 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of a motion measurement system for PET imaging studies
Dec 06, 2023Positron Emission Tomography (PET) enables functional imaging of deep brain structures, but the bulk and weight of current systems preclude their use during many natural human activities, such as locomotion. The proposed long-term solution is to construct a robotic system that can support an imaging system surrounding the subject's head, and then move the system to accommodate natural motion. This requires a system to measure the motion of the head with respect to the imaging ring, for use by both the robotic system and the image reconstruction software. We report here the design and experimental evaluation of a parallel string encoder mechanism for sensing this motion. Our preliminary results indicate that the measurement system may achieve accuracy within 0.5 mm, especially for small motions, with improved accuracy possible through kinematic calibration.
Method for robotic motion compensation during PET imaging of mobile subjects
Nov 29, 2023Studies of the human brain during natural activities, such as locomotion, would benefit from the ability to image deep brain structures during these activities. While Positron Emission Tomography (PET) can image these structures, the bulk and weight of current scanners are not compatible with the desire for a wearable device. This has motivated the design of a robotic system to support a PET imaging system around the subject's head and to move the system to accommodate natural motion. We report here the design and experimental evaluation of a prototype robotic system that senses motion of a subject's head, using parallel string encoders connected between the robot-supported imaging ring and a helmet worn by the subject. This measurement is used to robotically move the imaging ring (coarse motion correction) and to compensate for residual motion during image reconstruction (fine motion correction). Minimization of latency and measurement error are the key design goals, respectively, for coarse and fine motion correction. The system is evaluated using recorded human head motions during locomotion, with a mock imaging system consisting of lasers and cameras, and is shown to provide an overall system latency of about 80 ms, which is sufficient for coarse motion correction and collision avoidance, as well as a measurement accuracy of about 0.5 mm for fine motion correction.
Calibration and evaluation of a motion measurement system for PET imaging studies
Nov 29, 2023Positron Emission Tomography (PET) enables functional imaging of deep brain structures, but the bulk and weight of current systems preclude their use during many natural human activities, such as locomotion. The proposed long-term solution is to construct a robotic system that can support an imaging system surrounding the subject's head, and then move the system to accommodate natural motion. This requires a system to measure the motion of the head with respect to the imaging ring, for use by both the robotic system and the image reconstruction software. We report here the design, calibration, and experimental evaluation of a parallel string encoder mechanism for sensing this motion. Our results indicate that with kinematic calibration, the measurement system can achieve accuracy within 0.5mm, especially for small motions.
* arXiv admin note: text overlap with arXiv:2311.17863
Curriculum Learning for Graph Neural Networks: Which Edges Should We Learn First
Oct 28, 2023



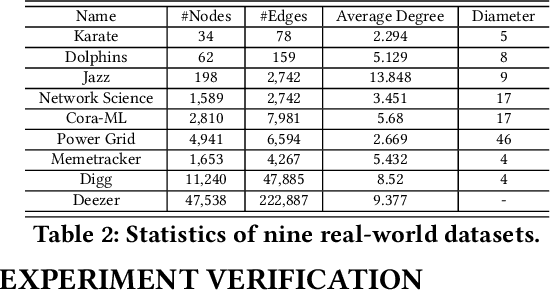
Graph Neural Networks (GNNs) have achieved great success in representing data with dependencies by recursively propagating and aggregating messages along the edges. However, edges in real-world graphs often have varying degrees of difficulty, and some edges may even be noisy to the downstream tasks. Therefore, existing GNNs may lead to suboptimal learned representations because they usually treat every edge in the graph equally. On the other hand, Curriculum Learning (CL), which mimics the human learning principle of learning data samples in a meaningful order, has been shown to be effective in improving the generalization ability and robustness of representation learners by gradually proceeding from easy to more difficult samples during training. Unfortunately, existing CL strategies are designed for independent data samples and cannot trivially generalize to handle data dependencies. To address these issues, we propose a novel CL strategy to gradually incorporate more edges into training according to their difficulty from easy to hard, where the degree of difficulty is measured by how well the edges are expected given the model training status. We demonstrate the strength of our proposed method in improving the generalization ability and robustness of learned representations through extensive experiments on nine synthetic datasets and nine real-world datasets. The code for our proposed method is available at https://github.com/rollingstonezz/Curriculum_learning_for_GNNs.
Beyond One-Model-Fits-All: A Survey of Domain Specialization for Large Language Models
May 31, 2023



Large language models (LLMs) have significantly advanced the field of natural language processing (NLP), providing a highly useful, task-agnostic foundation for a wide range of applications. The great promise of LLMs as general task solvers motivated people to extend their functionality largely beyond just a ``chatbot'', and use it as an assistant or even replacement for domain experts and tools in specific domains such as healthcare, finance, and education. However, directly applying LLMs to solve sophisticated problems in specific domains meets many hurdles, caused by the heterogeneity of domain data, the sophistication of domain knowledge, the uniqueness of domain objectives, and the diversity of the constraints (e.g., various social norms, cultural conformity, religious beliefs, and ethical standards in the domain applications). To fill such a gap, explosively-increase research, and practices have been conducted in very recent years on the domain specialization of LLMs, which, however, calls for a comprehensive and systematic review to better summarizes and guide this promising domain. In this survey paper, first, we propose a systematic taxonomy that categorizes the LLM domain-specialization techniques based on the accessibility to LLMs and summarizes the framework for all the subcategories as well as their relations and differences to each other. We also present a comprehensive taxonomy of critical application domains that can benefit from specialized LLMs, discussing their practical significance and open challenges. Furthermore, we offer insights into the current research status and future trends in this area.
Deep Graph Representation Learning and Optimization for Influence Maximization
May 06, 2023



Influence maximization (IM) is formulated as selecting a set of initial users from a social network to maximize the expected number of influenced users. Researchers have made great progress in designing various traditional methods, and their theoretical design and performance gain are close to a limit. In the past few years, learning-based IM methods have emerged to achieve stronger generalization ability to unknown graphs than traditional ones. However, the development of learning-based IM methods is still limited by fundamental obstacles, including 1) the difficulty of effectively solving the objective function; 2) the difficulty of characterizing the diversified underlying diffusion patterns; and 3) the difficulty of adapting the solution under various node-centrality-constrained IM variants. To cope with the above challenges, we design a novel framework DeepIM to generatively characterize the latent representation of seed sets, and we propose to learn the diversified information diffusion pattern in a data-driven and end-to-end manner. Finally, we design a novel objective function to infer optimal seed sets under flexible node-centrality-based budget constraints. Extensive analyses are conducted over both synthetic and real-world datasets to demonstrate the overall performance of DeepIM. The code and data are available at: https://github.com/triplej0079/DeepIM.
DeepGAR: Deep Graph Learning for Analogical Reasoning
Nov 19, 2022Analogical reasoning is the process of discovering and mapping correspondences from a target subject to a base subject. As the most well-known computational method of analogical reasoning, Structure-Mapping Theory (SMT) abstracts both target and base subjects into relational graphs and forms the cognitive process of analogical reasoning by finding a corresponding subgraph (i.e., correspondence) in the target graph that is aligned with the base graph. However, incorporating deep learning for SMT is still under-explored due to several obstacles: 1) the combinatorial complexity of searching for the correspondence in the target graph; 2) the correspondence mining is restricted by various cognitive theory-driven constraints. To address both challenges, we propose a novel framework for Analogical Reasoning (DeepGAR) that identifies the correspondence between source and target domains by assuring cognitive theory-driven constraints. Specifically, we design a geometric constraint embedding space to induce subgraph relation from node embeddings for efficient subgraph search. Furthermore, we develop novel learning and optimization strategies that could end-to-end identify correspondences that are strictly consistent with constraints driven by the cognitive theory. Extensive experiments are conducted on synthetic and real-world datasets to demonstrate the effectiveness of the proposed DeepGAR over existing methods.
Source Localization of Graph Diffusion via Variational Autoencoders for Graph Inverse Problems
Jun 24, 2022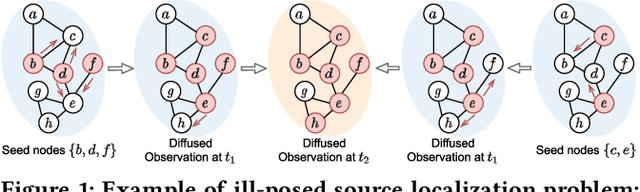
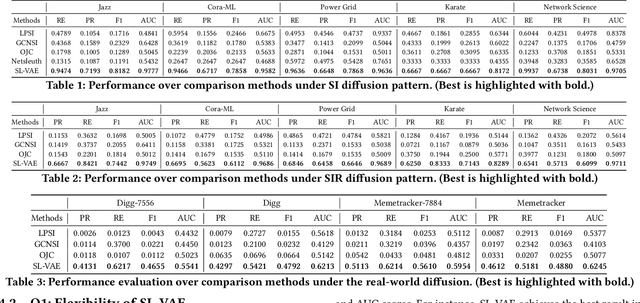
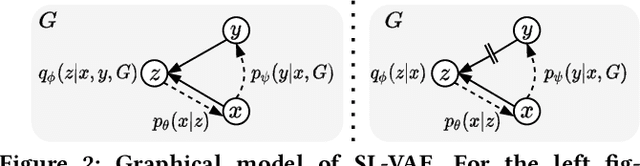

Graph diffusion problems such as the propagation of rumors, computer viruses, or smart grid failures are ubiquitous and societal. Hence it is usually crucial to identify diffusion sources according to the current graph diffusion observations. Despite its tremendous necessity and significance in practice, source localization, as the inverse problem of graph diffusion, is extremely challenging as it is ill-posed: different sources may lead to the same graph diffusion patterns. Different from most traditional source localization methods, this paper focuses on a probabilistic manner to account for the uncertainty of different candidate sources. Such endeavors require overcoming challenges including 1) the uncertainty in graph diffusion source localization is hard to be quantified; 2) the complex patterns of the graph diffusion sources are difficult to be probabilistically characterized; 3) the generalization under any underlying diffusion patterns is hard to be imposed. To solve the above challenges, this paper presents a generic framework: Source Localization Variational AutoEncoder (SL-VAE) for locating the diffusion sources under arbitrary diffusion patterns. Particularly, we propose a probabilistic model that leverages the forward diffusion estimation model along with deep generative models to approximate the diffusion source distribution for quantifying the uncertainty. SL-VAE further utilizes prior knowledge of the source-observation pairs to characterize the complex patterns of diffusion sources by a learned generative prior. Lastly, a unified objective that integrates the forward diffusion estimation model is derived to enforce the model to generalize under arbitrary diffusion patterns. Extensive experiments are conducted on 7 real-world datasets to demonstrate the superiority of SL-VAE in reconstructing the diffusion sources by excelling other methods on average 20% in AUC score.
An Invertible Graph Diffusion Neural Network for Source Localization
Jun 18, 2022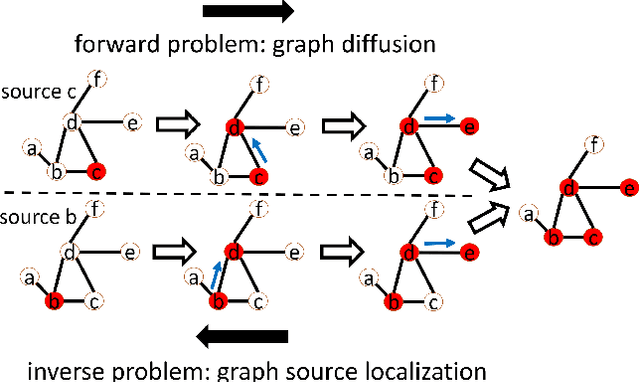

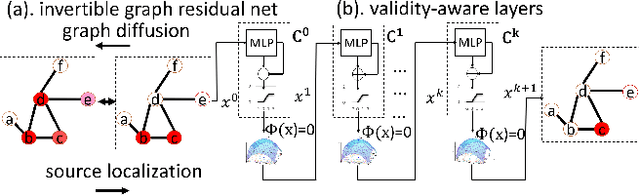
Localizing the source of graph diffusion phenomena, such as misinformation propagation, is an important yet extremely challenging task. Existing source localization models typically are heavily dependent on the hand-crafted rules. Unfortunately, a large portion of the graph diffusion process for many applications is still unknown to human beings so it is important to have expressive models for learning such underlying rules automatically. This paper aims to establish a generic framework of invertible graph diffusion models for source localization on graphs, namely Invertible Validity-aware Graph Diffusion (IVGD), to handle major challenges including 1) Difficulty to leverage knowledge in graph diffusion models for modeling their inverse processes in an end-to-end fashion, 2) Difficulty to ensure the validity of the inferred sources, and 3) Efficiency and scalability in source inference. Specifically, first, to inversely infer sources of graph diffusion, we propose a graph residual scenario to make existing graph diffusion models invertible with theoretical guarantees; second, we develop a novel error compensation mechanism that learns to offset the errors of the inferred sources. Finally, to ensure the validity of the inferred sources, a new set of validity-aware layers have been devised to project inferred sources to feasible regions by flexibly encoding constraints with unrolled optimization techniques. A linearization technique is proposed to strengthen the efficiency of our proposed layers. The convergence of the proposed IVGD is proven theoretically. Extensive experiments on nine real-world datasets demonstrate that our proposed IVGD outperforms state-of-the-art comparison methods significantly. We have released our code at https://github.com/xianggebenben/IVGD.
Do Multi-Lingual Pre-trained Language Models Reveal Consistent Token Attributions in Different Languages?
Dec 23, 2021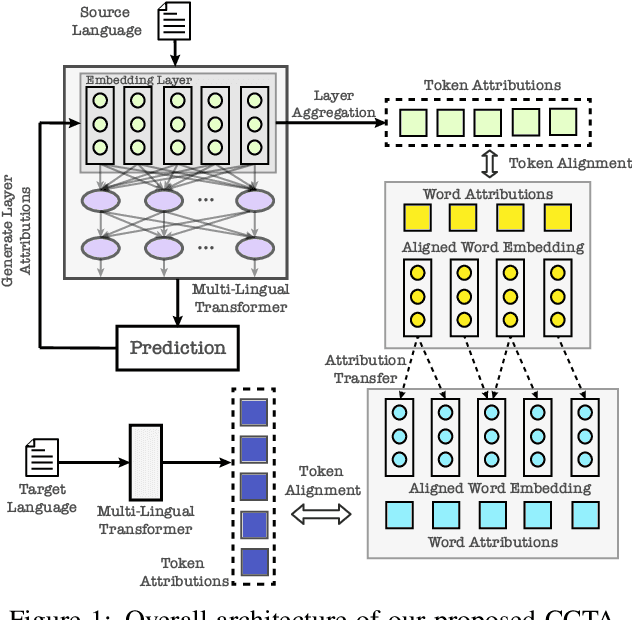
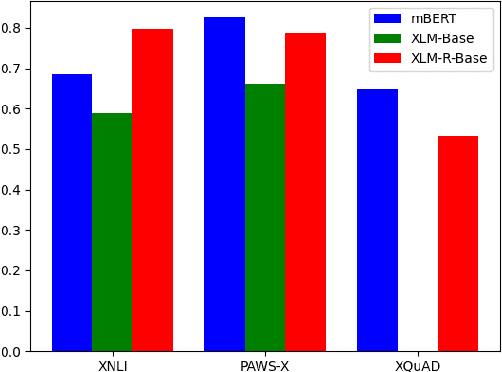
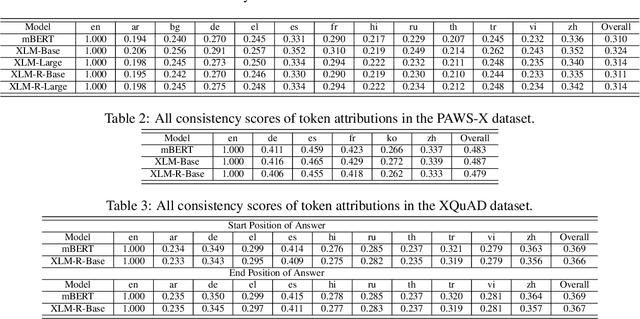
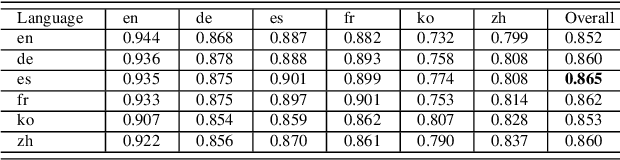
During the past several years, a surge of multi-lingual Pre-trained Language Models (PLMs) has been proposed to achieve state-of-the-art performance in many cross-lingual downstream tasks. However, the understanding of why multi-lingual PLMs perform well is still an open domain. For example, it is unclear whether multi-Lingual PLMs reveal consistent token attributions in different languages. To address this, in this paper, we propose a Cross-lingual Consistency of Token Attributions (CCTA) evaluation framework. Extensive experiments in three downstream tasks demonstrate that multi-lingual PLMs assign significantly different attributions to multi-lingual synonyms. Moreover, we have the following observations: 1) the Spanish achieves the most consistent token attributions in different languages when it is used for training PLMs; 2) the consistency of token attributions strongly correlates with performance in downstream tasks.