 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltrafast Photorealistic Style Transfer via Neural Architecture Search
Dec 05, 2019
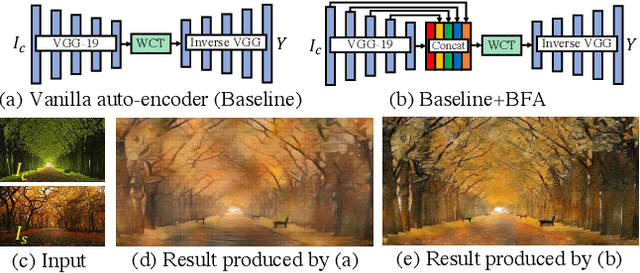

The key challenge in photorealistic style transfer is that an algorithm should faithfully transfer the style of a reference photo to a content photo while the generated image should look like one captured by a camera. Although several photorealistic style transfer algorithms have been proposed, they need to rely on post- and/or pre-processing to make the generated images look photorealistic. If we disable the additional processing, these algorithms would fail to produce plausible photorealistic stylization in terms of detail preservation and photorealism. In this work, we propose an effective solution to these issues. Our method consists of a construction step (C-step) to build a photorealistic stylization network and a pruning step (P-step) for acceleration. In the C-step, we propose a dense auto-encoder named PhotoNet based on a carefully designed pre-analysis. PhotoNet integrates a feature aggregation module (BFA) and instance normalized skip links (INSL). To generate faithful stylization, we introduce multiple style transfer modules in the decoder and INSLs. PhotoNet significantly outperforms existing algorithms in terms of both efficiency and effectiveness. In the P-step, we adopt a neural architecture search method to accelerate PhotoNet. We propose an automatic network pruning framework in the manner of teacher-student learning for photorealistic stylization. The network architecture named PhotoNAS resulted from the search achieves significant acceleration over PhotoNet while keeping the stylization effects almost intact. We conduct extensive experiments on both image and video transfer. The results show that our method can produce favorable results while achieving 20-30 times acceleration in comparison with the existing state-of-the-art approaches. It is worth noting that the proposed algorithm accomplishes better performance without any pre- or post-processing.
SecureGBM: Secure Multi-Party Gradient Boosting
Nov 27, 2019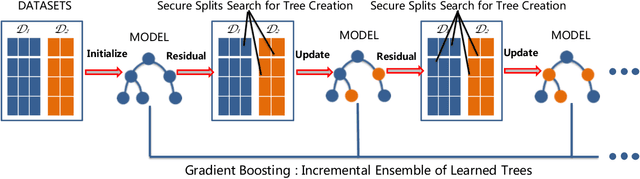
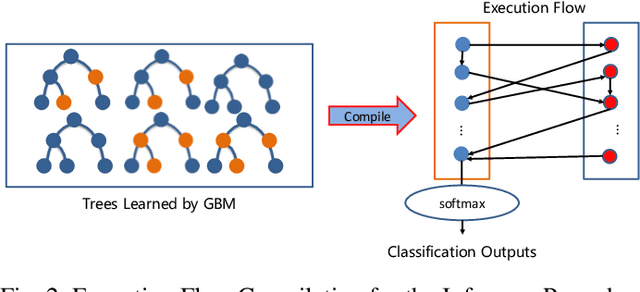
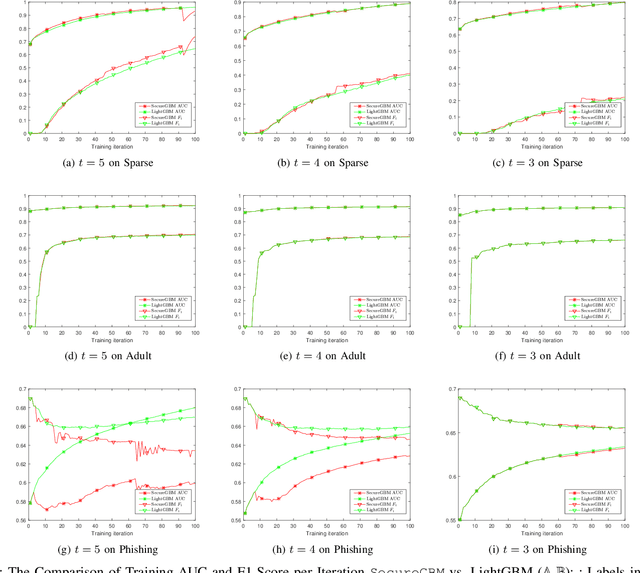
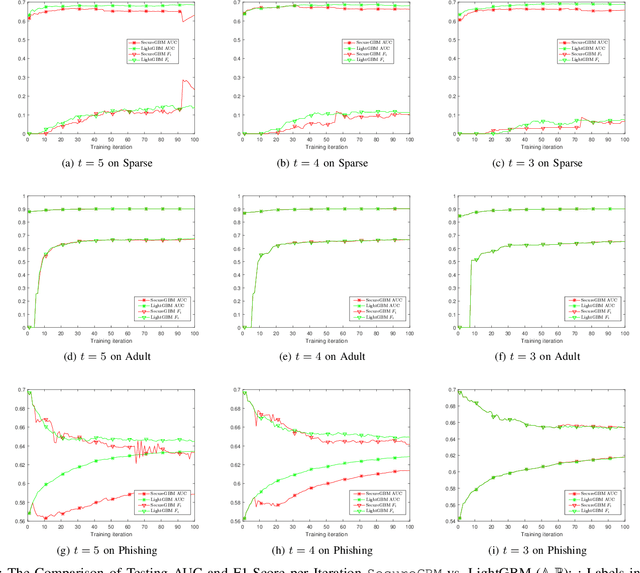
Federated machine learning systems have been widely used to facilitate the joint data analytics across the distributed datasets owned by the different parties that do not trust each others. In this paper, we proposed a novel Gradient Boosting Machines (GBM) framework SecureGBM built-up with a multi-party computation model based on semi-homomorphic encryption, where every involved party can jointly obtain a shared Gradient Boosting machines model while protecting their own data from the potential privacy leakage and inferential identification. More specific, our work focused on a specific "dual--party" secure learning scenario based on two parties -- both party own an unique view (i.e., attributes or features) to the sample group of samples while only one party owns the labels. In such scenario, feature and label data are not allowed to share with others. To achieve the above goal, we firstly extent -- LightGBM -- a well known implementation of tree-based GBM through covering its key operations for training and inference with SEAL homomorphic encryption schemes. However, the performance of such re-implementation is significantly bottle-necked by the explosive inflation of the communication payloads, based on ciphertexts subject to the increasing length of plaintexts. In this way, we then proposed to use stochastic approximation techniques to reduced the communication payloads while accelerating the overall training procedure in a statistical manner. Our experiments using the real-world data showed that SecureGBM can well secure the communication and computation of LightGBM training and inference procedures for the both parties while only losing less than 3% AUC, using the same number of iterations for gradient boosting, on a wide range of benchmark datasets.
Towards Making Deep Transfer Learning Never Hurt
Nov 18, 2019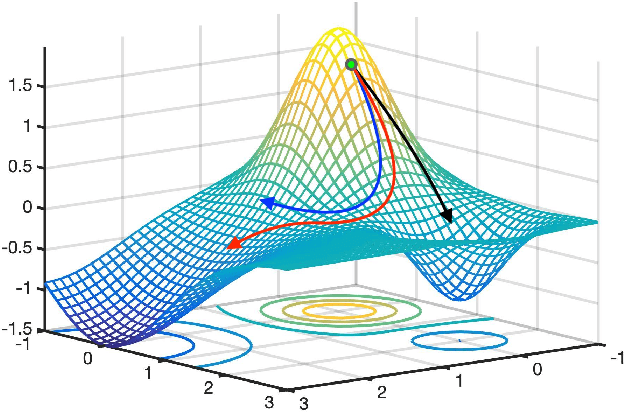
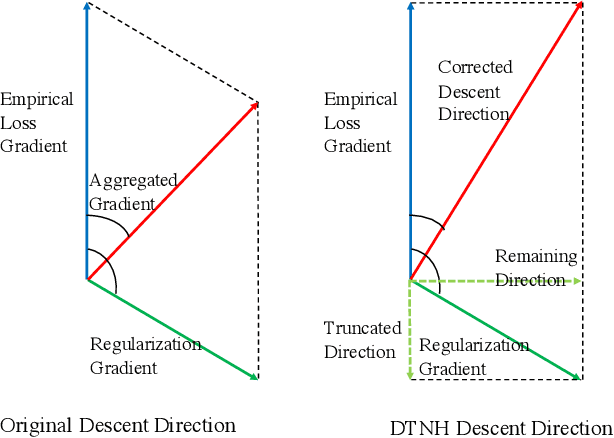
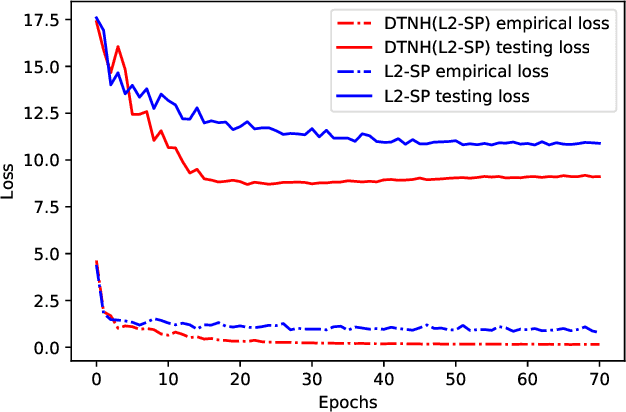
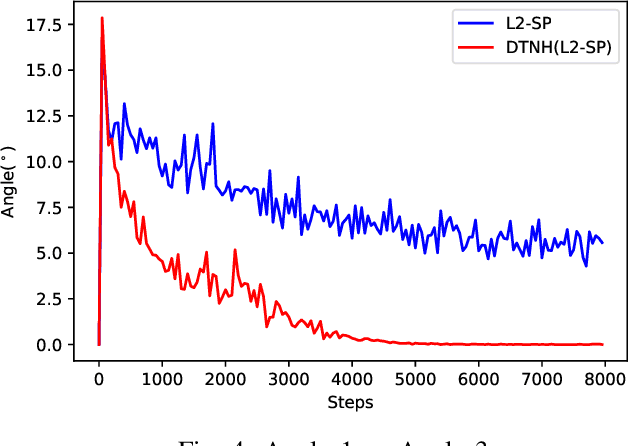
Transfer learning have been frequently used to improve deep neural network training through incorporating weights of pre-trained networks as the starting-point of optimization for regularization. While deep transfer learning can usually boost the performance with better accuracy and faster convergence, transferring weights from inappropriate networks hurts training procedure and may lead to even lower accuracy. In this paper, we consider deep transfer learning as minimizing a linear combination of empirical loss and regularizer based on pre-trained weights, where the regularizer would restrict the training procedure from lowering the empirical loss, with conflicted descent directions (e.g., derivatives). Following the view, we propose a novel strategy making regularization-based Deep Transfer learning Never Hurt (DTNH) that, for each iteration of training procedure, computes the derivatives of the two terms separately, then re-estimates a new descent direction that does not hurt the empirical loss minimization while preserving the regularization affects from the pre-trained weights. Extensive experiments have been done using common transfer learning regularizers, such as L2-SP and knowledge distillation, on top of a wide range of deep transfer learning benchmarks including Caltech, MIT indoor 67, CIFAR-10 and ImageNet. The empirical results show that the proposed descent direction estimation strategy DTNH can always improve the performance of deep transfer learning tasks based on all above regularizers, even when transferring pre-trained weights from inappropriate networks. All in all, DTNH strategy can improve state-of-the-art regularizers in all cases with 0.1%--7% higher accuracy in all experiments.
* 10 pages
NormLime: A New Feature Importance Metric for Explaining Deep Neural Networks
Oct 15, 2019
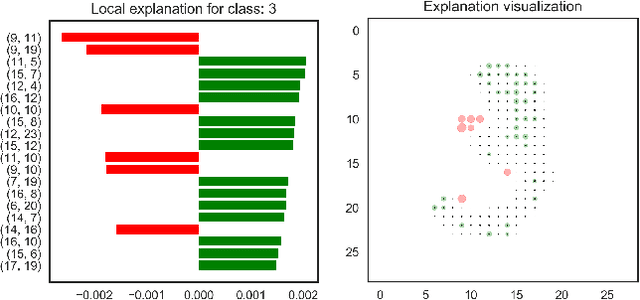
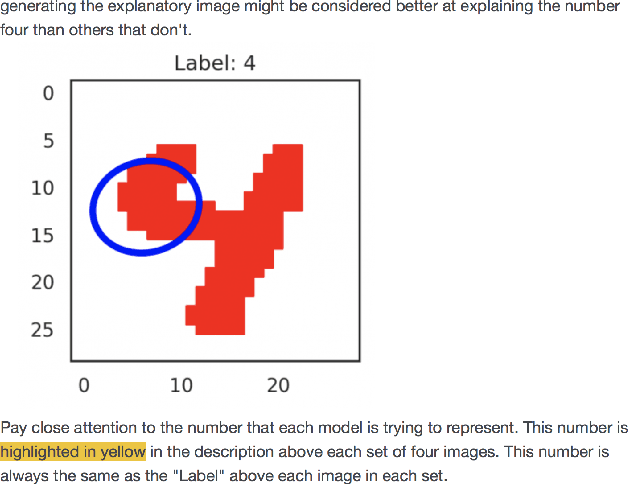
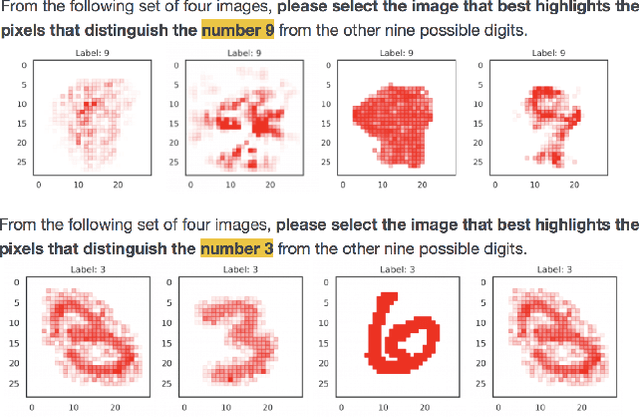
The problem of explaining deep learning models, and model predictions generally, has attracted intensive interest recently. Many successful approaches forgo global approximations in order to provide more faithful local interpretations of the model's behavior. LIME develops multiple interpretable models, each approximating a large neural network on a small region of the data manifold and SP-LIME aggregates the local models to form a global interpretation. Extending this line of research, we propose a simple yet effective method, NormLIME for aggregating local models into global and class-specific interpretations. A human user study strongly favored class-specific interpretations created by NormLIME to other feature importance metrics. Numerical experiments confirm that NormLIME is effective at recognizing important features.
Improving Adversarial Robustness via Attention and Adversarial Logit Pairing
Aug 23, 2019
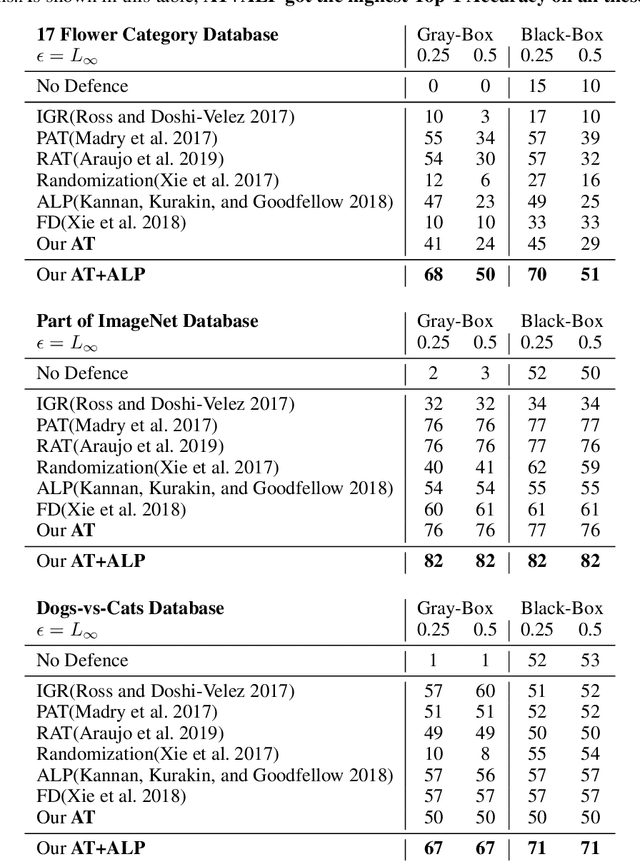
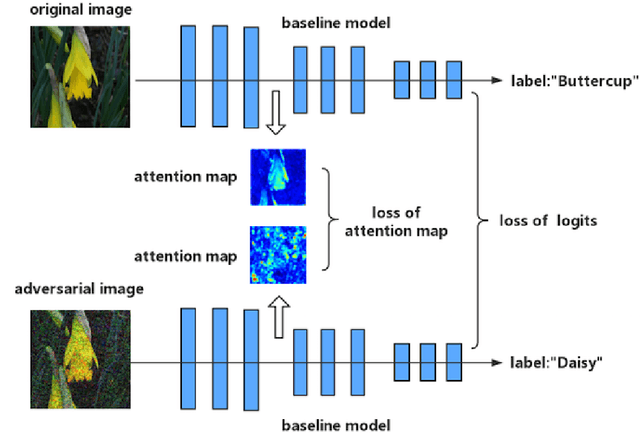
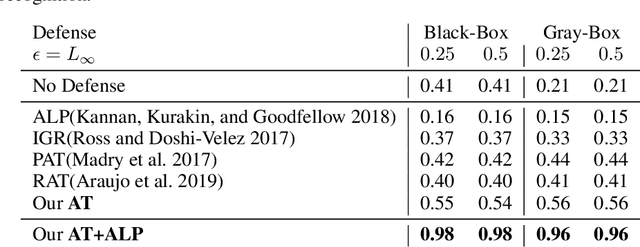
Though deep neural networks have achieved the state of the art performance in visual classification, recent studies have shown that they are all vulnerable to the attack of adversarial examples. In this paper, we develop improved techniques for defending against adversarial examples.First, we introduce enhanced defense using a technique we call \textbf{Attention and Adversarial Logit Pairing(AT+ALP)}, a method that encourages both attention map and logit for pairs of examples to be similar. When applied to clean examples and their adversarial counterparts, \textbf{AT+ALP} improves accuracy on adversarial examples over adversarial training.Next,We show that our \textbf{AT+ALP} can effectively increase the average activations of adversarial examples in the key area and demonstrate that it focuse on more discriminate features to improve the robustness of the model.Finally,we conducte extensive experiments using a wide range of datasets and the experiment results show that our \textbf{AT+ALP} achieves \textbf{the state of the art} defense.For example,on \textbf{17 Flower Category Database}, under strong 200-iteration \textbf{PGD} gray-box and black-box attacks where prior art has 34\% and 39\% accuracy, our method achieves \textbf{50\%} and \textbf{51\%}.Compared with previous work,our work is evaluated under highly challenging PGD attack:the maximum perturbation $\epsilon \in \{0.25,0.5\}$ i.e. $L_\infty \in \{0.25,0.5\}$ with 10 to 200 attack iterations.To our knowledge, such a strong attack has not been previously explored on a wide range of datasets.
Fast Universal Style Transfer for Artistic and Photorealistic Rendering
Jul 06, 2019
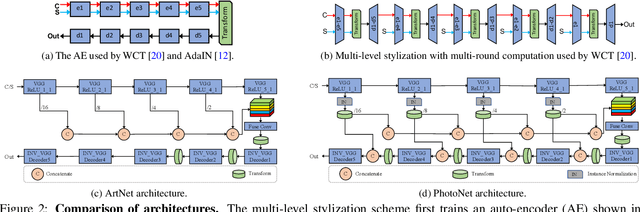
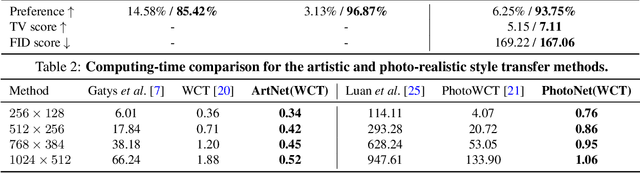

Universal style transfer is an image editing task that renders an input content image using the visual style of arbitrary reference images, including both artistic and photorealistic stylization. Given a pair of images as the source of content and the reference of style, existing solutions usually first train an auto-encoder (AE) to reconstruct the image using deep features and then embeds pre-defined style transfer modules into the AE reconstruction procedure to transfer the style of the reconstructed image through modifying the deep features. While existing methods typically need multiple rounds of time-consuming AE reconstruction for better stylization, our work intends to design novel neural network architectures on top of AE for fast style transfer with fewer artifacts and distortions all in one pass of end-to-end inference. To this end, we propose two network architectures named ArtNet and PhotoNet to improve artistic and photo-realistic stylization, respectively. Extensive experiments demonstrate that ArtNet generates images with fewer artifacts and distortions against the state-of-the-art artistic transfer algorithms, while PhotoNet improves the photorealistic stylization results by creating sharp images faithfully preserving rich details of the input content. Moreover, ArtNet and PhotoNet can achieve 3X to 100X speed-up over the state-of-the-art algorithms, which is a major advantage for large content images.
AGAN: Towards Automated Design of Generative Adversarial Networks
Jun 25, 2019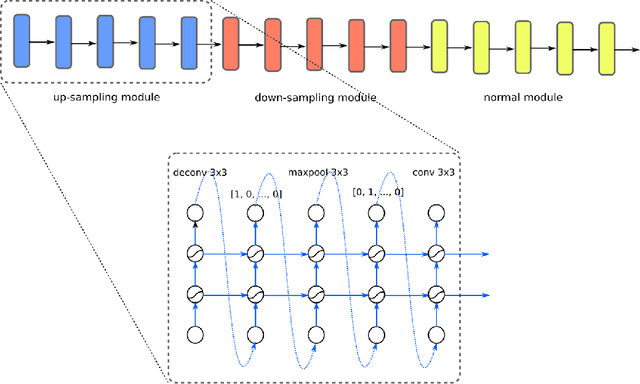
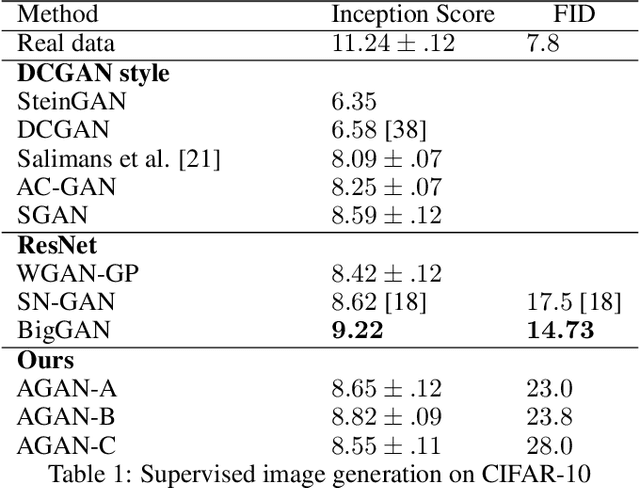
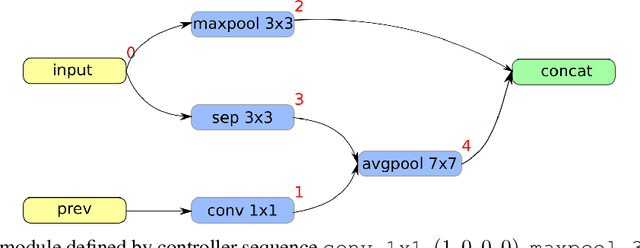
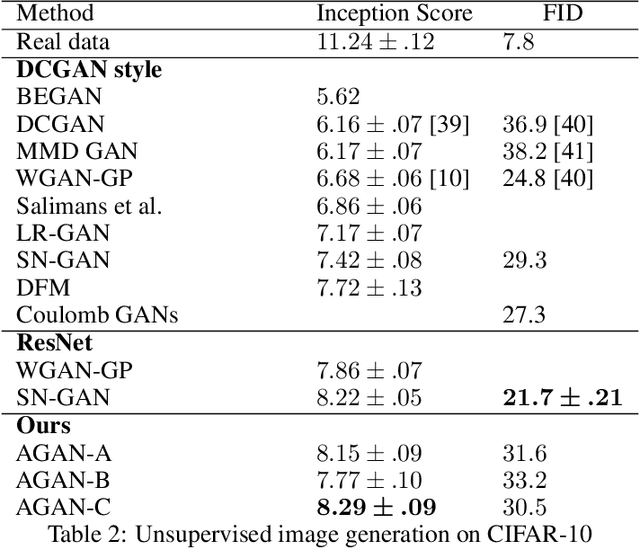
Recent progress in Generative Adversarial Networks (GANs) has shown promising signs of improving GAN training via architectural change. Despite some early success, at present the design of GAN architectures requires human expertise, laborious trial-and-error testings, and often draws inspiration from its image classification counterpart. In the current paper, we present the first neural architecture search algorithm, automated neural architecture search for deep generative models, or AGAN for abbreviation, that is specifically suited for GAN training. For unsupervised image generation tasks on CIFAR-10, our algorithm finds architecture that outperforms state-of-the-art models under same regularization techniques. For supervised tasks, the automatically searched architectures also achieve highly competitive performance, outperforming best human-invented architectures at resolution $32\times32$. Moreover, we empirically demonstrate that the modules learned by AGAN are transferable to other image generation tasks such as STL-10.
The Multiplicative Noise in Stochastic Gradient Descent: Data-Dependent Regularization, Continuous and Discrete Approximation
Jun 18, 2019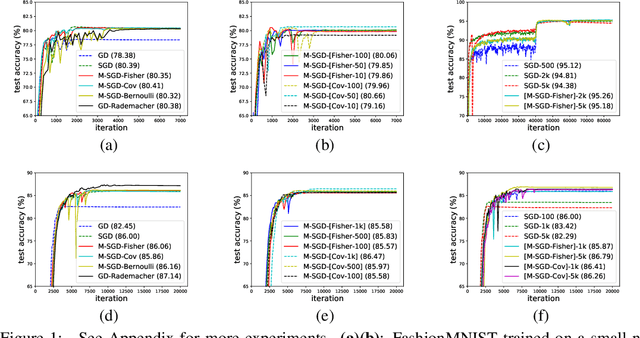
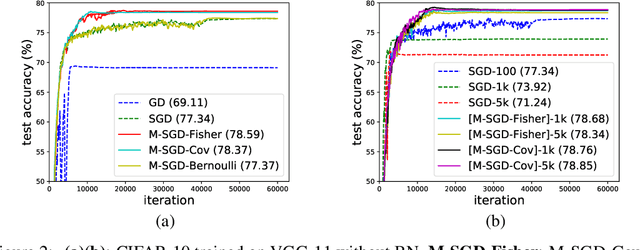
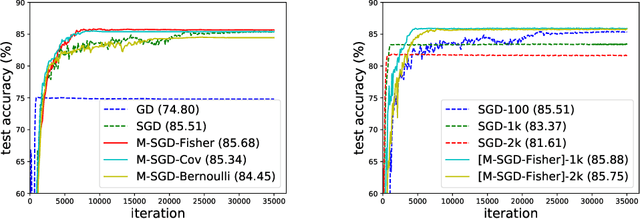
The randomness in Stochastic Gradient Descent (SGD) is considered to play a central role in the observed strong generalization capability of deep learning. In this work, we re-interpret the stochastic gradient of vanilla SGD as a matrix-vector product of the matrix of gradients and a random noise vector (namely multiplicative noise, M-Noise). Comparing to the existing theory that explains SGD using additive noise, the M-Noise helps establish a general case of SGD, namely Multiplicative SGD (M-SGD). The advantage of M-SGD is that it decouples noise from parameters, providing clear insights at the inherent randomness in SGD. Our analysis shows that 1) the M-SGD family, including the vanilla SGD, can be viewed as an minimizer with a data-dependent regularizer resemble of Rademacher complexity, which contributes to the implicit bias of M-SGD; 2) M-SGD holds a strong convergence to a continuous stochastic differential equation under the Gaussian noise assumption, ensuring the path-wise closeness of the discrete and continuous dynamics. For applications, based on M-SGD we design a fast algorithm to inject noise of different types (e.g., Gaussian and Bernoulli) into gradient descent. Based on the algorithm, we further demonstrate that M-SGD can approximate SGD with various noise types and recover the generalization performance, which reveals the potential of M-SGD to solve practical deep learning problems, e.g., large batch training with strong generalization performance. We have validated our observations on multiple practical deep learning scenarios.
StyleNAS: An Empirical Study of Neural Architecture Search to Uncover Surprisingly Fast End-to-End Universal Style Transfer Networks
Jun 06, 2019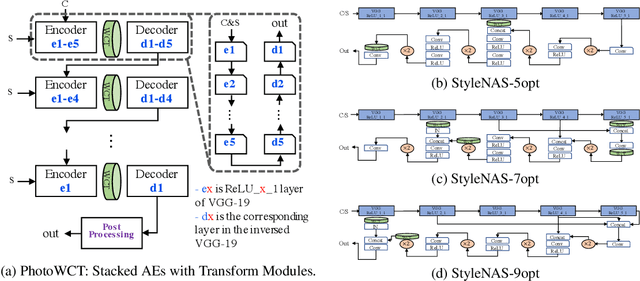

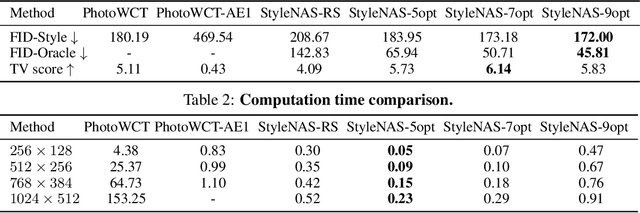
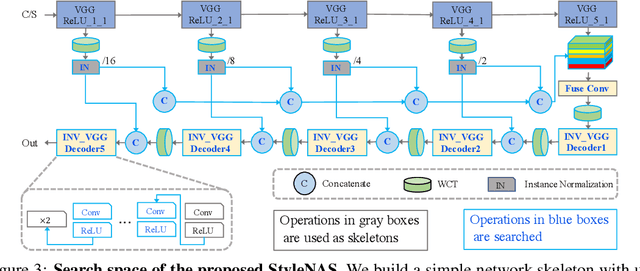
Neural Architecture Search (NAS) has been widely studied for designing discriminative deep learning models such as image classification, object detection, and semantic segmentation. As a large number of priors have been obtained through the manual design of architectures in the fields, NAS is usually considered as a supplement approach. In this paper, we have significantly expanded the application areas of NAS by performing an empirical study of NAS to search generative models, or specifically, auto-encoder based universal style transfer, which lacks systematic exploration, if any, from the architecture search aspect. In our work, we first designed a search space where common operators for image style transfer such as VGG-based encoders, whitening and coloring transforms (WCT), convolution kernels, instance normalization operators, and skip connections were searched in a combinatorial approach. With a simple yet effective parallel evolutionary NAS algorithm with multiple objectives, we derived the first group of end-to-end deep networks for universal photorealistic style transfer. Comparing to random search, a NAS method that is gaining popularity recently, we demonstrated that carefully designed search strategy leads to much better architecture design. Finally compared to existing universal style transfer networks for photorealistic rendering such as PhotoWCT that stacks multiple well-trained auto-encoders and WCT transforms in a non-end-to-end manner, the architectures designed by StyleNAS produce better style-transferred images with details preserving, using a tiny number of operators/parameters, and enjoying around 500x inference time speed-up.
An Empirical Study on Regularization of Deep Neural Networks by Local Rademacher Complexity
Feb 14, 2019
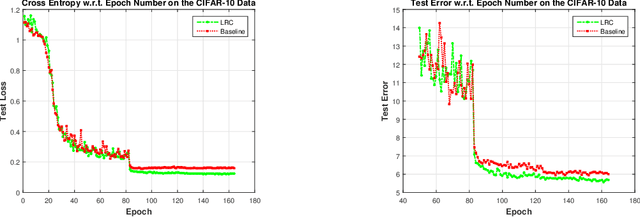
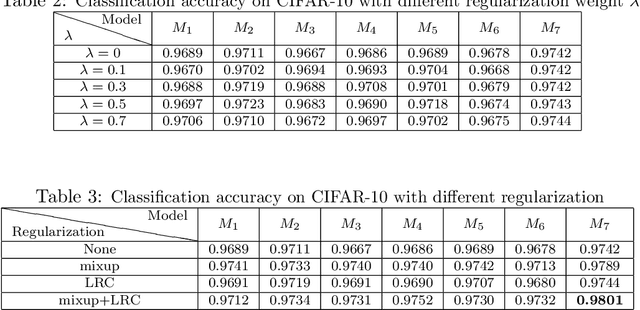
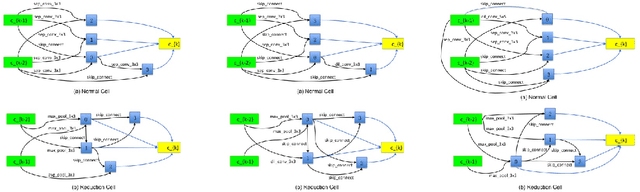
Regularization of Deep Neural Networks (DNNs) for the sake of improving their generalization capability is important and challenging. The development in this line benefits theoretical foundation of DNNs and promotes their usability in different areas of artificial intelligence. In this paper, we investigate the role of Rademacher complexity in improving generalization of DNNs and propose a novel regularizer rooted in Local Rademacher Complexity (LRC). While Rademacher complexity is well known as a distribution-free complexity measure of function class that help boost generalization of statistical learning methods, extensive study shows that LRC, its counterpart focusing on a restricted function class, leads to sharper convergence rates and potential better generalization given finite training sample. Our LRC based regularizer is developed by estimating the complexity of the function class centered at the minimizer of the empirical loss of DNNs. Experiments on various types of network architecture demonstrate the effectiveness of LRC regularization in improving generalization. Moreover, our method features the state-of-the-art result on the CIFAR-$10$ dataset with network architecture found by neural architecture search.