 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNSML: Meet the MLaaS platform with a real-world case study
Oct 08, 2018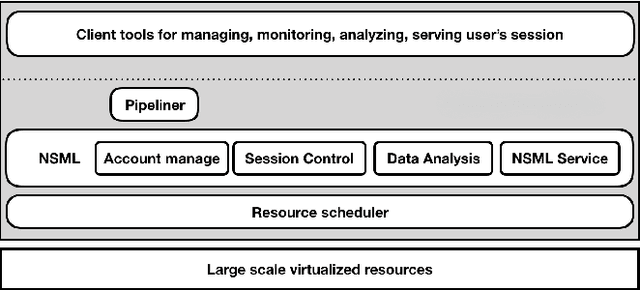
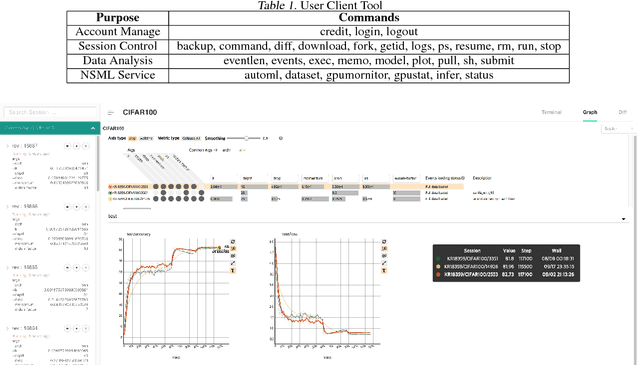
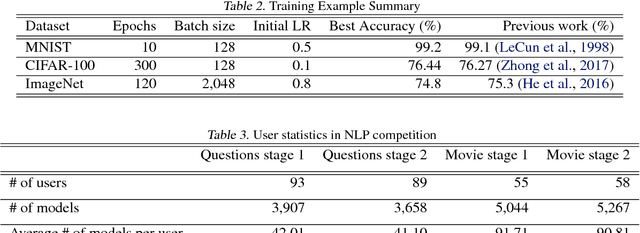
The boom of deep learning induced many industries and academies to introduce machine learning based approaches into their concern, competitively. However, existing machine learning frameworks are limited to sufficiently fulfill the collaboration and management for both data and models. We proposed NSML, a machine learning as a service (MLaaS) platform, to meet these demands. NSML helps machine learning work be easily launched on a NSML cluster and provides a collaborative environment which can afford development at enterprise scale. Finally, NSML users can deploy their own commercial services with NSML cluster. In addition, NSML furnishes convenient visualization tools which assist the users in analyzing their work. To verify the usefulness and accessibility of NSML, we performed some experiments with common examples. Furthermore, we examined the collaborative advantages of NSML through three competitions with real-world use cases.
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
Sep 21, 2018
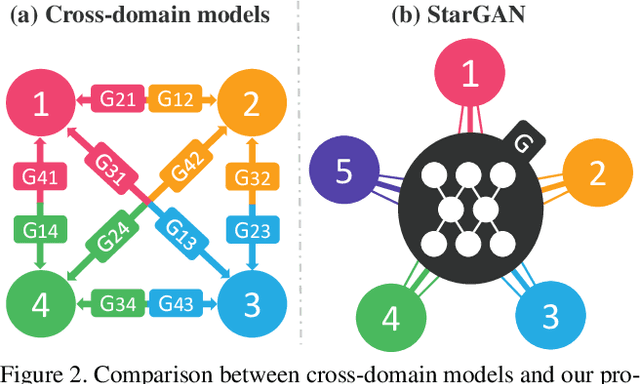
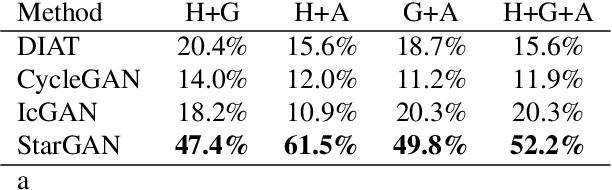
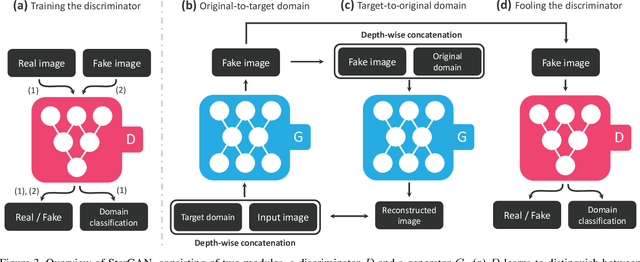
Recent studies have shown remarkable success in image-to-image translation for two domains. However, existing approaches have limited scalability and robustness in handling more than two domains, since different models should be built independently for every pair of image domains. To address this limitation, we propose StarGAN, a novel and scalable approach that can perform image-to-image translations for multiple domains using only a single model. Such a unified model architecture of StarGAN allows simultaneous training of multiple datasets with different domains within a single network. This leads to StarGAN's superior quality of translated images compared to existing models as well as the novel capability of flexibly translating an input image to any desired target domain. We empirically demonstrate the effectiveness of our approach on a facial attribute transfer and a facial expression synthesis tasks.
* Accepted to CVPR 2018 (Oral)
Overcoming Catastrophic Forgetting by Incremental Moment Matching
Jan 30, 2018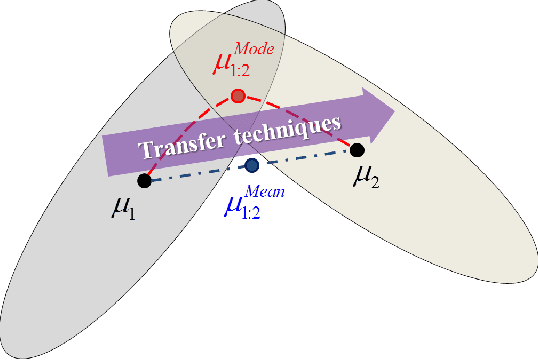
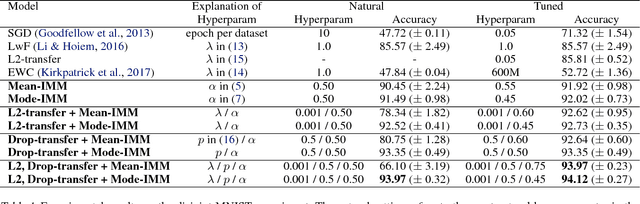
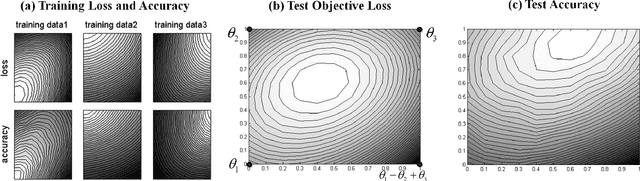

Catastrophic forgetting is a problem of neural networks that loses the information of the first task after training the second task. Here, we propose a method, i.e. incremental moment matching (IMM), to resolve this problem. IMM incrementally matches the moment of the posterior distribution of the neural network which is trained on the first and the second task, respectively. To make the search space of posterior parameter smooth, the IMM procedure is complemented by various transfer learning techniques including weight transfer, L2-norm of the old and the new parameter, and a variant of dropout with the old parameter. We analyze our approach on a variety of datasets including the MNIST, CIFAR-10, Caltech-UCSD-Birds, and Lifelog datasets. The experimental results show that IMM achieves state-of-the-art performance by balancing the information between an old and a new network.
Reinforcement Learning based Recommender System using Biclustering Technique
Jan 17, 2018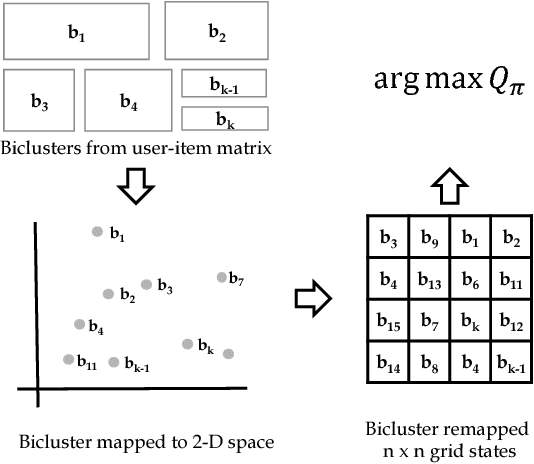
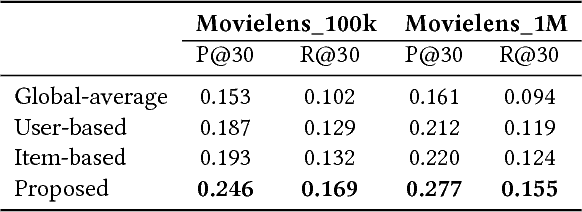
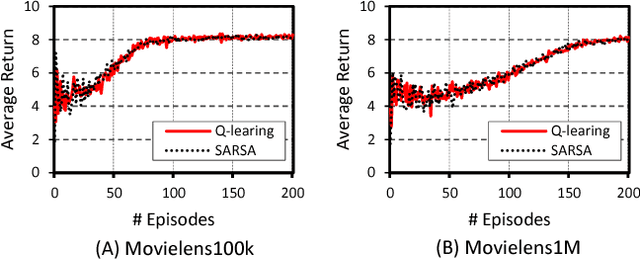
A recommender system aims to recommend items that a user is interested in among many items. The need for the recommender system has been expanded by the information explosion. Various approaches have been suggested for providing meaningful recommendations to users. One of the proposed approaches is to consider a recommender system as a Markov decision process (MDP) problem and try to solve it using reinforcement learning (RL). However, existing RL-based methods have an obvious drawback. To solve an MDP in a recommender system, they encountered a problem with the large number of discrete actions that bring RL to a larger class of problems. In this paper, we propose a novel RL-based recommender system. We formulate a recommender system as a gridworld game by using a biclustering technique that can reduce the state and action space significantly. Using biclustering not only reduces space but also improves the recommendation quality effectively handling the cold-start problem. In addition, our approach can provide users with some explanation why the system recommends certain items. Lastly, we examine the proposed algorithm on a real-world dataset and achieve a better performance than the widely used recommendation algorithm.
NSML: A Machine Learning Platform That Enables You to Focus on Your Models
Dec 16, 2017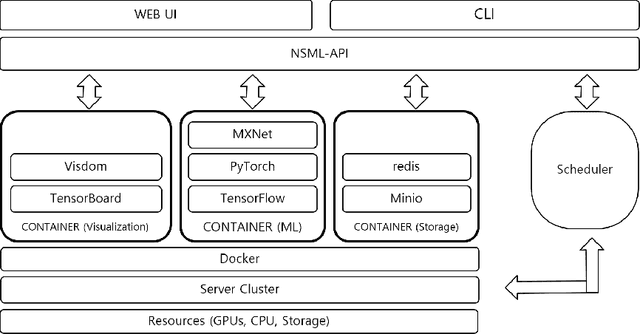
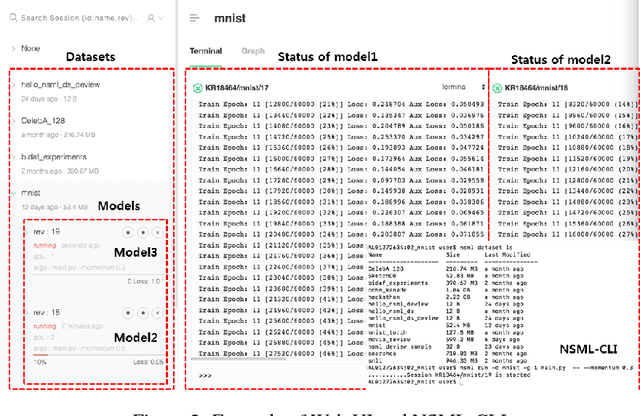
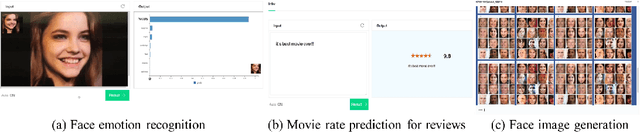
Machine learning libraries such as TensorFlow and PyTorch simplify model implementation. However, researchers are still required to perform a non-trivial amount of manual tasks such as GPU allocation, training status tracking, and comparison of models with different hyperparameter settings. We propose a system to handle these tasks and help researchers focus on models. We present the requirements of the system based on a collection of discussions from an online study group comprising 25k members. These include automatic GPU allocation, learning status visualization, handling model parameter snapshots as well as hyperparameter modification during learning, and comparison of performance metrics between models via a leaderboard. We describe the system architecture that fulfills these requirements and present a proof-of-concept implementation, NAVER Smart Machine Learning (NSML). We test the system and confirm substantial efficiency improvements for model development.
Automatic Music Highlight Extraction using Convolutional Recurrent Attention Networks
Dec 16, 2017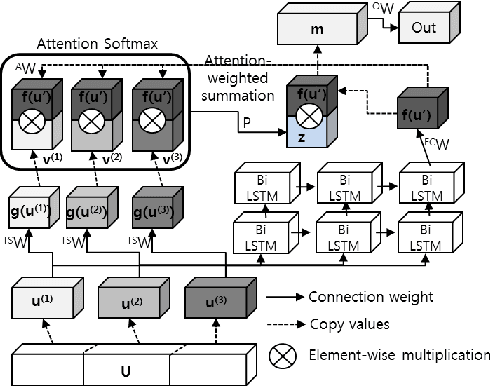
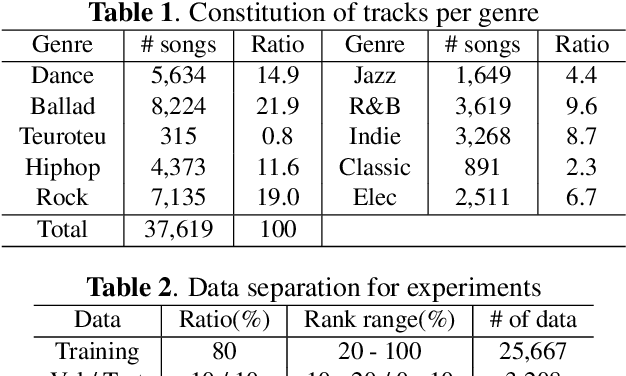
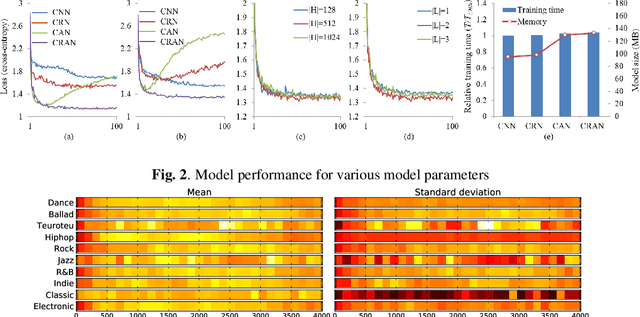
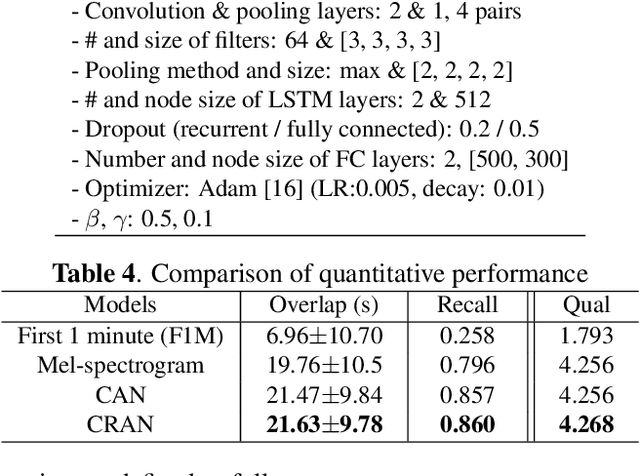
Music highlights are valuable contents for music services. Most methods focused on low-level signal features. We propose a method for extracting highlights using high-level features from convolutional recurrent attention networks (CRAN). CRAN utilizes convolution and recurrent layers for sequential learning with an attention mechanism. The attention allows CRAN to capture significant snippets for distinguishing between genres, thus being used as a high-level feature. CRAN was evaluated on over 32,000 popular tracks in Korea for two months. Experimental results show our method outperforms three baseline methods through quantitative and qualitative evaluations. Also, we analyze the effects of attention and sequence information on performance.
Highrisk Prediction from Electronic Medical Records via Deep Attention Networks
Nov 30, 2017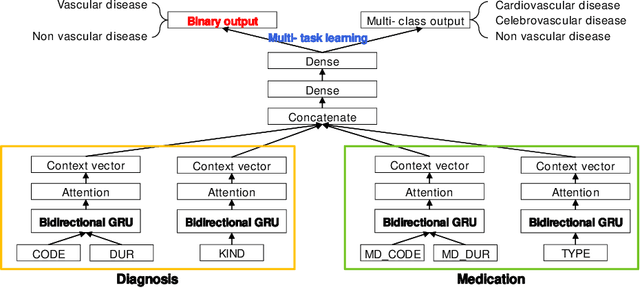
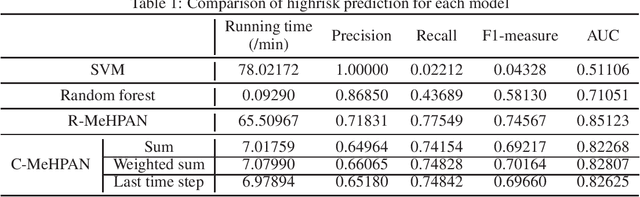
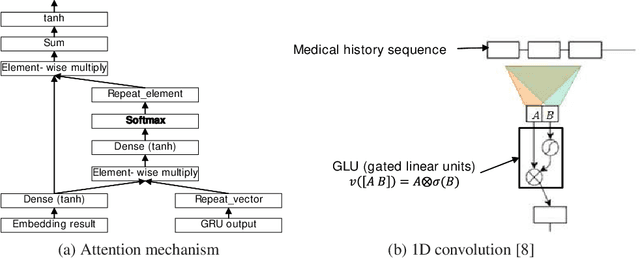
Predicting highrisk vascular diseases is a significant issue in the medical domain. Most predicting methods predict the prognosis of patients from pathological and radiological measurements, which are expensive and require much time to be analyzed. Here we propose deep attention models that predict the onset of the high risky vascular disease from symbolic medical histories sequence of hypertension patients such as ICD-10 and pharmacy codes only, Medical History-based Prediction using Attention Network (MeHPAN). We demonstrate two types of attention models based on 1) bidirectional gated recurrent unit (R-MeHPAN) and 2) 1D convolutional multilayer model (C-MeHPAN). Two MeHPAN models are evaluated on approximately 50,000 hypertension patients with respect to precision, recall, f1-measure and area under the curve (AUC). Experimental results show that our MeHPAN methods outperform standard classification models. Comparing two MeHPANs, R-MeHPAN provides more better discriminative capability with respect to all metrics while C-MeHPAN presents much shorter training time with competitive accuracy.
Energy-Based Sequence GANs for Recommendation and Their Connection to Imitation Learning
Jun 28, 2017
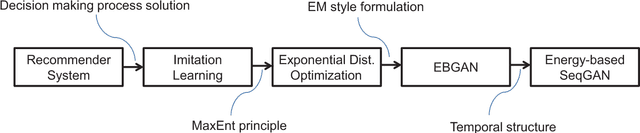
Recommender systems aim to find an accurate and efficient mapping from historic data of user-preferred items to a new item that is to be liked by a user. Towards this goal, energy-based sequence generative adversarial nets (EB-SeqGANs) are adopted for recommendation by learning a generative model for the time series of user-preferred items. By recasting the energy function as the feature function, the proposed EB-SeqGANs is interpreted as an instance of maximum-entropy imitation learning.
Hadamard Product for Low-rank Bilinear Pooling
Mar 26, 2017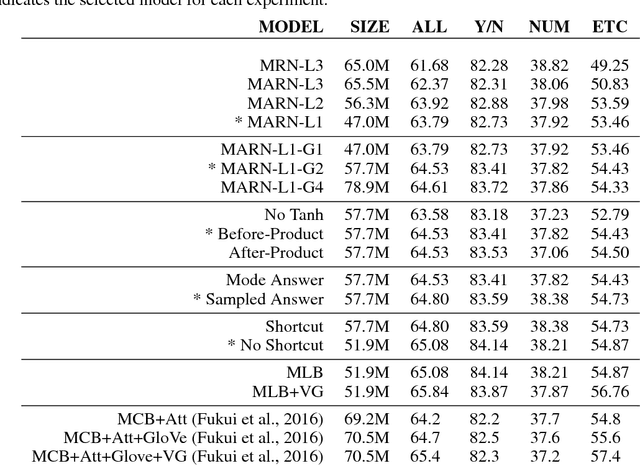
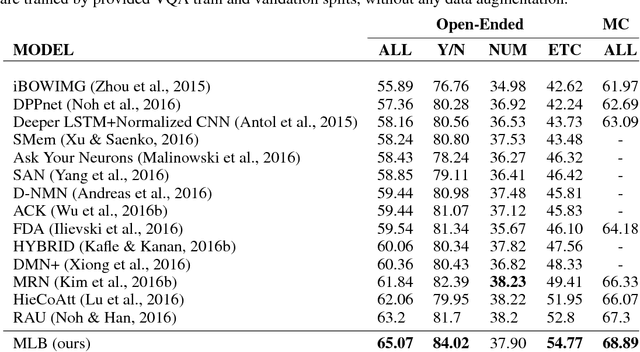
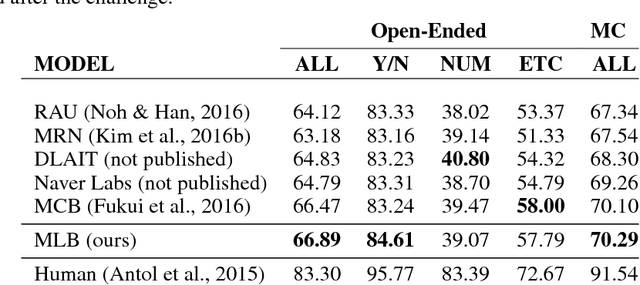
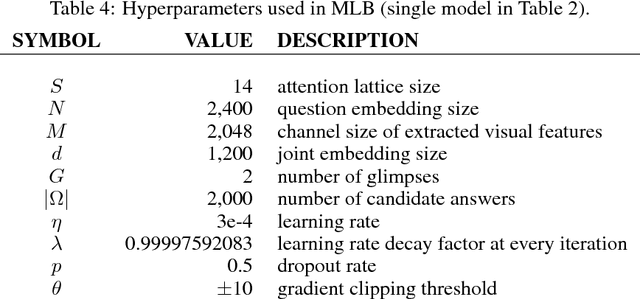
Bilinear models provide rich representations compared with linear models. They have been applied in various visual tasks, such as object recognition, segmentation, and visual question-answering, to get state-of-the-art performances taking advantage of the expanded representations. However, bilinear representations tend to be high-dimensional, limiting the applicability to computationally complex tasks. We propose low-rank bilinear pooling using Hadamard product for an efficient attention mechanism of multimodal learning. We show that our model outperforms compact bilinear pooling in visual question-answering tasks with the state-of-the-art results on the VQA dataset, having a better parsimonious property.
Dual Attention Networks for Multimodal Reasoning and Matching
Mar 21, 2017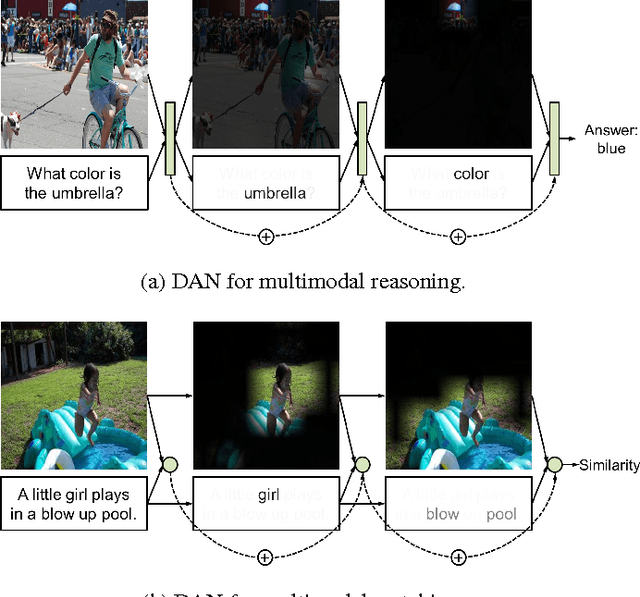
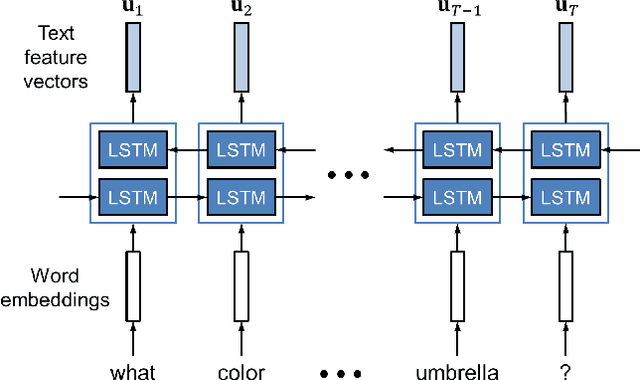
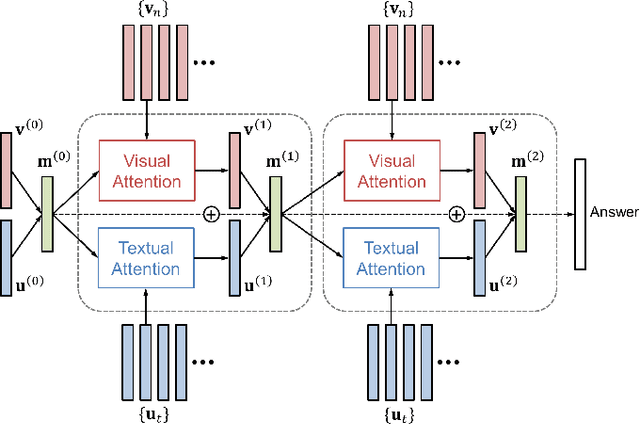
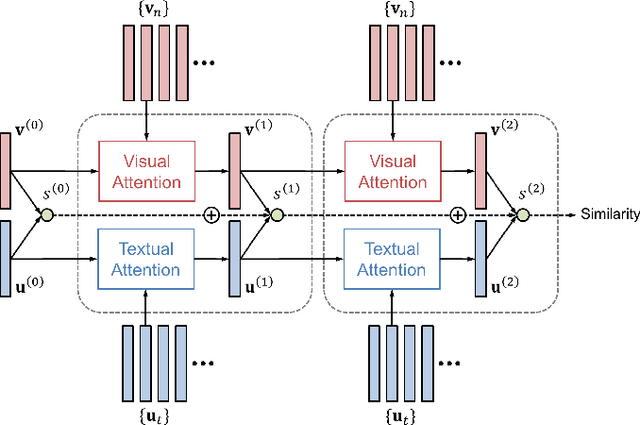
We propose Dual Attention Networks (DANs) which jointly leverage visual and textual attention mechanisms to capture fine-grained interplay between vision and language. DANs attend to specific regions in images and words in text through multiple steps and gather essential information from both modalities. Based on this framework, we introduce two types of DANs for multimodal reasoning and matching, respectively. The reasoning model allows visual and textual attentions to steer each other during collaborative inference, which is useful for tasks such as Visual Question Answering (VQA). In addition, the matching model exploits the two attention mechanisms to estimate the similarity between images and sentences by focusing on their shared semantics. Our extensive experiments validate the effectiveness of DANs in combining vision and language, achieving the state-of-the-art performance on public benchmarks for VQA and image-text matching.