 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2FN: Multi-step Modality Fusion for Advertisement Image Assessment
Feb 09, 2021
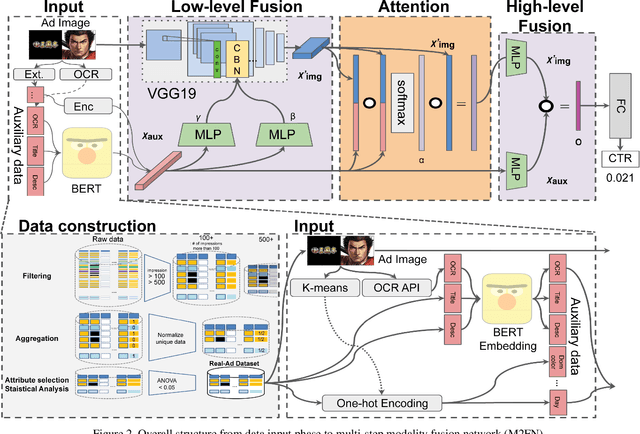
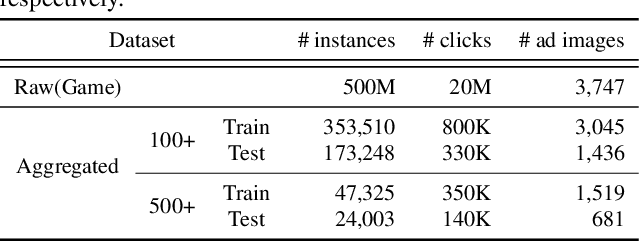
Assessing advertisements, specifically on the basis of user preferences and ad quality, is crucial to the marketing industry. Although recent studies have attempted to use deep neural networks for this purpose, these studies have not utilized image-related auxiliary attributes, which include embedded text frequently found in ad images. We, therefore, investigated the influence of these attributes on ad image preferences. First, we analyzed large-scale real-world ad log data and, based on our findings, proposed a novel multi-step modality fusion network (M2FN) that determines advertising images likely to appeal to user preferences. Our method utilizes auxiliary attributes through multiple steps in the network, which include conditional batch normalization-based low-level fusion and attention-based high-level fusion. We verified M2FN on the AVA dataset, which is widely used for aesthetic image assessment, and then demonstrated that M2FN can achieve state-of-the-art performance in preference prediction using a real-world ad dataset with rich auxiliary attributes.
DialogBERT: Discourse-Aware Response Generation via Learning to Recover and Rank Utterances
Dec 03, 2020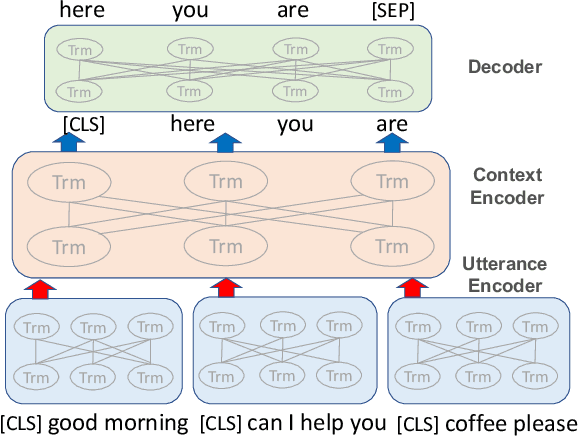
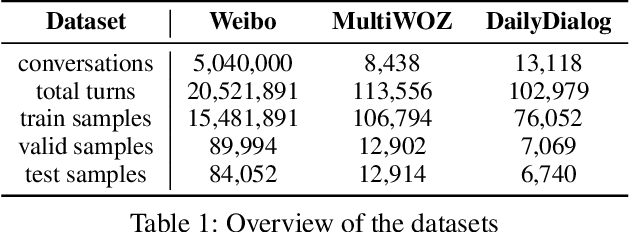
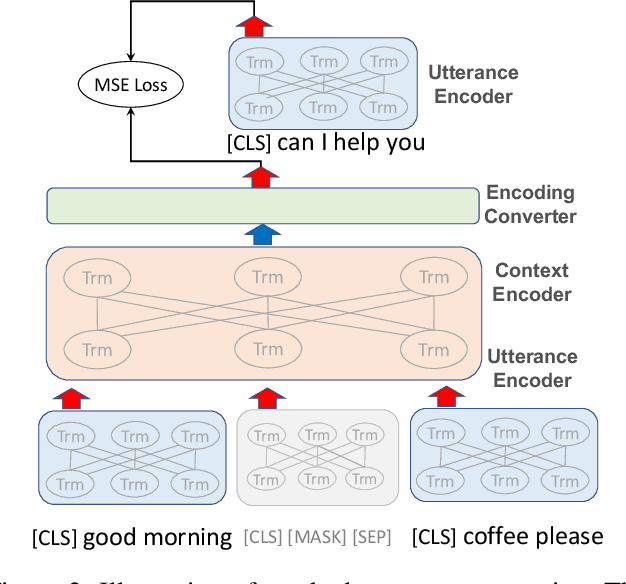
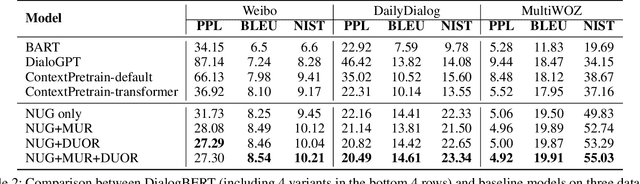
Recent advances in pre-trained language models have significantly improved neural response generation. However, existing methods usually view the dialogue context as a linear sequence of tokens and learn to generate the next word through token-level self-attention. Such token-level encoding hinders the exploration of discourse-level coherence among utterances. This paper presents DialogBERT, a novel conversational response generation model that enhances previous PLM-based dialogue models. DialogBERT employs a hierarchical Transformer architecture. To efficiently capture the discourse-level coherence among utterances, we propose two training objectives, including masked utterance regression and distributed utterance order ranking in analogy to the original BERT training. Experiments on three multi-turn conversation datasets show that our approach remarkably outperforms the baselines, such as BART and DialoGPT, in terms of quantitative evaluation. The human evaluation suggests that DialogBERT generates more coherent, informative, and human-like responses than the baselines with significant margins.
Context-Aware Answer Extraction in Question Answering
Nov 05, 2020
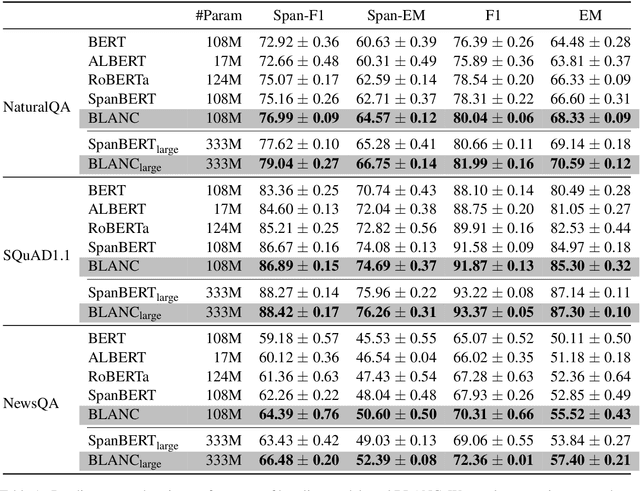
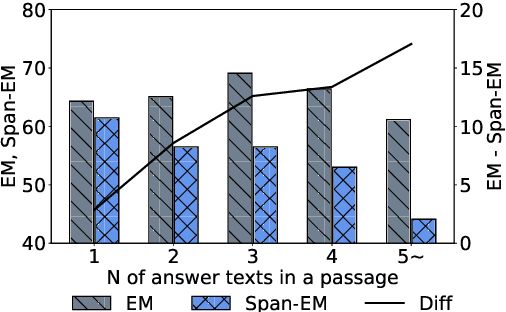

Extractive QA models have shown very promising performance in predicting the correct answer to a question for a given passage. However, they sometimes result in predicting the correct answer text but in a context irrelevant to the given question. This discrepancy becomes especially important as the number of occurrences of the answer text in a passage increases. To resolve this issue, we propose \textbf{BLANC} (\textbf{BL}ock \textbf{A}ttentio\textbf{N} for \textbf{C}ontext prediction) based on two main ideas: context prediction as an auxiliary task in multi-task learning manner, and a block attention method that learns the context prediction task. With experiments on reading comprehension, we show that BLANC outperforms the state-of-the-art QA models, and the performance gap increases as the number of answer text occurrences increases. We also conduct an experiment of training the models using SQuAD and predicting the supporting facts on HotpotQA and show that BLANC outperforms all baseline models in this zero-shot setting.
ST-BERT: Cross-modal Language Model Pre-training For End-to-end Spoken Language Understanding
Oct 23, 2020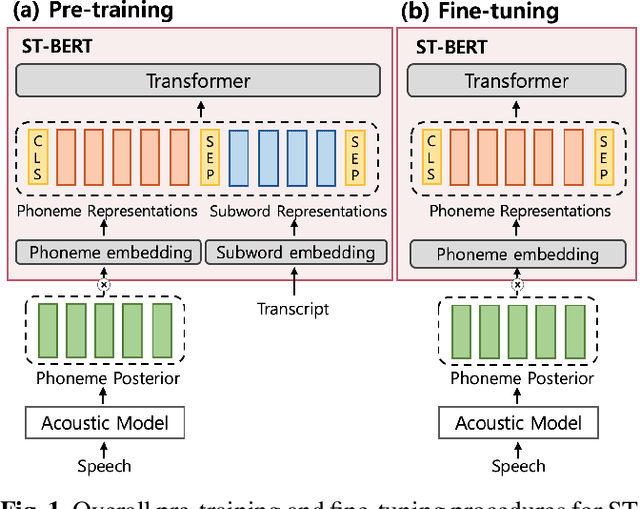
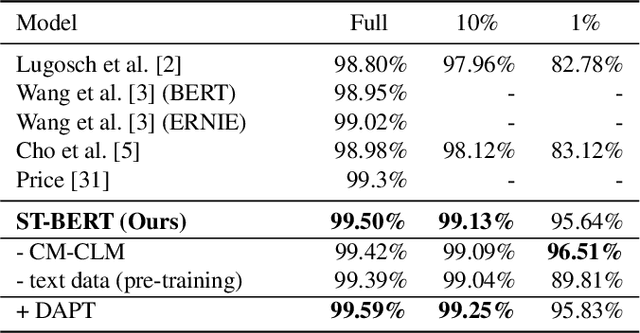
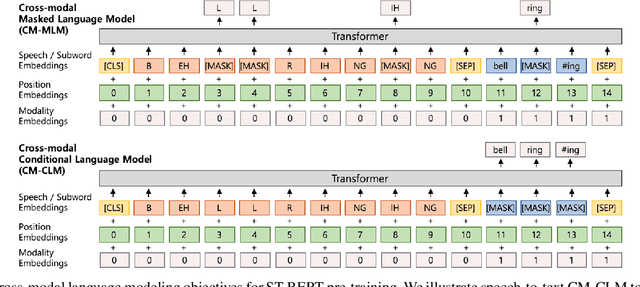
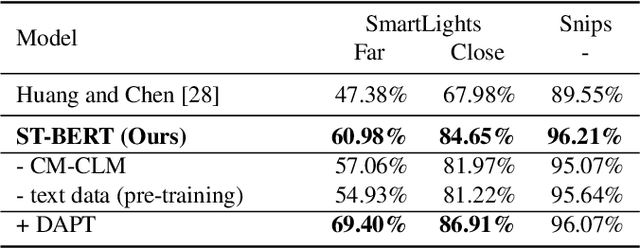
Language model pre-training has shown promising results in various downstream tasks. In this context, we introduce a cross-modal pre-trained language model, called Speech-Text BERT (ST-BERT), to tackle end-to-end spoken language understanding (E2E SLU) tasks. Taking phoneme posterior and subword-level text as an input, ST-BERT learns a contextualized cross-modal alignment via our two proposed pre-training tasks: Cross-modal Masked Language Modeling (CM-MLM) and Cross-modal Conditioned Language Modeling (CM-CLM). Experimental results on three benchmarks present that our approach is effective for various SLU datasets and shows a surprisingly marginal performance degradation even when 1% of the training data are available. Also, our method shows further SLU performance gain via domain-adaptive pre-training with domain-specific speech-text pair data.
Self-supervised Auxiliary Learning with Meta-paths for Heterogeneous Graphs
Aug 18, 2020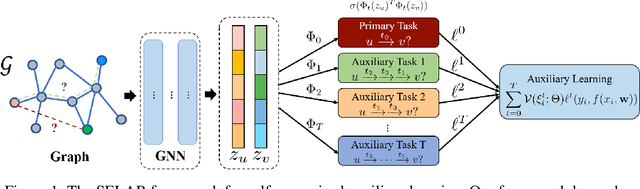
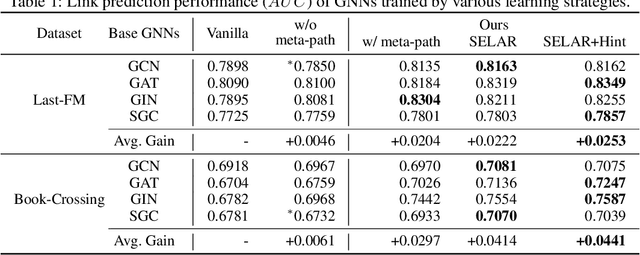
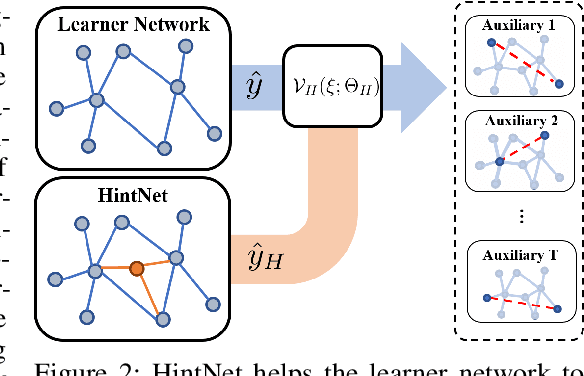
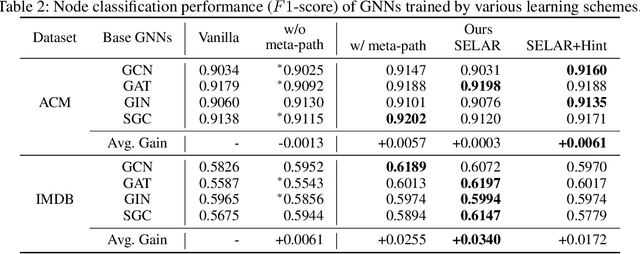
Graph neural networks have shown superior performance in a wide range of applications providing a powerful representation of graph-structured data. Recent works show that the representation can be further improved by auxiliary tasks. However, the auxiliary tasks for heterogeneous graphs, which contain rich semantic information with various types of nodes and edges, have less explored in the literature. In this paper, to learn graph neural networks on heterogeneous graphs we propose a novel self-supervised auxiliary learning method using meta-paths, which are composite relations of multiple edge types. Our proposed method is learning to learn a primary task by predicting meta-paths as auxiliary tasks. This can be viewed as a type of meta-learning. The proposed method can identify an effective combination of auxiliary tasks and automatically balance them to improve the primary task. Our methods can be applied to any graph neural networks in a plug-in manner without manual labeling or additional data. The experiments demonstrate that the proposed method consistently improves the performance of link prediction and node classification on heterogeneous graphs.
Which Strategies Matter for Noisy Label Classification? Insight into Loss and Uncertainty
Aug 14, 2020
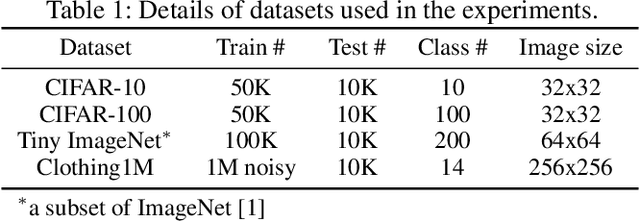
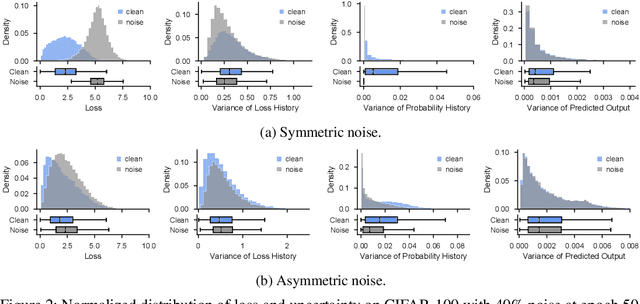
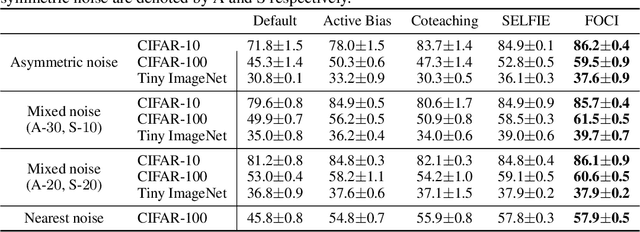
Label noise is a critical factor that degrades the generalization performance of deep neural networks, thus leading to severe issues in real-world problems. Existing studies have employed strategies based on either loss or uncertainty to address noisy labels, and ironically some strategies contradict each other: emphasizing or discarding uncertain samples or concentrating on high or low loss samples. To elucidate how opposing strategies can enhance model performance and offer insights into training with noisy labels, we present analytical results on how loss and uncertainty values of samples change throughout the training process. From the in-depth analysis, we design a new robust training method that emphasizes clean and informative samples, while minimizing the influence of noise using both loss and uncertainty. We demonstrate the effectiveness of our method with extensive experiments on synthetic and real-world datasets for various deep learning models. The results show that our method significantly outperforms other state-of-the-art methods and can be used generally regardless of neural network architectures.
CareCall: a Call-Based Active Monitoring Dialog Agent for Managing COVID-19 Pandemic
Jul 06, 2020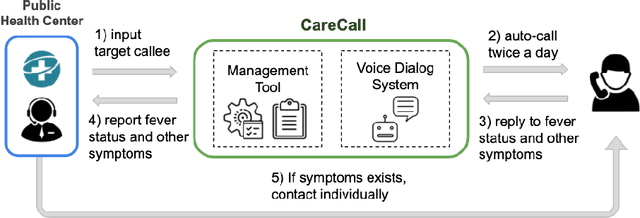
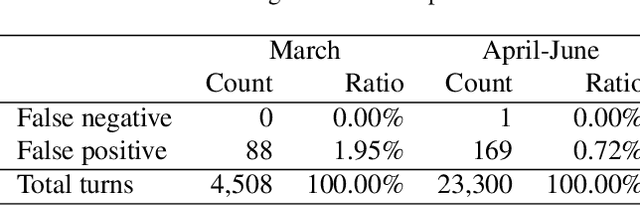
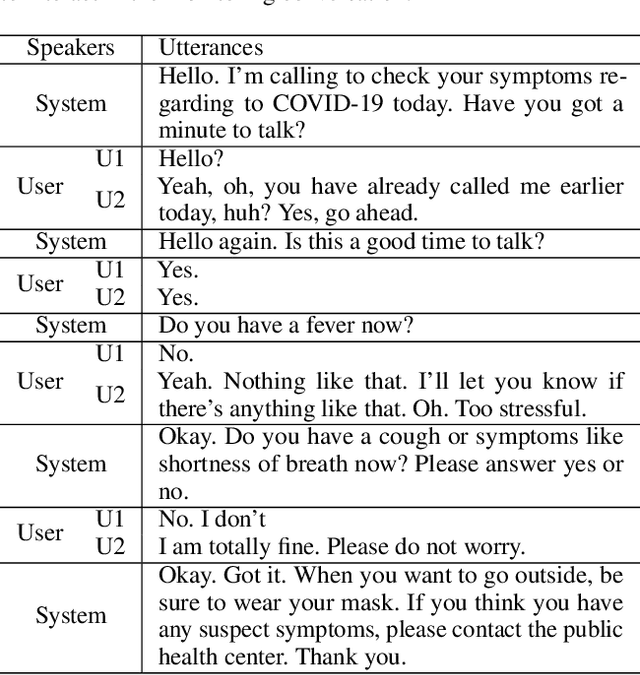
Tracking suspected cases of COVID-19 is crucial to suppressing the spread of COVID-19 pandemic. Active monitoring and proactive inspection are indispensable to mitigate COVID-19 spread, though these require considerable social and economic expense. To address this issue, we introduce CareCall, a call-based dialog agent which is deployed for active monitoring in Korea and Japan. We describe our system with a case study with statistics to show how the system works. Finally, we discuss a simple idea which uses CareCall to support proactive inspection.
Efficient Active Learning for Automatic Speech Recognition via Augmented Consistency Regularization
Jun 19, 2020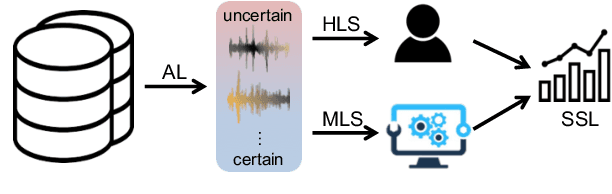
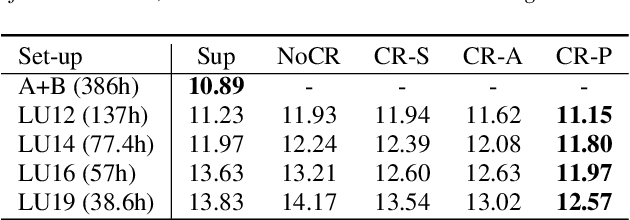
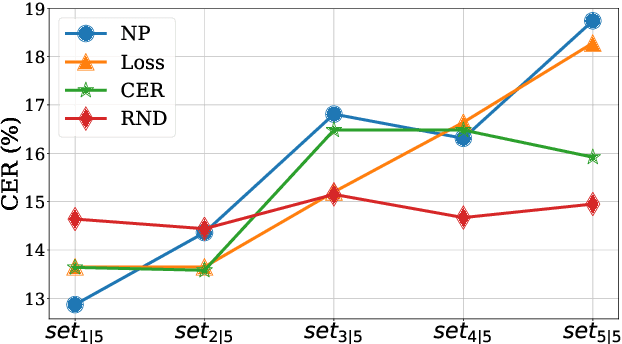
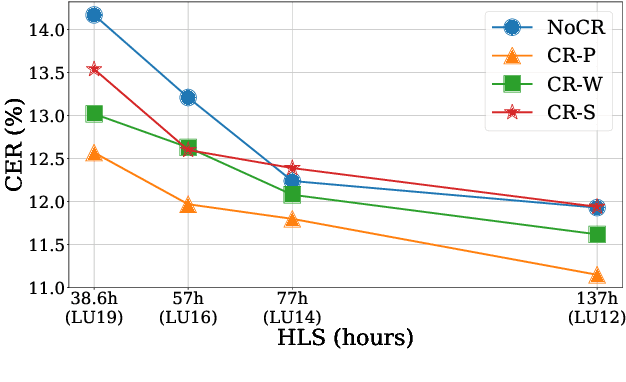
The cost of labeling transcriptions for large speech corpora becomes a bottleneck to maximally enjoy the potential capacity of deep neural network-based automatic speech recognition (ASR) models. Therefore, in this paper, we present a new training scheme that minimizes the labeling cost by adopting the concepts of semi-supervised learning (SSL) and active learning (AL) approaches and making a synergy from them. While AL studies only focus on selecting minimized the number of samples to be labeled with a criterion and taking advantage of such samples, we show that the training efficiency can be further improved by utilizing the unlabeled samples by sophisticatedly designing unsupervised loss that complements the unwanted behavior of supervised loss effectively. Our unsupervised loss is built on Consistency-Regularization (CR) approach, and we propose appropriate augmentation techniques to adopt CR in ASR field successfully. From the qualitative and quantitative experiments on the real-world dataset from deployed end-user voice assistant services, we show that the proposed methods can handle a large number of unlabeled speech data to achieve competitive model performance, with a sustainable amount of human labeling cost.
Slowing Down the Weight Norm Increase in Momentum-based Optimizers
Jun 15, 2020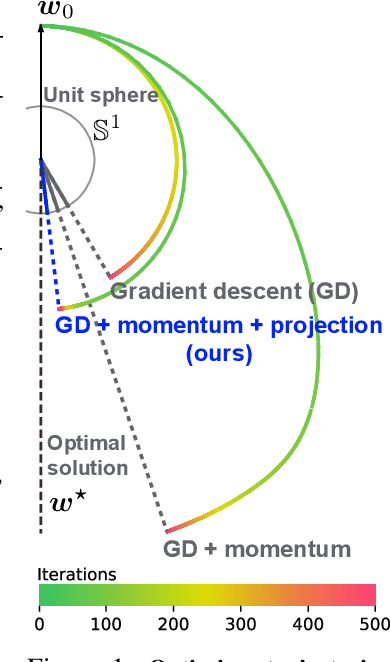

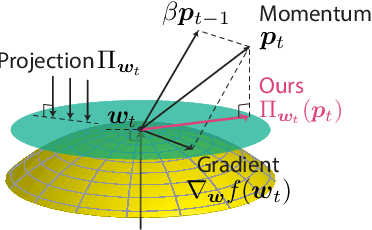
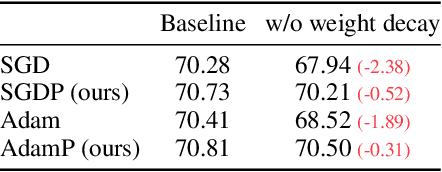
Normalization techniques, such as batch normalization (BN), have led to significant improvements in deep neural network performances. Prior studies have analyzed the benefits of the resulting scale invariance of the weights for the gradient descent (GD) optimizers: it leads to a stabilized training due to the auto-tuning of step sizes. However, we show that, combined with the momentum-based algorithms, the scale invariance tends to induce an excessive growth of the weight norms. This in turn overly suppresses the effective step sizes during training, potentially leading to sub-optimal performances in deep neural networks. We analyze this phenomenon both theoretically and empirically. We propose a simple and effective solution: at each iteration of momentum-based GD optimizers (e.g. SGD or Adam) applied on scale-invariant weights (e.g. Conv weights preceding a BN layer), we remove the radial component (i.e. parallel to the weight vector) from the update vector. Intuitively, this operation prevents the unnecessary update along the radial direction that only increases the weight norm without contributing to the loss minimization. We verify that the modified optimizers SGDP and AdamP successfully regularize the norm growth and improve the performance of a broad set of models. Our experiments cover tasks including image classification and retrieval, object detection, robustness benchmarks, and audio classification. Source code is available at https://github.com/clovaai/AdamP.
Graphs, Entities, and Step Mixture
May 18, 2020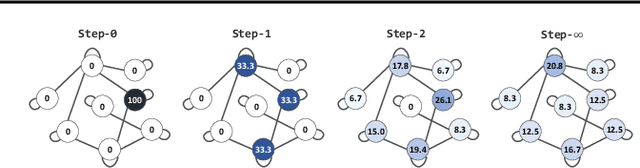
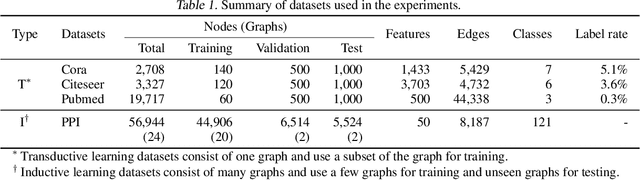
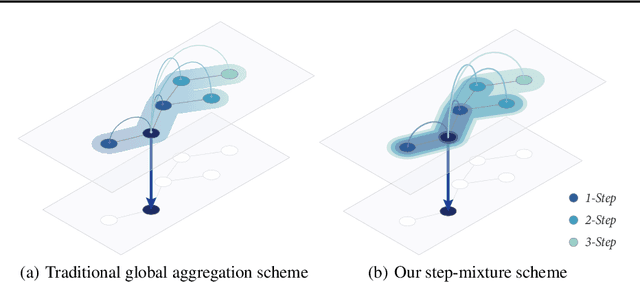
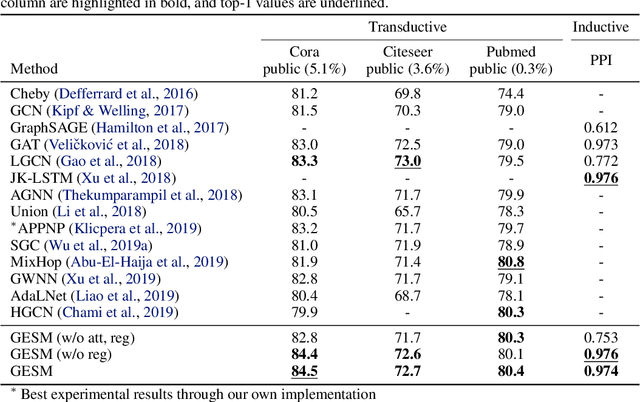
Existing approaches for graph neural networks commonly suffer from the oversmoothing issue, regardless of how neighborhoods are aggregated. Most methods also focus on transductive scenarios for fixed graphs, leading to poor generalization for unseen graphs. To address these issues, we propose a new graph neural network that considers both edge-based neighborhood relationships and node-based entity features, i.e. Graph Entities with Step Mixture via random walk (GESM). GESM employs a mixture of various steps through random walk to alleviate the oversmoothing problem, attention to dynamically reflect interrelations depending on node information, and structure-based regularization to enhance embedding representation. With intensive experiments, we show that the proposed GESM achieves state-of-the-art or comparable performances on eight benchmark graph datasets comprising transductive and inductive learning tasks. Furthermore, we empirically demonstrate the significance of considering global information.