 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding a Large Japanese Web Corpus for Large Language Models
Apr 27, 2024


Open Japanese large language models (LLMs) have been trained on the Japanese portions of corpora such as CC-100, mC4, and OSCAR. However, these corpora were not created for the quality of Japanese texts. This study builds a large Japanese web corpus by extracting and refining text from the Common Crawl archive (21 snapshots of approximately 63.4 billion pages crawled between 2020 and 2023). This corpus consists of approximately 312.1 billion characters (approximately 173 million pages), which is the largest of all available training corpora for Japanese LLMs, surpassing CC-100 (approximately 25.8 billion characters), mC4 (approximately 239.7 billion characters) and OSCAR 23.10 (approximately 74 billion characters). To confirm the quality of the corpus, we performed continual pre-training on Llama 2 7B, 13B, 70B, Mistral 7B v0.1, and Mixtral 8x7B Instruct as base LLMs and gained consistent (6.6-8.1 points) improvements on Japanese benchmark datasets. We also demonstrate that the improvement on Llama 2 13B brought from the presented corpus was the largest among those from other existing corpora.
Continual Pre-Training for Cross-Lingual LLM Adaptation: Enhancing Japanese Language Capabilities
Apr 27, 2024



Cross-lingual continual pre-training of large language models (LLMs) initially trained on English corpus allows us to leverage the vast amount of English language resources and reduce the pre-training cost. In this study, we constructed Swallow, an LLM with enhanced Japanese capability, by extending the vocabulary of Llama 2 to include Japanese characters and conducting continual pre-training on a large Japanese web corpus. Experimental results confirmed that the performance on Japanese tasks drastically improved through continual pre-training, and the performance monotonically increased with the amount of training data up to 100B tokens. Consequently, Swallow achieved superior performance compared to other LLMs that were trained from scratch in English and Japanese. An analysis of the effects of continual pre-training revealed that it was particularly effective for Japanese question answering tasks. Furthermore, to elucidate effective methodologies for cross-lingual continual pre-training from English to Japanese, we investigated the impact of vocabulary expansion and the effectiveness of incorporating parallel corpora. The results showed that the efficiency gained through vocabulary expansion had no negative impact on performance, except for the summarization task, and that the combined use of parallel corpora enhanced translation ability.
Likelihood-based Mitigation of Evaluation Bias in Large Language Models
Mar 01, 2024



Large Language Models (LLMs) are widely used to evaluate natural language generation tasks as automated metrics. However, the likelihood, a measure of LLM's plausibility for a sentence, can vary due to superficial differences in sentences, such as word order and sentence structure. It is therefore possible that there might be a likelihood bias if LLMs are used for evaluation: they might overrate sentences with higher likelihoods while underrating those with lower likelihoods. In this paper, we investigate the presence and impact of likelihood bias in LLM-based evaluators. We also propose a method to mitigate the likelihood bias. Our method utilizes highly biased instances as few-shot examples for in-context learning. Our experiments in evaluating the data-to-text and grammatical error correction tasks reveal that several LLMs we test display a likelihood bias. Furthermore, our proposed method successfully mitigates this bias, also improving evaluation performance (in terms of correlation of models with human scores) significantly.
SAIE Framework: Support Alone Isn't Enough -- Advancing LLM Training with Adversarial Remarks
Nov 14, 2023



Large Language Models (LLMs) can justify or criticize their predictions through discussion with other models or humans, thereby enhancing their intrinsic understanding of instances. While proactive discussions enhance performance, this approach is currently limited to the inference phase. In this context, we posit a hypothesis: learning interactive discussions during training can improve understanding for the instances in the training step and proficiency in logical/critical thinking ability and verbalized expression of the model in the inference step. Our proposed SAIE training method involves both supportive and adversarial discussions between the learner and partner models. The learner model receives a remark from the partner through the discussion, and the parameters of the learner model are then updated based on this remark. That is, the teacher signal dynamically adjusts in response to the evolving model output throughout the training step. By bolstering the capacity for discussion and comprehension of instances, our experiments across datasets, including GSM8K, CommonsenseQA, and MMLU, reveal that models fine-tuned with our method consistently surpass those trained with standard fine-tuning techniques. Moreover, our approach demonstrates superior performance in multi-agent inference scenarios, boosting the models' reasoning abilities at the inference step.
Exploring Effectiveness of GPT-3 in Grammatical Error Correction: A Study on Performance and Controllability in Prompt-Based Methods
May 29, 2023



Large-scale pre-trained language models such as GPT-3 have shown remarkable performance across various natural language processing tasks. However, applying prompt-based methods with GPT-3 for Grammatical Error Correction (GEC) tasks and their controllability remains underexplored. Controllability in GEC is crucial for real-world applications, particularly in educational settings, where the ability to tailor feedback according to learner levels and specific error types can significantly enhance the learning process. This paper investigates the performance and controllability of prompt-based methods with GPT-3 for GEC tasks using zero-shot and few-shot setting. We explore the impact of task instructions and examples on GPT-3's output, focusing on controlling aspects such as minimal edits, fluency edits, and learner levels. Our findings demonstrate that GPT-3 could effectively perform GEC tasks, outperforming existing supervised and unsupervised approaches. We also showed that GPT-3 could achieve controllability when appropriate task instructions and examples are given.
Are Neighbors Enough? Multi-Head Neural n-gram can be Alternative to Self-attention
Jul 27, 2022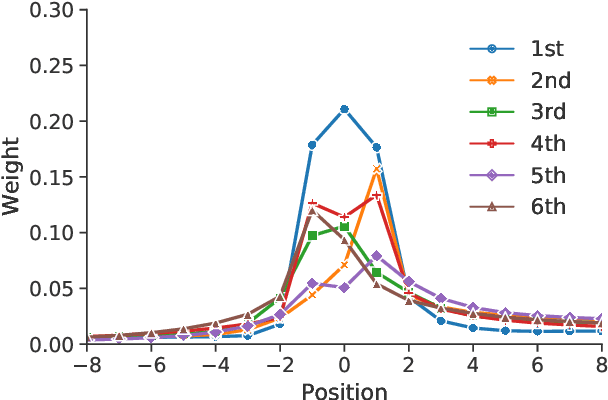
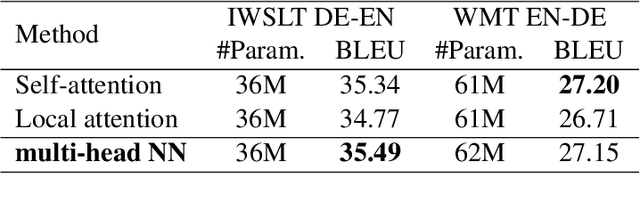
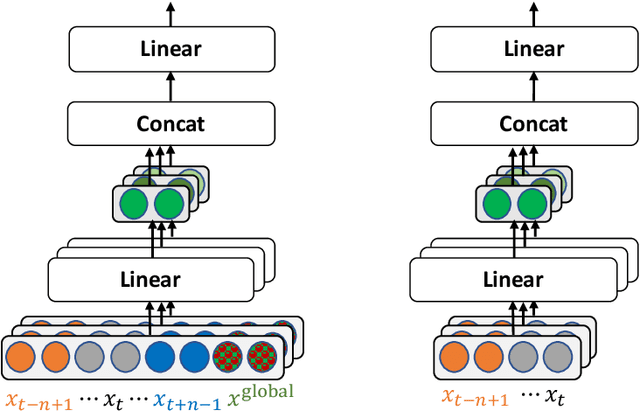
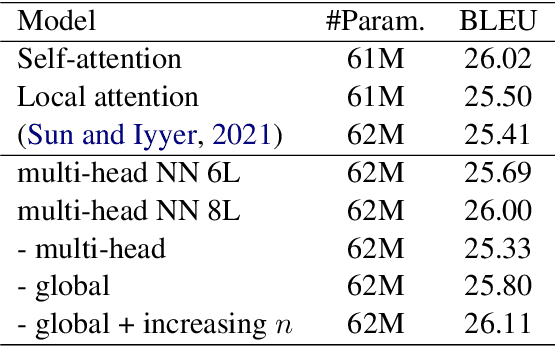
Impressive performance of Transformer has been attributed to self-attention, where dependencies between entire input in a sequence are considered at every position. In this work, we reform the neural $n$-gram model, which focuses on only several surrounding representations of each position, with the multi-head mechanism as in Vaswani et al.(2017). Through experiments on sequence-to-sequence tasks, we show that replacing self-attention in Transformer with multi-head neural $n$-gram can achieve comparable or better performance than Transformer. From various analyses on our proposed method, we find that multi-head neural $n$-gram is complementary to self-attention, and their combinations can further improve performance of vanilla Transformer.
ExtraPhrase: Efficient Data Augmentation for Abstractive Summarization
Jan 14, 2022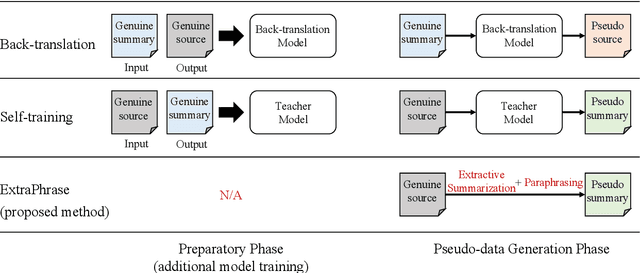
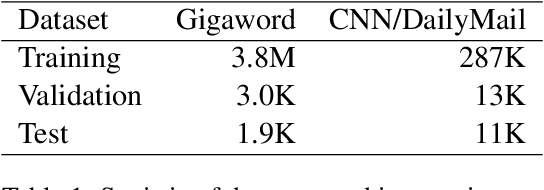
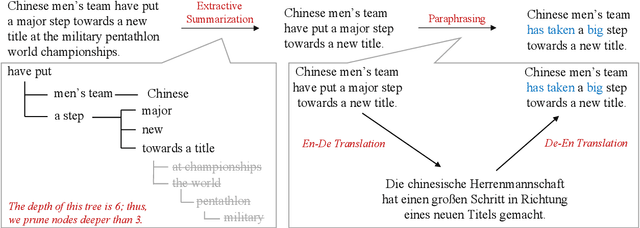
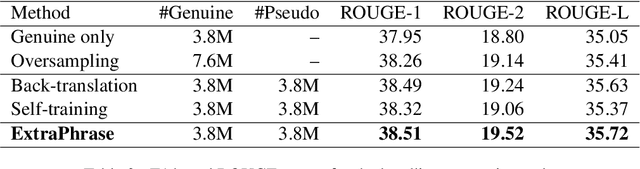
Neural models trained with large amount of parallel data have achieved impressive performance in abstractive summarization tasks. However, large-scale parallel corpora are expensive and challenging to construct. In this work, we introduce a low-cost and effective strategy, ExtraPhrase, to augment training data for abstractive summarization tasks. ExtraPhrase constructs pseudo training data in two steps: extractive summarization and paraphrasing. We extract major parts of an input text in the extractive summarization step, and obtain its diverse expressions with the paraphrasing step. Through experiments, we show that ExtraPhrase improves the performance of abstractive summarization tasks by more than 0.50 points in ROUGE scores compared to the setting without data augmentation. ExtraPhrase also outperforms existing methods such as back-translation and self-training. We also show that ExtraPhrase is significantly effective when the amount of genuine training data is remarkably small, i.e., a low-resource setting. Moreover, ExtraPhrase is more cost-efficient than the existing approaches.