 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFBNetV2: Differentiable Neural Architecture Search for Spatial and Channel Dimensions
Apr 12, 2020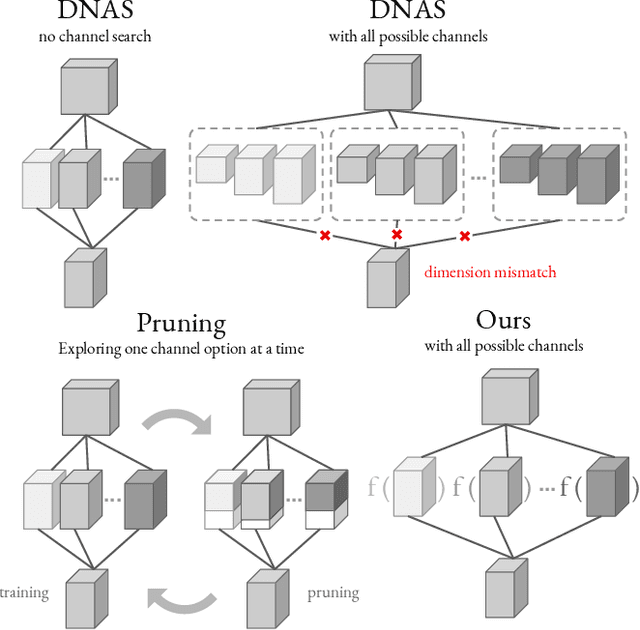
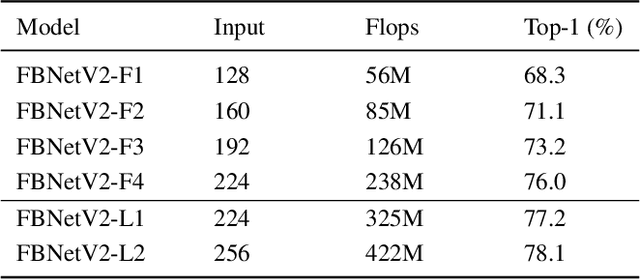
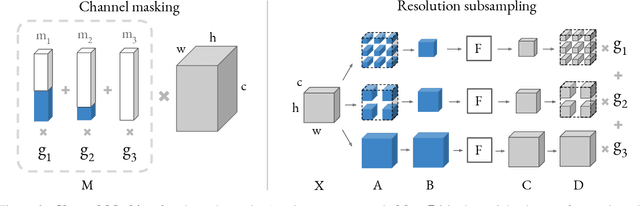
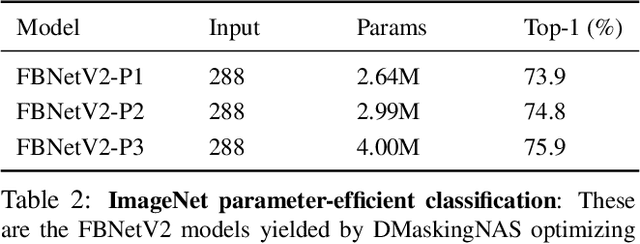
Differentiable Neural Architecture Search (DNAS) has demonstrated great success in designing state-of-the-art, efficient neural networks. However, DARTS-based DNAS's search space is small when compared to other search methods', since all candidate network layers must be explicitly instantiated in memory. To address this bottleneck, we propose a memory and computationally efficient DNAS variant: DMaskingNAS. This algorithm expands the search space by up to $10^{14}\times$ over conventional DNAS, supporting searches over spatial and channel dimensions that are otherwise prohibitively expensive: input resolution and number of filters. We propose a masking mechanism for feature map reuse, so that memory and computational costs stay nearly constant as the search space expands. Furthermore, we employ effective shape propagation to maximize per-FLOP or per-parameter accuracy. The searched FBNetV2s yield state-of-the-art performance when compared with all previous architectures. With up to 421$\times$ less search cost, DMaskingNAS finds models with 0.9% higher accuracy, 15% fewer FLOPs than MobileNetV3-Small; and with similar accuracy but 20% fewer FLOPs than Efficient-B0. Furthermore, our FBNetV2 outperforms MobileNetV3 by 2.6% in accuracy, with equivalent model size. FBNetV2 models are open-sourced at https://github.com/facebookresearch/mobile-vision.
Video Object Grounding using Semantic Roles in Language Description
Mar 24, 2020
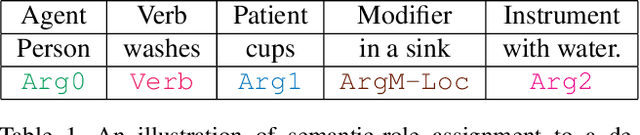


We explore the task of Video Object Grounding (VOG), which grounds objects in videos referred to in natural language descriptions. Previous methods apply image grounding based algorithms to address VOG, fail to explore the object relation information and suffer from limited generalization. Here, we investigate the role of object relations in VOG and propose a novel framework VOGNet to encode multi-modal object relations via self-attention with relative position encoding. To evaluate VOGNet, we propose novel contrasting sampling methods to generate more challenging grounding input samples, and construct a new dataset called ActivityNet-SRL (ASRL) based on existing caption and grounding datasets. Experiments on ASRL validate the need of encoding object relations in VOG, and our VOGNet outperforms competitive baselines by a significant margin.
Zero-Shot Grounding of Objects from Natural Language Queries
Aug 20, 2019
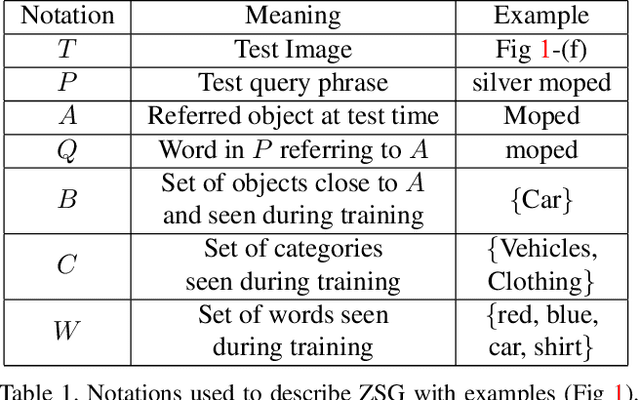
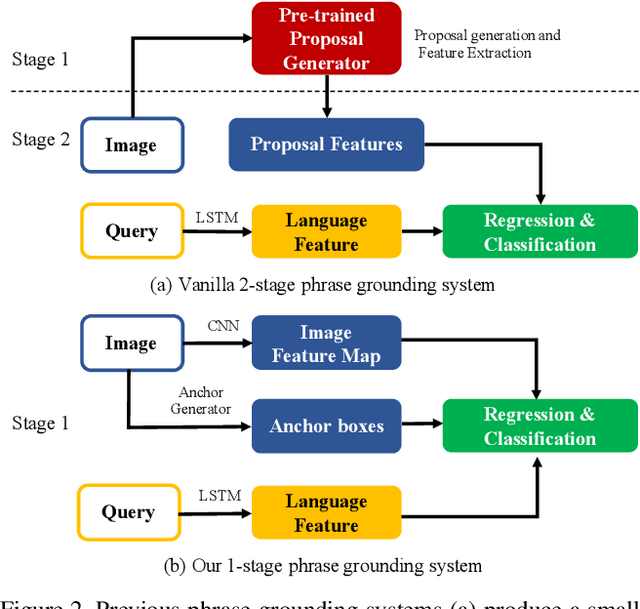
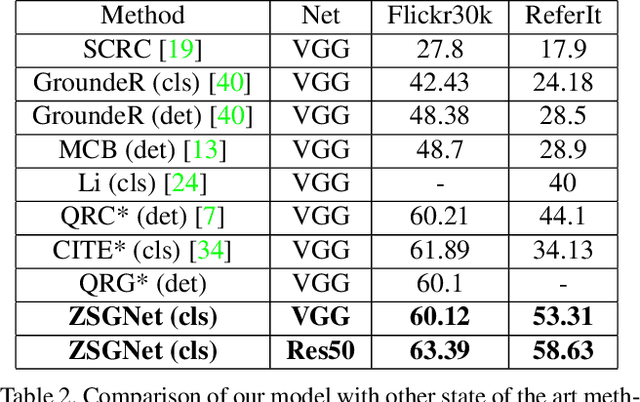
A phrase grounding system localizes a particular object in an image referred to by a natural language query. In previous work, the phrases were restricted to have nouns that were encountered in training, we extend the task to Zero-Shot Grounding(ZSG) which can include novel, "unseen" nouns. Current phrase grounding systems use an explicit object detection network in a 2-stage framework where one stage generates sparse proposals and the other stage evaluates them. In the ZSG setting, generating appropriate proposals itself becomes an obstacle as the proposal generator is trained on the entities common in the detection and grounding datasets. We propose a new single-stage model called ZSGNet which combines the detector network and the grounding system and predicts classification scores and regression parameters. Evaluation of ZSG system brings additional subtleties due to the influence of the relationship between the query and learned categories; we define four distinct conditions that incorporate different levels of difficulty. We also introduce new datasets, sub-sampled from Flickr30k Entities and Visual Genome, that enable evaluations for the four conditions. Our experiments show that ZSGNet achieves state-of-the-art performance on Flickr30k and ReferIt under the usual "seen" settings and performs significantly better than baseline in the zero-shot setting.
Cascaded Parallel Filtering for Memory-Efficient Image-Based Localization
Aug 16, 2019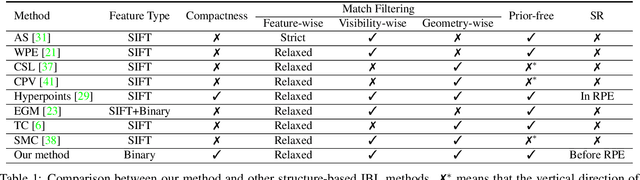
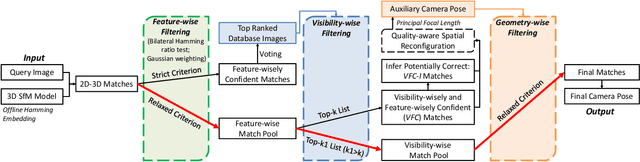
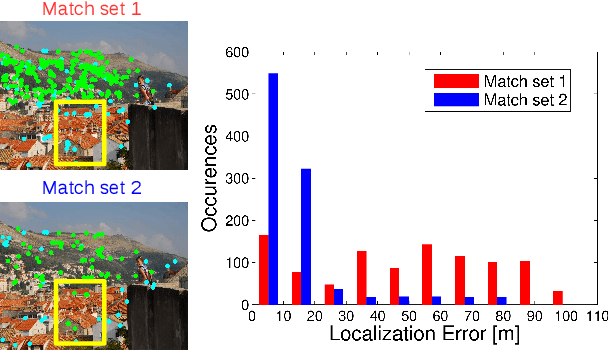
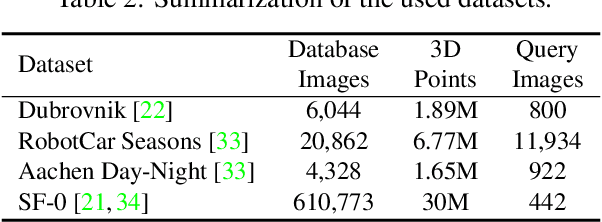
Image-based localization (IBL) aims to estimate the 6DOF camera pose for a given query image. The camera pose can be computed from 2D-3D matches between a query image and Structure-from-Motion (SfM) models. Despite recent advances in IBL, it remains difficult to simultaneously resolve the memory consumption and match ambiguity problems of large SfM models. In this work, we propose a cascaded parallel filtering method that leverages the feature, visibility and geometry information to filter wrong matches under binary feature representation. The core idea is that we divide the challenging filtering task into two parallel tasks before deriving an auxiliary camera pose for final filtering. One task focuses on preserving potentially correct matches, while another focuses on obtaining high quality matches to facilitate subsequent more powerful filtering. Moreover, our proposed method improves the localization accuracy by introducing a quality-aware spatial reconfiguration method and a principal focal length enhanced pose estimation method. Experimental results on real-world datasets demonstrate that our method achieves very competitive localization performances in a memory-efficient manner.
Billion-scale semi-supervised learning for image classification
May 02, 2019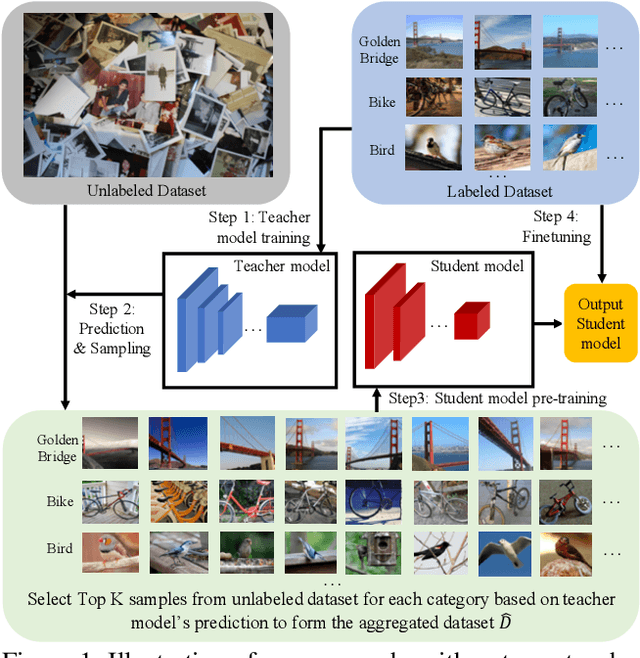

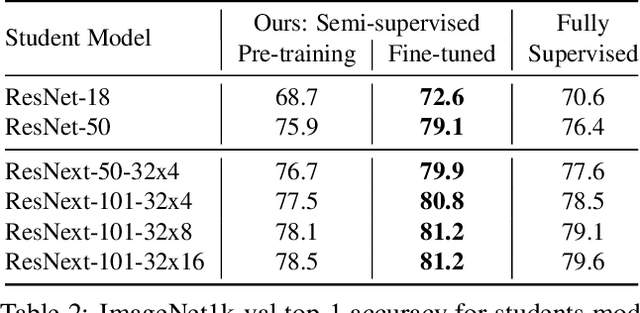
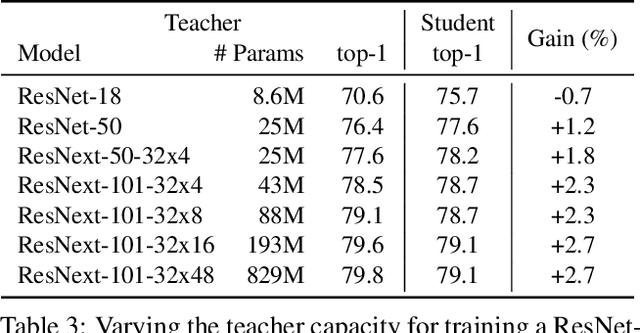
This paper presents a study of semi-supervised learning with large convolutional networks. We propose a pipeline, based on a teacher/student paradigm, that leverages a large collection of unlabelled images (up to 1 billion). Our main goal is to improve the performance for a given target architecture, like ResNet-50 or ResNext. We provide an extensive analysis of the success factors of our approach, which leads us to formulate some recommendations to produce high-accuracy models for image classification with semi-supervised learning. As a result, our approach brings important gains to standard architectures for image, video and fine-grained classification. For instance, by leveraging one billion unlabelled images, our learned vanilla ResNet-50 achieves 81.2% top-1 accuracy on the ImageNet benchmark.
MAC: Mining Activity Concepts for Language-based Temporal Localization
Nov 21, 2018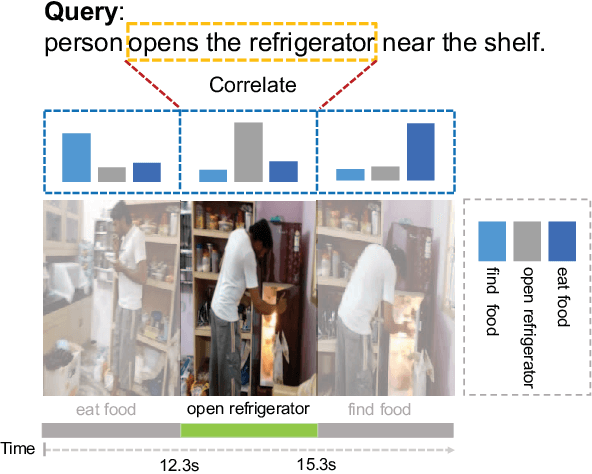
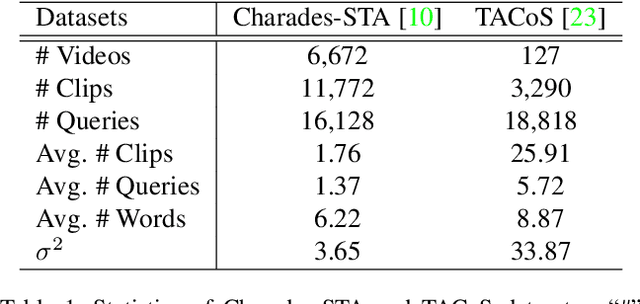
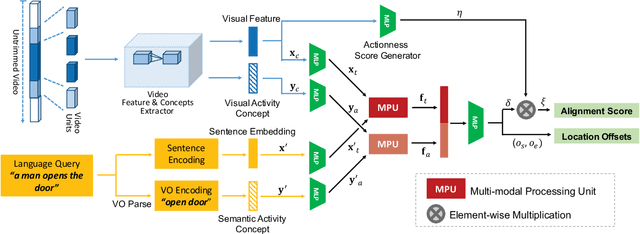
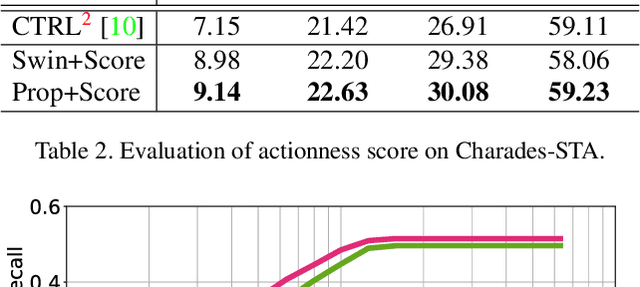
We address the problem of language-based temporal localization in untrimmed videos. Compared to temporal localization with fixed categories, this problem is more challenging as the language-based queries not only have no pre-defined activity list but also may contain complex descriptions. Previous methods address the problem by considering features from video sliding windows and language queries and learning a subspace to encode their correlation, which ignore rich semantic cues about activities in videos and queries. We propose to mine activity concepts from both video and language modalities by applying the actionness score enhanced Activity Concepts based Localizer (ACL). Specifically, the novel ACL encodes the semantic concepts from verb-obj pairs in language queries and leverages activity classifiers' prediction scores to encode visual concepts. Besides, ACL also has the capability to regress sliding windows as localization results. Experiments show that ACL significantly outperforms state-of-the-arts under the widely used metric, with more than 5% increase on both Charades-STA and TACoS datasets.
CTAP: Complementary Temporal Action Proposal Generation
Jul 18, 2018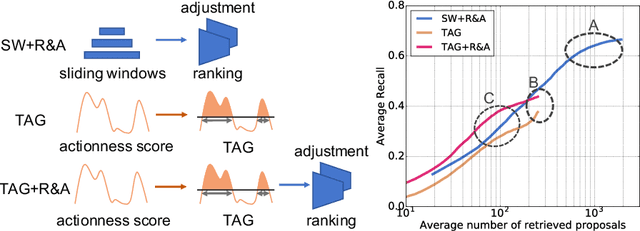

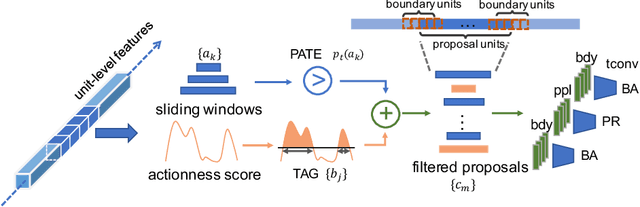

Temporal action proposal generation is an important task, akin to object proposals, temporal action proposals are intended to capture "clips" or temporal intervals in videos that are likely to contain an action. Previous methods can be divided to two groups: sliding window ranking and actionness score grouping. Sliding windows uniformly cover all segments in videos, but the temporal boundaries are imprecise; grouping based method may have more precise boundaries but it may omit some proposals when the quality of actionness score is low. Based on the complementary characteristics of these two methods, we propose a novel Complementary Temporal Action Proposal (CTAP) generator. Specifically, we apply a Proposal-level Actionness Trustworthiness Estimator (PATE) on the sliding windows proposals to generate the probabilities indicating whether the actions can be correctly detected by actionness scores, the windows with high scores are collected. The collected sliding windows and actionness proposals are then processed by a temporal convolutional neural network for proposal ranking and boundary adjustment. CTAP outperforms state-of-the-art methods on average recall (AR) by a large margin on THUMOS-14 and ActivityNet 1.3 datasets. We further apply CTAP as a proposal generation method in an existing action detector, and show consistent significant improvements.
Motion-Appearance Co-Memory Networks for Video Question Answering
Mar 29, 2018
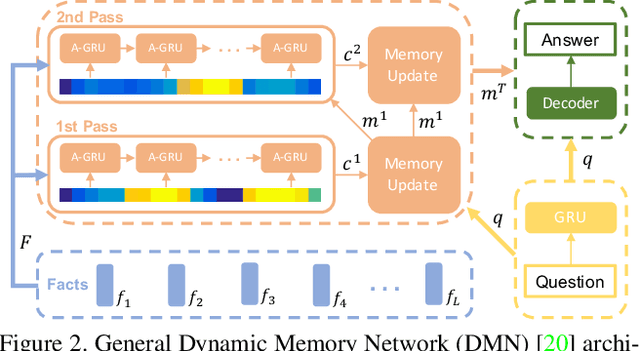
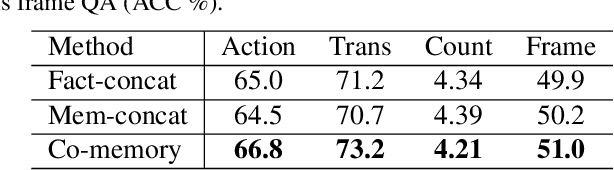
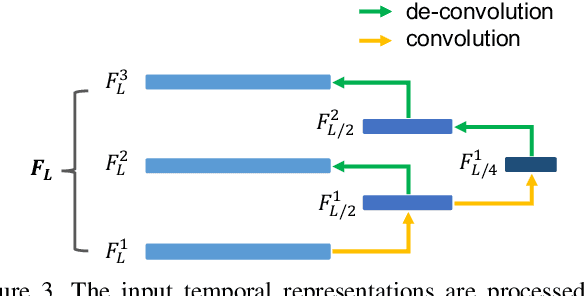
Video Question Answering (QA) is an important task in understanding video temporal structure. We observe that there are three unique attributes of video QA compared with image QA: (1) it deals with long sequences of images containing richer information not only in quantity but also in variety; (2) motion and appearance information are usually correlated with each other and able to provide useful attention cues to the other; (3) different questions require different number of frames to infer the answer. Based these observations, we propose a motion-appearance comemory network for video QA. Our networks are built on concepts from Dynamic Memory Network (DMN) and introduces new mechanisms for video QA. Specifically, there are three salient aspects: (1) a co-memory attention mechanism that utilizes cues from both motion and appearance to generate attention; (2) a temporal conv-deconv network to generate multi-level contextual facts; (3) a dynamic fact ensemble method to construct temporal representation dynamically for different questions. We evaluate our method on TGIF-QA dataset, and the results outperform state-of-the-art significantly on all four tasks of TGIF-QA.
Knowledge Aided Consistency for Weakly Supervised Phrase Grounding
Mar 11, 2018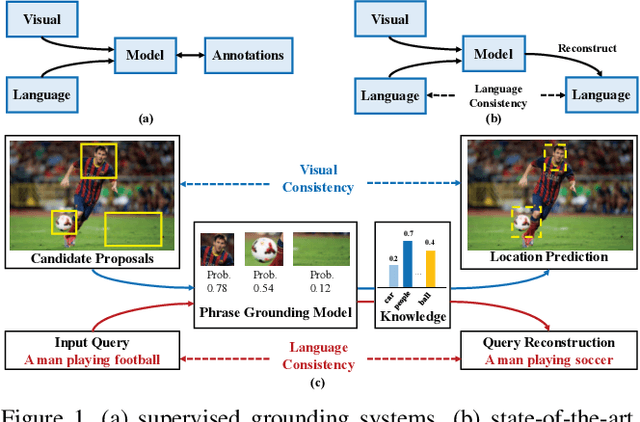
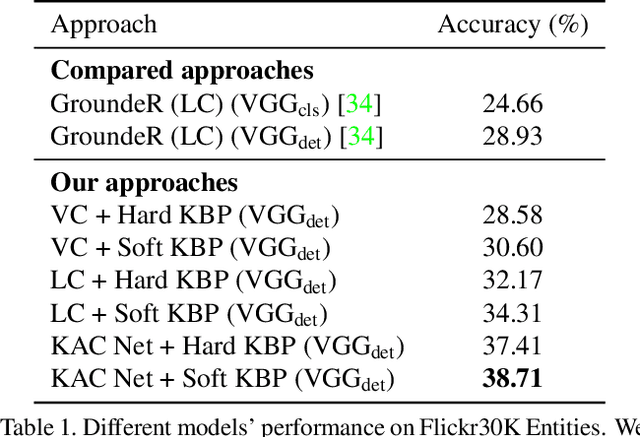
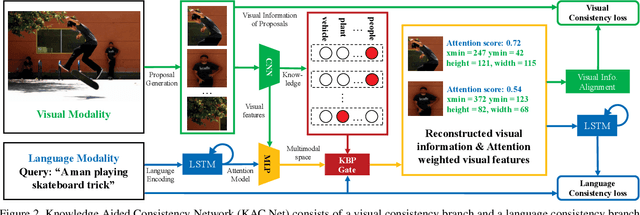

Given a natural language query, a phrase grounding system aims to localize mentioned objects in an image. In weakly supervised scenario, mapping between image regions (i.e., proposals) and language is not available in the training set. Previous methods address this deficiency by training a grounding system via learning to reconstruct language information contained in input queries from predicted proposals. However, the optimization is solely guided by the reconstruction loss from the language modality, and ignores rich visual information contained in proposals and useful cues from external knowledge. In this paper, we explore the consistency contained in both visual and language modalities, and leverage complementary external knowledge to facilitate weakly supervised grounding. We propose a novel Knowledge Aided Consistency Network (KAC Net) which is optimized by reconstructing input query and proposal's information. To leverage complementary knowledge contained in the visual features, we introduce a Knowledge Based Pooling (KBP) gate to focus on query-related proposals. Experiments show that KAC Net provides a significant improvement on two popular datasets.
Query-guided Regression Network with Context Policy for Phrase Grounding
Aug 04, 2017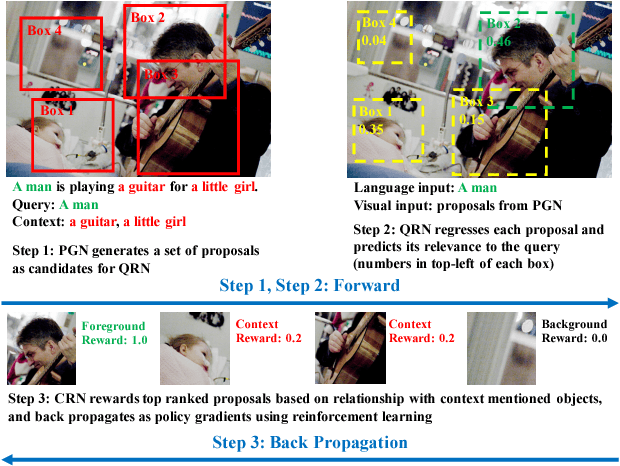
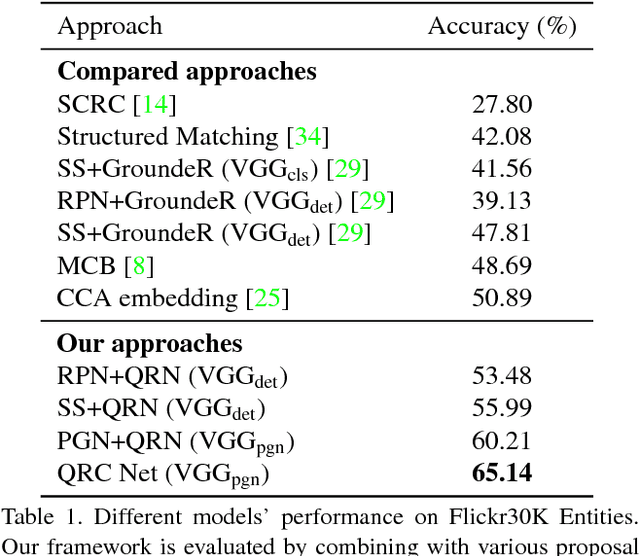
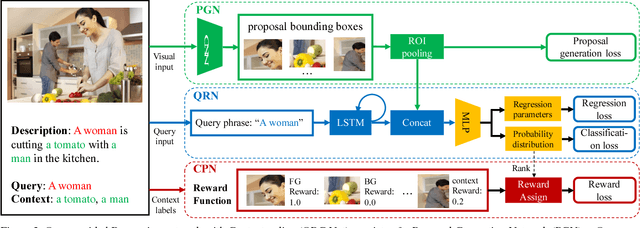
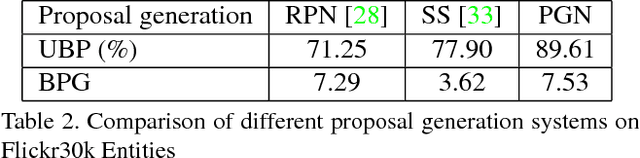
Given a textual description of an image, phrase grounding localizes objects in the image referred by query phrases in the description. State-of-the-art methods address the problem by ranking a set of proposals based on the relevance to each query, which are limited by the performance of independent proposal generation systems and ignore useful cues from context in the description. In this paper, we adopt a spatial regression method to break the performance limit, and introduce reinforcement learning techniques to further leverage semantic context information. We propose a novel Query-guided Regression network with Context policy (QRC Net) which jointly learns a Proposal Generation Network (PGN), a Query-guided Regression Network (QRN) and a Context Policy Network (CPN). Experiments show QRC Net provides a significant improvement in accuracy on two popular datasets: Flickr30K Entities and Referit Game, with 14.25% and 17.14% increase over the state-of-the-arts respectively.