 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Evolving Attention Towards Domain Adaptation
Mar 25, 2021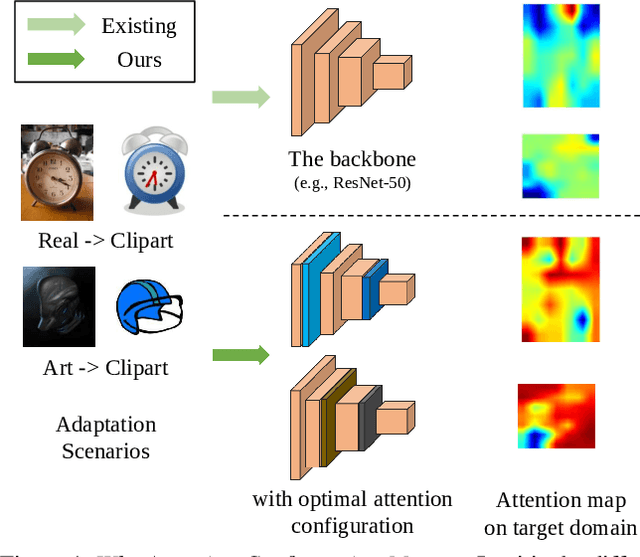
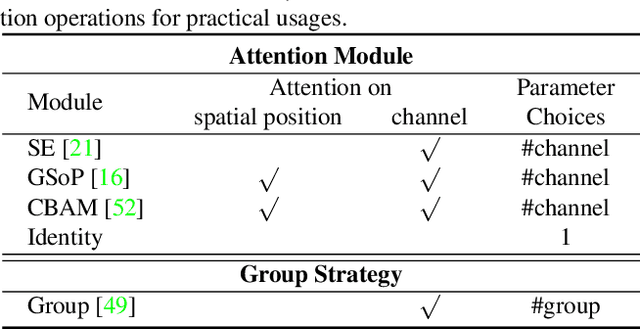
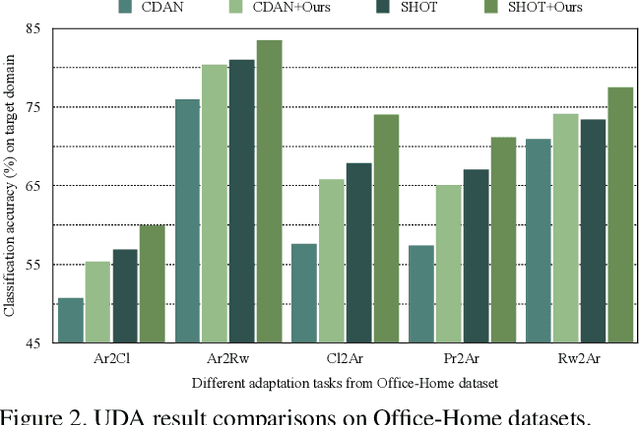
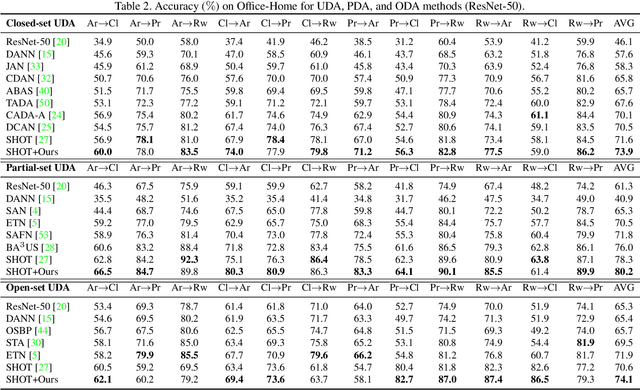
Towards better unsupervised domain adaptation (UDA). Recently, researchers propose various domain-conditioned attention modules and make promising progresses. However, considering that the configuration of attention, i.e., the type and the position of attention module, affects the performance significantly, it is more generalized to optimize the attention configuration automatically to be specialized for arbitrary UDA scenario. For the first time, this paper proposes EvoADA: a novel framework to evolve the attention configuration for a given UDA task without human intervention. In particular, we propose a novel search space containing diverse attention configurations. Then, to evaluate the attention configurations and make search procedure UDA-oriented (transferability + discrimination), we apply a simple and effective evaluation strategy: 1) training the network weights on two domains with off-the-shelf domain adaptation methods; 2) evolving the attention configurations under the guide of the discriminative ability on the target domain. Experiments on various kinds of cross-domain benchmarks, i.e., Office-31, Office-Home, CUB-Paintings, and Duke-Market-1510, reveal that the proposed EvoADA consistently boosts multiple state-of-the-art domain adaptation approaches, and the optimal attention configurations help them achieve better performance.
Effective Label Propagation for Discriminative Semi-Supervised Domain Adaptation
Dec 04, 2020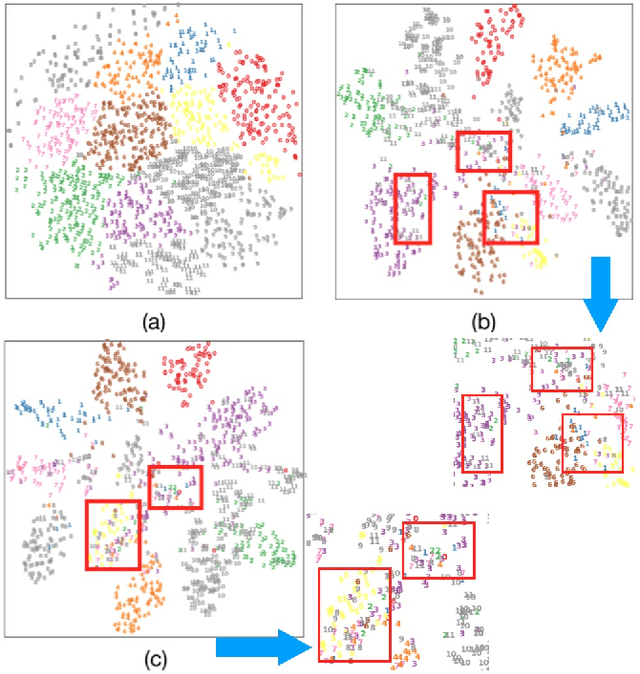
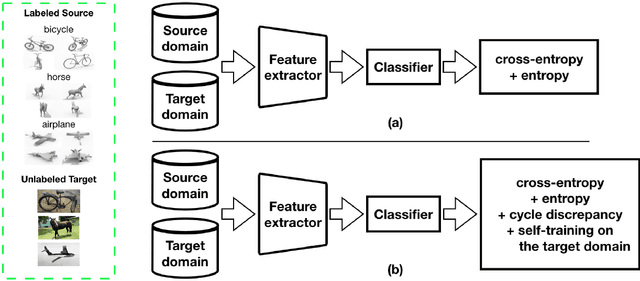
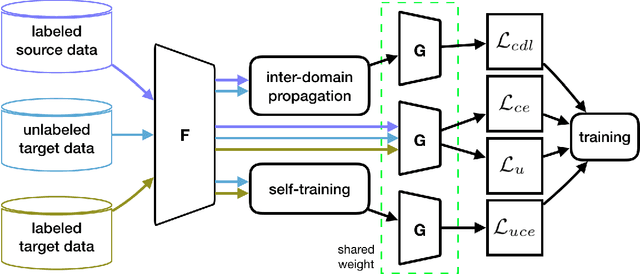
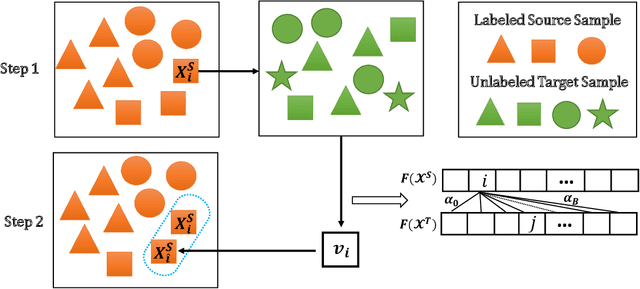
Semi-supervised domain adaptation (SSDA) methods have demonstrated great potential in large-scale image classification tasks when massive labeled data are available in the source domain but very few labeled samples are provided in the target domain. Existing solutions usually focus on feature alignment between the two domains while paying little attention to the discrimination capability of learned representations in the target domain. In this paper, we present a novel and effective method, namely Effective Label Propagation (ELP), to tackle this problem by using effective inter-domain and intra-domain semantic information propagation. For inter-domain propagation, we propose a new cycle discrepancy loss to encourage consistency of semantic information between the two domains. For intra-domain propagation, we propose an effective self-training strategy to mitigate the noises in pseudo-labeled target domain data and improve the feature discriminability in the target domain. As a general method, our ELP can be easily applied to various domain adaptation approaches and can facilitate their feature discrimination in the target domain. Experiments on Office-Home and DomainNet benchmarks show ELP consistently improves the classification accuracy of mainstream SSDA methods by 2%~3%. Additionally, ELP also improves the performance of UDA methods as well (81.5% vs 86.1%), based on UDA experiments on the VisDA-2017 benchmark. Our source code and pre-trained models will be released soon.
Dynamic Refinement Network for Oriented and Densely Packed Object Detection
Jun 10, 2020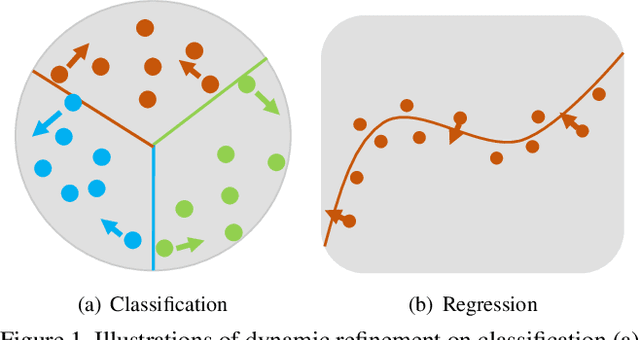
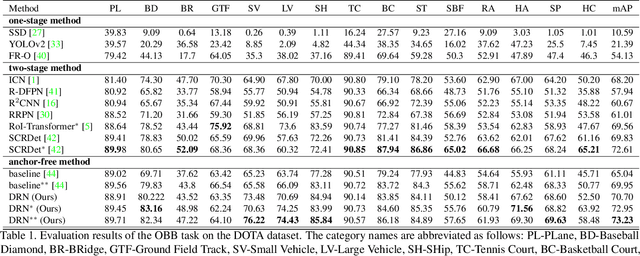
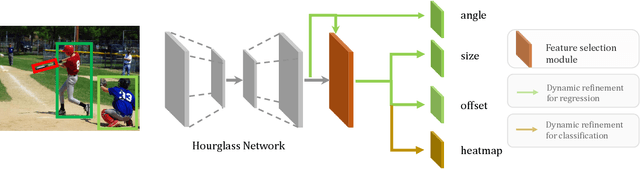

Object detection has achieved remarkable progress in the past decade. However, the detection of oriented and densely packed objects remains challenging because of following inherent reasons: (1) receptive fields of neurons are all axis-aligned and of the same shape, whereas objects are usually of diverse shapes and align along various directions; (2) detection models are typically trained with generic knowledge and may not generalize well to handle specific objects at test time; (3) the limited dataset hinders the development on this task. To resolve the first two issues, we present a dynamic refinement network that consists of two novel components, i.e., a feature selection module (FSM) and a dynamic refinement head (DRH). Our FSM enables neurons to adjust receptive fields in accordance with the shapes and orientations of target objects, whereas the DRH empowers our model to refine the prediction dynamically in an object-aware manner. To address the limited availability of related benchmarks, we collect an extensive and fully annotated dataset, namely, SKU110K-R, which is relabeled with oriented bounding boxes based on SKU110K. We perform quantitative evaluations on several publicly available benchmarks including DOTA, HRSC2016, SKU110K, and our own SKU110K-R dataset. Experimental results show that our method achieves consistent and substantial gains compared with baseline approaches. The code and dataset are available at https://github.com/Anymake/DRN_CVPR2020.
Revisiting Image Aesthetic Assessment via Self-Supervised Feature Learning
Nov 26, 2019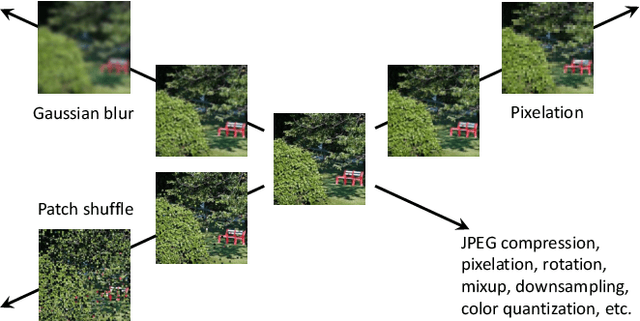
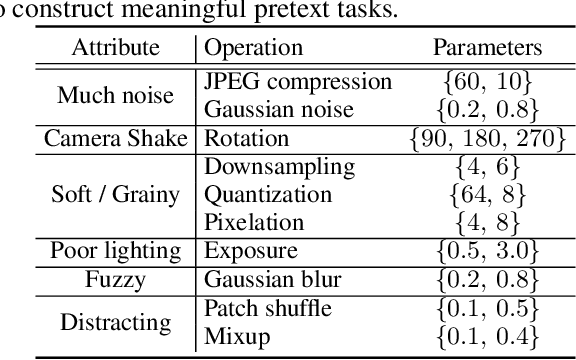

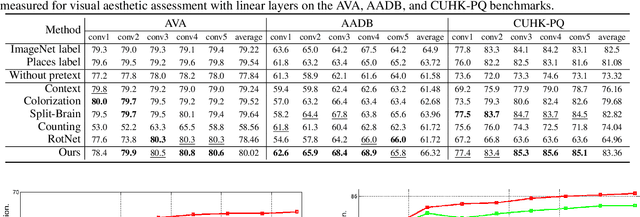
Visual aesthetic assessment has been an active research field for decades. Although latest methods have achieved promising performance on benchmark datasets, they typically rely on a large number of manual annotations including both aesthetic labels and related image attributes. In this paper, we revisit the problem of image aesthetic assessment from the self-supervised feature learning perspective. Our motivation is that a suitable feature representation for image aesthetic assessment should be able to distinguish different expert-designed image manipulations, which have close relationships with negative aesthetic effects. To this end, we design two novel pretext tasks to identify the types and parameters of editing operations applied to synthetic instances. The features from our pretext tasks are then adapted for a one-layer linear classifier to evaluate the performance in terms of binary aesthetic classification. We conduct extensive quantitative experiments on three benchmark datasets and demonstrate that our approach can faithfully extract aesthetics-aware features and outperform alternative pretext schemes. Moreover, we achieve comparable results to state-of-the-art supervised methods that use 10 million labels from ImageNet.