 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResponsible Multilingual Large Language Models: A Survey of Development, Applications, and Societal Impact
Oct 23, 2024



Multilingual Large Language Models (MLLMs) represent a pivotal advancement in democratizing artificial intelligence across linguistic boundaries. While theoretical foundations are well-established, practical implementation guidelines remain scattered. This work bridges this gap by providing a comprehensive end-to-end framework for developing and deploying MLLMs in production environments. We make three distinctive contributions: First, we present an actionable pipeline from data pre-processing through deployment, integrating insights from academic research and industrial applications. Second, using Llama2 as a case study, we provide detailed optimization strategies for enhancing multilingual capabilities, including curriculum learning approaches for balancing high-resource and low-resource languages, tokenization strategies, and effective sampling methods. Third, we offer an interdisciplinary analysis that considers technical, linguistic, and cultural perspectives in MLLM development. Our findings reveal critical challenges in supporting linguistic diversity, with 88.38% of world languages categorized as low-resource, affecting over a billion speakers. We examine practical solutions through real-world applications in customer service, search engines, and machine translation. By synthesizing theoretical frameworks with production-ready implementation strategies, this survey provides essential guidance for practitioners and researchers working to develop more inclusive and effective multilingual AI systems.
Math-LLaVA: Bootstrapping Mathematical Reasoning for Multimodal Large Language Models
Jun 26, 2024



Large language models (LLMs) have demonstrated impressive reasoning capabilities, particularly in textual mathematical problem-solving. However, existing open-source image instruction fine-tuning datasets, containing limited question-answer pairs per image, do not fully exploit visual information to enhance the multimodal mathematical reasoning capabilities of Multimodal LLMs (MLLMs). To bridge this gap, we address the lack of high-quality, diverse multimodal mathematical datasets by collecting 40K high-quality images with question-answer pairs from 24 existing datasets and synthesizing 320K new pairs, creating the MathV360K dataset, which enhances both the breadth and depth of multimodal mathematical questions. We introduce Math-LLaVA, a LLaVA-1.5-based model fine-tuned with MathV360K. This novel approach significantly improves the multimodal mathematical reasoning capabilities of LLaVA-1.5, achieving a 19-point increase and comparable performance to GPT-4V on MathVista's minitest split. Furthermore, Math-LLaVA demonstrates enhanced generalizability, showing substantial improvements on the MMMU benchmark. Our research highlights the importance of dataset diversity and synthesis in advancing MLLMs' mathematical reasoning abilities. The code and data are available at: \url{https://github.com/HZQ950419/Math-LLaVA}.
GauU-Scene V2: Assessing the Reliability of Image-Based Metrics with Expansive Lidar Image Dataset Using 3DGS and NeRF
Apr 13, 2024



We introduce a novel, multimodal large-scale scene reconstruction benchmark that utilizes newly developed 3D representation approaches: Gaussian Splatting and Neural Radiance Fields (NeRF). Our expansive U-Scene dataset surpasses any previously existing real large-scale outdoor LiDAR and image dataset in both area and point count. GauU-Scene encompasses over 6.5 square kilometers and features a comprehensive RGB dataset coupled with LiDAR ground truth. Additionally, we are the first to propose a LiDAR and image alignment method for a drone-based dataset. Our assessment of GauU-Scene includes a detailed analysis across various novel viewpoints, employing image-based metrics such as SSIM, LPIPS, and PSNR on NeRF and Gaussian Splatting based methods. This analysis reveals contradictory results when applying geometric-based metrics like Chamfer distance. The experimental results on our multimodal dataset highlight the unreliability of current image-based metrics and reveal significant drawbacks in geometric reconstruction using the current Gaussian Splatting-based method, further illustrating the necessity of our dataset for assessing geometry reconstruction tasks. We also provide detailed supplementary information on data collection protocols and make the dataset available on the following anonymous project page
From Capture to Display: A Survey on Volumetric Video
Sep 11, 2023Volumetric video, which offers immersive viewing experiences, is gaining increasing prominence. With its six degrees of freedom, it provides viewers with greater immersion and interactivity compared to traditional videos. Despite their potential, volumetric video services poses significant challenges. This survey conducts a comprehensive review of the existing literature on volumetric video. We firstly provide a general framework of volumetric video services, followed by a discussion on prerequisites for volumetric video, encompassing representations, open datasets, and quality assessment metrics. Then we delve into the current methodologies for each stage of the volumetric video service pipeline, detailing capturing, compression, transmission, rendering, and display techniques. Lastly, we explore various applications enabled by this pioneering technology and we present an array of research challenges and opportunities in the domain of volumetric video services. This survey aspires to provide a holistic understanding of this burgeoning field and shed light on potential future research trajectories, aiming to bring the vision of volumetric video to fruition.
Optimizing Group Utility in Itinerary Planning: A Strategic and Crowd-Aware Approach
Apr 20, 2023Itinerary recommendation is a complex sequence prediction problem with numerous real-world applications. This task becomes even more challenging when considering the optimization of multiple user queuing times and crowd levels, as well as numerous involved parameters, such as attraction popularity, queuing time, walking time, and operating hours. Existing solutions typically focus on single-person perspectives and fail to address real-world issues resulting from natural crowd behavior, like the Selfish Routing problem. In this paper, we introduce the Strategic and Crowd-Aware Itinerary Recommendation (SCAIR) algorithm, which optimizes group utility in real-world settings. We model the route recommendation strategy as a Markov Decision Process and propose a State Encoding mechanism that enables real-time planning and allocation in linear time. We evaluate our algorithm against various competitive and realistic baselines using a theme park dataset, demonstrating that SCAIR outperforms these baselines in addressing the Selfish Routing problem across four theme parks.
FSVVD: A Dataset of Full Scene Volumetric Video
Mar 07, 2023Recent years have witnessed a rapid development of immersive multimedia which bridges the gap between the real world and virtual space. Volumetric videos, as an emerging representative 3D video paradigm that empowers extended reality, stand out to provide unprecedented immersive and interactive video watching experience. Despite the tremendous potential, the research towards 3D volumetric video is still in its infancy, relying on sufficient and complete datasets for further exploration. However, existing related volumetric video datasets mostly only include a single object, lacking details about the scene and the interaction between them. In this paper, we focus on the current most widely used data format, point cloud, and for the first time release a full-scene volumetric video dataset that includes multiple people and their daily activities interacting with the external environments. Comprehensive dataset description and analysis are conducted, with potential usage of this dataset. The dataset and additional tools can be accessed via the following website: https://cuhksz-inml.github.io/full_scene_volumetric_video_dataset/.
A Transformer-based Framework for POI-level Social Post Geolocation
Oct 26, 2022POI-level geo-information of social posts is critical to many location-based applications and services. However, the multi-modality, complexity and diverse nature of social media data and their platforms limit the performance of inferring such fine-grained locations and their subsequent applications. To address this issue, we present a transformer-based general framework, which builds upon pre-trained language models and considers non-textual data, for social post geolocation at the POI level. To this end, inputs are categorized to handle different social data, and an optimal combination strategy is provided for feature representations. Moreover, a uniform representation of hierarchy is proposed to learn temporal information, and a concatenated version of encodings is employed to capture feature-wise positions better. Experimental results on various social datasets demonstrate that three variants of our proposed framework outperform multiple state-of-art baselines by a large margin in terms of accuracy and distance error metrics.
Analyzing Scientific Publications using Domain-Specific Word Embedding and Topic Modelling
Dec 24, 2021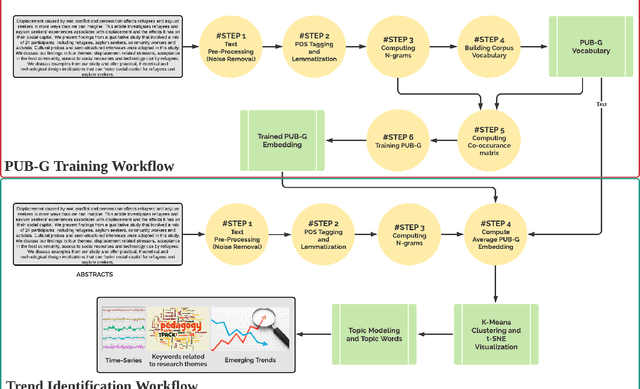
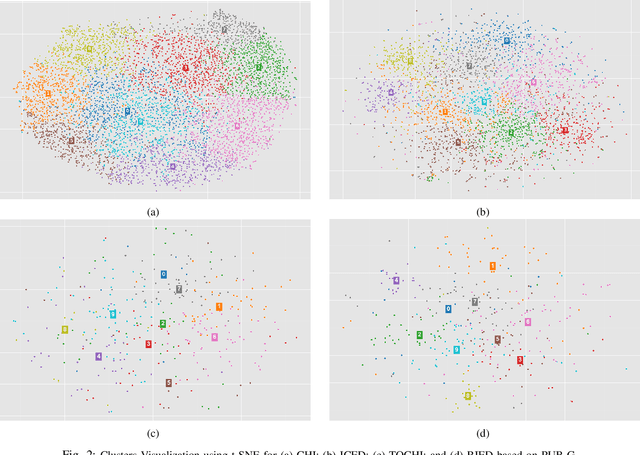
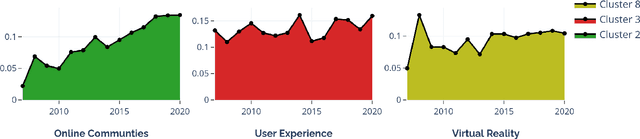
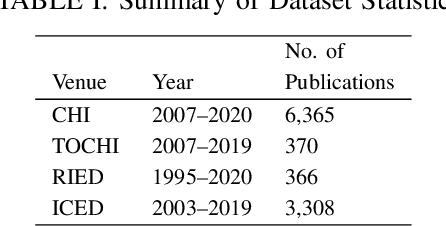
The scientific world is changing at a rapid pace, with new technology being developed and new trends being set at an increasing frequency. This paper presents a framework for conducting scientific analyses of academic publications, which is crucial to monitor research trends and identify potential innovations. This framework adopts and combines various techniques of Natural Language Processing, such as word embedding and topic modelling. Word embedding is used to capture semantic meanings of domain-specific words. We propose two novel scientific publication embedding, i.e., PUB-G and PUB-W, which are capable of learning semantic meanings of general as well as domain-specific words in various research fields. Thereafter, topic modelling is used to identify clusters of research topics within these larger research fields. We curated a publication dataset consisting of two conferences and two journals from 1995 to 2020 from two research domains. Experimental results show that our PUB-G and PUB-W embeddings are superior in comparison to other baseline embeddings by a margin of ~0.18-1.03 based on topic coherence.
Photozilla: A Large-Scale Photography Dataset and Visual Embedding for 20 Photography Styles
Jun 21, 2021


The advent of social media platforms has been a catalyst for the development of digital photography that engendered a boom in vision applications. With this motivation, we introduce a large-scale dataset termed 'Photozilla', which includes over 990k images belonging to 10 different photographic styles. The dataset is then used to train 3 classification models to automatically classify the images into the relevant style which resulted in an accuracy of ~96%. With the rapid evolution of digital photography, we have seen new types of photography styles emerging at an exponential rate. On that account, we present a novel Siamese-based network that uses the trained classification models as the base architecture to adapt and classify unseen styles with only 25 training samples. We report an accuracy of over 68% for identifying 10 other distinct types of photography styles. This dataset can be found at https://trisha025.github.io/Photozilla/
Urban Crowdsensing using Social Media: An Empirical Study on Transformer and Recurrent Neural Networks
Dec 05, 2020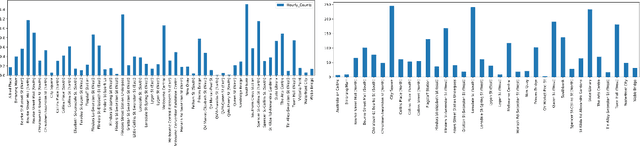

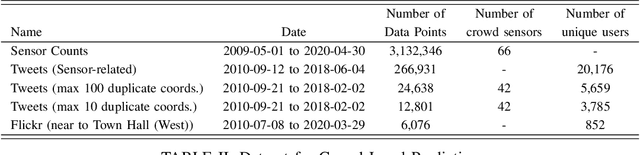
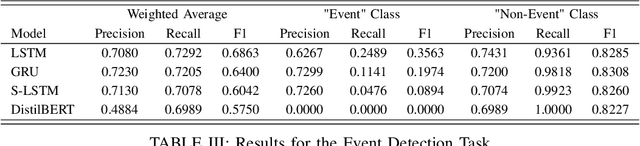
An important aspect of urban planning is understanding crowd levels at various locations, which typically require the use of physical sensors. Such sensors are potentially costly and time consuming to implement on a large scale. To address this issue, we utilize publicly available social media datasets and use them as the basis for two urban sensing problems, namely event detection and crowd level prediction. One main contribution of this work is our collected dataset from Twitter and Flickr, alongside ground truth events. We demonstrate the usefulness of this dataset with two preliminary supervised learning approaches: firstly, a series of neural network models to determine if a social media post is related to an event and secondly a regression model using social media post counts to predict actual crowd levels. We discuss preliminary results from these tasks and highlight some challenges.