 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Neural Networks for Novelty-based Test Selection to Accelerate Functional Coverage Closure
Jul 07, 2022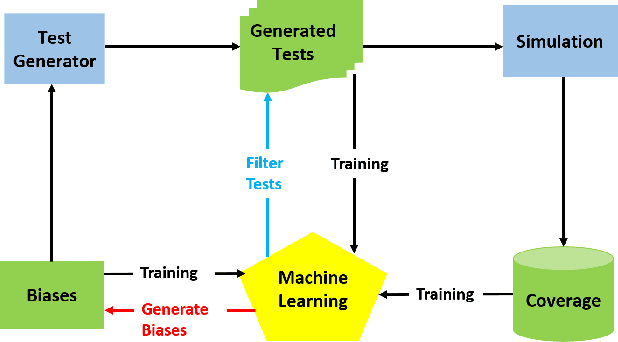
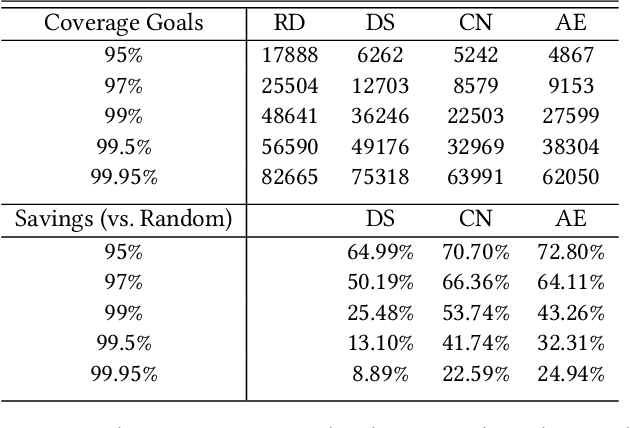
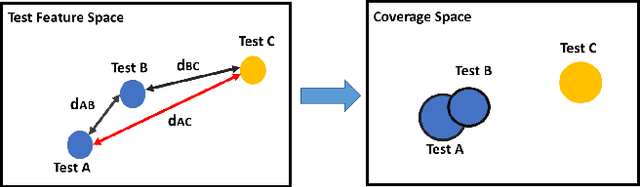
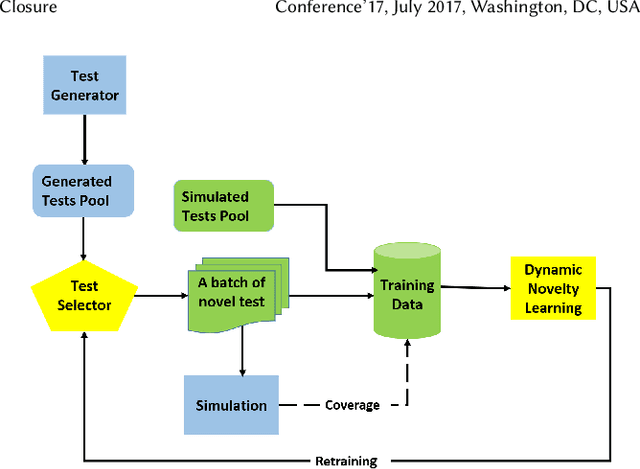
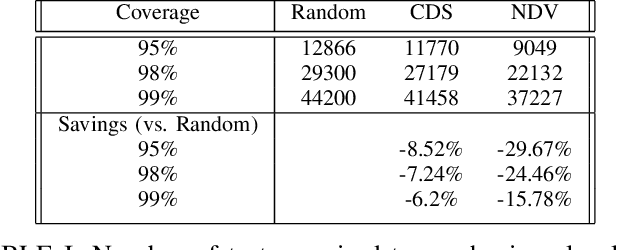
Machine learning (ML) has been used to accelerate the closure of functional coverage in simulation-based verification. A supervised ML algorithm, as a prevalent option in the previous work, is used to bias the test generation or filter the generated tests. However, for missing coverage events, these algorithms lack the positive examples to learn from in the training phase. Therefore, the tests generated or filtered by the algorithms cannot effectively fill the coverage holes. This is more severe when verifying large-scale design because the coverage space is larger and the functionalities are more complex. This paper presents a configurable framework of test selection based on neural networks (NN), which can achieve a similar coverage gain as random simulation with far less simulation effort under three configurations of the framework. Moreover, the performance of the framework is not limited by the number of coverage events being hit. A commercial signal processing unit is used in the experiment to demonstrate the effectiveness of the framework. Compared to the random simulation, the framework can reduce up to 53.74% of simulation time to reach 99% coverage level.
On Specifying for Trustworthiness
Jun 22, 2022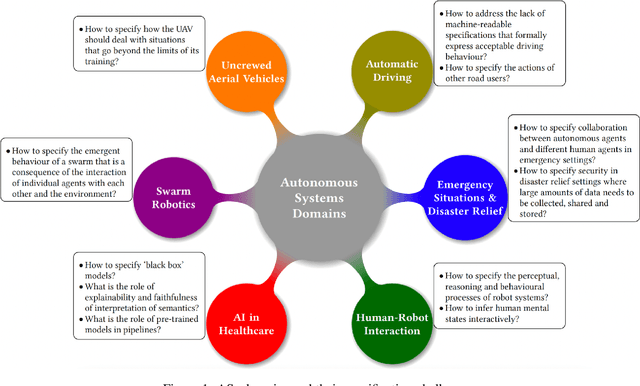
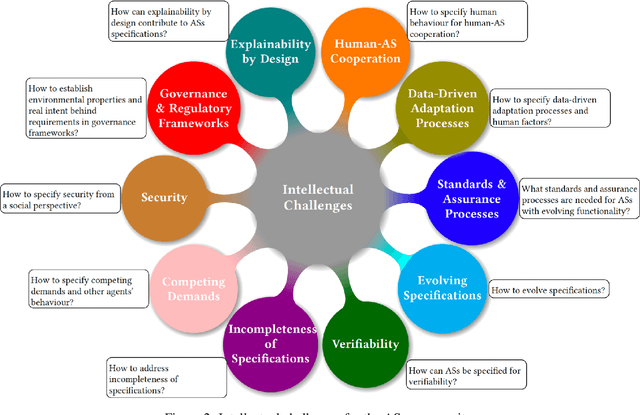
As autonomous systems are becoming part of our daily lives, ensuring their trustworthiness is crucial. There are a number of techniques for demonstrating trustworthiness. Common to all these techniques is the need to articulate specifications. In this paper, we take a broad view of specification, concentrating on top-level requirements including but not limited to functionality, safety, security and other non-functional properties. The main contribution of this article is a set of high-level intellectual challenges for the autonomous systems community related to specifying for trustworthiness. We also describe unique specification challenges concerning a number of application domains for autonomous systems.
Hybrid Intelligent Testing in Simulation-Based Verification
May 19, 2022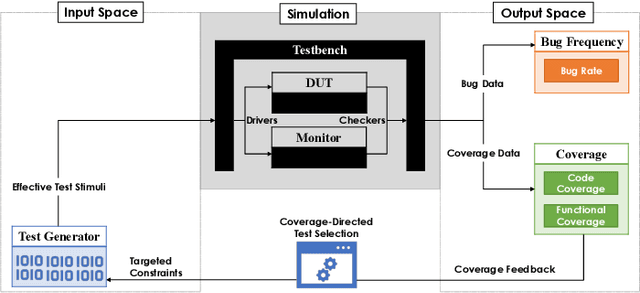
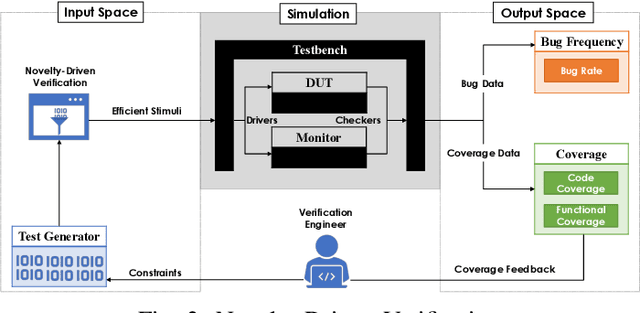
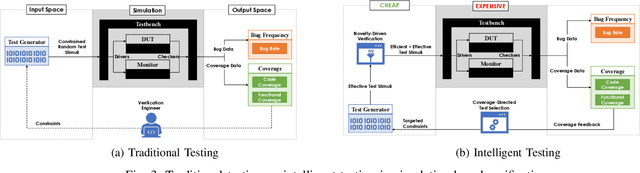
Efficient and effective testing for simulation-based hardware verification is challenging. Using constrained random test generation, several millions of tests may be required to achieve coverage goals. The vast majority of tests do not contribute to coverage progress, yet they consume verification resources. In this paper, we propose a hybrid intelligent testing approach combining two methods that have previously been treated separately, namely Coverage-Directed Test Selection and Novelty-Driven Verification. Coverage-Directed Test Selection learns from coverage feedback to bias testing towards the most effective tests. Novelty-Driven Verification learns to identify and simulate stimuli that differ from previous stimuli, thereby reducing the number of simulations and increasing testing efficiency. We discuss the strengths and limitations of each method, and we show how our approach addresses each method's limitations, leading to hardware testing that is both efficient and effective.
Supervised Learning for Coverage-Directed Test Selection in Simulation-Based Verification
May 17, 2022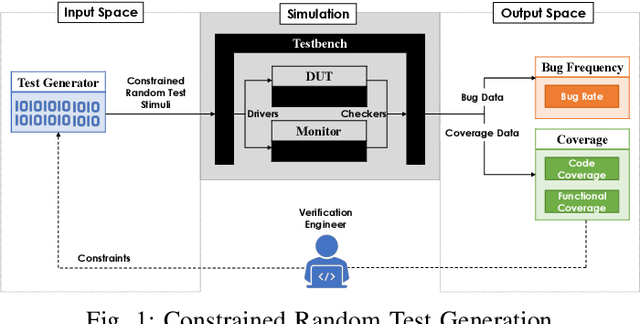

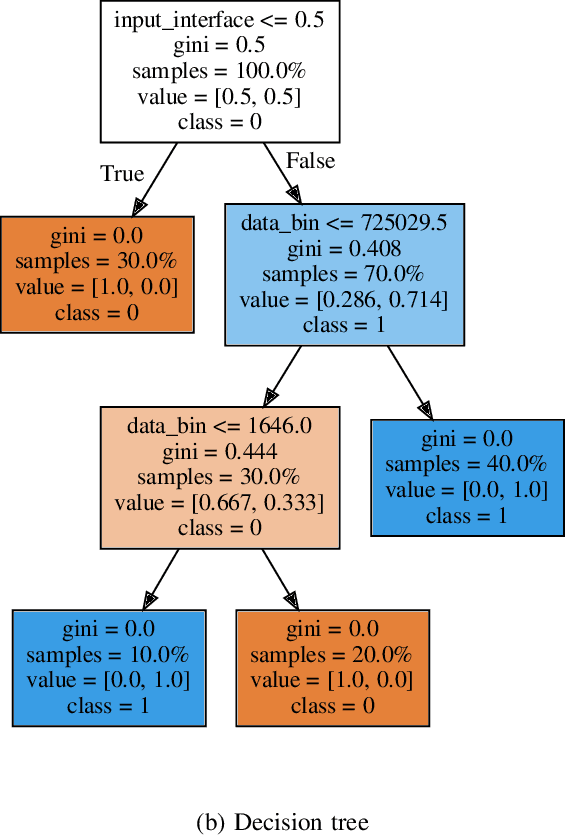
Constrained random test generation is one the most widely adopted methods for generating stimuli for simulation-based verification. Randomness leads to test diversity, but tests tend to repeatedly exercise the same design logic. Constraints are written (typically manually) to bias random tests towards interesting, hard-to-reach, and yet-untested logic. However, as verification progresses, most constrained random tests yield little to no effect on functional coverage. If stimuli generation consumes significantly less resources than simulation, then a better approach involves randomly generating a large number tests, selecting the most effective subset, and only simulating that subset. In this paper, we introduce a novel method for automatic constraint extraction and test selection. This method, which we call coverage-directed test selection, is based on supervised learning from coverage feedback. Our method biases selection towards tests that have a high probability of increasing functional coverage, and prioritises them for simulation. We show how coverage-directed test selection can reduce manual constraint writing, prioritise effective tests, reduce verification resource consumption, and accelerate coverage closure on a large, real-life industrial hardware design.
Operational Adaptation of DNN Classifiers using Elastic Weight Consolidation
Apr 30, 2022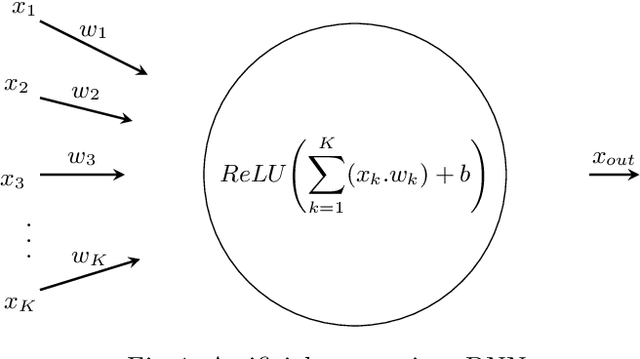
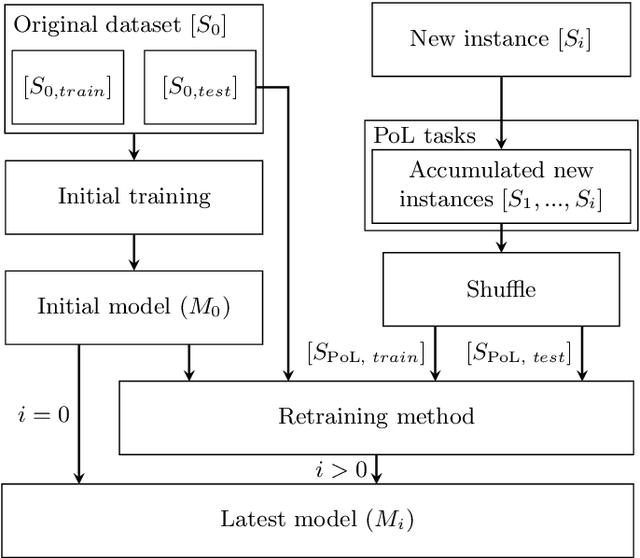
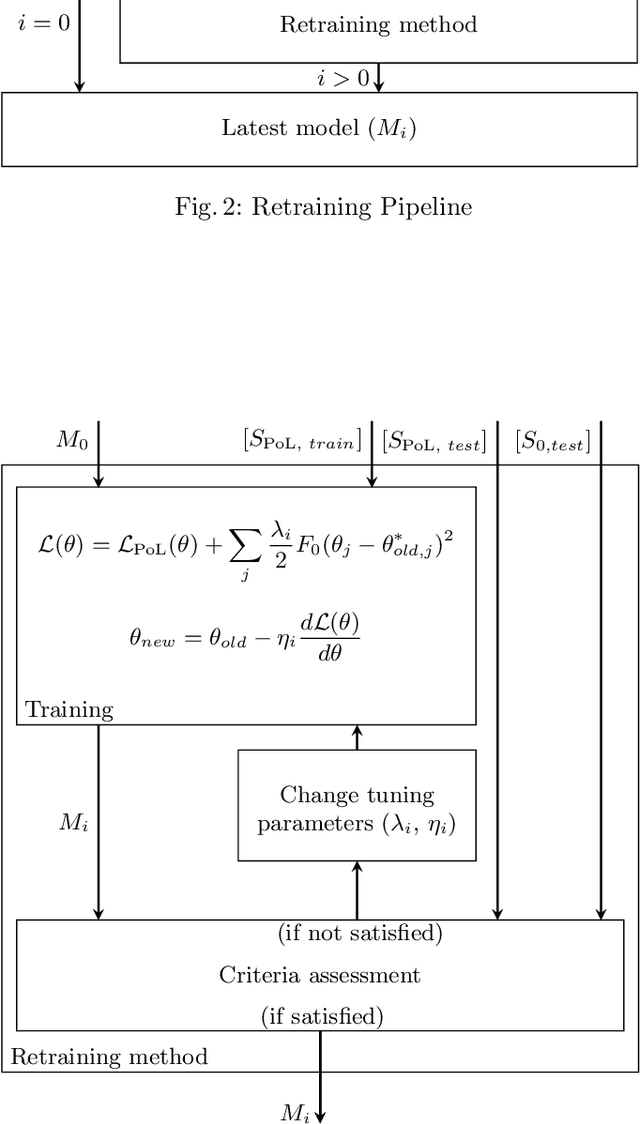
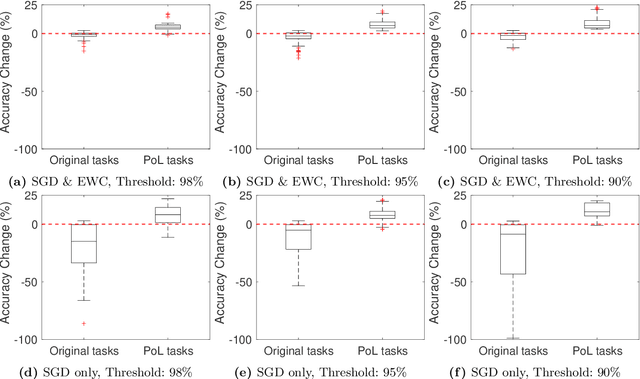
Autonomous systems (AS) often use Deep Neural Network (DNN) classifiers to allow them to operate in complex, high dimensional, non-linear, and dynamically changing environments. Due to the complexity of these environments, DNN classifiers may output misclassifications due to experiencing new tasks in their operational environments, which were not identified during development. Removing a system from operation and retraining it to include the new identified task becomes economically infeasible as the number of such autonomous systems increase. Additionally, such misclassifications may cause financial losses and safety threats to the AS or to other operators in its environment. In this paper, we propose to reduce such threats by investigating if DNN classifiers can adapt its knowledge to learn new information in the AS's operational environment, using only a limited number of observations encountered sequentially during operation. This allows the AS to adapt to new encountered information and hence increases the AS's reliability on doing correct classifications. However, retraining DNNs on different observations than used in prior training is known to cause catastrophic forgetting or significant model drift. We investigate if this problem can be controlled by using Elastic Weight Consolidation (EWC) whilst learning from limited new observations. We carry out experiments using original and noisy versions of the MNIST dataset to represent known and new information to DNN classifiers. Results show that using EWC does make the process of adaptation to new information a lot more controlled, and thus allowing for reliable adaption of ASs to new information in their operational environment.
D-VAL: An automatic functional equivalence validation tool for planning domain models
Apr 29, 2021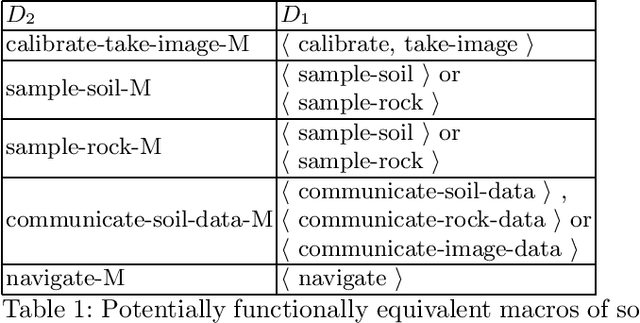
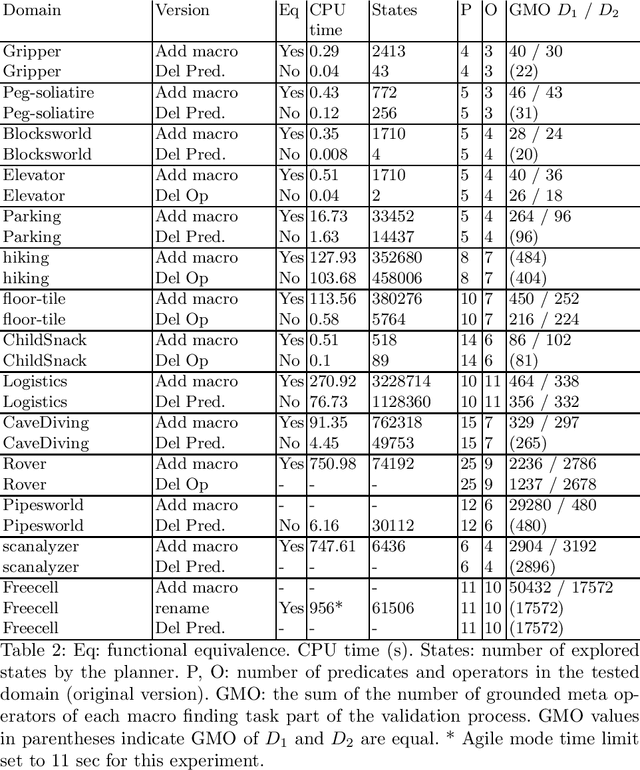
In this paper, we introduce an approach to validate the functional equivalence of planning domain models. Validating the functional equivalence of planning domain models is the problem of formally confirming that two planning domain models can be used to solve the same set of problems. The need for techniques to validate the functional equivalence of planning domain models has been highlighted in previous research and has applications in model learning, development and extension. We prove the soundness and completeness of our method. We also develop D-VAL, an automatic functional equivalence validation tool for planning domain models. Empirical evaluation shows that D-VAL validates the functional equivalence of most examined domains in less than five minutes. Additionally, we provide a benchmark to evaluate the feasibility and scalability of this and future related work.
On Determinism of Game Engines used for Simulation-based Autonomous Vehicle Verification
Apr 29, 2021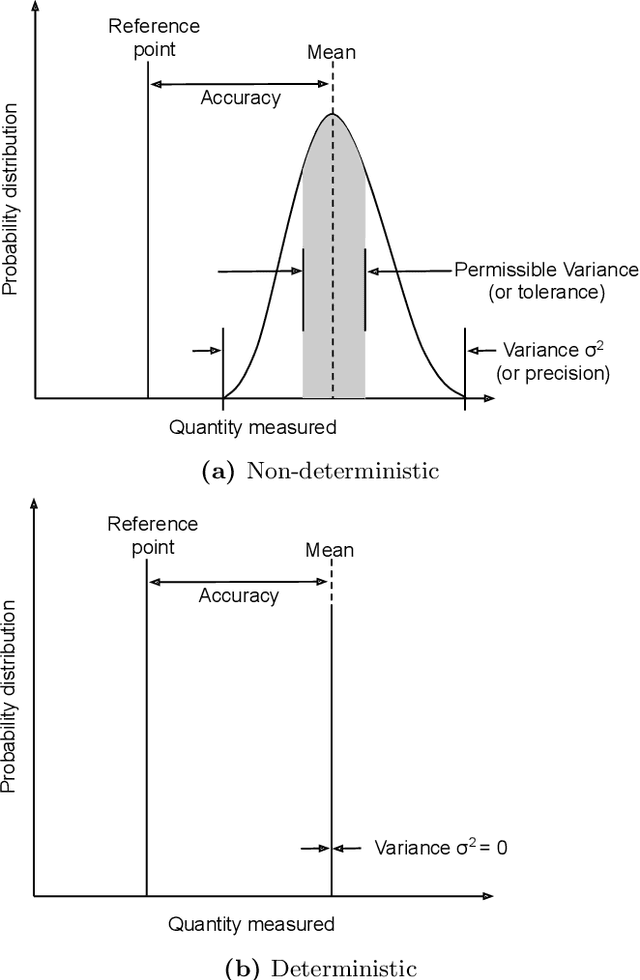


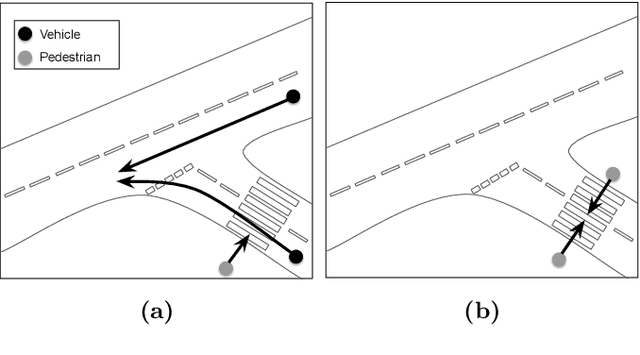
Game engines are increasingly used as simulation platforms by the autonomous vehicle (AV) community to develop vehicle control systems and test environments. A key requirement for simulation-based development and verification is determinism, since a deterministic process will always produce the same output given the same initial conditions and event history. Thus, in a deterministic simulation environment, tests are rendered repeatable and yield simulation results that are trustworthy and straightforward to debug. However, game engines are seldom deterministic. This paper reviews and identifies the potential causes of non-deterministic behaviours in game engines. A case study using CARLA, an open-source autonomous driving simulation environment powered by Unreal Engine, is presented to highlight its inherent shortcomings in providing sufficient precision in experimental results. Different configurations and utilisations of the software and hardware are explored to determine an operational domain where the simulation precision is sufficiently low i.e.\ variance between repeated executions becomes negligible for development and testing work. Finally, a method of a general nature is proposed, that can be used to find the domains of permissible variance in game engine simulations for any given system configuration.
CyRes -- Avoiding Catastrophic Failure in Connected and Autonomous Vehicles (Extended Abstract)
Jul 03, 2020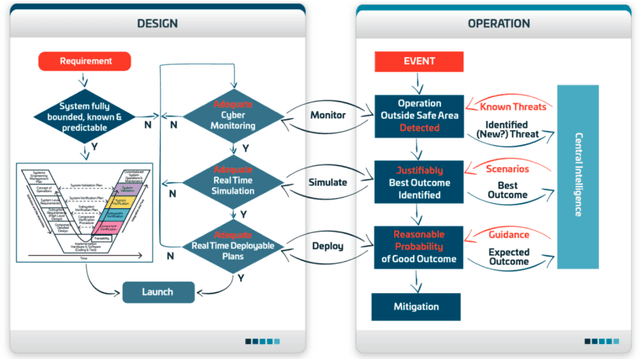
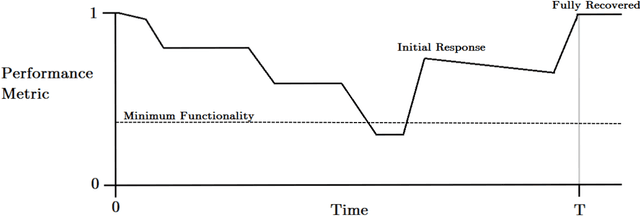
Existing approaches to cyber security and regulation in the automotive sector cannot achieve the quality of outcome necessary to ensure the safe mass deployment of advanced vehicle technologies and smart mobility systems. Without sustainable resilience hard-fought public trust will evaporate, derailing emerging global initiatives to improve the efficiency, safety and environmental impact of future transport. This paper introduces an operational cyber resilience methodology, CyRes, that is suitable for standardisation. The CyRes methodology itself is capable of being tested in court or by publicly appointed regulators. It is designed so that operators understand what evidence should be produced by it and are able to measure the quality of that evidence. The evidence produced is capable of being tested in court or by publicly appointed regulators. Thus, the real-world system to which the CyRes methodology has been applied is capable of operating at all times and in all places with a legally and socially acceptable value of negative consequence.
Formalizing and Guaranteeing* Human-Robot Interaction
Jun 30, 2020
Robot capabilities are maturing across domains, from self-driving cars, to bipeds and drones. As a result, robots will soon no longer be confined to safety-controlled industrial settings; instead, they will directly interact with the general public. The growing field of Human-Robot Interaction (HRI) studies various aspects of this scenario - from social norms to joint action to human-robot teams and more. Researchers in HRI have made great strides in developing models, methods, and algorithms for robots acting with and around humans, but these "computational HRI" models and algorithms generally do not come with formal guarantees and constraints on their operation. To enable human-interactive robots to move from the lab to real-world deployments, we must address this gap. This article provides an overview of verification, validation and synthesis techniques used to create demonstrably trustworthy systems, describes several HRI domains that could benefit from such techniques, and provides a roadmap for the challenges and the research needed to create formalized and guaranteed human-robot interaction.
Verification of Planning Domain Models - Revisited
Nov 22, 2018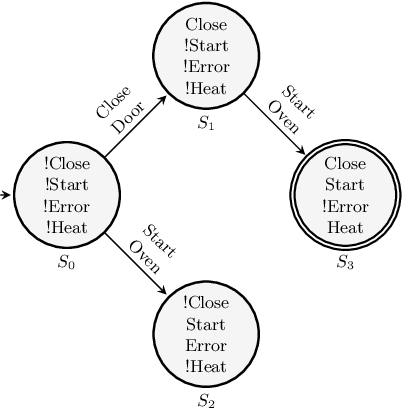
The verification of planning domain models is crucial to ensure the safety, integrity and correctness of planning-based automated systems. This task is usually performed using model checking techniques. However, directly applying model checkers to verify planning domain models can result in false positives, i.e. counterexamples that are unreachable by a sound planner when using the domain under verification during a planning task. In this paper, we discuss the downside of unconstrained planning domain model verification. We then propose a fail-safe practice for designing planning domain models that can inherently guarantee the safety of the produced plans in case of undetected errors in domain models. In addition, we demonstrate how model checkers, as well as state trajectory constraints planning techniques, should be used to verify planning domain models so that unreachable counterexamples are not returned.