 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Mean Estimation under Quantization
Jan 11, 2026We consider the problem of mean estimation under quantization and adversarial corruption. We construct multivariate robust estimators that are optimal up to logarithmic factors in two different settings. The first is a one-bit setting, where each bit depends only on a single sample, and the second is a partial quantization setting, in which the estimator may use a small fraction of unquantized data.
Phase Transitions in Phase-Only Compressed Sensing
Jan 21, 2025The goal of phase-only compressed sensing is to recover a structured signal $\mathbf{x}$ from the phases $\mathbf{z} = {\rm sign}(\mathbf{\Phi}\mathbf{x})$ under some complex-valued sensing matrix $\mathbf{\Phi}$. Exact reconstruction of the signal's direction is possible: we can reformulate it as a linear compressed sensing problem and use basis pursuit (i.e., constrained norm minimization). For $\mathbf{\Phi}$ with i.i.d. complex-valued Gaussian entries, this paper shows that the phase transition is approximately located at the statistical dimension of the descent cone of a signal-dependent norm. Leveraging this insight, we derive asymptotically precise formulas for the phase transition locations in phase-only sensing of both sparse signals and low-rank matrices. Our results prove that the minimum number of measurements required for exact recovery is smaller for phase-only measurements than for traditional linear compressed sensing. For instance, in recovering a 1-sparse signal with sufficiently large dimension, phase-only compressed sensing requires approximately 68% of the measurements needed for linear compressed sensing. This result disproves earlier conjecture suggesting that the two phase transitions coincide. Our proof hinges on the Gaussian min-max theorem and the key observation that, up to a signal-dependent orthogonal transformation, the sensing matrix in the reformulated problem behaves as a nearly Gaussian matrix.
Interactive Medical Image Segmentation: A Benchmark Dataset and Baseline
Nov 19, 2024Interactive Medical Image Segmentation (IMIS) has long been constrained by the limited availability of large-scale, diverse, and densely annotated datasets, which hinders model generalization and consistent evaluation across different models. In this paper, we introduce the IMed-361M benchmark dataset, a significant advancement in general IMIS research. First, we collect and standardize over 6.4 million medical images and their corresponding ground truth masks from multiple data sources. Then, leveraging the strong object recognition capabilities of a vision foundational model, we automatically generated dense interactive masks for each image and ensured their quality through rigorous quality control and granularity management. Unlike previous datasets, which are limited by specific modalities or sparse annotations, IMed-361M spans 14 modalities and 204 segmentation targets, totaling 361 million masks-an average of 56 masks per image. Finally, we developed an IMIS baseline network on this dataset that supports high-quality mask generation through interactive inputs, including clicks, bounding boxes, text prompts, and their combinations. We evaluate its performance on medical image segmentation tasks from multiple perspectives, demonstrating superior accuracy and scalability compared to existing interactive segmentation models. To facilitate research on foundational models in medical computer vision, we release the IMed-361M and model at https://github.com/uni-medical/IMIS-Bench.
Generalized Eigenvalue Problems with Generative Priors
Nov 02, 2024Generalized eigenvalue problems (GEPs) find applications in various fields of science and engineering. For example, principal component analysis, Fisher's discriminant analysis, and canonical correlation analysis are specific instances of GEPs and are widely used in statistical data processing. In this work, we study GEPs under generative priors, assuming that the underlying leading generalized eigenvector lies within the range of a Lipschitz continuous generative model. Under appropriate conditions, we show that any optimal solution to the corresponding optimization problems attains the optimal statistical rate. Moreover, from a computational perspective, we propose an iterative algorithm called the Projected Rayleigh Flow Method (PRFM) to approximate the optimal solution. We theoretically demonstrate that under suitable assumptions, PRFM converges linearly to an estimated vector that achieves the optimal statistical rate. Numerical results are provided to demonstrate the effectiveness of the proposed method.
TEXEL: A neuromorphic processor with on-chip learning for beyond-CMOS device integration
Oct 21, 2024



Recent advances in memory technologies, devices and materials have shown great potential for integration into neuromorphic electronic systems. However, a significant gap remains between the development of these materials and the realization of large-scale, fully functional systems. One key challenge is determining which devices and materials are best suited for specific functions and how they can be paired with CMOS circuitry. To address this, we introduce TEXEL, a mixed-signal neuromorphic architecture designed to explore the integration of on-chip learning circuits and novel two- and three-terminal devices. TEXEL serves as an accessible platform to bridge the gap between CMOS-based neuromorphic computation and the latest advancements in emerging devices. In this paper, we demonstrate the readiness of TEXEL for device integration through comprehensive chip measurements and simulations. TEXEL provides a practical system for testing bio-inspired learning algorithms alongside emerging devices, establishing a tangible link between brain-inspired computation and cutting-edge device research.
Robust Instance Optimal Phase-Only Compressed Sensing
Aug 12, 2024Phase-only compressed sensing (PO-CS) is concerned with the recovery of structured signals from the phases of complex measurements. Recent results show that structured signals in the standard sphere $\mathbb{S}^{n-1}$ can be exactly recovered from complex Gaussian phases, by recasting PO-CS as linear compressed sensing and then applying existing solvers such as basis pursuit. Known guarantees are either non-uniform or do not tolerate model error. We show that this linearization approach is more powerful than the prior results indicate. First, it achieves uniform instance optimality: Under complex Gaussian matrix with a near-optimal number of rows, this approach uniformly recovers all signals in $\mathbb{S}^{n-1}$ with errors proportional to the model errors of the signals. Specifically, for sparse recovery there exists an efficient estimator $\mathbf{x}^\sharp$ and some universal constant $C$ such that $\|\mathbf{x}^\sharp-\mathbf{x}\|_2\le \frac{C\sigma_s(\mathbf{x})_1}{\sqrt{s}}~(\forall\mathbf{x}\in\mathbb{S}^{n-1})$, where $\sigma_s(\mathbf{x})_1=\min_{\mathbf{u}\in\Sigma^n_s}\|\mathbf{u}-\mathbf{x}\|_1$ is the model error under $\ell_1$-norm. Second, the instance optimality is robust to small dense disturbances and sparse corruptions that arise before or after capturing the phases. As an extension, we also propose to recast sparsely corrupted PO-CS as a linear corrupted sensing problem and show that this achieves perfect reconstruction of the signals. Our results resemble the instance optimal guarantees in linear compressed sensing and, to our knowledge, are the first results of this kind for a non-linear sensing scenario.
Distributed Representations Enable Robust Multi-Timescale Computation in Neuromorphic Hardware
May 02, 2024



Programming recurrent spiking neural networks (RSNNs) to robustly perform multi-timescale computation remains a difficult challenge. To address this, we show how the distributed approach offered by vector symbolic architectures (VSAs), which uses high-dimensional random vectors as the smallest units of representation, can be leveraged to embed robust multi-timescale dynamics into attractor-based RSNNs. We embed finite state machines into the RSNN dynamics by superimposing a symmetric autoassociative weight matrix and asymmetric transition terms. The transition terms are formed by the VSA binding of an input and heteroassociative outer-products between states. Our approach is validated through simulations with highly non-ideal weights; an experimental closed-loop memristive hardware setup; and on Loihi 2, where it scales seamlessly to large state machines. This work demonstrates the effectiveness of VSA representations for embedding robust computation with recurrent dynamics into neuromorphic hardware, without requiring parameter fine-tuning or significant platform-specific optimisation. This advances VSAs as a high-level representation-invariant abstract language for cognitive algorithms in neuromorphic hardware.
Uniform Recovery Guarantees for Quantized Corrupted Sensing Using Structured or Generative Priors
Jan 16, 2024This paper studies quantized corrupted sensing where the measurements are contaminated by unknown corruption and then quantized by a dithered uniform quantizer. We establish uniform guarantees for Lasso that ensure the accurate recovery of all signals and corruptions using a single draw of the sub-Gaussian sensing matrix and uniform dither. For signal and corruption with structured priors (e.g., sparsity, low-rankness), our uniform error rate for constrained Lasso typically coincides with the non-uniform one [Sun, Cui and Liu, 2022] up to logarithmic factors. By contrast, our uniform error rate for unconstrained Lasso exhibits worse dependence on the structured parameters due to regularization parameters larger than the ones for non-uniform recovery. For signal and corruption living in the ranges of some Lipschitz continuous generative models (referred to as generative priors), we achieve uniform recovery via constrained Lasso with a measurement number proportional to the latent dimensions of the generative models. Our treatments to the two kinds of priors are (nearly) unified and share the common key ingredients of (global) quantized product embedding (QPE) property, which states that the dithered uniform quantization (universally) preserves inner product. As a by-product, our QPE result refines the one in [Xu and Jacques, 2020] under sub-Gaussian random matrix, and in this specific instance we are able to sharpen the uniform error decaying rate (for the projected-back projection estimator with signals in some convex symmetric set) presented therein from $O(m^{-1/16})$ to $O(m^{-1/8})$.
Solving Quadratic Systems with Full-Rank Matrices Using Sparse or Generative Priors
Sep 16, 2023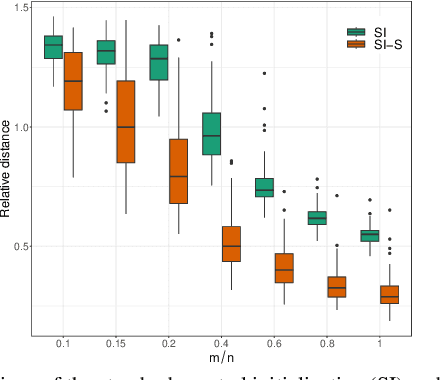
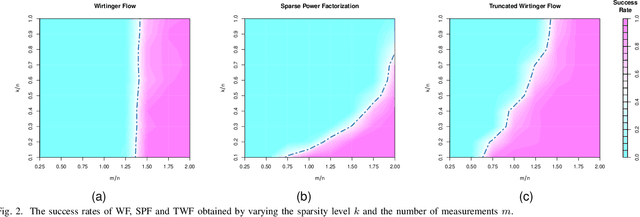

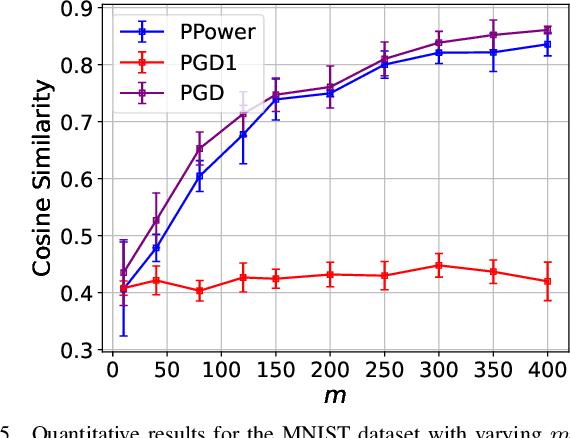
The problem of recovering a signal $\boldsymbol{x} \in \mathbb{R}^n$ from a quadratic system $\{y_i=\boldsymbol{x}^\top\boldsymbol{A}_i\boldsymbol{x},\ i=1,\ldots,m\}$ with full-rank matrices $\boldsymbol{A}_i$ frequently arises in applications such as unassigned distance geometry and sub-wavelength imaging. With i.i.d. standard Gaussian matrices $\boldsymbol{A}_i$, this paper addresses the high-dimensional case where $m\ll n$ by incorporating prior knowledge of $\boldsymbol{x}$. First, we consider a $k$-sparse $\boldsymbol{x}$ and introduce the thresholded Wirtinger flow (TWF) algorithm that does not require the sparsity level $k$. TWF comprises two steps: the spectral initialization that identifies a point sufficiently close to $\boldsymbol{x}$ (up to a sign flip) when $m=O(k^2\log n)$, and the thresholded gradient descent (with a good initialization) that produces a sequence linearly converging to $\boldsymbol{x}$ with $m=O(k\log n)$ measurements. Second, we explore the generative prior, assuming that $\boldsymbol{x}$ lies in the range of an $L$-Lipschitz continuous generative model with $k$-dimensional inputs in an $\ell_2$-ball of radius $r$. We develop the projected gradient descent (PGD) algorithm that also comprises two steps: the projected power method that provides an initial vector with $O\big(\sqrt{\frac{k \log L}{m}}\big)$ $\ell_2$-error given $m=O(k\log(Lnr))$ measurements, and the projected gradient descent that refines the $\ell_2$-error to $O(\delta)$ at a geometric rate when $m=O(k\log\frac{Lrn}{\delta^2})$. Experimental results corroborate our theoretical findings and show that: (i) our approach for the sparse case notably outperforms the existing provable algorithm sparse power factorization; (ii) leveraging the generative prior allows for precise image recovery in the MNIST dataset from a small number of quadratic measurements.
A Parameter-Free Two-Bit Covariance Estimator with Improved Operator Norm Error Rate
Aug 30, 2023A covariance matrix estimator using two bits per entry was recently developed by Dirksen, Maly and Rauhut [Annals of Statistics, 50(6), pp. 3538-3562]. The estimator achieves near minimax rate for general sub-Gaussian distributions, but also suffers from two downsides: theoretically, there is an essential gap on operator norm error between their estimator and sample covariance when the diagonal of the covariance matrix is dominated by only a few entries; practically, its performance heavily relies on the dithering scale, which needs to be tuned according to some unknown parameters. In this work, we propose a new 2-bit covariance matrix estimator that simultaneously addresses both issues. Unlike the sign quantizer associated with uniform dither in Dirksen et al., we adopt a triangular dither prior to a 2-bit quantizer inspired by the multi-bit uniform quantizer. By employing dithering scales varying across entries, our estimator enjoys an improved operator norm error rate that depends on the effective rank of the underlying covariance matrix rather than the ambient dimension, thus closing the theoretical gap. Moreover, our proposed method eliminates the need of any tuning parameter, as the dithering scales are entirely determined by the data. Experimental results under Gaussian samples are provided to showcase the impressive numerical performance of our estimator. Remarkably, by halving the dithering scales, our estimator oftentimes achieves operator norm errors less than twice of the errors of sample covariance.