 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJuyong Zhang
Lightweight Photometric Stereo for Facial Details Recovery
Mar 27, 2020


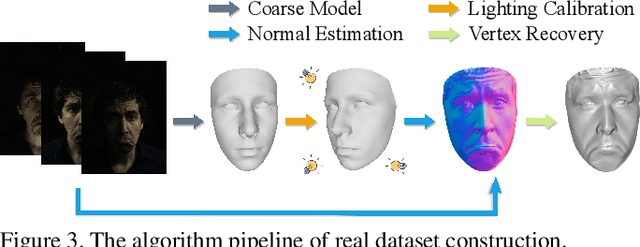
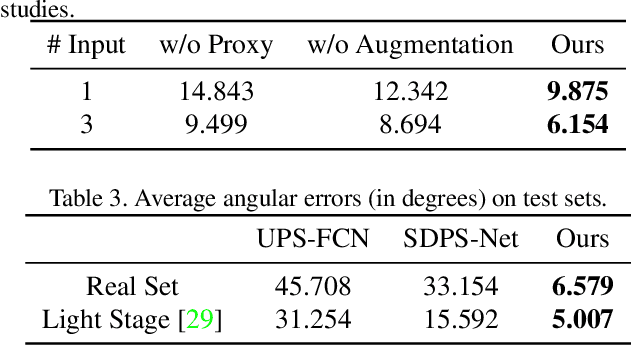
Recently, 3D face reconstruction from a single image has achieved great success with the help of deep learning and shape prior knowledge, but they often fail to produce accurate geometry details. On the other hand, photometric stereo methods can recover reliable geometry details, but require dense inputs and need to solve a complex optimization problem. In this paper, we present a lightweight strategy that only requires sparse inputs or even a single image to recover high-fidelity face shapes with images captured under near-field lights. To this end, we construct a dataset containing 84 different subjects with 29 expressions under 3 different lights. Data augmentation is applied to enrich the data in terms of diversity in identity, lighting, expression, etc. With this constructed dataset, we propose a novel neural network specially designed for photometric stereo based 3D face reconstruction. Extensive experiments and comparisons demonstrate that our method can generate high-quality reconstruction results with one to three facial images captured under near-field lights. Our full framework is available at https://github.com/Juyong/FacePSNet.
3D-CariGAN: An End-to-End Solution to 3D Caricature Generation from Face Photos
Mar 15, 2020

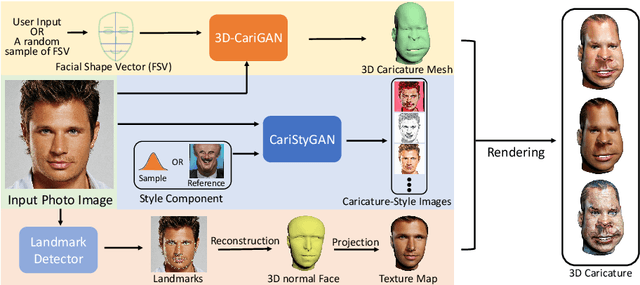
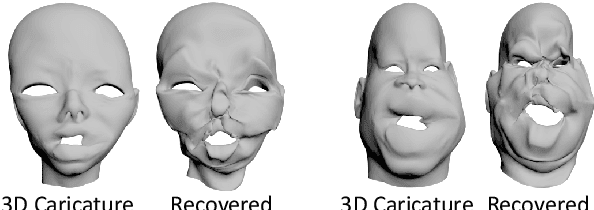
Caricature is a kind of artistic style of human faces that attracts considerable research in computer vision. So far all existing 3D caricature generation methods require some information related to caricature as input, e.g., a caricature sketch or 2D caricature. However, this kind of input is difficult to provide by non-professional users. In this paper, we propose an end-to-end deep neural network model to generate high-quality 3D caricature with a simple face photo as input. The most challenging issue in our system is that the source domain of face photos (characterized by 2D normal faces) is significantly different from the target domain of 3D caricatures (characterized by 3D exaggerated face shapes and texture). To address this challenge, we (1) build a large dataset of 6,100 3D caricature meshes and use it to establish a PCA model in the 3D caricature shape space and (2) detect landmarks in the input face photo and use them to set up correspondence between 2D caricature and 3D caricature shape. Our system can automatically generate high-quality 3D caricatures. In many situations, users want to control the output by a simple and intuitive way, so we further introduce a simple-to-use interactive control with three horizontal and one vertical lines. Experiments and user studies show that our system is easy to use and can generate high-quality 3D caricatures.
Audio-driven Talking Face Video Generation with Learning-based Personalized Head Pose
Mar 05, 2020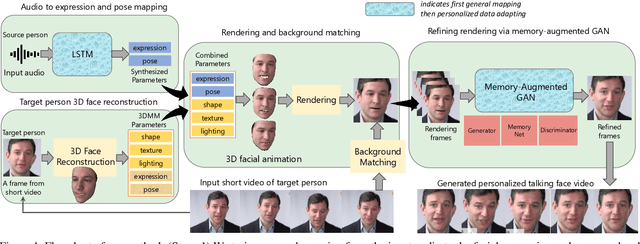
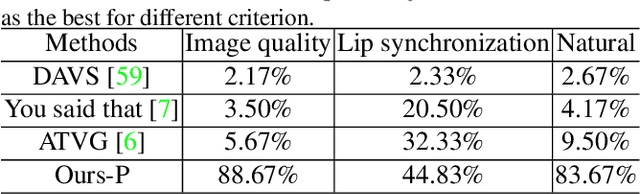
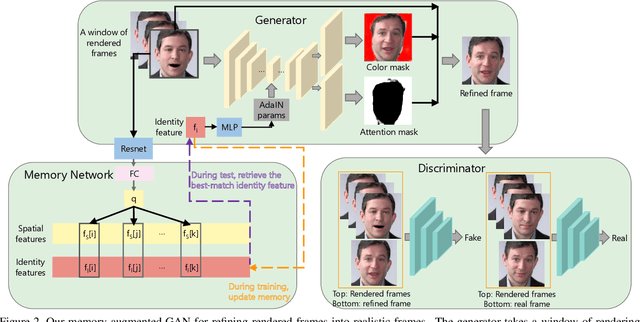
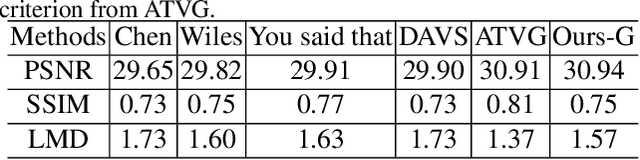
Real-world talking faces often accompany with natural head movement. However, most existing talking face video generation methods only consider facial animation with fixed head pose. In this paper, we address this problem by proposing a deep neural network model that takes an audio signal A of a source person and a very short video V of a target person as input, and outputs a synthesized high-quality talking face video with personalized head pose (making use of the visual information in V), expression and lip synchronization (by considering both A and V). The most challenging issue in our work is that natural poses often cause in-plane and out-of-plane head rotations, which makes synthesized talking face video far from realistic. To address this challenge, we reconstruct 3D face animation and re-render it into synthesized frames. To fine tune these frames into realistic ones with smooth background transition, we propose a novel memory-augmented GAN module. By first training a general mapping based on a publicly available dataset and fine-tuning the mapping using the input short video of target person, we develop an effective strategy that only requires a small number of frames (about 300 frames) to learn personalized talking behavior including head pose. Extensive experiments and two user studies show that our method can generate high-quality (i.e., personalized head movements, expressions and good lip synchronization) talking face videos, which are naturally looking with more distinguishing head movement effects than the state-of-the-art methods.
Audio-driven Talking Face Video Generation with Natural Head Pose
Feb 24, 2020Real-world talking faces often accompany with natural head movement. However, most existing talking face video generation methods only consider facial animation with fixed head pose. In this paper, we address this problem by proposing a deep neural network model that takes an audio signal A of a source person and a very short video V of a target person as input, and outputs a synthesized high-quality talking face video with natural head pose (making use of the visual information in V), expression and lip synchronization (by considering both A and V). The most challenging issue in our work is that natural poses often cause in-plane and out-of-plane head rotations, which makes synthesized talking face video far from realistic. To address this challenge, we reconstruct 3D face animation and re-render it into synthesized frames. To fine tune these frames into realistic ones with smooth background transition, we propose a novel memory-augmented GAN module. Extensive experiments and three user studies show that our method can generate high-quality (i.e., natural head movements, expressions and good lip synchronization) personalized talking face videos, outperforming the state-of-the-art methods.
Bandit Learning for Diversified Interactive Recommendation
Jul 01, 2019
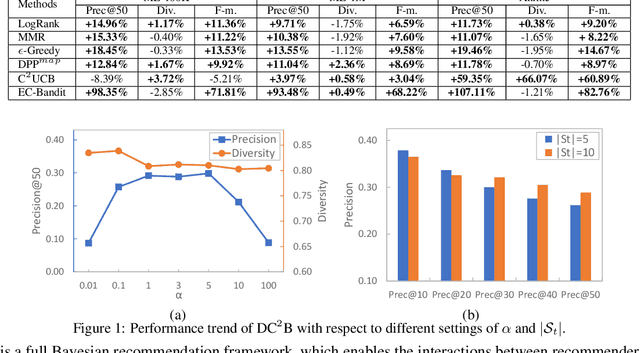
Interactive recommender systems that enable the interactions between users and the recommender system have attracted increasing research attentions. Previous methods mainly focus on optimizing recommendation accuracy. However, they usually ignore the diversity of the recommendation results, thus usually results in unsatisfying user experiences. In this paper, we propose a novel diversified recommendation model, named Diversified Contextual Combinatorial Bandit (DC$^2$B), for interactive recommendation with users' implicit feedback. Specifically, DC$^2$B employs determinantal point process in the recommendation procedure to promote diversity of the recommendation results. To learn the model parameters, a Thompson sampling-type algorithm based on variational Bayesian inference is proposed. In addition, theoretical regret analysis is also provided to guarantee the performance of DC$^2$B. Extensive experiments on real datasets are performed to demonstrate the effectiveness of the proposed method.
3D Magic Mirror: Automatic Video to 3D Caricature Translation
Jun 03, 2019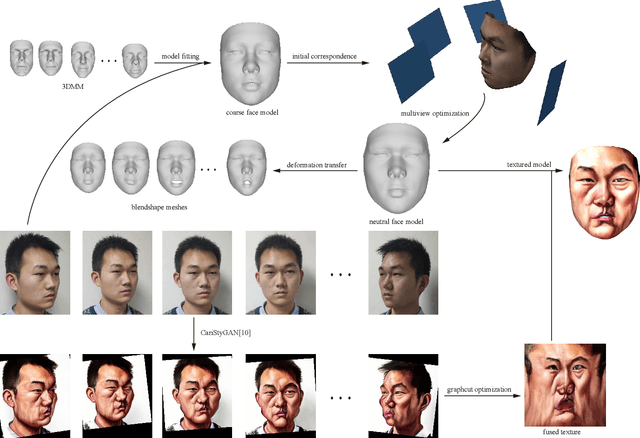
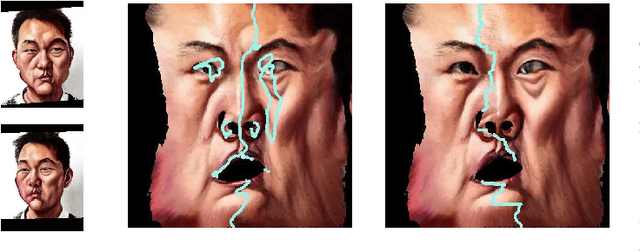
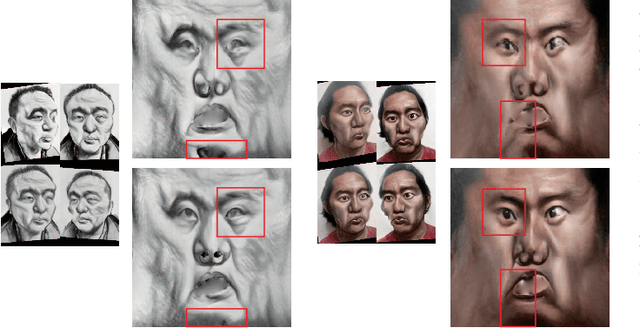
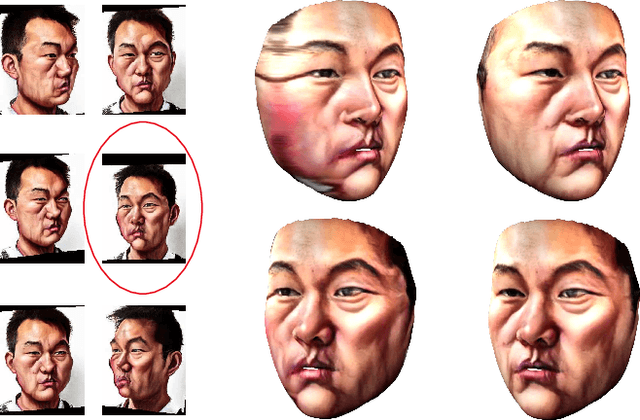
Caricature is an abstraction of a real person which distorts or exaggerates certain features, but still retains a likeness. While most existing works focus on 3D caricature reconstruction from 2D caricatures or translating 2D photos to 2D caricatures, this paper presents a real-time and automatic algorithm for creating expressive 3D caricatures with caricature style texture map from 2D photos or videos. To solve this challenging ill-posed reconstruction problem and cross-domain translation problem, we first reconstruct the 3D face shape for each frame, and then translate 3D face shape from normal style to caricature style by a novel identity and expression preserving VAE-CycleGAN. Based on a labeling formulation, the caricature texture map is constructed from a set of multi-view caricature images generated by CariGANs. The effectiveness and efficiency of our method are demonstrated by comparison with baseline implementations. The perceptual study shows that the 3D caricatures generated by our method meet people's expectations of 3D caricature style.
Learning 3D Human Body Embedding
May 14, 2019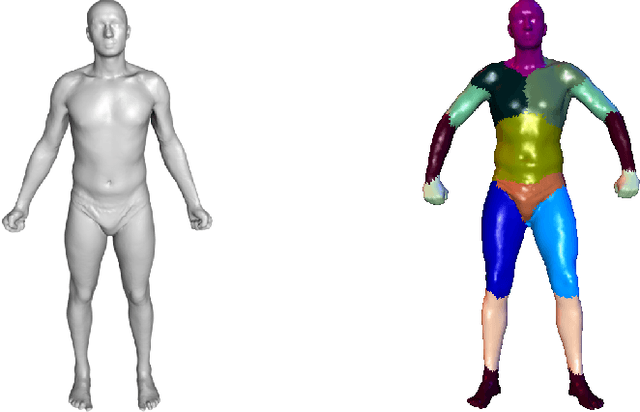
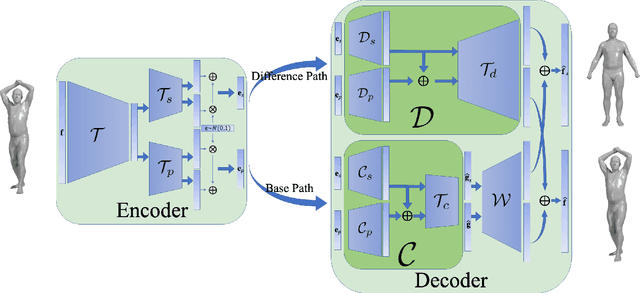
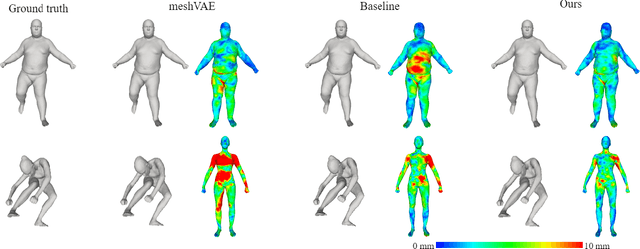

Although human body shapes vary for different identities with different poses, they can be embedded into a low-dimensional space due to their similarity in structure. Inspired by the recent work on latent representation learning with a deformation-based mesh representation, we propose an autoencoder like network architecture to learn disentangled shape and pose embedding specifically for 3D human body. We also integrate a coarse-to-fine reconstruction pipeline into the disentangling process to improve the reconstruction accuracy. Moreover, we construct a large dataset of human body models with consistent topology for the learning of neural network. Our learned embedding can achieve not only superior reconstruction accuracy but also provide great flexibilities in 3D human body creations via interpolation, bilateral interpolation and latent space sampling, which is confirmed by extensive experiments. The constructed dataset and trained model will be made publicly available.
Disentangled Representation Learning for 3D Face Shape
Mar 03, 2019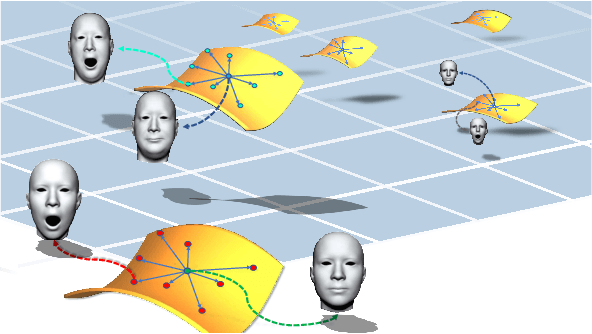
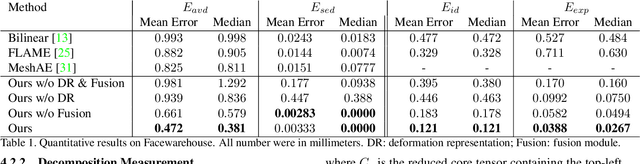
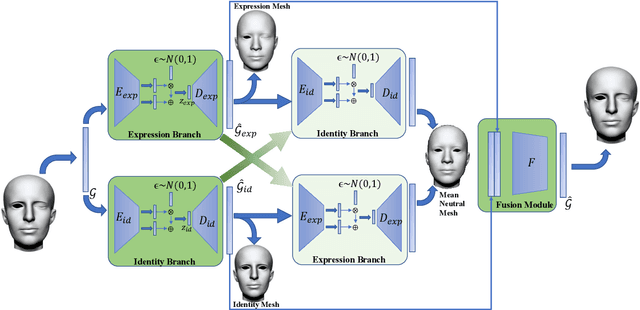
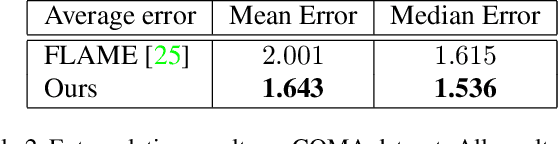
In this paper, we present a novel strategy to design disentangled 3D face shape representation. Specifically, a given 3D face shape is decomposed into identity part and expression part, which are both encoded and decoded in a nonlinear way. To solve this problem, we propose an attribute decomposition framework for 3D face mesh. To better represent face shapes which are usually nonlinear deformed between each other, the face shapes are represented by a vertex based deformation representation rather than Euclidean coordinates. The experimental results demonstrate that our method has better performance than existing methods on decomposing the identity and expression parts. Moreover, more natural expression transfer results can be achieved with our method than existing methods.
Region Deformer Networks for Unsupervised Depth Estimation from Unconstrained Monocular Videos
Feb 26, 2019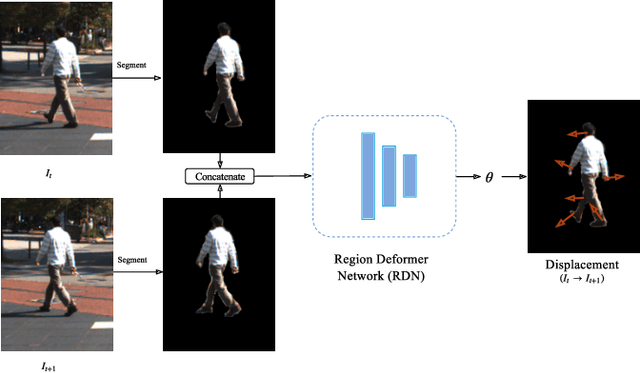
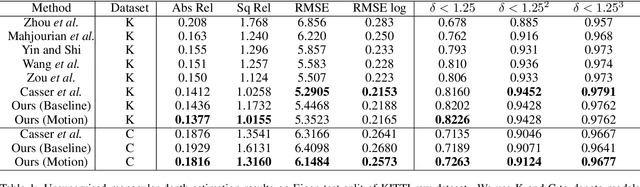
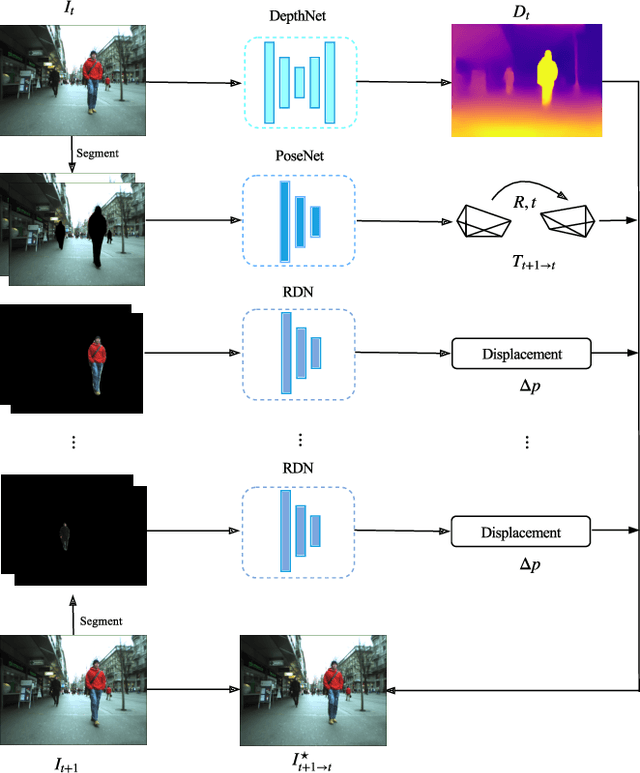

While learning based depth estimation from images/videos has achieved substantial progress, there still exist intrinsic limitations. Supervised methods are limited by small amount of ground truth or labeled data and unsupervised methods for monocular videos are mostly based on the static scene assumption, not performing well on real world scenarios with the presence of dynamic objects. In this paper, we propose a new learning based method consisting of DepthNet, PoseNet and Region Deformer Networks (RDN) to estimate depth from unconstrained monocular videos without ground truth supervision. The core contribution lies in RDN for proper handling of rigid and non-rigid motions of various objects such as rigidly moving cars and deformable humans. In particular, a deformation based motion representation is proposed to model individual object motion on 2D images. This representation enables our method to be applicable to diverse unconstrained monocular videos. Our method can not only achieve the state-of-the-art results on standard benchmarks KITTI and Cityscapes, but also show promising results on a crowded pedestrian tracking dataset, which demonstrates the effectiveness of the deformation based motion representation.
Real-time 3D Face-Eye Performance Capture of a Person Wearing VR Headset
Jan 21, 2019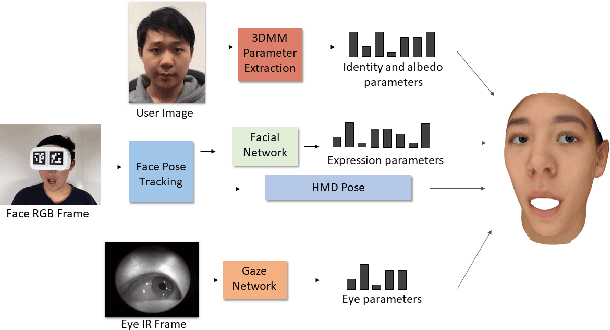
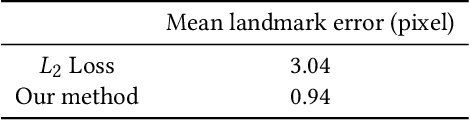

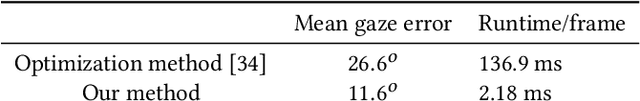
Teleconference or telepresence based on virtual reality (VR) headmount display (HMD) device is a very interesting and promising application since HMD can provide immersive feelings for users. However, in order to facilitate face-to-face communications for HMD users, real-time 3D facial performance capture of a person wearing HMD is needed, which is a very challenging task due to the large occlusion caused by HMD. The existing limited solutions are very complex either in setting or in approach as well as lacking the performance capture of 3D eye gaze movement. In this paper, we propose a convolutional neural network (CNN) based solution for real-time 3D face-eye performance capture of HMD users without complex modification to devices. To address the issue of lacking training data, we generate massive pairs of HMD face-label dataset by data synthesis as well as collecting VR-IR eye dataset from multiple subjects. Then, we train a dense-fitting network for facial region and an eye gaze network to regress 3D eye model parameters. Extensive experimental results demonstrate that our system can efficiently and effectively produce in real time a vivid personalized 3D avatar with the correct identity, pose, expression and eye motion corresponding to the HMD user.