 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Discourse Parsing-inspired Semantic Storytelling
Apr 25, 2020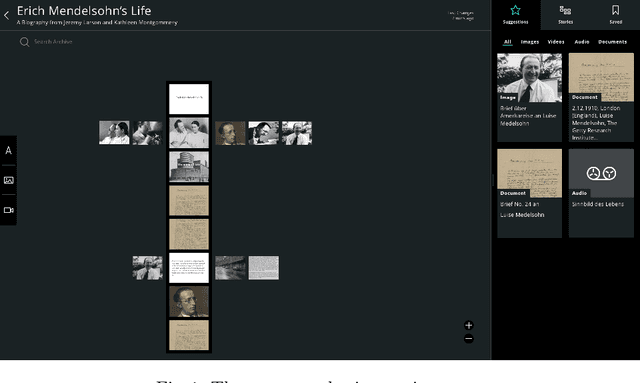
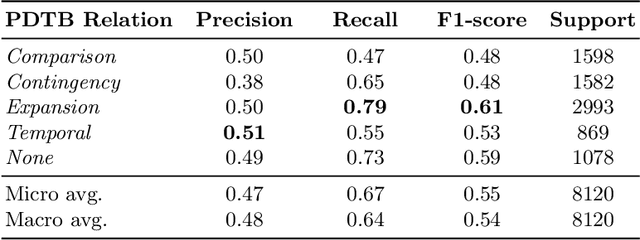

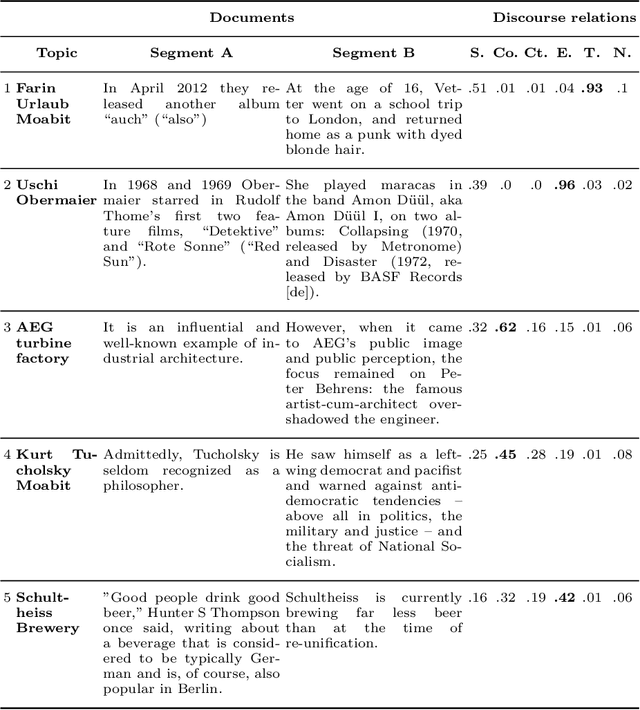
Previous work of ours on Semantic Storytelling uses text analytics procedures including Named Entity Recognition and Event Detection. In this paper, we outline our longer-term vision on Semantic Storytelling and describe the current conceptual and technical approach. In the project that drives our research we develop AI-based technologies that are verified by partners from industry. One long-term goal is the development of an approach for Semantic Storytelling that has broad coverage and that is, furthermore, robust. We provide first results on experiments that involve discourse parsing, applied to a concrete use case, "Explore the Neighbourhood!", which is based on a semi-automatically collected data set with documents about noteworthy people in one of Berlin's districts. Though automatically obtaining annotations for coherence relations from plain text is a non-trivial challenge, our preliminary results are promising. We envision our approach to be combined with additional features (NER, coreference resolution, knowledge graphs
European Language Grid: An Overview
Mar 30, 2020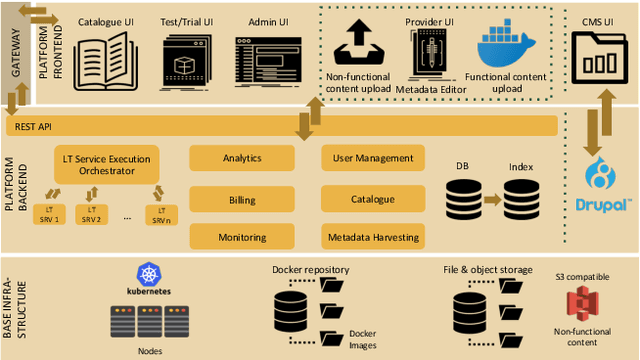

With 24 official EU and many additional languages, multilingualism in Europe and an inclusive Digital Single Market can only be enabled through Language Technologies (LTs). European LT business is dominated by hundreds of SMEs and a few large players. Many are world-class, with technologies that outperform the global players. However, European LT business is also fragmented, by nation states, languages, verticals and sectors, significantly holding back its impact. The European Language Grid (ELG) project addresses this fragmentation by establishing the ELG as the primary platform for LT in Europe. The ELG is a scalable cloud platform, providing, in an easy-to-integrate way, access to hundreds of commercial and non-commercial LTs for all European languages, including running tools and services as well as data sets and resources. Once fully operational, it will enable the commercial and non-commercial European LT community to deposit and upload their technologies and data sets into the ELG, to deploy them through the grid, and to connect with other resources. The ELG will boost the Multilingual Digital Single Market towards a thriving European LT community, creating new jobs and opportunities. Furthermore, the ELG project organises two open calls for up to 20 pilot projects. It also sets up 32 National Competence Centres (NCCs) and the European LT Council (LTC) for outreach and coordination purposes.
Making Metadata Fit for Next Generation Language Technology Platforms: The Metadata Schema of the European Language Grid
Mar 30, 2020
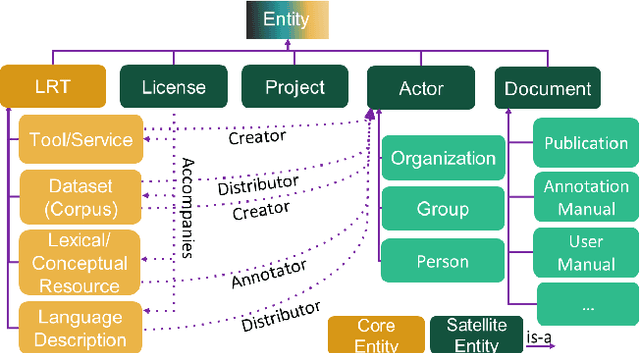
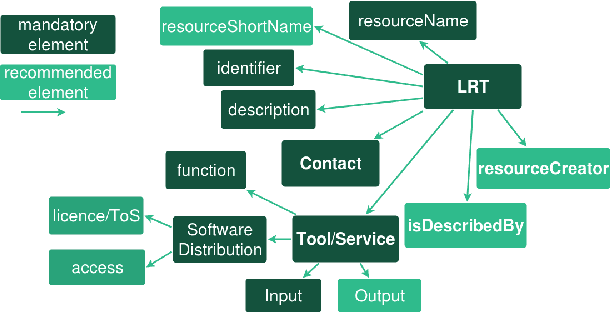

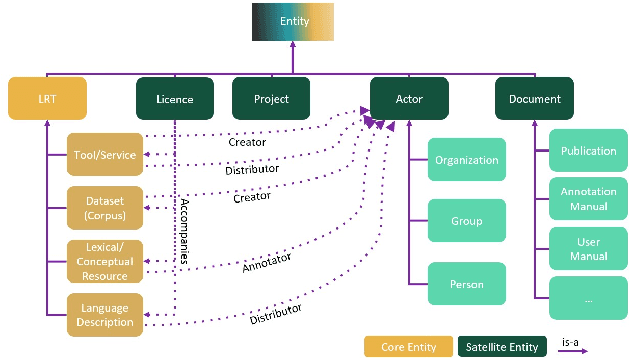
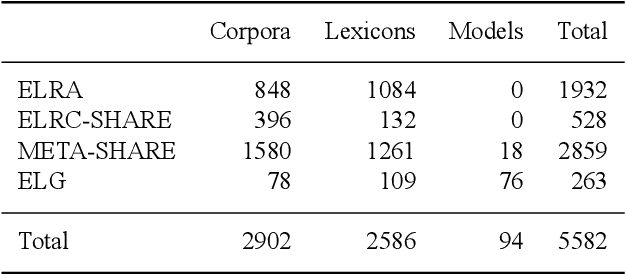
The current scientific and technological landscape is characterised by the increasing availability of data resources and processing tools and services. In this setting, metadata have emerged as a key factor facilitating management, sharing and usage of such digital assets. In this paper we present ELG-SHARE, a rich metadata schema catering for the description of Language Resources and Technologies (processing and generation services and tools, models, corpora, term lists, etc.), as well as related entities (e.g., organizations, projects, supporting documents, etc.). The schema powers the European Language Grid platform that aims to be the primary hub and marketplace for industry-relevant Language Technology in Europe. ELG-SHARE has been based on various metadata schemas, vocabularies, and ontologies, as well as related recommendations and guidelines.
Enriching BERT with Knowledge Graph Embeddings for Document Classification
Sep 18, 2019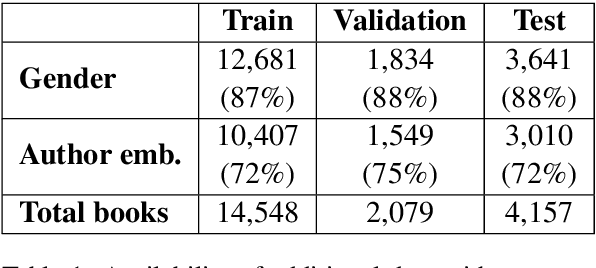
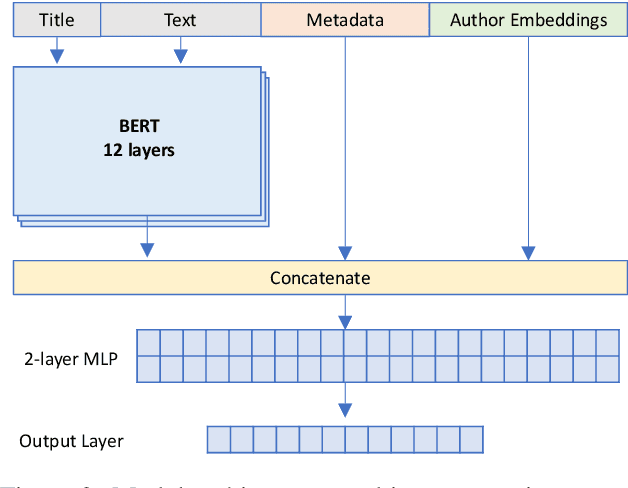
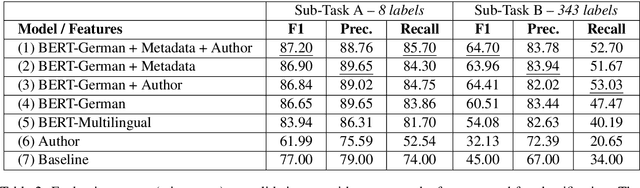
In this paper, we focus on the classification of books using short descriptive texts (cover blurbs) and additional metadata. Building upon BERT, a deep neural language model, we demonstrate how to combine text representations with metadata and knowledge graph embeddings, which encode author information. Compared to the standard BERT approach we achieve considerably better results for the classification task. For a more coarse-grained classification using eight labels we achieve an F1- score of 87.20, while a detailed classification using 343 labels yields an F1-score of 64.70. We make the source code and trained models of our experiments publicly available