 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScientistOne: Towards Human-Level Autonomous Research via Chain-of-Evidence
May 25, 2026Autonomous research agents produce competitive solutions and professional-looking manuscripts, yet their outputs contain verifiability failures undetectable by surface-level evaluation: fabricated citations, unreproducible scores, and method descriptions that diverge from the implementation. We address this through three contributions. First, Chain-of-Evidence (CoE), a verifiability framework requiring every claim to be traceable to its evidence source. Second, ScientistOne, an end-to-end autonomous research system that maintains evidence chains by construction throughout literature review, solution discovery, and paper writing. Third, CoE Audit, a post-hoc audit whose four integrity checks -- score verification, specification violation, reference verification, and method-code alignment -- apply uniformly to all systems. Across 75 papers spanning five systems and five frontier research tasks, every baseline exhibits at least one systematic failure mode: hallucinated reference rates reach 21%, score verification passes in as few as 42% of papers, and method-code alignment ranges from 20% to 80%. ScientistOne achieves zero hallucinated references (0/337), perfect score verification (12/12), and the highest method-code alignment (14/15), while matching or exceeding human expert performance on all five tasks. ScientistOne further generalizes to six additional tasks spanning medical imaging, fine-grained recognition, 3D perception, and language modeling, achieving state-of-the-art on Parameter Golf and gold medals on MLE-Bench tasks where baselines fail entirely.
A Multi-agent AI System for Deep Learning Model Migration from TensorFlow to JAX
Mar 28, 2026The rapid development of AI-based products and their underlying models has led to constant innovation in deep learning frameworks. Google has been pioneering machine learning usage across dozens of products. Maintaining the multitude of model source codes in different ML frameworks and versions is a significant challenge. So far the maintenance and migration work was done largely manually by human experts. We describe an AI-based multi-agent system that we built to support automatic migration of TensorFlow-based deep learning models into JAX-based ones. We make three main contributions: First, we show how an AI planner that uses a mix of static analysis with AI instructions can create migration plans for very complex code components that are reliably followed by the combination of an orchestrator and coders, using AI-generated example-based playbooks. Second, we define quality metrics and AI-based judges that accelerate development when the code to evaluate has no tests and has to adhere to strict style and dependency requirements. Third, we demonstrate how the system accelerates code migrations in a large hyperscaler environment on commercial real-world use-cases. Our approach dramatically reduces the time (6.4x-8x speedup) for deep learning model migrations and creates a virtuous circle where effectively AI supports its own development workflow. We expect that the techniques and approaches described here can be generalized for other framework migrations and general code transformation tasks.
ArchAgent: Agentic AI-driven Computer Architecture Discovery
Feb 25, 2026Agile hardware design flows are a critically needed force multiplier to meet the exploding demand for compute. Recently, agentic generative AI systems have demonstrated significant advances in algorithm design, improving code efficiency, and enabling discovery across scientific domains. Bridging these worlds, we present ArchAgent, an automated computer architecture discovery system built on AlphaEvolve. We show ArchAgent's ability to automatically design/implement state-of-the-art (SoTA) cache replacement policies (architecting new mechanisms/logic, not only changing parameters), broadly within the confines of an established cache replacement policy design competition. In two days without human intervention, ArchAgent generated a policy achieving a 5.3% IPC speedup improvement over the prior SoTA on public multi-core Google Workload Traces. On the heavily-explored single-core SPEC06 workloads, it generated a policy in just 18 days showing a 0.9% IPC speedup improvement over the existing SoTA (a similar "winning margin" as reported by the existing SoTA). ArchAgent achieved these gains 3-5x faster than prior human-developed SoTA policies. Agentic flows also enable "post-silicon hyperspecialization" where agents tune runtime-configurable parameters exposed in hardware policies to further align the policies with a specific workload (mix). Exploiting this, we demonstrate a 2.4% IPC speedup improvement over prior SoTA on SPEC06 workloads. Finally, we outline broader implications for computer architecture research in the era of agentic AI. For example, we demonstrate the phenomenon of "simulator escapes", where the agentic AI flow discovered and exploited a loophole in a popular microarchitectural simulator - a consequence of the fact that these research tools were designed for a (now past) world where they were exclusively operated by humans acting in good-faith.
SWE-fficiency: Can Language Models Optimize Real-World Repositories on Real Workloads?
Nov 11, 2025



Optimizing the performance of large-scale software repositories demands expertise in code reasoning and software engineering (SWE) to reduce runtime while preserving program correctness. However, most benchmarks emphasize what to fix rather than how to fix code. We introduce SWE-fficiency, a benchmark for evaluating repository-level performance optimization on real workloads. Our suite contains 498 tasks across nine widely used data-science, machine-learning, and HPC repositories (e.g., numpy, pandas, scipy): given a complete codebase and a slow workload, an agent must investigate code semantics, localize bottlenecks and relevant tests, and produce a patch that matches or exceeds expert speedup while passing the same unit tests. To enable this how-to-fix evaluation, our automated pipeline scrapes GitHub pull requests for performance-improving edits, combining keyword filtering, static analysis, coverage tooling, and execution validation to both confirm expert speedup baselines and identify relevant repository unit tests. Empirical evaluation of state-of-the-art agents reveals significant underperformance. On average, agents achieve less than 0.15x the expert speedup: agents struggle in localizing optimization opportunities, reasoning about execution across functions, and maintaining correctness in proposed edits. We release the benchmark and accompanying data pipeline to facilitate research on automated performance engineering and long-horizon software reasoning.
Concorde: Fast and Accurate CPU Performance Modeling with Compositional Analytical-ML Fusion
Mar 29, 2025Cycle-level simulators such as gem5 are widely used in microarchitecture design, but they are prohibitively slow for large-scale design space explorations. We present Concorde, a new methodology for learning fast and accurate performance models of microarchitectures. Unlike existing simulators and learning approaches that emulate each instruction, Concorde predicts the behavior of a program based on compact performance distributions that capture the impact of different microarchitectural components. It derives these performance distributions using simple analytical models that estimate bounds on performance induced by each microarchitectural component, providing a simple yet rich representation of a program's performance characteristics across a large space of microarchitectural parameters. Experiments show that Concorde is more than five orders of magnitude faster than a reference cycle-level simulator, with about 2% average Cycles-Per-Instruction (CPI) prediction error across a range of SPEC, open-source, and proprietary benchmarks. This enables rapid design-space exploration and performance sensitivity analyses that are currently infeasible, e.g., in about an hour, we conducted a first-of-its-kind fine-grained performance attribution to different microarchitectural components across a diverse set of programs, requiring nearly 150 million CPI evaluations.
Learning Performance-Improving Code Edits
Feb 21, 2023The waning of Moore's Law has shifted the focus of the tech industry towards alternative methods for continued performance gains. While optimizing compilers are a standard tool to help increase program efficiency, programmers continue to shoulder much responsibility in crafting and refactoring code with better performance characteristics. In this paper, we investigate the ability of large language models (LLMs) to suggest functionally correct, performance improving code edits. We hypothesize that language models can suggest such edits in ways that would be impractical for static analysis alone. We investigate these questions by curating a large-scale dataset of Performance-Improving Edits, PIE. PIE contains trajectories of programs, where a programmer begins with an initial, slower version and iteratively makes changes to improve the program's performance. We use PIE to evaluate and improve the capacity of large language models. Specifically, use examples from PIE to fine-tune multiple variants of CODEGEN, a billion-scale Transformer-decoder model. Additionally, we use examples from PIE to prompt OpenAI's CODEX using a few-shot prompting. By leveraging PIE, we find that both CODEX and CODEGEN can generate performance-improving edits, with speedups of more than 2.5x for over 25% of the programs, for C++ and Python, even after the C++ programs were compiled using the O3 optimization level. Crucially, we show that PIE allows CODEGEN, an open-sourced and 10x smaller model than CODEX, to match the performance of CODEX on this challenging task. Overall, this work opens new doors for creating systems and methods that can help programmers write efficient code.
Learning to Improve Code Efficiency
Aug 09, 2022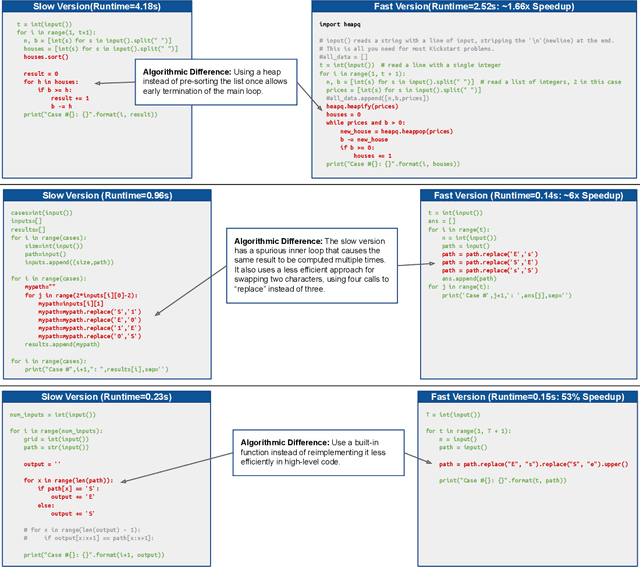
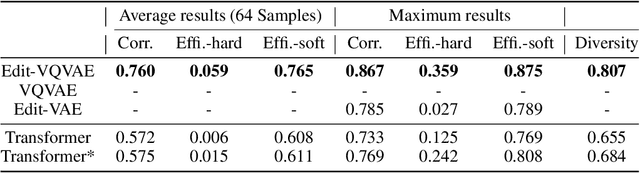
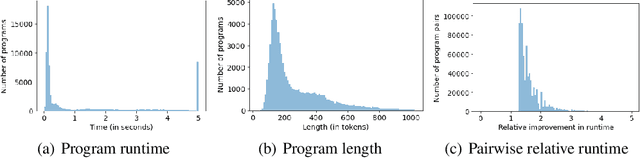

Improvements in the performance of computing systems, driven by Moore's Law, have transformed society. As such hardware-driven gains slow down, it becomes even more important for software developers to focus on performance and efficiency during development. While several studies have demonstrated the potential from such improved code efficiency (e.g., 2x better generational improvements compared to hardware), unlocking these gains in practice has been challenging. Reasoning about algorithmic complexity and the interaction of coding patterns on hardware can be challenging for the average programmer, especially when combined with pragmatic constraints around development velocity and multi-person development. This paper seeks to address this problem. We analyze a large competitive programming dataset from the Google Code Jam competition and find that efficient code is indeed rare, with a 2x runtime difference between the median and the 90th percentile of solutions. We propose using machine learning to automatically provide prescriptive feedback in the form of hints, to guide programmers towards writing high-performance code. To automatically learn these hints from the dataset, we propose a novel discrete variational auto-encoder, where each discrete latent variable represents a different learned category of code-edit that increases performance. We show that this method represents the multi-modal space of code efficiency edits better than a sequence-to-sequence baseline and generates a distribution of more efficient solutions.
An Imitation Learning Approach for Cache Replacement
Jul 09, 2020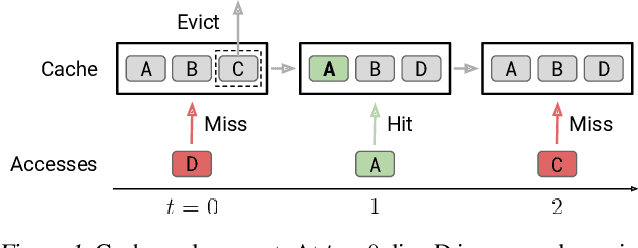
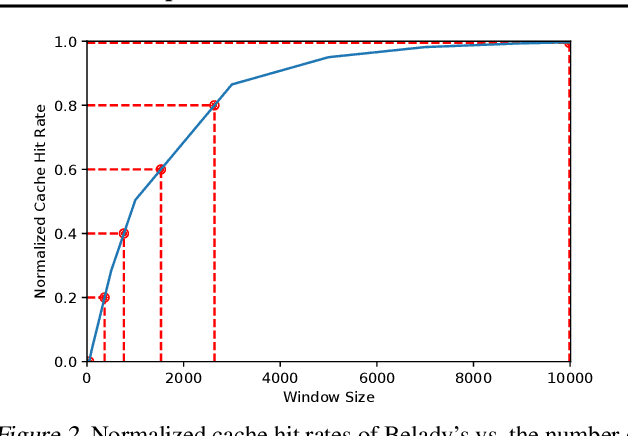
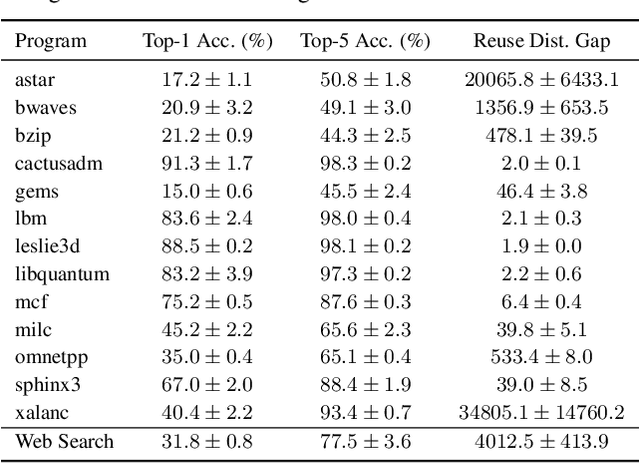
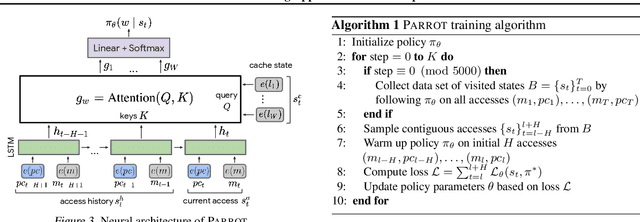
Program execution speed critically depends on increasing cache hits, as cache hits are orders of magnitude faster than misses. To increase cache hits, we focus on the problem of cache replacement: choosing which cache line to evict upon inserting a new line. This is challenging because it requires planning far ahead and currently there is no known practical solution. As a result, current replacement policies typically resort to heuristics designed for specific common access patterns, which fail on more diverse and complex access patterns. In contrast, we propose an imitation learning approach to automatically learn cache access patterns by leveraging Belady's, an oracle policy that computes the optimal eviction decision given the future cache accesses. While directly applying Belady's is infeasible since the future is unknown, we train a policy conditioned only on past accesses that accurately approximates Belady's even on diverse and complex access patterns, and call this approach Parrot. When evaluated on 13 of the most memory-intensive SPEC applications, Parrot increases cache miss rates by 20% over the current state of the art. In addition, on a large-scale web search benchmark, Parrot increases cache hit rates by 61% over a conventional LRU policy. We release a Gym environment to facilitate research in this area, as data is plentiful, and further advancements can have significant real-world impact.
Neural Execution Engines: Learning to Execute Subroutines
Jun 23, 2020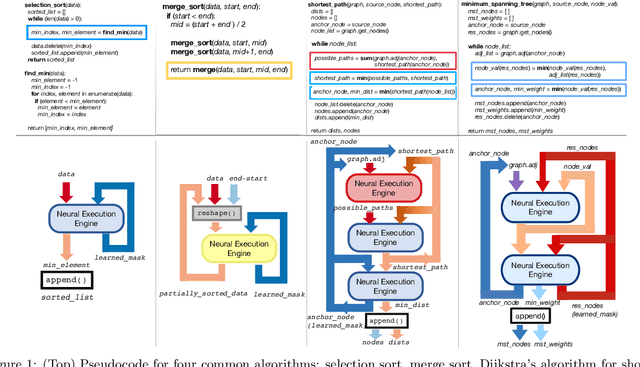
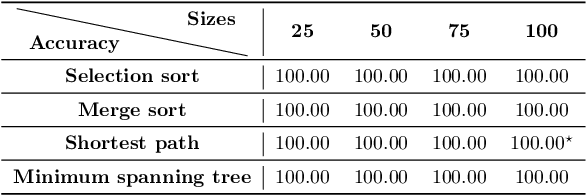
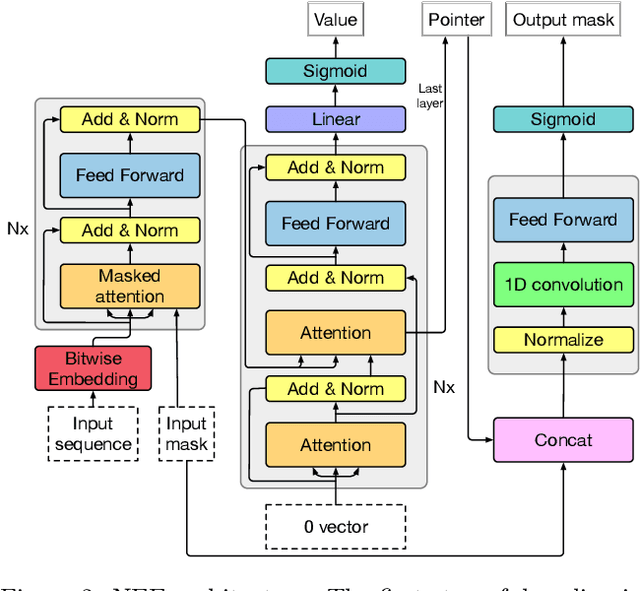
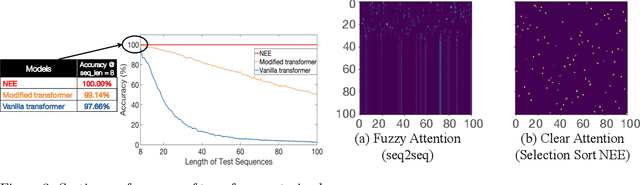
A significant effort has been made to train neural networks that replicate algorithmic reasoning, but they often fail to learn the abstract concepts underlying these algorithms. This is evidenced by their inability to generalize to data distributions that are outside of their restricted training sets, namely larger inputs and unseen data. We study these generalization issues at the level of numerical subroutines that comprise common algorithms like sorting, shortest paths, and minimum spanning trees. First, we observe that transformer-based sequence-to-sequence models can learn subroutines like sorting a list of numbers, but their performance rapidly degrades as the length of lists grows beyond those found in the training set. We demonstrate that this is due to attention weights that lose fidelity with longer sequences, particularly when the input numbers are numerically similar. To address the issue, we propose a learned conditional masking mechanism, which enables the model to strongly generalize far outside of its training range with near-perfect accuracy on a variety of algorithms. Second, to generalize to unseen data, we show that encoding numbers with a binary representation leads to embeddings with rich structure once trained on downstream tasks like addition or multiplication. This allows the embedding to handle missing data by faithfully interpolating numbers not seen during training.
Learning Execution through Neural Code Fusion
Jun 17, 2019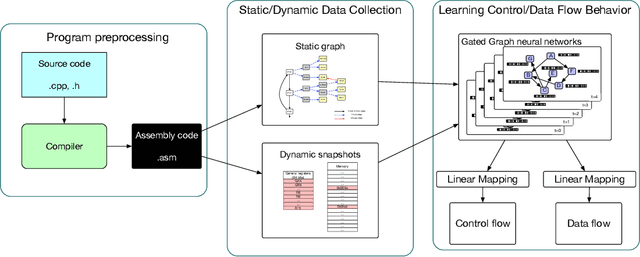
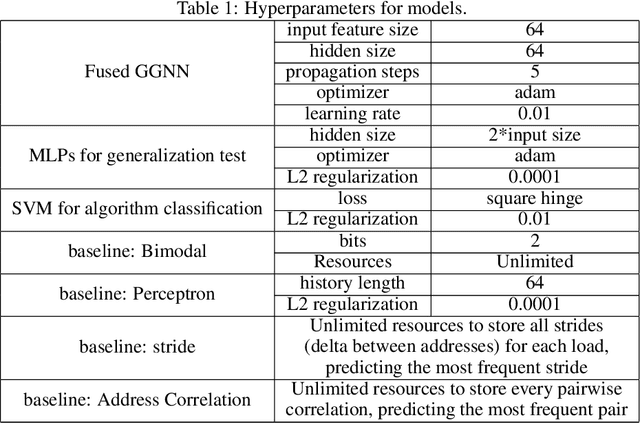
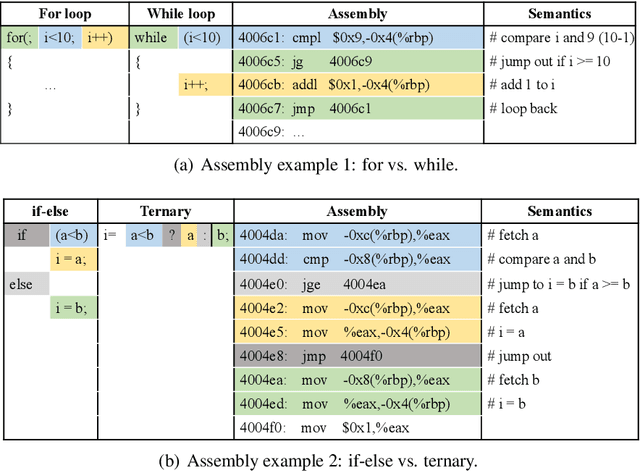
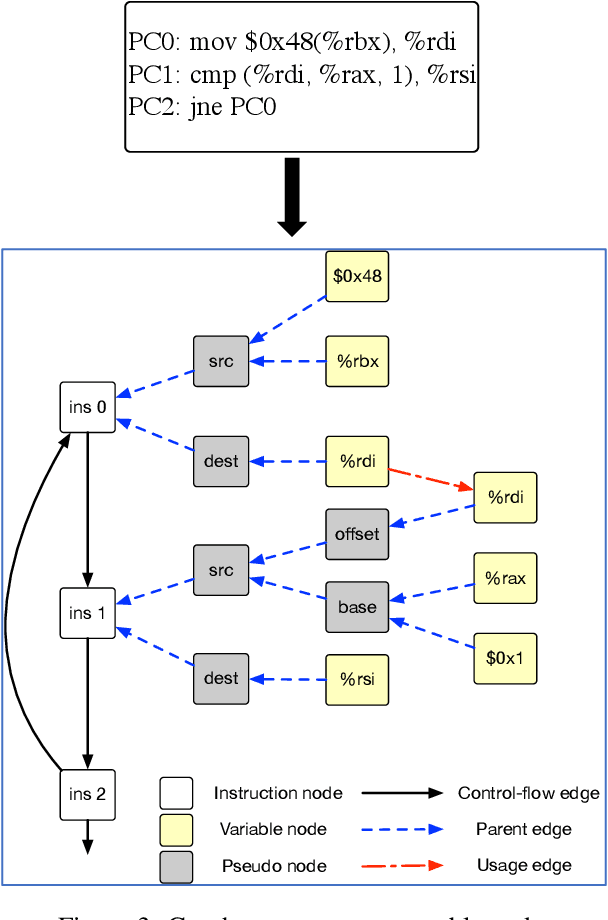
As the performance of computer systems stagnates due to the end of Moore's Law, there is a need for new models that can understand and optimize the execution of general purpose code. While there is a growing body of work on using Graph Neural Networks (GNNs) to learn representations of source code, these representations do not understand how code dynamically executes. In this work, we propose a new approach to use GNNs to learn fused representations of general source code and its execution. Our approach defines a multi-task GNN over low-level representations of source code and program state (i.e., assembly code and dynamic memory states), converting complex source code constructs and complex data structures into a simpler, more uniform format. We show that this leads to improved performance over similar methods that do not use execution and it opens the door to applying GNN models to new tasks that would not be feasible from static code alone. As an illustration of this, we apply the new model to challenging dynamic tasks (branch prediction and prefetching) from the SPEC CPU benchmark suite, outperforming the state-of-the-art by 26% and 45% respectively. Moreover, we use the learned fused graph embeddings to demonstrate transfer learning with high performance on an indirectly related task (algorithm classification).