 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultistage BiCross Encoder: Team GATE Entry for MLIA Multilingual Semantic Search Task 2
Jan 15, 2021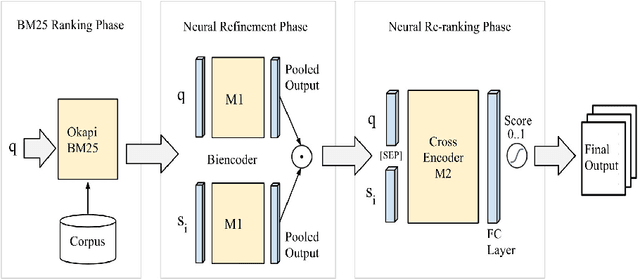
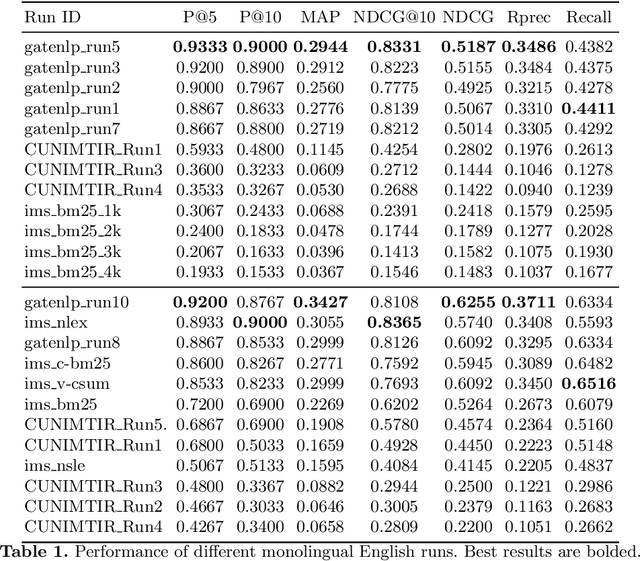
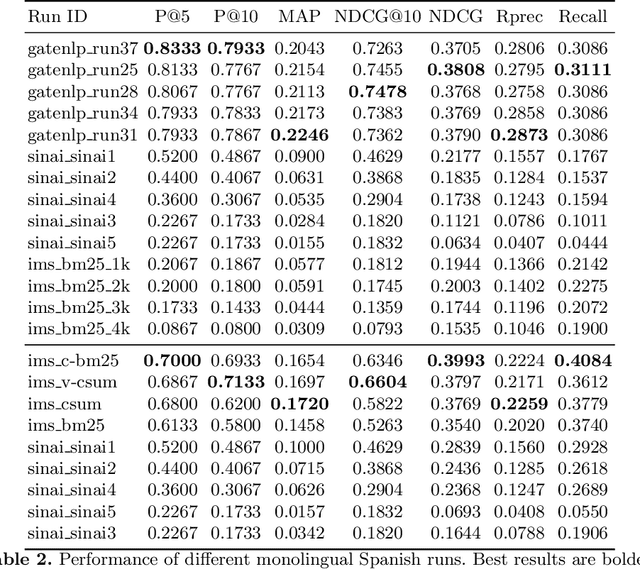
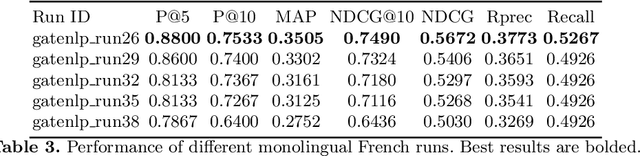
The Coronavirus (COVID-19) pandemic has led to a rapidly growing `infodemic' online. Thus, the accurate retrieval of reliable relevant data from millions of documents about COVID-19 has become urgently needed for the general public as well as for other stakeholders. The COVID-19 Multilingual Information Access (MLIA) initiative is a joint effort to ameliorate exchange of COVID-19 related information by developing applications and services through research and community participation. In this work, we present a search system called Multistage BiCross Encoder, developed by team GATE for the MLIA task 2 Multilingual Semantic Search. Multistage BiCross-Encoder is a sequential three stage pipeline which uses the Okapi BM25 algorithm and a transformer based bi-encoder and cross-encoder to effectively rank the documents with respect to the query. The results of round 1 show that our models achieve state-of-the-art performance for all ranking metrics for both monolingual and bilingual runs.
Toxic Language Detection in Social Media for Brazilian Portuguese: New Dataset and Multilingual Analysis
Oct 09, 2020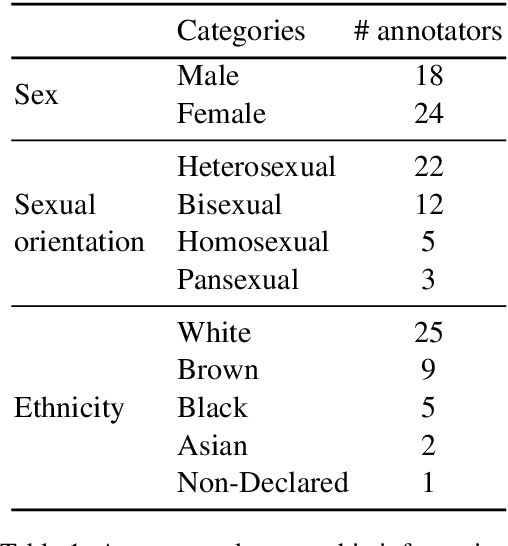
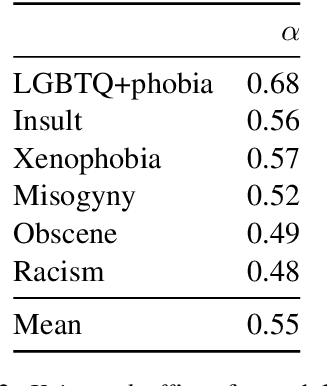

Hate speech and toxic comments are a common concern of social media platform users. Although these comments are, fortunately, the minority in these platforms, they are still capable of causing harm. Therefore, identifying these comments is an important task for studying and preventing the proliferation of toxicity in social media. Previous work in automatically detecting toxic comments focus mainly in English, with very few work in languages like Brazilian Portuguese. In this paper, we propose a new large-scale dataset for Brazilian Portuguese with tweets annotated as either toxic or non-toxic or in different types of toxicity. We present our dataset collection and annotation process, where we aimed to select candidates covering multiple demographic groups. State-of-the-art BERT models were able to achieve 76% macro-F1 score using monolingual data in the binary case. We also show that large-scale monolingual data is still needed to create more accurate models, despite recent advances in multilingual approaches. An error analysis and experiments with multi-label classification show the difficulty of classifying certain types of toxic comments that appear less frequently in our data and highlights the need to develop models that are aware of different categories of toxicity.
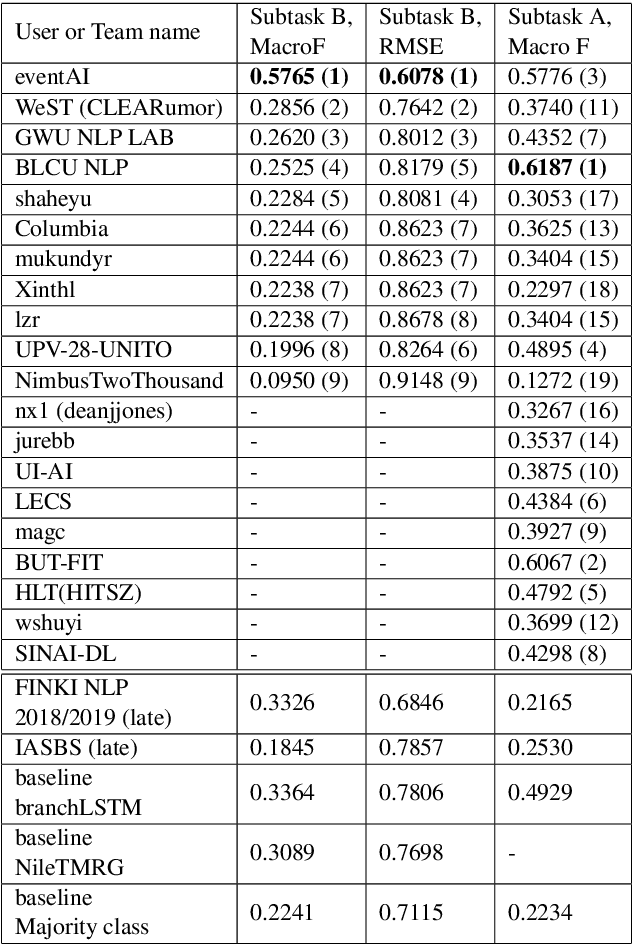
Measuring What Counts: The case of Rumour Stance Classification
Oct 09, 2020
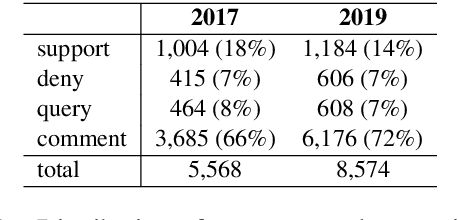
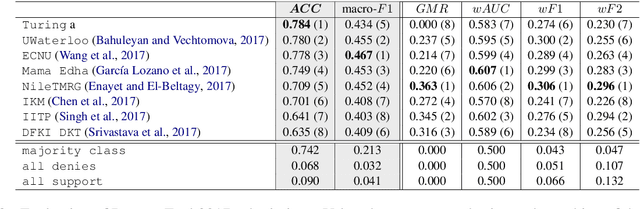

Stance classification can be a powerful tool for understanding whether and which users believe in online rumours. The task aims to automatically predict the stance of replies towards a given rumour, namely support, deny, question, or comment. Numerous methods have been proposed and their performance compared in the RumourEval shared tasks in 2017 and 2019. Results demonstrated that this is a challenging problem since naturally occurring rumour stance data is highly imbalanced. This paper specifically questions the evaluation metrics used in these shared tasks. We re-evaluate the systems submitted to the two RumourEval tasks and show that the two widely adopted metrics -- accuracy and macro-F1 -- are not robust for the four-class imbalanced task of rumour stance classification, as they wrongly favour systems with highly skewed accuracy towards the majority class. To overcome this problem, we propose new evaluation metrics for rumour stance detection. These are not only robust to imbalanced data but also score higher systems that are capable of recognising the two most informative minority classes (support and deny).
Classification Aware Neural Topic Model and its Application on a New COVID-19 Disinformation Corpus
Jun 05, 2020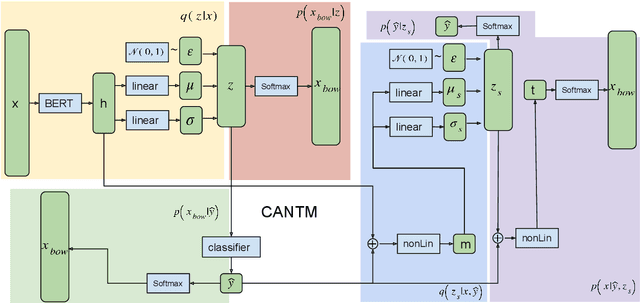
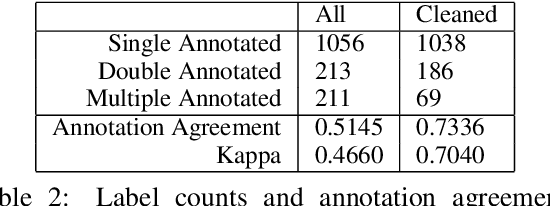
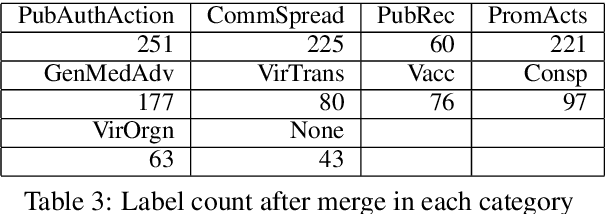
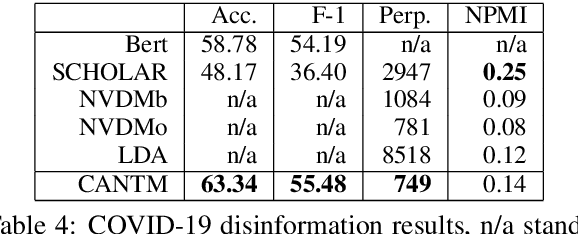
The explosion of disinformation related to the COVID-19 pandemic has overloaded fact-checkers and media worldwide. To help tackle this, we developed computational methods to support COVID-19 disinformation debunking and social impacts research. This paper presents: 1) the currently largest available manually annotated COVID-19 disinformation category dataset; and 2) a classification-aware neural topic model (CANTM) that combines classification and topic modelling under a variational autoencoder framework. We demonstrate that CANTM efficiently improves classification performance with low resources, and is scalable. In addition, the classification-aware topics help researchers and end-users to better understand the classification results.
Towards an Interoperable Ecosystem of AI and LT Platforms: A Roadmap for the Implementation of Different Levels of Interoperability
Apr 17, 2020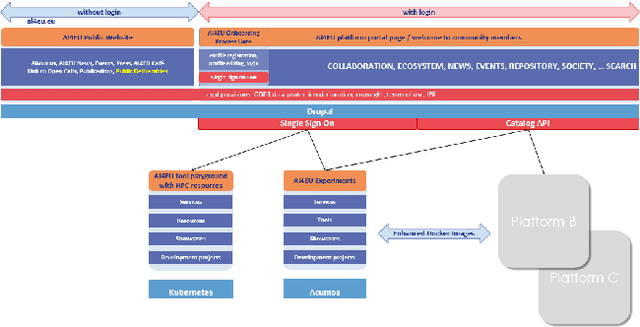
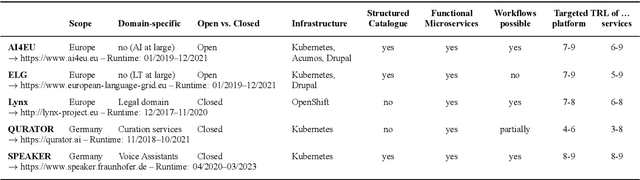
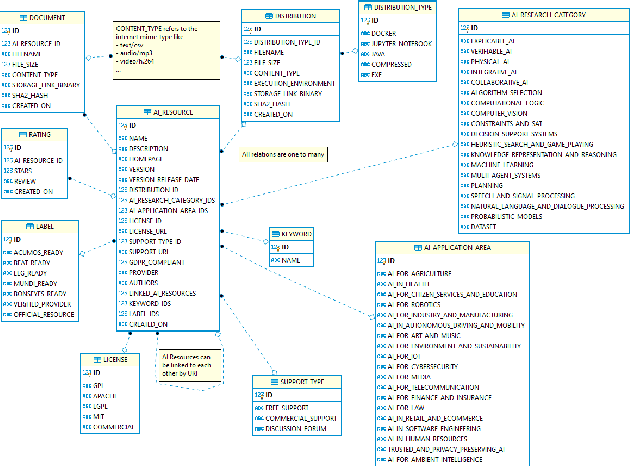

With regard to the wider area of AI/LT platform interoperability, we concentrate on two core aspects: (1) cross-platform search and discovery of resources and services; (2) composition of cross-platform service workflows. We devise five different levels (of increasing complexity) of platform interoperability that we suggest to implement in a wider federation of AI/LT platforms. We illustrate the approach using the five emerging AI/LT platforms AI4EU, ELG, Lynx, QURATOR and SPEAKER.
The European Language Technology Landscape in 2020: Language-Centric and Human-Centric AI for Cross-Cultural Communication in Multilingual Europe
Mar 30, 2020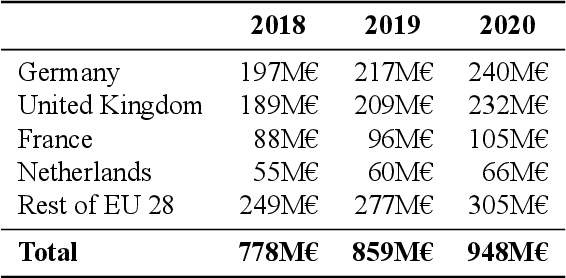
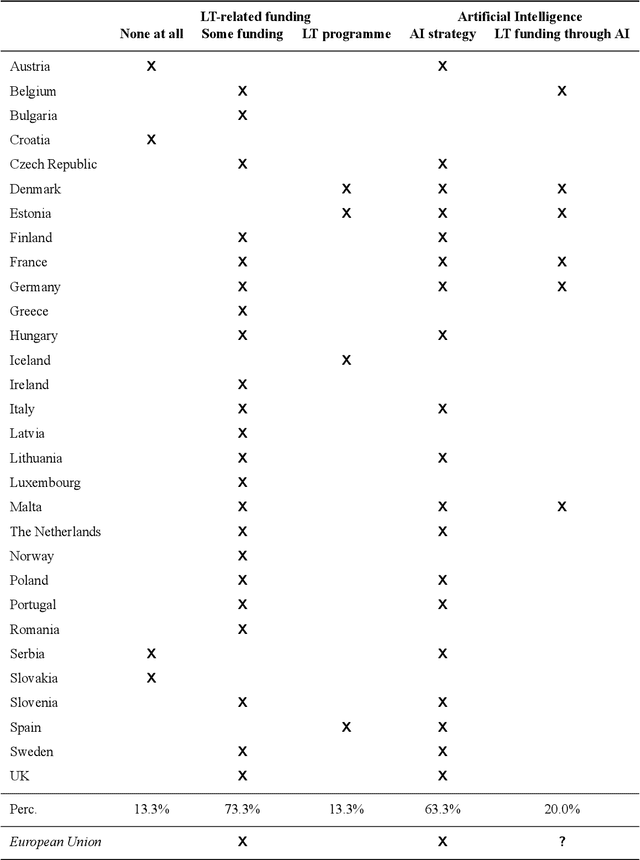
Multilingualism is a cultural cornerstone of Europe and firmly anchored in the European treaties including full language equality. However, language barriers impacting business, cross-lingual and cross-cultural communication are still omnipresent. Language Technologies (LTs) are a powerful means to break down these barriers. While the last decade has seen various initiatives that created a multitude of approaches and technologies tailored to Europe's specific needs, there is still an immense level of fragmentation. At the same time, AI has become an increasingly important concept in the European Information and Communication Technology area. For a few years now, AI, including many opportunities, synergies but also misconceptions, has been overshadowing every other topic. We present an overview of the European LT landscape, describing funding programmes, activities, actions and challenges in the different countries with regard to LT, including the current state of play in industry and the LT market. We present a brief overview of the main LT-related activities on the EU level in the last ten years and develop strategic guidance with regard to four key dimensions.
European Language Grid: An Overview
Mar 30, 2020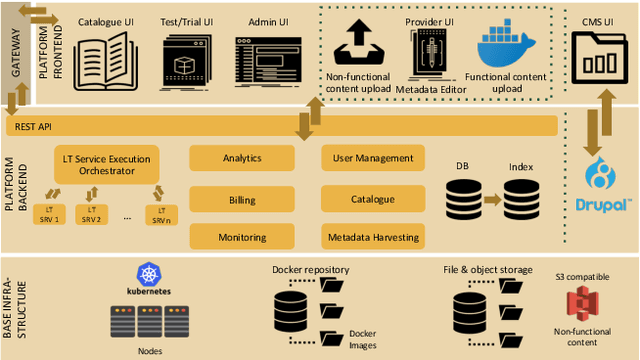

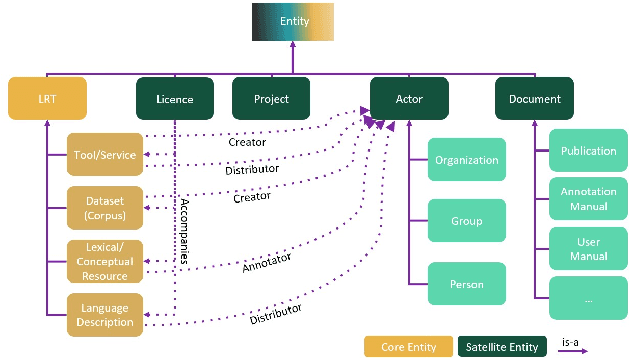
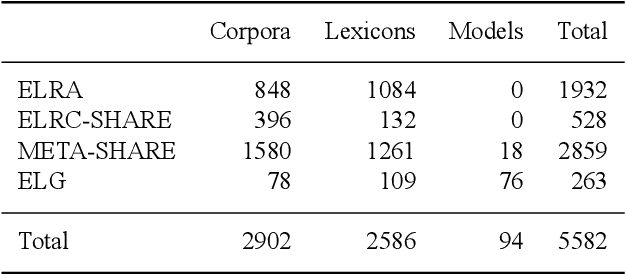
With 24 official EU and many additional languages, multilingualism in Europe and an inclusive Digital Single Market can only be enabled through Language Technologies (LTs). European LT business is dominated by hundreds of SMEs and a few large players. Many are world-class, with technologies that outperform the global players. However, European LT business is also fragmented, by nation states, languages, verticals and sectors, significantly holding back its impact. The European Language Grid (ELG) project addresses this fragmentation by establishing the ELG as the primary platform for LT in Europe. The ELG is a scalable cloud platform, providing, in an easy-to-integrate way, access to hundreds of commercial and non-commercial LTs for all European languages, including running tools and services as well as data sets and resources. Once fully operational, it will enable the commercial and non-commercial European LT community to deposit and upload their technologies and data sets into the ELG, to deploy them through the grid, and to connect with other resources. The ELG will boost the Multilingual Digital Single Market towards a thriving European LT community, creating new jobs and opportunities. Furthermore, the ELG project organises two open calls for up to 20 pilot projects. It also sets up 32 National Competence Centres (NCCs) and the European LT Council (LTC) for outreach and coordination purposes.
The evolution of argumentation mining: From models to social media and emerging tools
Jul 04, 2019
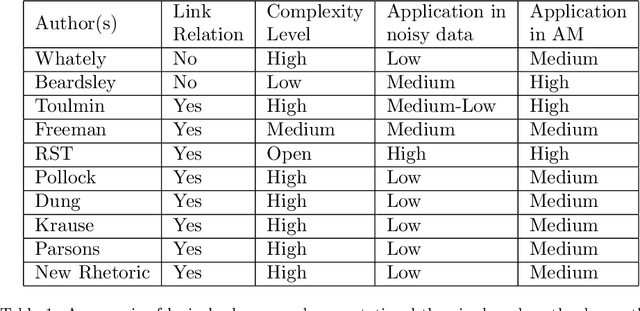
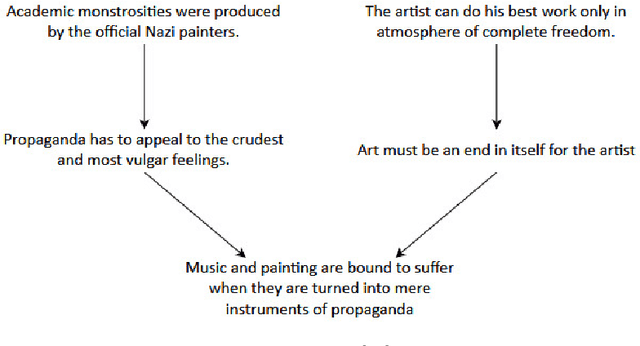
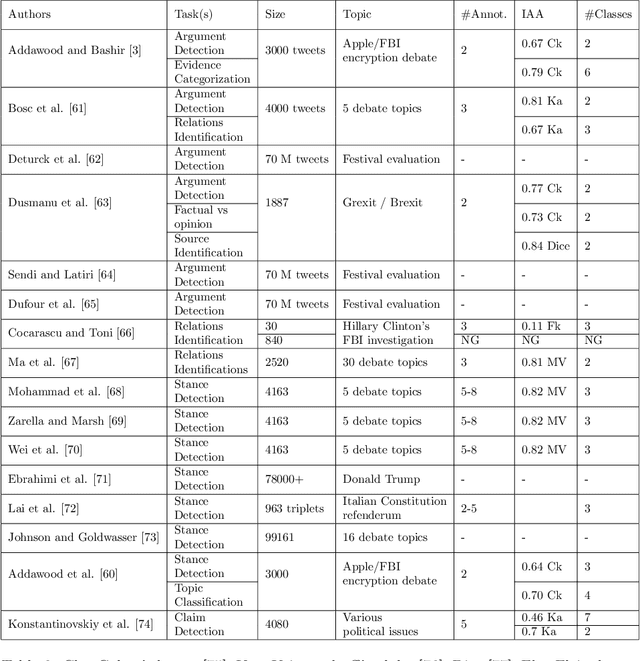
Argumentation mining is a rising subject in the computational linguistics domain focusing on extracting structured arguments from natural text, often from unstructured or noisy text. The initial approaches on modeling arguments was aiming to identify a flawless argument on specific fields (Law, Scientific Papers) serving specific needs (completeness, effectiveness). With the emerge of Web 2.0 and the explosion in the use of social media both the diffusion of the data and the argument structure have changed. In this survey article, we bridge the gap between theoretical approaches of argumentation mining and pragmatic schemes that satisfy the needs of social media generated data, recognizing the need for adapting more flexible and expandable schemes, capable to adjust to the argumentation conditions that exist in social media. We review, compare, and classify existing approaches, techniques and tools, identifying the positive outcome of combining tasks and features, and eventually propose a conceptual architecture framework. The proposed theoretical framework is an argumentation mining scheme able to identify the distinct sub-tasks and capture the needs of social media text, revealing the need for adopting more flexible and extensible frameworks.
* Journal of Information Processing & Management, Elsevier - Accepted Version
RumourEval 2019: Determining Rumour Veracity and Support for Rumours
Sep 18, 2018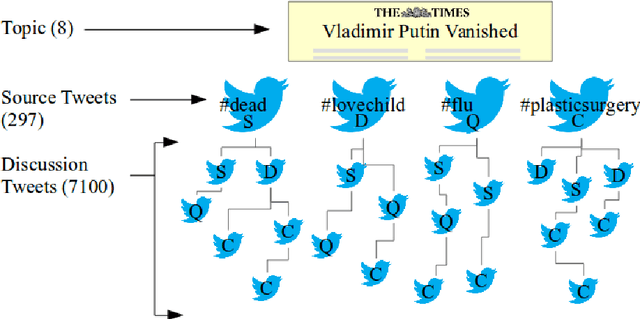
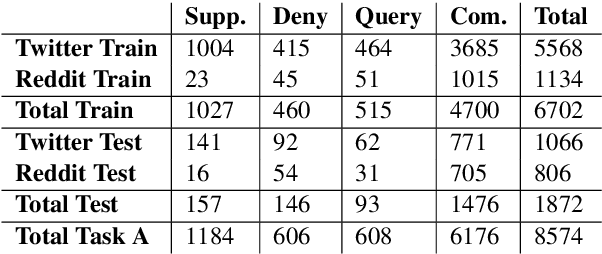
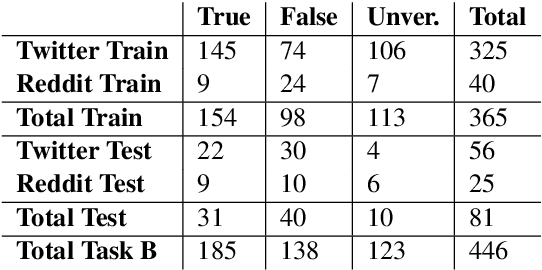
This is the proposal for RumourEval-2019, which will run in early 2019 as part of that year's SemEval event. Since the first RumourEval shared task in 2017, interest in automated claim validation has greatly increased, as the dangers of "fake news" have become a mainstream concern. Yet automated support for rumour checking remains in its infancy. For this reason, it is important that a shared task in this area continues to provide a focus for effort, which is likely to increase. We therefore propose a continuation in which the veracity of further rumours is determined, and as previously, supportive of this goal, tweets discussing them are classified according to the stance they take regarding the rumour. Scope is extended compared with the first RumourEval, in that the dataset is substantially expanded to include Reddit as well as Twitter data, and additional languages are also included.
Detection and Resolution of Rumours in Social Media: A Survey
Apr 03, 2018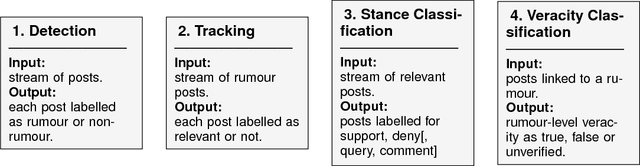
Despite the increasing use of social media platforms for information and news gathering, its unmoderated nature often leads to the emergence and spread of rumours, i.e. pieces of information that are unverified at the time of posting. At the same time, the openness of social media platforms provides opportunities to study how users share and discuss rumours, and to explore how natural language processing and data mining techniques may be used to find ways of determining their veracity. In this survey we introduce and discuss two types of rumours that circulate on social media; long-standing rumours that circulate for long periods of time, and newly-emerging rumours spawned during fast-paced events such as breaking news, where reports are released piecemeal and often with an unverified status in their early stages. We provide an overview of research into social media rumours with the ultimate goal of developing a rumour classification system that consists of four components: rumour detection, rumour tracking, rumour stance classification and rumour veracity classification. We delve into the approaches presented in the scientific literature for the development of each of these four components. We summarise the efforts and achievements so far towards the development of rumour classification systems and conclude with suggestions for avenues for future research in social media mining for detection and resolution of rumours.
* ACM Computing Surveys