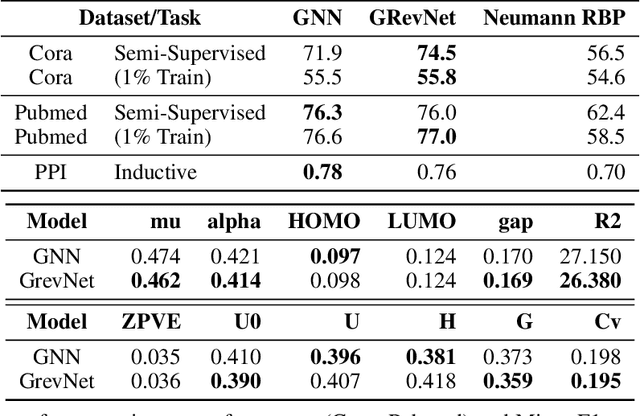

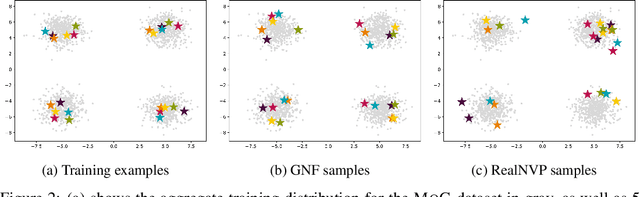
We introduce graph normalizing flows: a new, reversible graph neural network model for prediction and generation. On supervised tasks, graph normalizing flows perform similarly to message passing neural networks, but at a significantly reduced memory footprint, allowing them to scale to larger graphs. In the unsupervised case, we combine graph normalizing flows with a novel graph auto-encoder to create a generative model of graph structures. Our model is permutation-invariant, generating entire graphs with a single feed-forward pass, and achieves competitive results with the state-of-the art auto-regressive models, while being better suited to parallel computing architectures.
Neural Networks for Modeling Source Code Edits
Apr 04, 2019
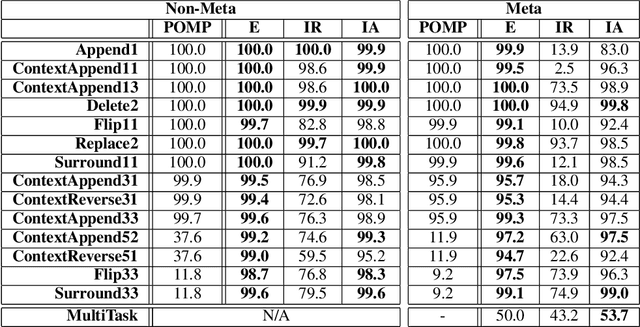

Programming languages are emerging as a challenging and interesting domain for machine learning. A core task, which has received significant attention in recent years, is building generative models of source code. However, to our knowledge, previous generative models have always been framed in terms of generating static snapshots of code. In this work, we instead treat source code as a dynamic object and tackle the problem of modeling the edits that software developers make to source code files. This requires extracting intent from previous edits and leveraging it to generate subsequent edits. We develop several neural networks and use synthetic data to test their ability to learn challenging edit patterns that require strong generalization. We then collect and train our models on a large-scale dataset of Google source code, consisting of millions of fine-grained edits from thousands of Python developers. From the modeling perspective, our main conclusion is that a new composition of attentional and pointer network components provides the best overall performance and scalability. From the application perspective, our results provide preliminary evidence of the feasibility of developing tools that learn to predict future edits.
Meta-Dataset: A Dataset of Datasets for Learning to Learn from Few Examples
Mar 07, 2019
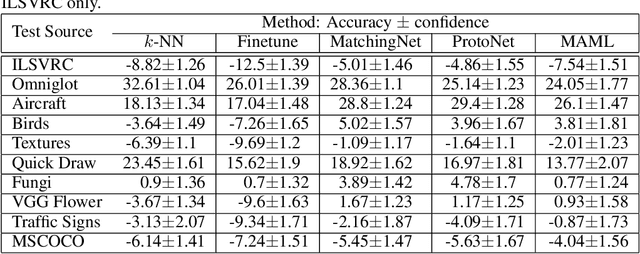

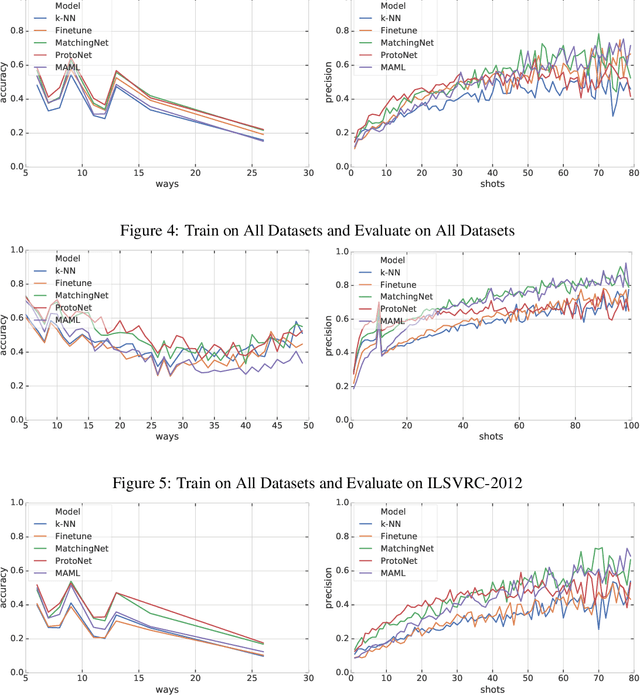
Few-shot classification refers to learning a classifier for new classes given only a few examples. While a plethora of models have emerged to tackle this recently, we find the current procedure and datasets that are used to systematically assess progress in this setting lacking. To address this, we propose Meta-Dataset: a new benchmark for training and evaluating few-shot classifiers that is large-scale, consists of multiple datasets, and presents more natural and realistic tasks. The aim is to measure the ability of state-of-the-art models to leverage diverse sources of data to achieve higher generalization, and to evaluate that generalization ability in a more challenging setting. We additionally measure robustness of current methods to variations in the number of available examples and the number of classes. Finally our extensive empirical evaluation leads us to identify weaknesses in Prototypical Networks and MAML, two popular few-shot classification methods, and to propose a new method, Proto-MAML, which achieves improved performance on our benchmark.
Learning Memory Access Patterns
Mar 06, 2018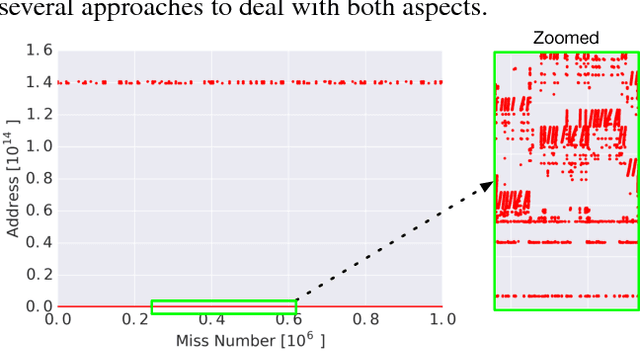
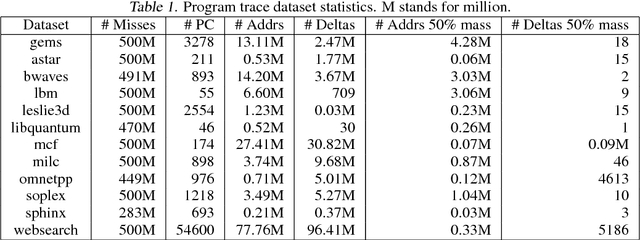
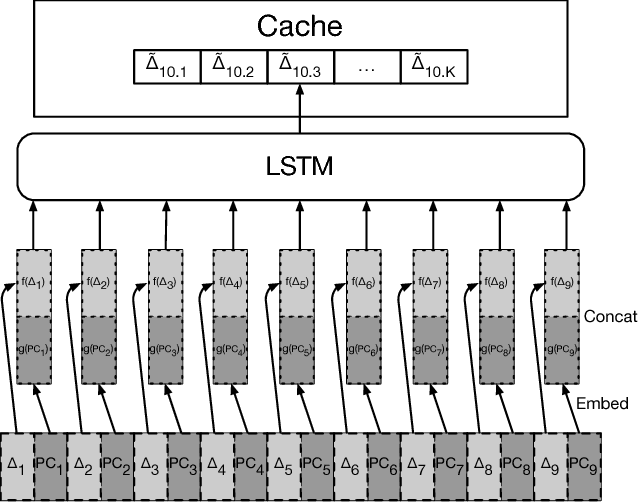
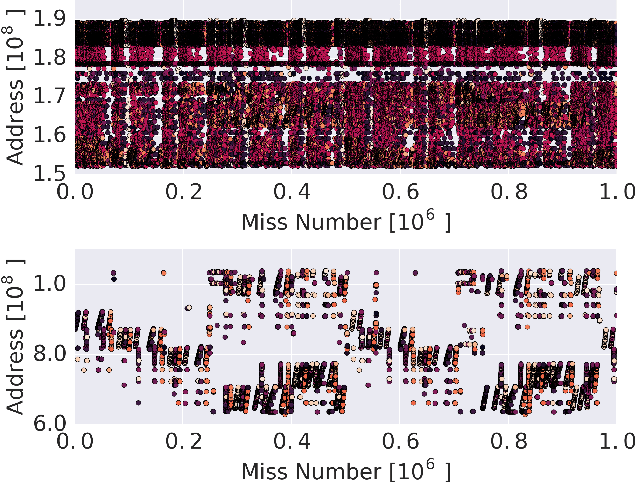
The explosion in workload complexity and the recent slow-down in Moore's law scaling call for new approaches towards efficient computing. Researchers are now beginning to use recent advances in machine learning in software optimizations, augmenting or replacing traditional heuristics and data structures. However, the space of machine learning for computer hardware architecture is only lightly explored. In this paper, we demonstrate the potential of deep learning to address the von Neumann bottleneck of memory performance. We focus on the critical problem of learning memory access patterns, with the goal of constructing accurate and efficient memory prefetchers. We relate contemporary prefetching strategies to n-gram models in natural language processing, and show how recurrent neural networks can serve as a drop-in replacement. On a suite of challenging benchmark datasets, we find that neural networks consistently demonstrate superior performance in terms of precision and recall. This work represents the first step towards practical neural-network based prefetching, and opens a wide range of exciting directions for machine learning in computer architecture research.