 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Non-Parametric Methods for Adaptive Robustness
Feb 18, 2021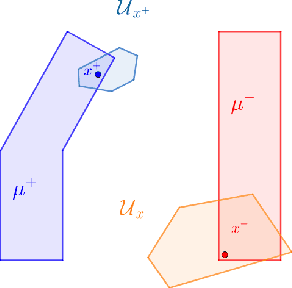
Learning classifiers that are robust to adversarial examples has received a great deal of recent attention. A major drawback of the standard robust learning framework is the imposition of an artificial robustness radius $r$ that applies to all inputs, and ignores the fact that data may be highly heterogeneous. In this paper, we address this limitation by proposing a new framework for adaptive robustness, called neighborhood preserving robustness. We present sufficient conditions under which general non-parametric methods that can be represented as weight functions satisfy our notion of robustness, and show that both nearest neighbors and kernel classifiers satisfy these conditions in the large sample limit.
Connecting Interpretability and Robustness in Decision Trees through Separation
Feb 14, 2021
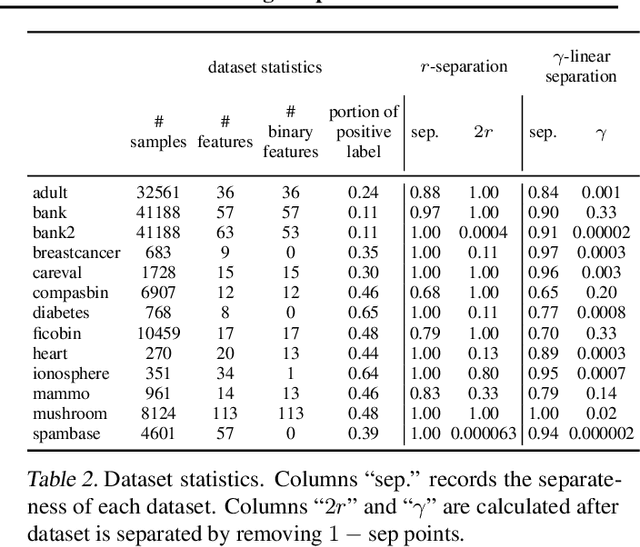
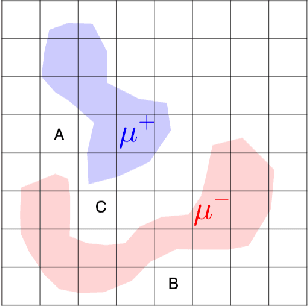
Recent research has recognized interpretability and robustness as essential properties of trustworthy classification. Curiously, a connection between robustness and interpretability was empirically observed, but the theoretical reasoning behind it remained elusive. In this paper, we rigorously investigate this connection. Specifically, we focus on interpretation using decision trees and robustness to $l_{\infty}$-perturbation. Previous works defined the notion of $r$-separation as a sufficient condition for robustness. We prove upper and lower bounds on the tree size in case the data is $r$-separated. We then show that a tighter bound on the size is possible when the data is linearly separated. We provide the first algorithm with provable guarantees both on robustness, interpretability, and accuracy in the context of decision trees. Experiments confirm that our algorithm yields classifiers that are both interpretable and robust and have high accuracy. The code for the experiments is available at https://github.com/yangarbiter/interpretable-robust-trees .
Sample Complexity of Adversarially Robust Linear Classification on Separated Data
Dec 19, 2020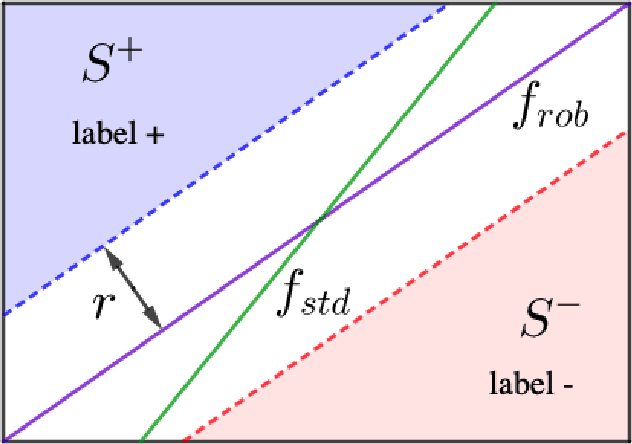
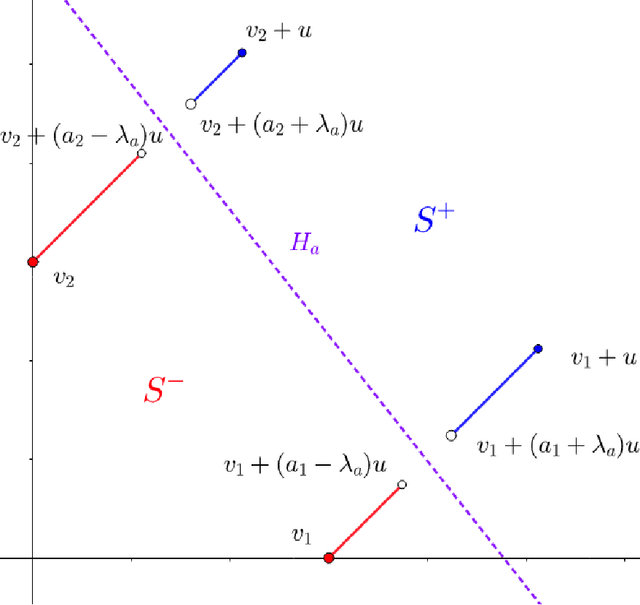
We consider the sample complexity of learning with adversarial robustness. Most prior theoretical results for this problem have considered a setting where different classes in the data are close together or overlapping. Motivated by some real applications, we consider, in contrast, the well-separated case where there exists a classifier with perfect accuracy and robustness, and show that the sample complexity narrates an entirely different story. Specifically, for linear classifiers, we show a large class of well-separated distributions where the expected robust loss of any algorithm is at least $\Omega(\frac{d}{n})$, whereas the max margin algorithm has expected standard loss $O(\frac{1}{n})$. This shows a gap in the standard and robust losses that cannot be obtained via prior techniques. Additionally, we present an algorithm that, given an instance where the robustness radius is much smaller than the gap between the classes, gives a solution with expected robust loss is $O(\frac{1}{n})$. This shows that for very well-separated data, convergence rates of $O(\frac{1}{n})$ are achievable, which is not the case otherwise. Our results apply to robustness measured in any $\ell_p$ norm with $p > 1$ (including $p = \infty$).
Close Category Generalization
Nov 17, 2020
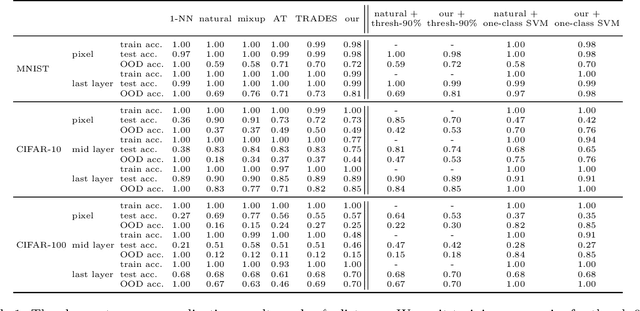
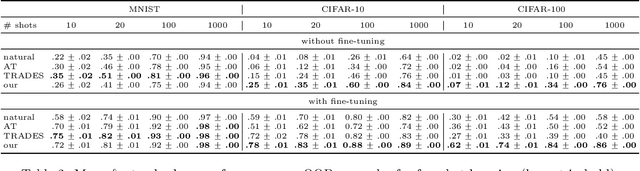
Out-of-distribution generalization is a core challenge in machine learning. We introduce and propose a solution to a new type of out-of-distribution evaluation, which we call close category generalization. This task specifies how a classifier should extrapolate to unseen classes by considering a bi-criteria objective: (i) on in-distribution examples, output the correct label, and (ii) on out-of-distribution examples, output the label of the nearest neighbor in the training set. In addition to formalizing this problem, we present a new training algorithm to improve the close category generalization of neural networks. We compare to many baselines, including robust algorithms and out-of-distribution detection methods, and we show that our method has better or comparable close category generalization. Then, we investigate a related representation learning task, and we find that performing well on close category generalization correlates with learning a good representation of an unseen class and with finding a good initialization for few-shot learning. Code available at https://github.com/yangarbiter/close-category-generalization
Revisiting Model-Agnostic Private Learning: Faster Rates and Active Learning
Nov 13, 2020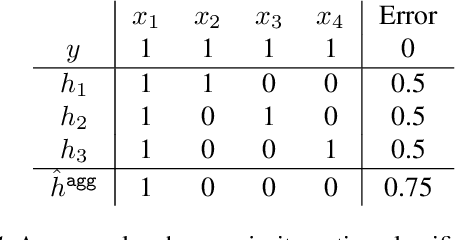
The Private Aggregation of Teacher Ensembles (PATE) framework is one of the most promising recent approaches in differentially private learning. Existing theoretical analysis shows that PATE consistently learns any VC-classes in the realizable setting, but falls short in explaining its success in more general cases where the error rate of the optimal classifier is bounded away from zero. We fill in this gap by introducing the Tsybakov Noise Condition (TNC) and establish stronger and more interpretable learning bounds. These bounds provide new insights into when PATE works and improve over existing results even in the narrower realizable setting. We also investigate the compelling idea of using active learning for saving privacy budget. The novel components in the proofs include a more refined analysis of the majority voting classifier -- which could be of independent interest -- and an observation that the synthetic "student" learning problem is nearly realizable by construction under the Tsybakov noise condition.
Multitask Bandit Learning through Heterogeneous Feedback Aggregation
Oct 29, 2020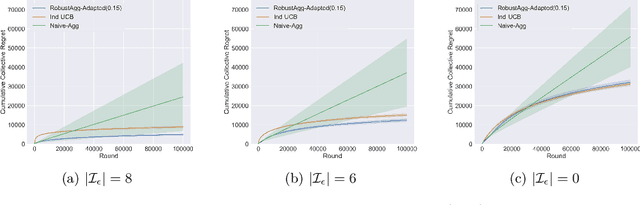
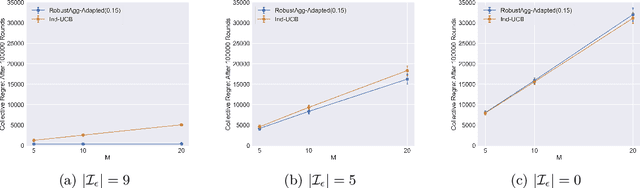
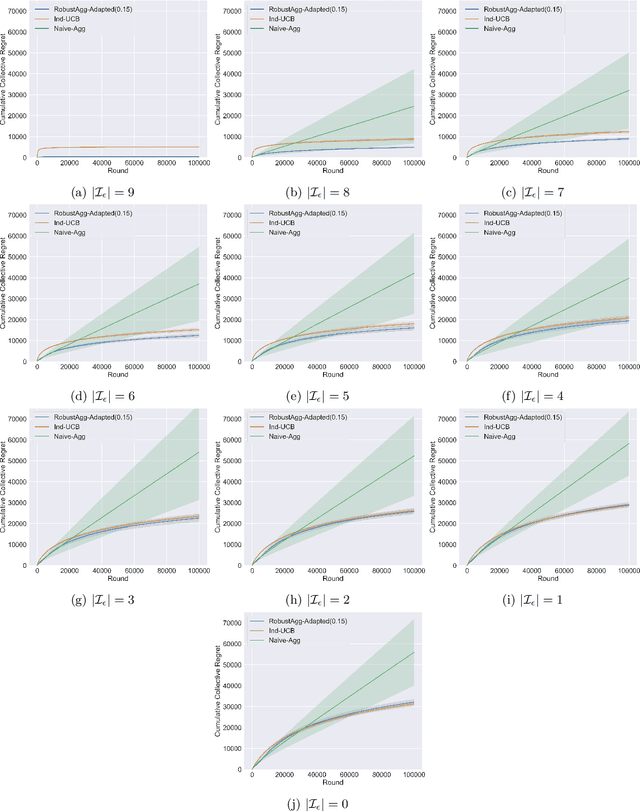
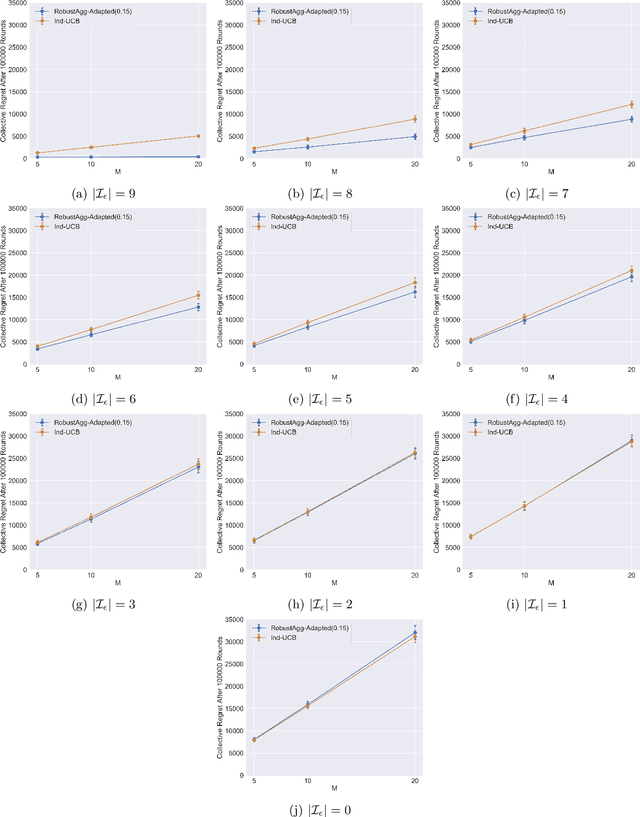
In many real-world applications, multiple agents seek to learn how to perform highly related yet slightly different tasks in an online bandit learning protocol. We formulate this problem as the $\epsilon$-multi-player multi-armed bandit problem, in which a set of players concurrently interact with a set of arms, and for each arm, the reward distributions for all players are similar but not necessarily identical. We develop an upper confidence bound-based algorithm, RobustAgg$(\epsilon)$, that adaptively aggregates rewards collected by different players. In the setting where an upper bound on the pairwise similarities of reward distributions between players is known, we achieve instance-dependent regret guarantees that depend on the amenability of information sharing across players. We complement these upper bounds with nearly matching lower bounds. In the setting where pairwise similarities are unknown, we provide a lower bound, as well as an algorithm that trades off minimax regret guarantees for adaptivity to unknown similarity structure.
Trustworthy AI Inference Systems: An Industry Research View
Aug 10, 2020In this work, we provide an industry research view for approaching the design, deployment, and operation of trustworthy Artificial Intelligence (AI) inference systems. Such systems provide customers with timely, informed, and customized inferences to aid their decision, while at the same time utilizing appropriate security protection mechanisms for AI models. Additionally, such systems should also use Privacy-Enhancing Technologies (PETs) to protect customers' data at any time. To approach the subject, we start by introducing trends in AI inference systems. We continue by elaborating on the relationship between Intellectual Property (IP) and private data protection in such systems. Regarding the protection mechanisms, we survey the security and privacy building blocks instrumental in designing, building, deploying, and operating private AI inference systems. For example, we highlight opportunities and challenges in AI systems using trusted execution environments combined with more recent advances in cryptographic techniques to protect data in use. Finally, we outline areas of further development that require the global collective attention of industry, academia, and government researchers to sustain the operation of trustworthy AI inference systems.
The Expressive Power of a Class of Normalizing Flow Models
May 31, 2020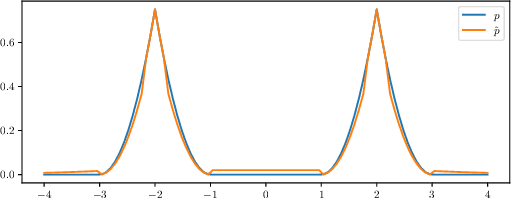
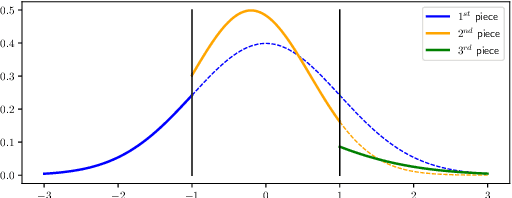
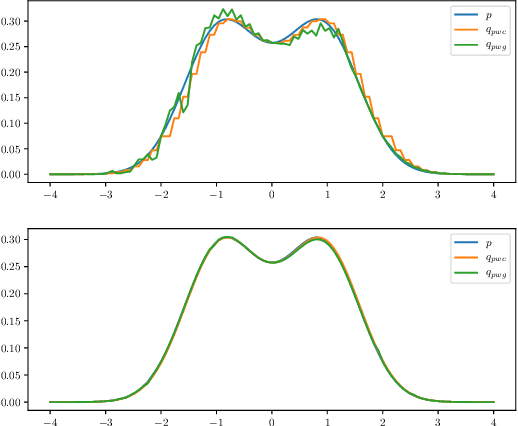
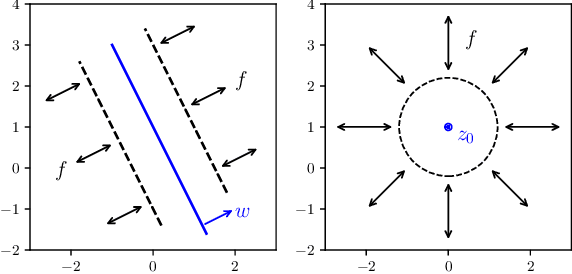
Normalizing flows have received a great deal of recent attention as they allow flexible generative modeling as well as easy likelihood computation. While a wide variety of flow models have been proposed, there is little formal understanding of the representation power of these models. In this work, we study some basic normalizing flows and rigorously establish bounds on their expressive power. Our results indicate that while these flows are highly expressive in one dimension, in higher dimensions their representation power may be limited, especially when the flows have moderate depth.
Successive Refinement of Privacy
May 24, 2020

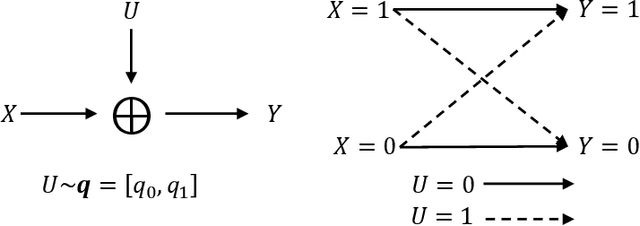
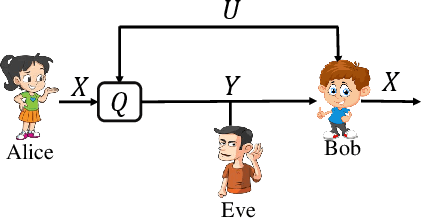
This work examines a novel question: how much randomness is needed to achieve local differential privacy (LDP)? A motivating scenario is providing {\em multiple levels of privacy} to multiple analysts, either for distribution or for heavy-hitter estimation, using the \emph{same} (randomized) output. We call this setting \emph{successive refinement of privacy}, as it provides hierarchical access to the raw data with different privacy levels. For example, the same randomized output could enable one analyst to reconstruct the input, while another can only estimate the distribution subject to LDP requirements. This extends the classical Shannon (wiretap) security setting to local differential privacy. We provide (order-wise) tight characterizations of privacy-utility-randomness trade-offs in several cases for distribution estimation, including the standard LDP setting under a randomness constraint. We also provide a non-trivial privacy mechanism for multi-level privacy. Furthermore, we show that we cannot reuse random keys over time while preserving privacy of each user.
Adversarial Robustness Through Local Lipschitzness
Apr 16, 2020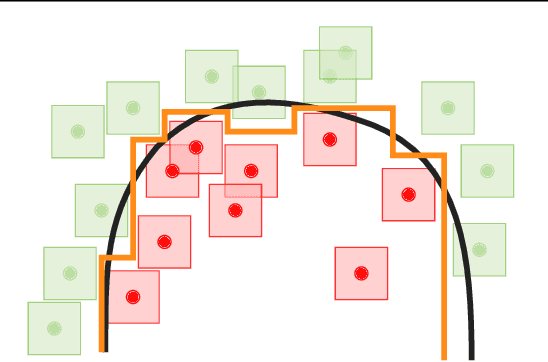
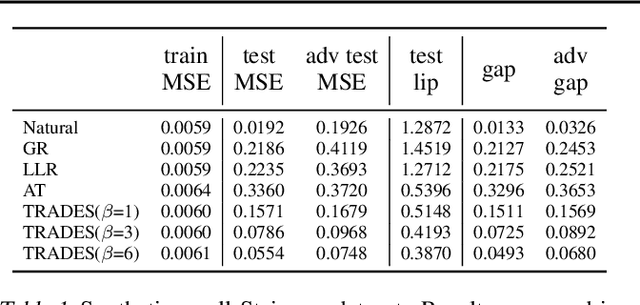
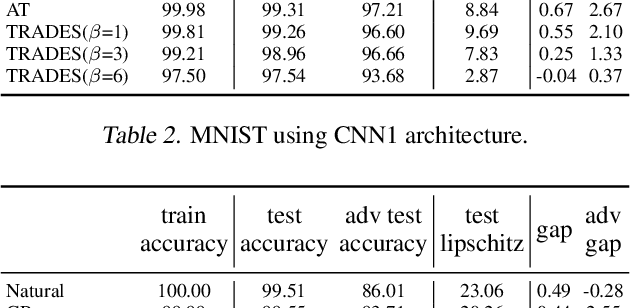
A standard method for improving the robustness of neural networks is adversarial training, where the network is trained on adversarial examples that are close to the training inputs. This produces classifiers that are robust, but it often decreases clean accuracy. Prior work even posits that the tradeoff between robustness and accuracy may be inevitable. We investigate this tradeoff in more depth through the lens of local Lipschitzness. In many image datasets, the classes are separated in the sense that images with different labels are not extremely close in $\ell_\infty$ distance. Using this separation as a starting point, we argue that it is possible to achieve both accuracy and robustness by encouraging the classifier to be locally smooth around the data. More precisely, we consider classifiers that are obtained by rounding locally Lipschitz functions. Theoretically, we show that such classifiers exist for any dataset such that there is a positive distance between the support of different classes. Empirically, we compare the local Lipschitzness of classifiers trained by several methods. Our results show that having a small Lipschitz constant correlates with achieving high clean and robust accuracy, and therefore, the smoothness of the classifier is an important property to consider in the context of adversarial examples. Code available at https://github.com/yangarbiter/robust-local-lipschitz .