 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyCoRM: Dynamic Criterion-Aware Reward Modeling for Text-to-Image Generation
May 25, 2026With the continued advancement of text-to-image (T2I) generation, producing high-quality images is becoming increasingly attainable; consequently, user demands are shifting toward images that better satisfy their specific requirements. As reward models play an increasingly important role in assessing whether generated images align with user preference, this trend introduces an important challenge for reward modeling: rather than relying solely on static and general evaluation dimensions, reward models should account for the task-relevant and fine-grained criteria through which users assess whether generated images meet their specific requirements. To address this challenge, we propose DyCoRM, a dynamic, criterion-aware reward model that grounds task-relevant criteria and performs criterion-aware preference comparison. To support this setting, we construct DyCoDataset-20K, which provides dynamic criteria together with criterion-level annotations, and further derive DyCoBench-1K, a benchmark for systematically evaluating reward models under dynamic criteria. We further introduce DyCoPick, which applies criterion-aware reward modeling to selecting T2I images. Our contributions establish the first reward modeling framework for dynamic and fine-grained evaluation and practical application in T2I generation.
Relevance Feedback in Text-to-Image Diffusion: A Training-Free And Model-Agnostic Interactive Framework
Mar 16, 2026Text-to-image generation using diffusion models has achieved remarkable success. However, users often possess clear visual intents but struggle to express them precisely in language, resulting in ambiguous prompts and misaligned images. Existing methods struggle to bridge this gap, typically relying on high-load textual dialogues, opaque black-box inferences, or expensive fine-tuning. They fail to simultaneously achieve low cognitive load, interpretable preference inference, and remain training-free and model-agnostic. To address this, we propose RFD, an interactive framework that adapts the relevance feedback mechanism from information retrieval to diffusion models. In RFD, users replace explicit textual dialogue with implicit, multi-select visual feedback to minimize cognitive load, easily expressing complex, multi-dimensional preferences. To translate feedback into precise generative guidance, we construct an expert-curated feature repository and introduce an information-theoretic weighted cumulative preference analysis. This white-box method calculates preferences from current-round feedback and incrementally accumulates them, avoiding the concatenation of historical interactions and preventing inference degradation caused by lengthy contexts. Furthermore, RFD employs a probabilistic sampling mechanism for prompt reconstruction to balance exploitation and exploration, preventing output homogenization. Crucially, RFD operates entirely within the external text space, making it strictly training-free and model-agnostic as a universal plug-and-play solution. Extensive experiments demonstrate that RFD effectively captures the user's true visual intent, significantly outperforming baselines in preference alignment.
Compromising Embodied Agents with Contextual Backdoor Attacks
Aug 06, 2024



Large language models (LLMs) have transformed the development of embodied intelligence. By providing a few contextual demonstrations, developers can utilize the extensive internal knowledge of LLMs to effortlessly translate complex tasks described in abstract language into sequences of code snippets, which will serve as the execution logic for embodied agents. However, this paper uncovers a significant backdoor security threat within this process and introduces a novel method called \method{}. By poisoning just a few contextual demonstrations, attackers can covertly compromise the contextual environment of a black-box LLM, prompting it to generate programs with context-dependent defects. These programs appear logically sound but contain defects that can activate and induce unintended behaviors when the operational agent encounters specific triggers in its interactive environment. To compromise the LLM's contextual environment, we employ adversarial in-context generation to optimize poisoned demonstrations, where an LLM judge evaluates these poisoned prompts, reporting to an additional LLM that iteratively optimizes the demonstration in a two-player adversarial game using chain-of-thought reasoning. To enable context-dependent behaviors in downstream agents, we implement a dual-modality activation strategy that controls both the generation and execution of program defects through textual and visual triggers. We expand the scope of our attack by developing five program defect modes that compromise key aspects of confidentiality, integrity, and availability in embodied agents. To validate the effectiveness of our approach, we conducted extensive experiments across various tasks, including robot planning, robot manipulation, and compositional visual reasoning. Additionally, we demonstrate the potential impact of our approach by successfully attacking real-world autonomous driving systems.
Dual-Phase Accelerated Prompt Optimization
Jun 19, 2024



Gradient-free prompt optimization methods have made significant strides in enhancing the performance of closed-source Large Language Models (LLMs) across a wide range of tasks. However, existing approaches make light of the importance of high-quality prompt initialization and the identification of effective optimization directions, thus resulting in substantial optimization steps to obtain satisfactory performance. In this light, we aim to accelerate prompt optimization process to tackle the challenge of low convergence rate. We propose a dual-phase approach which starts with generating high-quality initial prompts by adopting a well-designed meta-instruction to delve into task-specific information, and iteratively optimize the prompts at the sentence level, leveraging previous tuning experience to expand prompt candidates and accept effective ones. Extensive experiments on eight datasets demonstrate the effectiveness of our proposed method, achieving a consistent accuracy gain over baselines with less than five optimization steps.
General-Purpose User Embeddings based on Mobile App Usage
May 27, 2020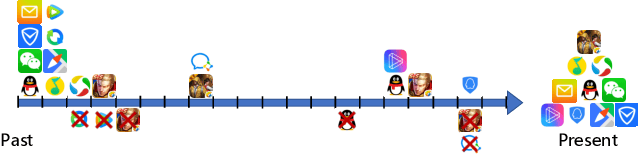

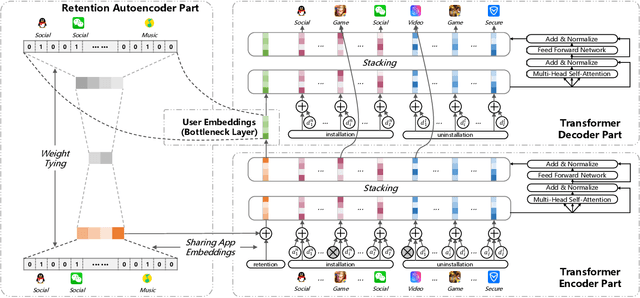
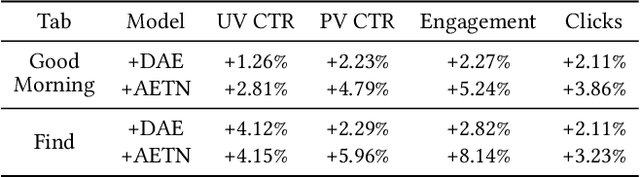
In this paper, we report our recent practice at Tencent for user modeling based on mobile app usage. User behaviors on mobile app usage, including retention, installation, and uninstallation, can be a good indicator for both long-term and short-term interests of users. For example, if a user installs Snapseed recently, she might have a growing interest in photographing. Such information is valuable for numerous downstream applications, including advertising, recommendations, etc. Traditionally, user modeling from mobile app usage heavily relies on handcrafted feature engineering, which requires onerous human work for different downstream applications, and could be sub-optimal without domain experts. However, automatic user modeling based on mobile app usage faces unique challenges, including (1) retention, installation, and uninstallation are heterogeneous but need to be modeled collectively, (2) user behaviors are distributed unevenly over time, and (3) many long-tailed apps suffer from serious sparsity. In this paper, we present a tailored AutoEncoder-coupled Transformer Network (AETN), by which we overcome these challenges and achieve the goals of reducing manual efforts and boosting performance. We have deployed the model at Tencent, and both online/offline experiments from multiple domains of downstream applications have demonstrated the effectiveness of the output user embeddings.
Demographics Should Not Be the Reason of Toxicity: Mitigating Discrimination in Text Classifications with Instance Weighting
Apr 29, 2020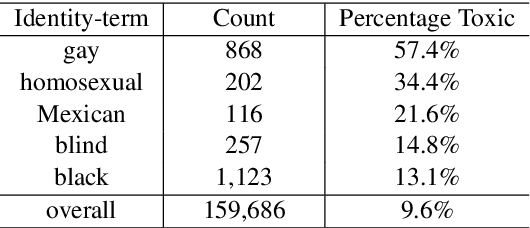
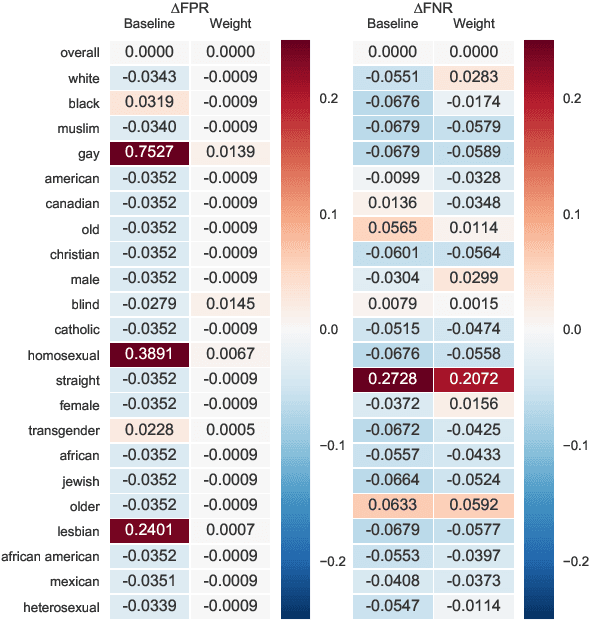
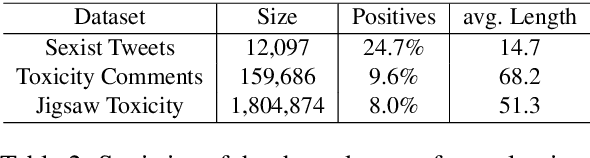
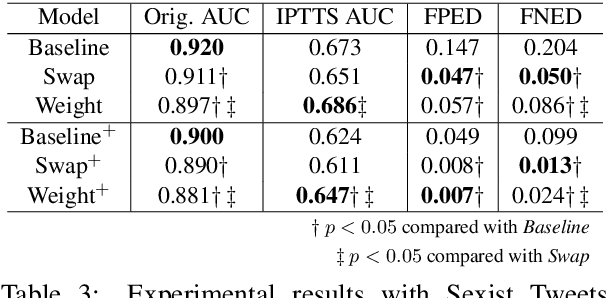
With the recent proliferation of the use of text classifications, researchers have found that there are certain unintended biases in text classification datasets. For example, texts containing some demographic identity-terms (e.g., "gay", "black") are more likely to be abusive in existing abusive language detection datasets. As a result, models trained with these datasets may consider sentences like "She makes me happy to be gay" as abusive simply because of the word "gay." In this paper, we formalize the unintended biases in text classification datasets as a kind of selection bias from the non-discrimination distribution to the discrimination distribution. Based on this formalization, we further propose a model-agnostic debiasing training framework by recovering the non-discrimination distribution using instance weighting, which does not require any extra resources or annotations apart from a pre-defined set of demographic identity-terms. Experiments demonstrate that our method can effectively alleviate the impacts of the unintended biases without significantly hurting models' generalization ability.
Mitigating Annotation Artifacts in Natural Language Inference Datasets to Improve Cross-dataset Generalization Ability
Oct 05, 2019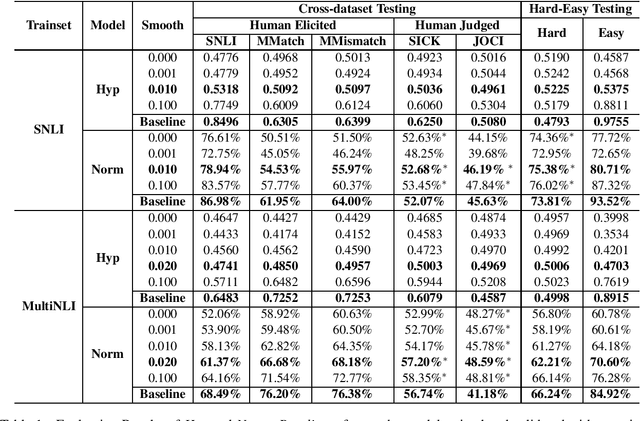
Natural language inference (NLI) aims at predicting the relationship between a given pair of premise and hypothesis. However, several works have found that there widely exists a bias pattern called annotation artifacts in NLI datasets, making it possible to identify the label only by looking at the hypothesis. This irregularity makes the evaluation results over-estimated and affects models' generalization ability. In this paper, we consider a more trust-worthy setting, i.e., cross-dataset evaluation. We explore the impacts of annotation artifacts in cross-dataset testing. Furthermore, we propose a training framework to mitigate the impacts of the bias pattern. Experimental results demonstrate that our methods can alleviate the negative effect of the artifacts and improve the generalization ability of models.