 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBio-YODIE: A Named Entity Linking System for Biomedical Text
Nov 12, 2018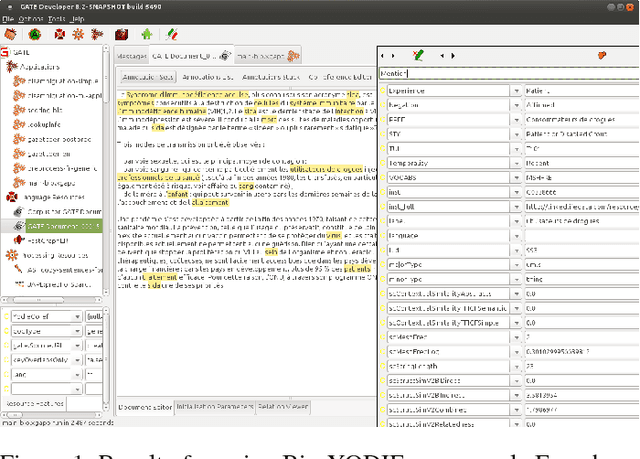


Ever-expanding volumes of biomedical text require automated semantic annotation techniques to curate and put to best use. An established field of research seeks to link mentions in text to knowledge bases such as those included in the UMLS (Unified Medical Language System), in order to enable a more sophisticated understanding. This work has yielded good results for tasks such as curating literature, but increasingly, annotation systems are more broadly applied. Medical vocabularies are expanding in size, and with them the extent of term ambiguity. Document collections are increasing in size and complexity, creating a greater need for speed and robustness. Furthermore, as the technologies are turned to new tasks, requirements change; for example greater coverage of expressions may be required in order to annotate patient records, and greater accuracy may be needed for applications that affect patients. This places new demands on the approaches currently in use. In this work, we present a new system, Bio-YODIE, and compare it to two other popular systems in order to give guidance about suitable approaches in different scenarios and how systems might be designed to accommodate future needs.
RumourEval 2019: Determining Rumour Veracity and Support for Rumours
Sep 18, 2018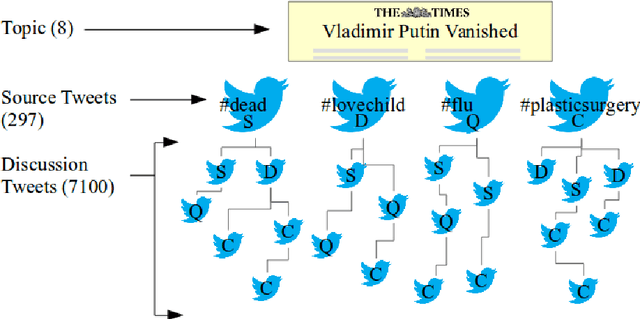
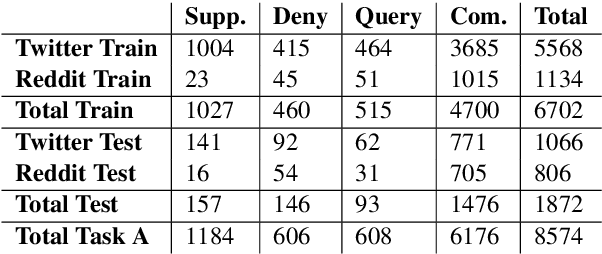
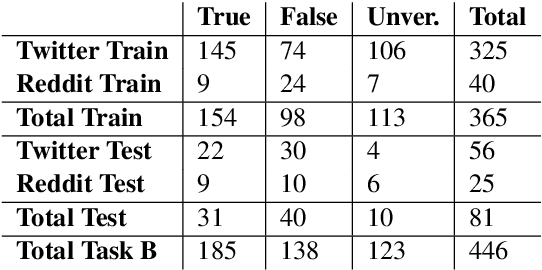
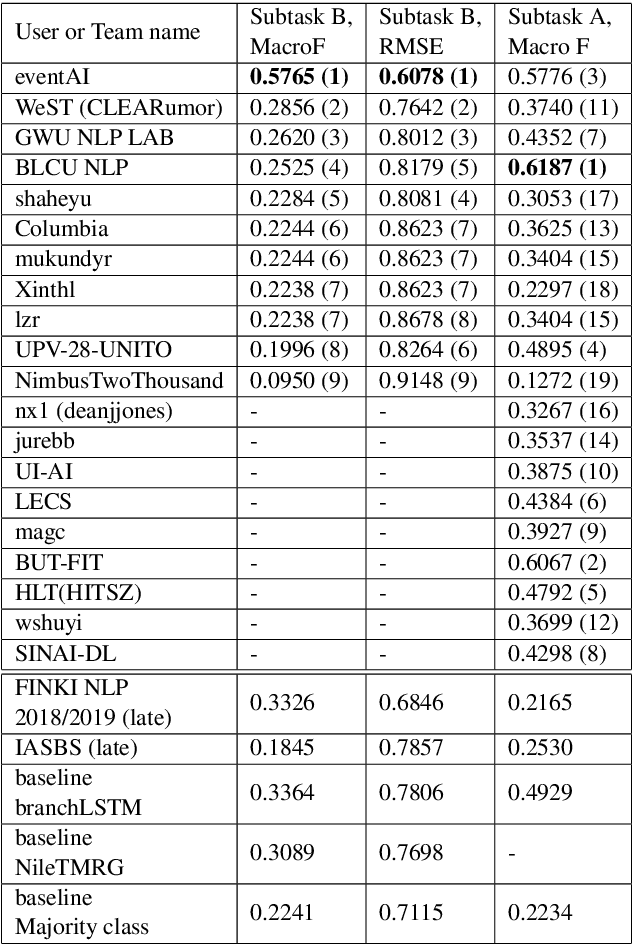
This is the proposal for RumourEval-2019, which will run in early 2019 as part of that year's SemEval event. Since the first RumourEval shared task in 2017, interest in automated claim validation has greatly increased, as the dangers of "fake news" have become a mainstream concern. Yet automated support for rumour checking remains in its infancy. For this reason, it is important that a shared task in this area continues to provide a focus for effort, which is likely to increase. We therefore propose a continuation in which the veracity of further rumours is determined, and as previously, supportive of this goal, tweets discussing them are classified according to the stance they take regarding the rumour. Scope is extended compared with the first RumourEval, in that the dataset is substantially expanded to include Reddit as well as Twitter data, and additional languages are also included.
Analysis of Named Entity Recognition and Linking for Tweets
Oct 27, 2014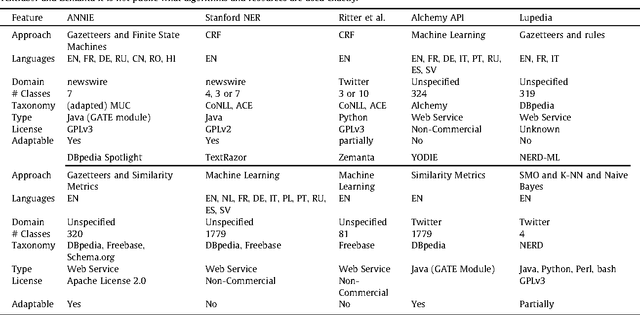
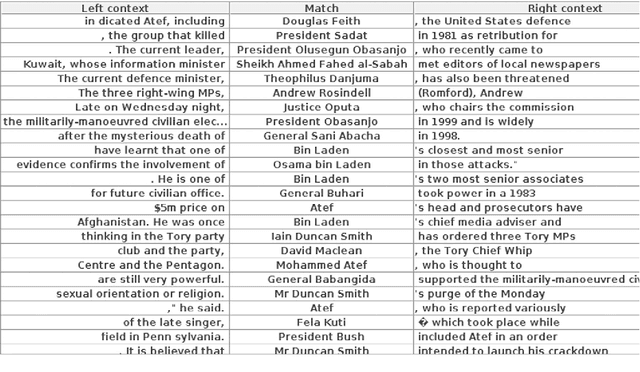

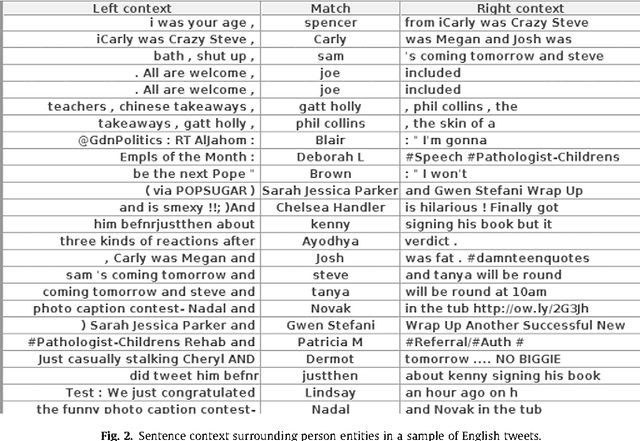
Applying natural language processing for mining and intelligent information access to tweets (a form of microblog) is a challenging, emerging research area. Unlike carefully authored news text and other longer content, tweets pose a number of new challenges, due to their short, noisy, context-dependent, and dynamic nature. Information extraction from tweets is typically performed in a pipeline, comprising consecutive stages of language identification, tokenisation, part-of-speech tagging, named entity recognition and entity disambiguation (e.g. with respect to DBpedia). In this work, we describe a new Twitter entity disambiguation dataset, and conduct an empirical analysis of named entity recognition and disambiguation, investigating how robust a number of state-of-the-art systems are on such noisy texts, what the main sources of error are, and which problems should be further investigated to improve the state of the art.
* 35 pages, accepted to journal Information Processing and Management