 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Semantic Segmentation via Video Propagation and Label Relaxation
Dec 04, 2018
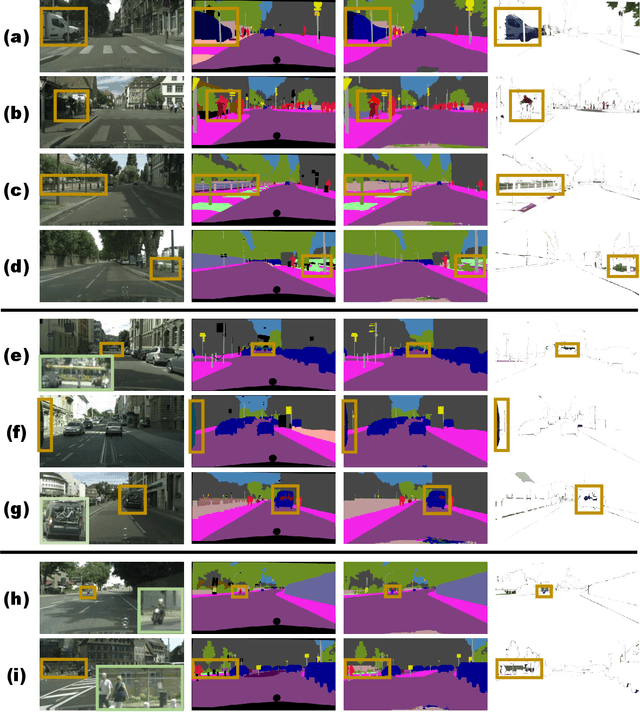

Semantic segmentation requires large amounts of pixel-wise annotations to learn accurate models. In this paper, we present a video prediction-based methodology to scale up training sets by synthesizing new training samples in order to improve the accuracy of semantic segmentation networks. We exploit video prediction models' ability to predict future frames in order to also predict future labels. A joint propagation strategy is also proposed to alleviate mis-alignments in synthesized samples. We demonstrate that training segmentation models on datasets augmented by the synthesized samples leads to significant improvements in accuracy. Furthermore, we introduce a novel boundary label relaxation technique that makes training robust to annotation noise and propagation artifacts along object boundaries. Our proposed methods achieve state-of-the-art mIoUs of 83.5% on Cityscapes and 82.9% on CamVid. Our single model, without model ensembles, achieves 72.8% mIoU on the KITTI semantic segmentation test set, which surpasses the winning entry of the ROB challenge 2018. Our code and videos can be found at https://nv-adlr.github.io/publication/2018-Segmentation.
Partial Convolution based Padding
Nov 28, 2018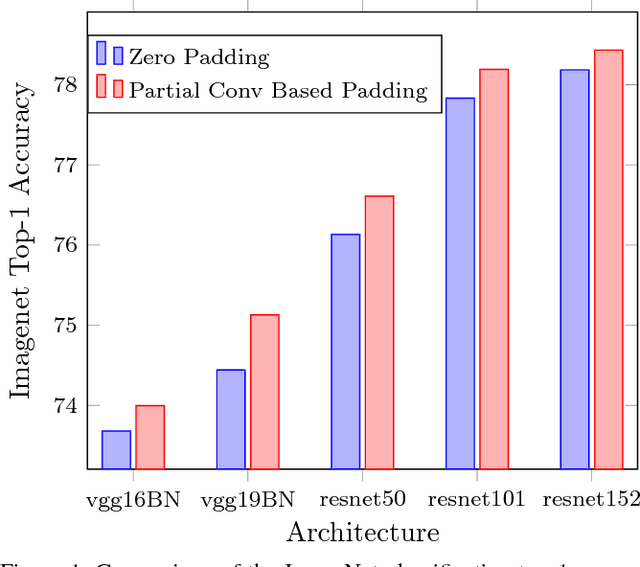
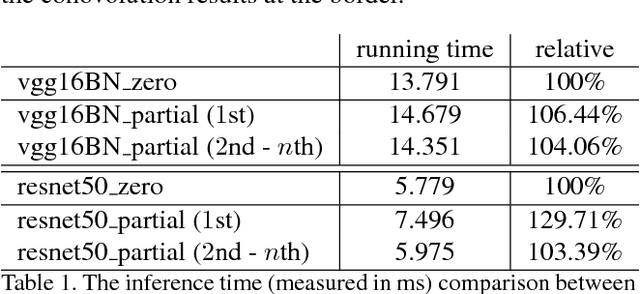
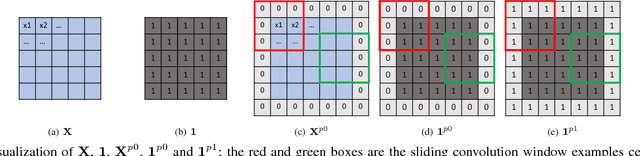
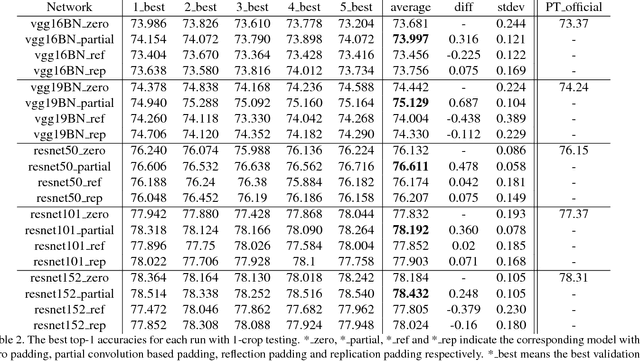
In this paper, we present a simple yet effective padding scheme that can be used as a drop-in module for existing convolutional neural networks. We call it partial convolution based padding, with the intuition that the padded region can be treated as holes and the original input as non-holes. Specifically, during the convolution operation, the convolution results are re-weighted near image borders based on the ratios between the padded area and the convolution sliding window area. Extensive experiments with various deep network models on ImageNet classification and semantic segmentation demonstrate that the proposed padding scheme consistently outperforms standard zero padding with better accuracy.
Open-vocabulary Phrase Detection
Nov 17, 2018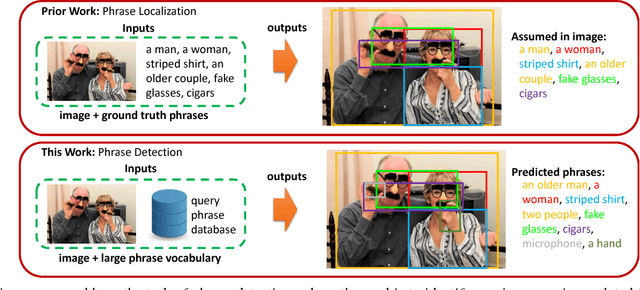
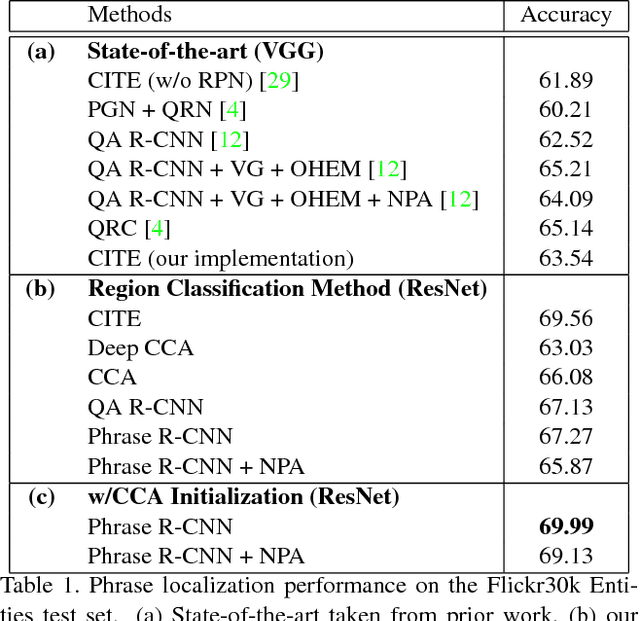
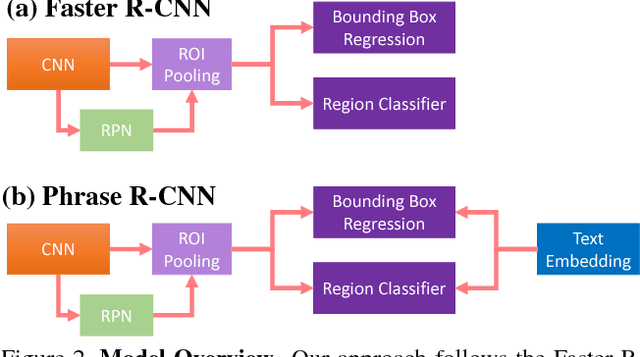

Most existing work that grounds natural language phrases in images starts with the assumption that the phrase in question is relevant to the image. In this paper we address a more realistic version of the natural language grounding task where we must both identify whether the phrase is relevant to an image and localize the phrase. This can also be viewed as a generalization of object detection to an open-ended vocabulary, essentially introducing elements of few- and zero-shot detection. We propose a Phrase R-CNN network for this task that extends Faster R-CNN to relate image regions and phrases. By carefully initializing the classification layers of our network using canonical correlation analysis (CCA), we encourage a solution that is more discerning when reasoning between similar phrases, resulting in over double the performance compared to a naive adaptation on two popular phrase grounding datasets, Flickr30K Entities and ReferIt Game, with test-time phrase vocabulary sizes of 5K and 39K, respectively.
SDCNet: Video Prediction Using Spatially-Displaced Convolution
Nov 02, 2018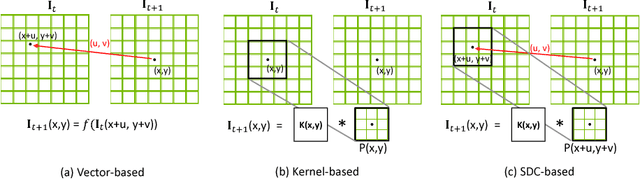
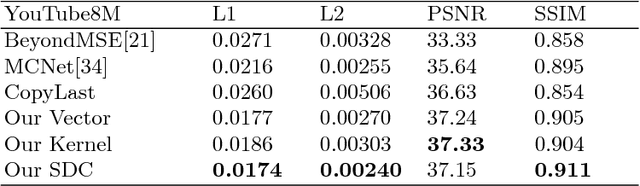
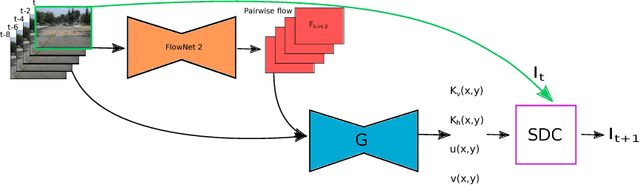
We present an approach for high-resolution video frame prediction by conditioning on both past frames and past optical flows. Previous approaches rely on resampling past frames, guided by a learned future optical flow, or on direct generation of pixels. Resampling based on flow is insufficient because it cannot deal with disocclusions. Generative models currently lead to blurry results. Recent approaches synthesis a pixel by convolving input patches with a predicted kernel. However, their memory requirement increases with kernel size. Here, we spatially-displaced convolution (SDC) module for video frame prediction. We learn a motion vector and a kernel for each pixel and synthesize a pixel by applying the kernel at a displaced location in the source image, defined by the predicted motion vector. Our approach inherits the merits of both vector-based and kernel-based approaches, while ameliorating their respective disadvantages. We train our model on 428K unlabelled 1080p video game frames. Our approach produces state-of-the-art results, achieving an SSIM score of 0.904 on high-definition YouTube-8M videos, 0.918 on Caltech Pedestrian videos. Our model handles large motion effectively and synthesizes crisp frames with consistent motion.
Image Inpainting for Irregular Holes Using Partial Convolutions
Apr 20, 2018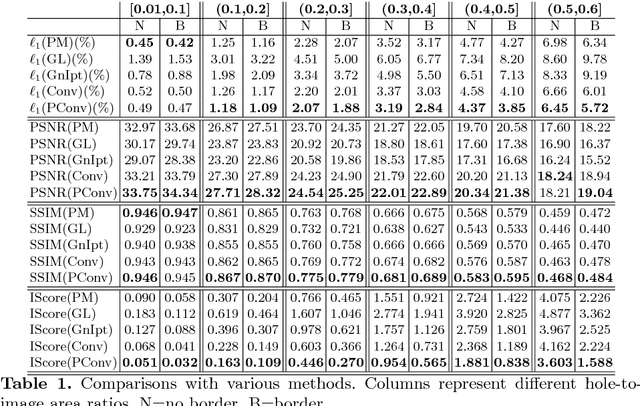

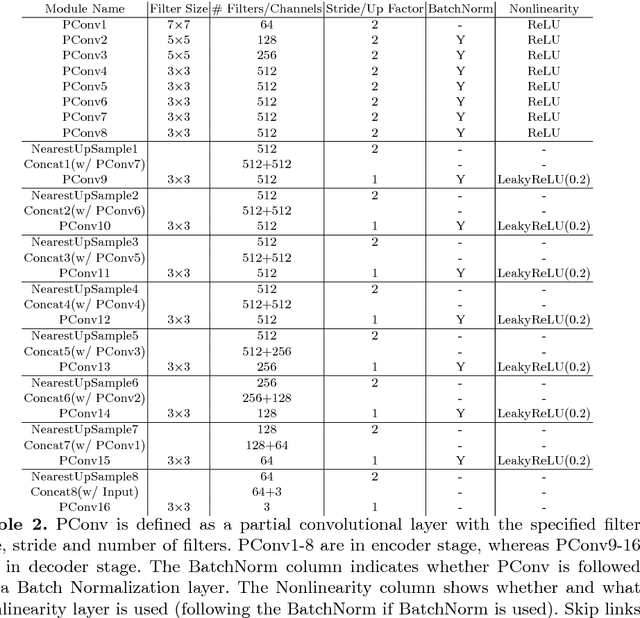

Existing deep learning based image inpainting methods use a standard convolutional network over the corrupted image, using convolutional filter responses conditioned on both valid pixels as well as the substitute values in the masked holes (typically the mean value). This often leads to artifacts such as color discrepancy and blurriness. Post-processing is usually used to reduce such artifacts, but are expensive and may fail. We propose the use of partial convolutions, where the convolution is masked and renormalized to be conditioned on only valid pixels. We further include a mechanism to automatically generate an updated mask for the next layer as part of the forward pass. Our model outperforms other methods for irregular masks. We show qualitative and quantitative comparisons with other methods to validate our approach.
Learning Interpretable Spatial Operations in a Rich 3D Blocks World
Dec 24, 2017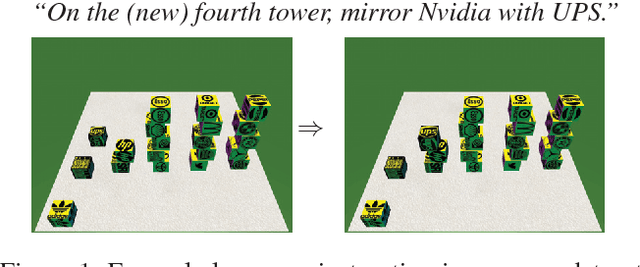
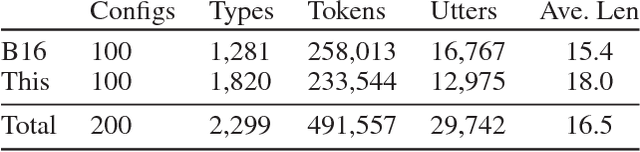


In this paper, we study the problem of mapping natural language instructions to complex spatial actions in a 3D blocks world. We first introduce a new dataset that pairs complex 3D spatial operations to rich natural language descriptions that require complex spatial and pragmatic interpretations such as "mirroring", "twisting", and "balancing". This dataset, built on the simulation environment of Bisk, Yuret, and Marcu (2016), attains language that is significantly richer and more complex, while also doubling the size of the original dataset in the 2D environment with 100 new world configurations and 250,000 tokens. In addition, we propose a new neural architecture that achieves competitive results while automatically discovering an inventory of interpretable spatial operations (Figure 5)
Where To Look: Focus Regions for Visual Question Answering
Jan 10, 2016


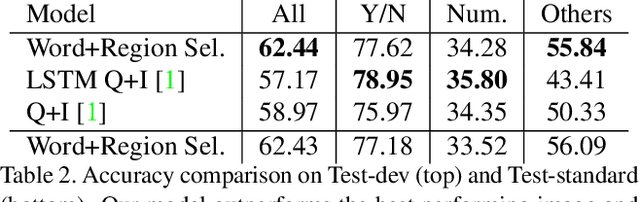
We present a method that learns to answer visual questions by selecting image regions relevant to the text-based query. Our method exhibits significant improvements in answering questions such as "what color," where it is necessary to evaluate a specific location, and "what room," where it selectively identifies informative image regions. Our model is tested on the VQA dataset which is the largest human-annotated visual question answering dataset to our knowledge.
Part Localization using Multi-Proposal Consensus for Fine-Grained Categorization
Jul 22, 2015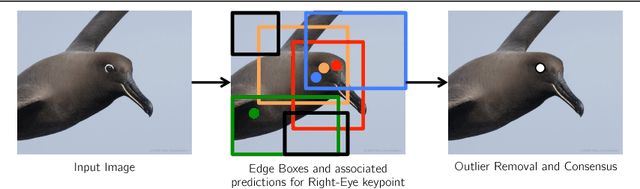
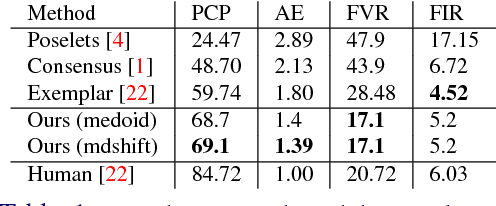

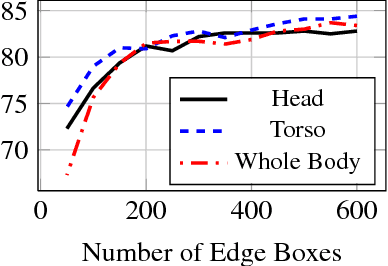
We present a simple deep learning framework to simultaneously predict keypoint locations and their respective visibilities and use those to achieve state-of-the-art performance for fine-grained classification. We show that by conditioning the predictions on object proposals with sufficient image support, our method can do well without complicated spatial reasoning. Instead, inference methods with robustness to outliers, yield state-of-the-art for keypoint localization. We demonstrate the effectiveness of our accurate keypoint localization and visibility prediction on the fine-grained bird recognition task with and without ground truth bird bounding boxes, and outperform existing state-of-the-art methods by over 2%.