 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlot-VAE: Object-Centric Scene Generation with Slot Attention
Jun 12, 2023Slot attention has shown remarkable object-centric representation learning performance in computer vision tasks without requiring any supervision. Despite its object-centric binding ability brought by compositional modelling, as a deterministic module, slot attention lacks the ability to generate novel scenes. In this paper, we propose the Slot-VAE, a generative model that integrates slot attention with the hierarchical VAE framework for object-centric structured scene generation. For each image, the model simultaneously infers a global scene representation to capture high-level scene structure and object-centric slot representations to embed individual object components. During generation, slot representations are generated from the global scene representation to ensure coherent scene structures. Our extensive evaluation of the scene generation ability indicates that Slot-VAE outperforms slot representation-based generative baselines in terms of sample quality and scene structure accuracy.
MERLIon CCS Challenge Evaluation Plan
May 31, 2023



This paper introduces the inaugural Multilingual Everyday Recordings- Language Identification on Code-Switched Child-Directed Speech (MERLIon CCS) Challenge, focused on developing robust language identification and language diarization systems that are reliable for non-standard, accented, spontaneous code-switched, child-directed speech collected via Zoom. Aligning closely with Interspeech 2023 theme, the main objectives of this inaugural challenge are to present a unique first-of-its-kind Zoom videocall dataset featuring English-Mandarin spontaneous code-switched child-directed speech, benchmark the current and novel language identification and language diarization systems in a code-switching scenario including extremely short utterances, and test the robustness of such systems under accented speech. The MERLIon CCS challenge features two task: language identification (Task 1) and language diarization (Task 2). Two tracks, open and closed, are available for each task, differing by the volume of data systems can be trained on. This paper describes the dataset, dataset annotation protocol, challenge tasks, open and closed tracks, evaluation metrics, and evaluation protocol.
Investigating model performance in language identification: beyond simple error statistics
May 30, 2023Language development experts need tools that can automatically identify languages from fluent, conversational speech, and provide reliable estimates of usage rates at the level of an individual recording. However, language identification systems are typically evaluated on metrics such as equal error rate and balanced accuracy, applied at the level of an entire speech corpus. These overview metrics do not provide information about model performance at the level of individual speakers, recordings, or units of speech with different linguistic characteristics. Overview statistics may therefore mask systematic errors in model performance for some subsets of the data, and consequently, have worse performance on data derived from some subsets of human speakers, creating a kind of algorithmic bias. In the current paper, we investigate how well a number of language identification systems perform on individual recordings and speech units with different linguistic properties in the MERLIon CCS Challenge. The Challenge dataset features accented English-Mandarin code-switched child-directed speech.
MERLIon CCS Challenge: A English-Mandarin code-switching child-directed speech corpus for language identification and diarization
May 30, 2023



To enhance the reliability and robustness of language identification (LID) and language diarization (LD) systems for heterogeneous populations and scenarios, there is a need for speech processing models to be trained on datasets that feature diverse language registers and speech patterns. We present the MERLIon CCS challenge, featuring a first-of-its-kind Zoom video call dataset of parent-child shared book reading, of over 30 hours with over 300 recordings, annotated by multilingual transcribers using a high-fidelity linguistic transcription protocol. The audio corpus features spontaneous and in-the-wild English-Mandarin code-switching, child-directed speech in non-standard accents with diverse language-mixing patterns recorded in a variety of home environments. This report describes the corpus, as well as LID and LD results for our baseline and several systems submitted to the MERLIon CCS challenge using the corpus.
TC-VAE: Uncovering Out-of-Distribution Data Generative Factors
Apr 11, 2023Uncovering data generative factors is the ultimate goal of disentanglement learning. Although many works proposed disentangling generative models able to uncover the underlying generative factors of a dataset, so far no one was able to uncover OOD generative factors (i.e., factors of variations that are not explicitly shown on the dataset). Moreover, the datasets used to validate these models are synthetically generated using a balanced mixture of some predefined generative factors, implicitly assuming that generative factors are uniformly distributed across the datasets. However, real datasets do not present this property. In this work we analyse the effect of using datasets with unbalanced generative factors, providing qualitative and quantitative results for widely used generative models. Moreover, we propose TC-VAE, a generative model optimized using a lower bound of the joint total correlation between the learned latent representations and the input data. We show that the proposed model is able to uncover OOD generative factors on different datasets and outperforms on average the related baselines in terms of downstream disentanglement metrics.
On the Simulation of Perception Errors in Autonomous Vehicles
Feb 23, 2023



Even though virtual testing of Autonomous Vehicles (AVs) has been well recognized as essential for safety assessment, AV simulators are still undergoing active development. One particularly challenging question is to effectively include the Sensing and Perception (S&P) subsystem into the simulation loop. In this article, we define Perception Error Models (PEM), a virtual simulation component that can enable the analysis of the impact of perception errors on AV safety, without the need to model the sensors themselves. We propose a generalized data-driven procedure towards parametric modeling and evaluate it using Apollo, an open-source driving software, and nuScenes, a public AV dataset. Additionally, we implement PEMs in SVL, an open-source vehicle simulator. Furthermore, we demonstrate the usefulness of PEM-based virtual tests, by evaluating camera, LiDAR, and camera-LiDAR setups. Our virtual tests highlight limitations in the current evaluation metrics, and the proposed approach can help study the impact of perception errors on AV safety.
CoPEM: Cooperative Perception Error Models for Autonomous Driving
Nov 22, 2022



In this paper, we introduce the notion of Cooperative Perception Error Models (coPEMs) towards achieving an effective and efficient integration of V2X solutions within a virtual test environment. We focus our analysis on the occlusion problem in the (onboard) perception of Autonomous Vehicles (AV), which can manifest as misdetection errors on the occluded objects. Cooperative perception (CP) solutions based on Vehicle-to-Everything (V2X) communications aim to avoid such issues by cooperatively leveraging additional points of view for the world around the AV. This approach usually requires many sensors, mainly cameras and LiDARs, to be deployed simultaneously in the environment either as part of the road infrastructure or on other traffic vehicles. However, implementing a large number of sensor models in a virtual simulation pipeline is often prohibitively computationally expensive. Therefore, in this paper, we rely on extending Perception Error Models (PEMs) to efficiently implement such cooperative perception solutions along with the errors and uncertainties associated with them. We demonstrate the approach by comparing the safety achievable by an AV challenged with a traffic scenario where occlusion is the primary cause of a potential collision.
Learning to Solve Multiple-TSP with Time Window and Rejections via Deep Reinforcement Learning
Sep 13, 2022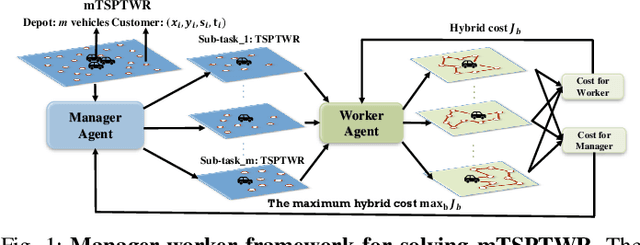
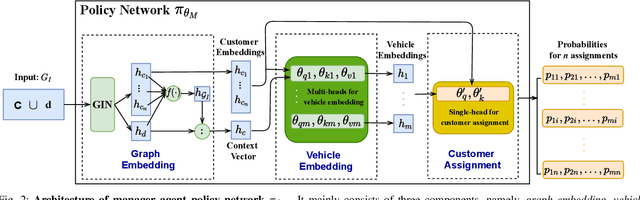
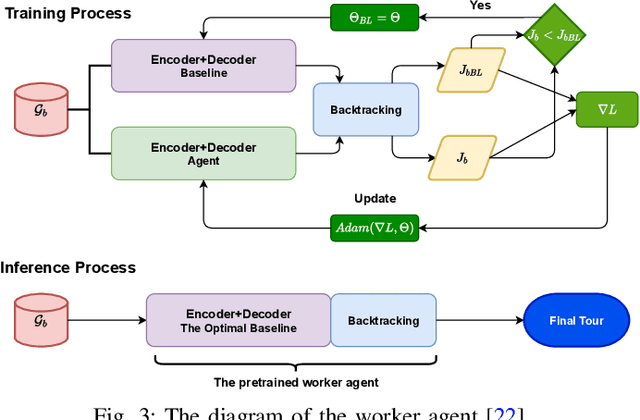
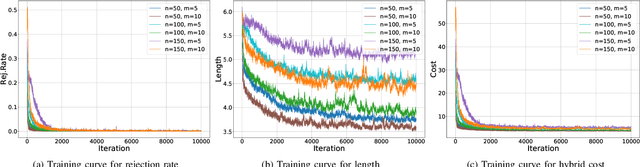
We propose a manager-worker framework based on deep reinforcement learning to tackle a hard yet nontrivial variant of Travelling Salesman Problem (TSP), \ie~multiple-vehicle TSP with time window and rejections (mTSPTWR), where customers who cannot be served before the deadline are subject to rejections. Particularly, in the proposed framework, a manager agent learns to divide mTSPTWR into sub-routing tasks by assigning customers to each vehicle via a Graph Isomorphism Network (GIN) based policy network. A worker agent learns to solve sub-routing tasks by minimizing the cost in terms of both tour length and rejection rate for each vehicle, the maximum of which is then fed back to the manager agent to learn better assignments. Experimental results demonstrate that the proposed framework outperforms strong baselines in terms of higher solution quality and shorter computation time. More importantly, the trained agents also achieve competitive performance for solving unseen larger instances.
Multi-center Assessment of CNN-Transformer with Belief Matching Loss for Patient-independent Seizure Detection in Scalp and Intracranial EEG
Aug 09, 2022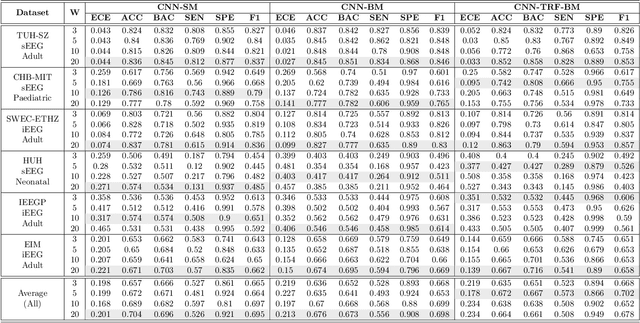
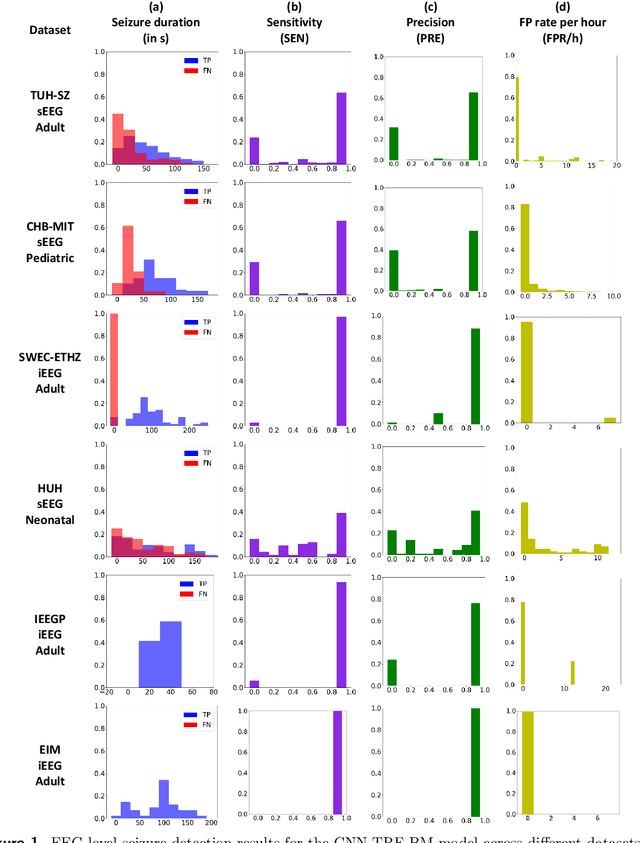
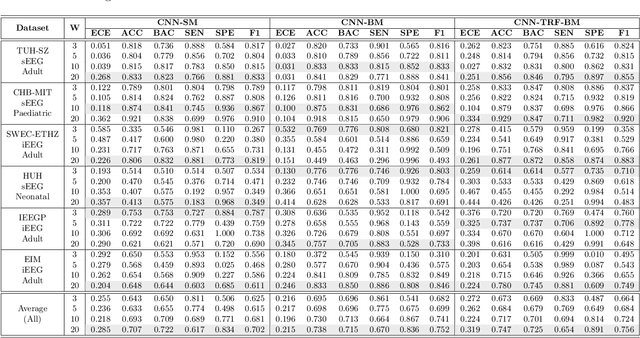
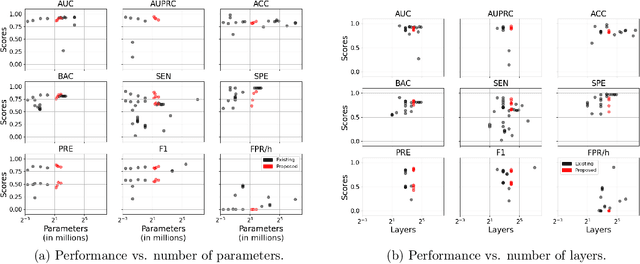
Neurologists typically identify epileptic seizures from electroencephalograms (EEGs) by visual inspection. This process is often time-consuming. To expedite the process, a reliable, automated, and patient-independent seizure detector is essential. However, developing such detector is challenging as seizures exhibit diverse morphologies across patients. In this study, we propose a patient-independent seizure detector to automatically detect seizures in both scalp EEG (sEEG) and intracranial EEG (iEEG). First, we deploy a convolutional neural network (CNN) with transformers and belief matching loss to detect seizures in single-channel EEG segments. Next, we utilized the channel-level outputs to detect seizures in multi-channel EEG segments. At last, we apply postprocessing filters to the segment-level outputs to determine the start and end points of seizures in multi-channel EEGs. We introduce the minimum overlap evaluation scoring (MOES) as an evaluation metric, improving upon existing metrics. We trained the seizure detector on the Temple University Hospital Seizure (TUH-SZ) sEEG dataset and evaluated it on five other independent sEEG and iEEG datasets. On the TUH-SZ dataset, the proposed patient-independent seizure detector achieves a sensitivity (SEN), precision (PRE), average and median false positive rate per hour (aFPR/h and mFPR/h), and median offset of 0.772, 0.429, 4.425, 0, and -2.125s, respectively. Across four adult datasets, we obtained SEN of 0.617-1.00, PRE of 0.534-1.00, aFPR/h of 0.425-2.002, and mFPR/h of 0-1.003. Meanwhile, on neonatal and paediatric datasets, we obtained SEN of 0.227-0.678, PRE of 0.377-0.818, aFPR/h of 0.253-0.421, and mFPR/h of 0.118-0.223. The proposed seizure detector takes less than 15s for a 30 minutes EEG, hence, it could potentially aid the clinicians in identifying seizures expeditiously, allocating more time for devising proper treatment.
Transformer Convolutional Neural Networks for Automated Artifact Detection in Scalp EEG
Aug 04, 2022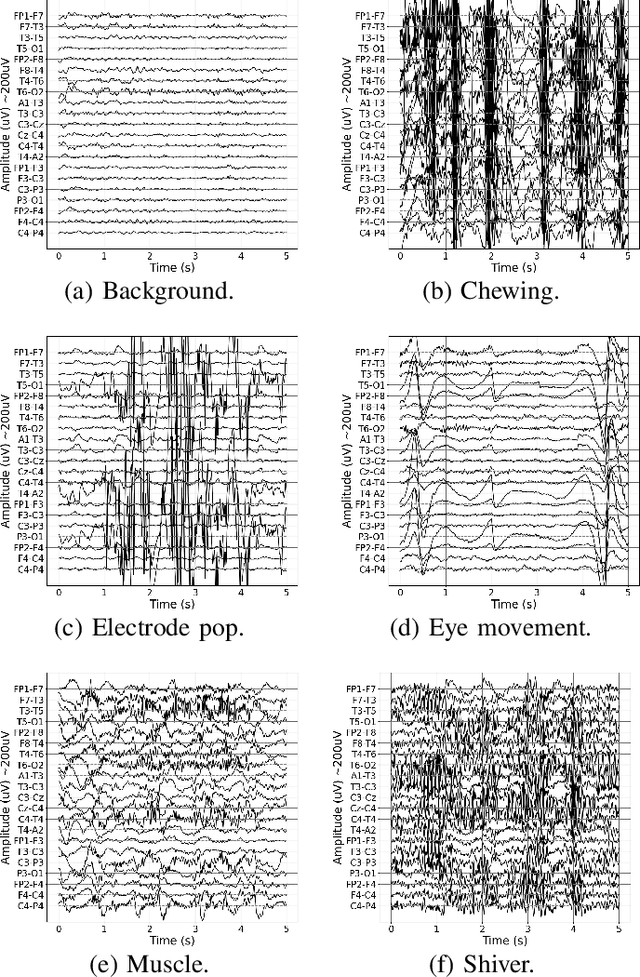
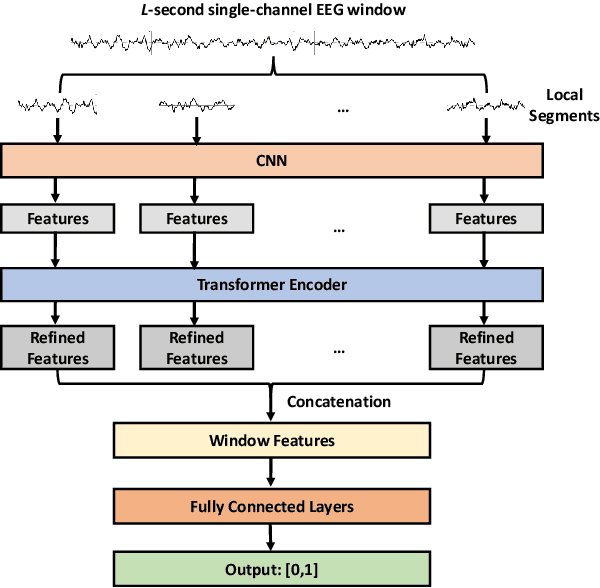
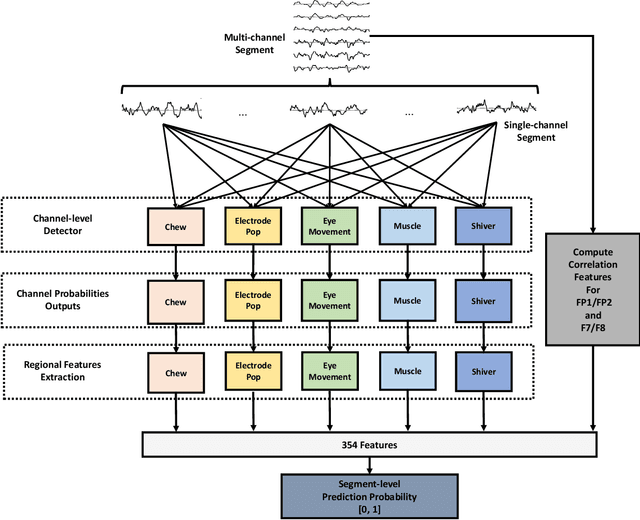
It is well known that electroencephalograms (EEGs) often contain artifacts due to muscle activity, eye blinks, and various other causes. Detecting such artifacts is an essential first step toward a correct interpretation of EEGs. Although much effort has been devoted to semi-automated and automated artifact detection in EEG, the problem of artifact detection remains challenging. In this paper, we propose a convolutional neural network (CNN) enhanced by transformers using belief matching (BM) loss for automated detection of five types of artifacts: chewing, electrode pop, eye movement, muscle, and shiver. Specifically, we apply these five detectors at individual EEG channels to distinguish artifacts from background EEG. Next, for each of these five types of artifacts, we combine the output of these channel-wise detectors to detect artifacts in multi-channel EEG segments. These segment-level classifiers can detect specific artifacts with a balanced accuracy (BAC) of 0.947, 0.735, 0.826, 0.857, and 0.655 for chewing, electrode pop, eye movement, muscle, and shiver artifacts, respectively. Finally, we combine the outputs of the five segment-level detectors to perform a combined binary classification (any artifact vs. background). The resulting detector achieves a sensitivity (SEN) of 60.4%, 51.8%, and 35.5%, at a specificity (SPE) of 95%, 97%, and 99%, respectively. This artifact detection module can reject artifact segments while only removing a small fraction of the background EEG, leading to a cleaner EEG for further analysis.