 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACR-Pose: Adversarial Canonical Representation Reconstruction Network for Category Level 6D Object Pose Estimation
Nov 20, 2021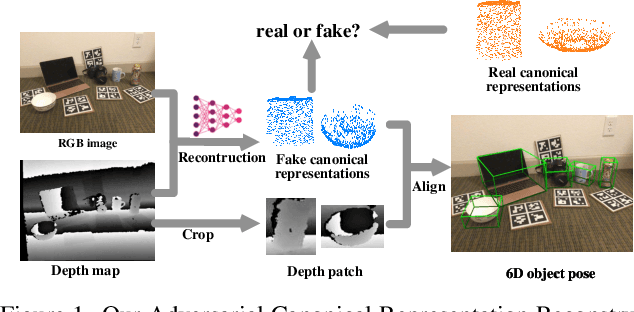
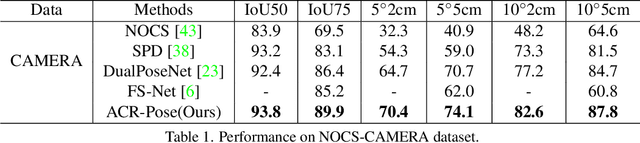
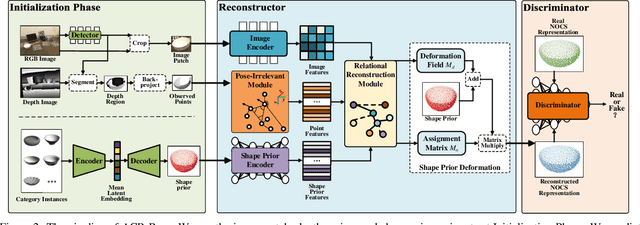
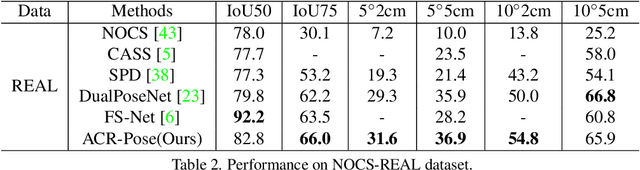
Recently, category-level 6D object pose estimation has achieved significant improvements with the development of reconstructing canonical 3D representations. However, the reconstruction quality of existing methods is still far from excellent. In this paper, we propose a novel Adversarial Canonical Representation Reconstruction Network named ACR-Pose. ACR-Pose consists of a Reconstructor and a Discriminator. The Reconstructor is primarily composed of two novel sub-modules: Pose-Irrelevant Module (PIM) and Relational Reconstruction Module (RRM). PIM tends to learn canonical-related features to make the Reconstructor insensitive to rotation and translation, while RRM explores essential relational information between different input modalities to generate high-quality features. Subsequently, a Discriminator is employed to guide the Reconstructor to generate realistic canonical representations. The Reconstructor and the Discriminator learn to optimize through adversarial training. Experimental results on the prevalent NOCS-CAMERA and NOCS-REAL datasets demonstrate that our method achieves state-of-the-art performance.
Influence of the Binomial Crossover on Performance of Randomized Search Heuristics
Sep 29, 2021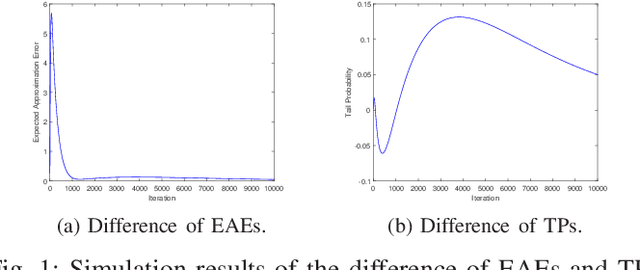
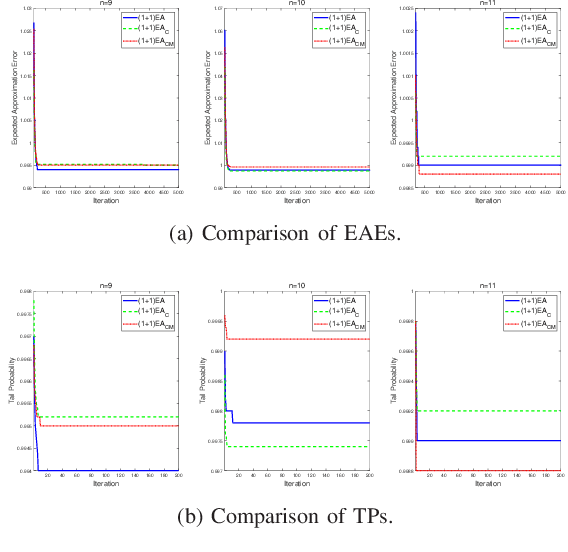
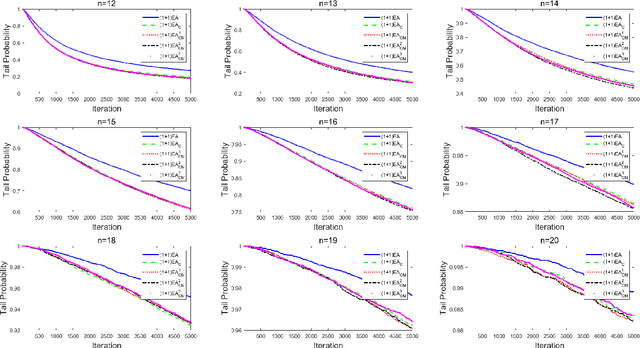
Unlike other metaheuristics, differential Evolution (DE) employs a crossover operation filtering variables to be mutated, which contributes to its successful applications in a variety of complicated optimization problems. However, the underlying working principles of the crossover operation is not yet fully understood. In this paper, we try to reveal the influence of the binomial crossover by performing a theoretical comparison between the $(1+1)EA$ and its variants, the $(1+1)EA_{C}$ and the $(1+1)EA_{CM}$. Generally, the introduction of the binomial crossover contributes to the enhancement of the exploration ability as well as degradation of the exploitation ability, and under some conditions, leads to the dominance of the transition matrix for binary optimization problems. As a result, both the $(1+1)EA_{C}$ and the $(1+1)EA_{CM}$ outperform the $(1+1)EA$ on the unimodal OneMax problem, but do not always dominate it on the Deceptive problem. Finally, we perform exploration analysis by investigating probabilities to transfer from non-optimal statuses to the optimal status of the Deceptive problem, inspired by which adaptive strategies are proposed to improve the ability of global exploration. It suggests that incorporation of the binomial crossover could be a feasible strategy to improve the performances of randomized search heuristics.
An MRC Framework for Semantic Role Labeling
Sep 14, 2021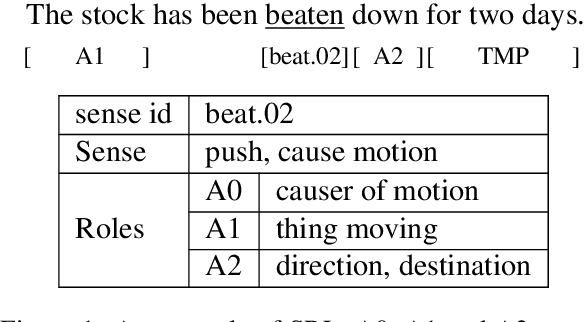
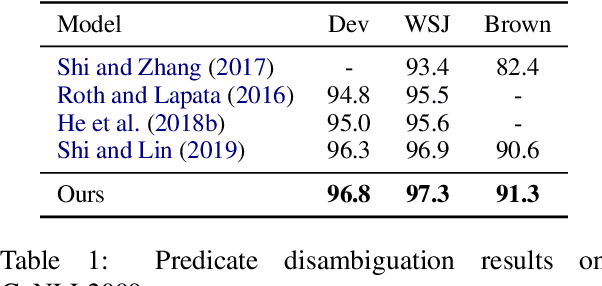

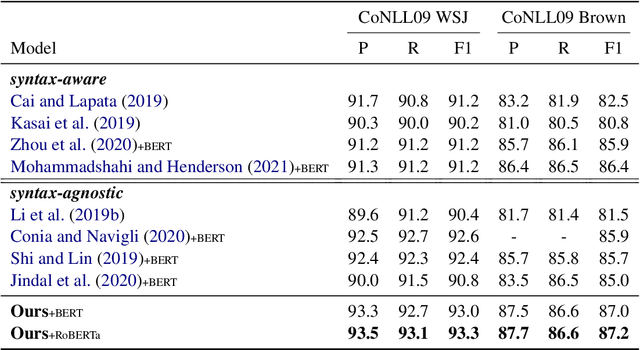
Semantic Role Labeling (SRL) aims at recognizing the predicate-argument structure of a sentence and can be decomposed into two subtasks: predicate disambiguation and argument labeling. Prior work deals with these two tasks independently, which ignores the semantic connection between the two tasks. In this paper, we propose to use the machine reading comprehension (MRC) framework to bridge this gap. We formalize predicate disambiguation as multiple-choice machine reading comprehension, where the descriptions of candidate senses of a given predicate are used as options to select the correct sense. The chosen predicate sense is then used to determine the semantic roles for that predicate, and these semantic roles are used to construct the query for another MRC model for argument labeling. In this way, we are able to leverage both the predicate semantics and the semantic role semantics for argument labeling. We also propose to select a subset of all the possible semantic roles for computational efficiency. Experiments show that the proposed framework achieves state-of-the-art results on both span and dependency benchmarks.
Attentive Rotation Invariant Convolution for Point Cloud-based Large Scale Place Recognition
Aug 29, 2021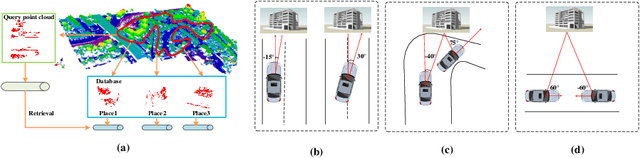
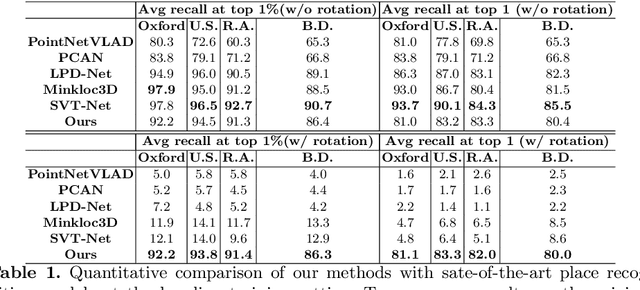
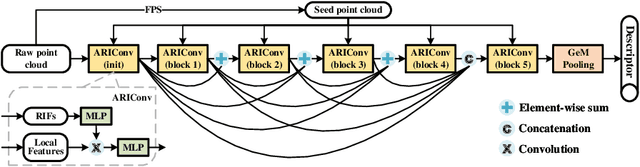
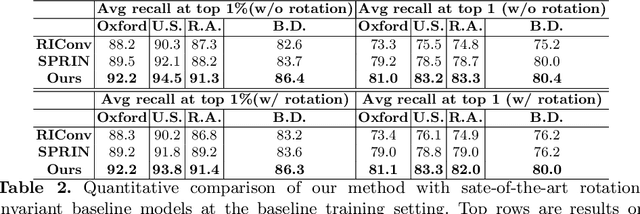
Autonomous Driving and Simultaneous Localization and Mapping(SLAM) are becoming increasingly important in real world, where point cloud-based large scale place recognition is the spike of them. Previous place recognition methods have achieved acceptable performances by regarding the task as a point cloud retrieval problem. However, all of them are suffered from a common defect: they can't handle the situation when the point clouds are rotated, which is common, e.g, when viewpoints or motorcycle types are changed. To tackle this issue, we propose an Attentive Rotation Invariant Convolution (ARIConv) in this paper. The ARIConv adopts three kind of Rotation Invariant Features (RIFs): Spherical Signals (SS), Individual-Local Rotation Invariant Features (ILRIF) and Group-Local Rotation Invariant features (GLRIF) in its structure to learn rotation invariant convolutional kernels, which are robust for learning rotation invariant point cloud features. What's more, to highlight pivotal RIFs, we inject an attentive module in ARIConv to give different RIFs different importance when learning kernels. Finally, utilizing ARIConv, we build a DenseNet-like network architecture to learn rotation-insensitive global descriptors used for retrieving. We experimentally demonstrate that our model can achieve state-of-the-art performance on large scale place recognition task when the point cloud scans are rotated and can achieve comparable results with most of existing methods on the original non-rotated datasets.
Improving Entity Linking through Semantic Reinforced Entity Embeddings
Jun 16, 2021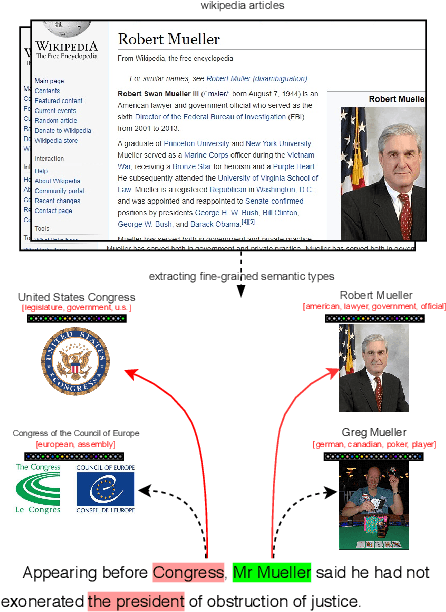
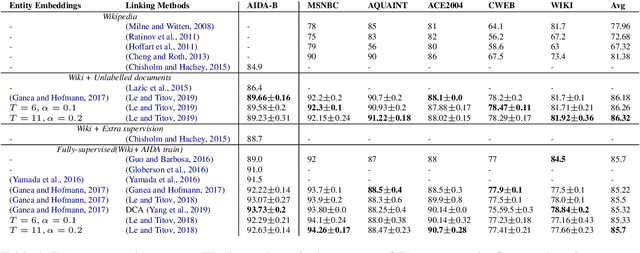
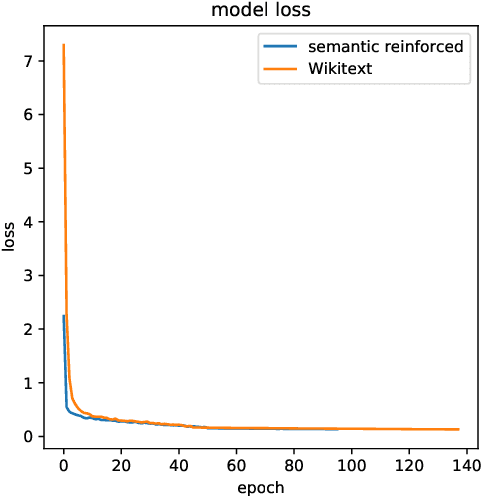
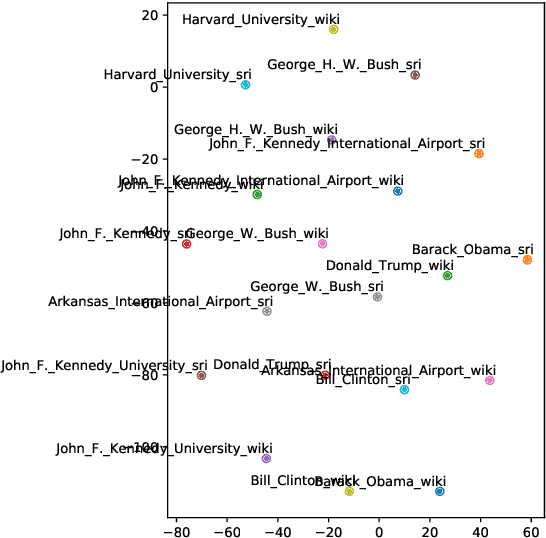
Entity embeddings, which represent different aspects of each entity with a single vector like word embeddings, are a key component of neural entity linking models. Existing entity embeddings are learned from canonical Wikipedia articles and local contexts surrounding target entities. Such entity embeddings are effective, but too distinctive for linking models to learn contextual commonality. We propose a simple yet effective method, FGS2EE, to inject fine-grained semantic information into entity embeddings to reduce the distinctiveness and facilitate the learning of contextual commonality. FGS2EE first uses the embeddings of semantic type words to generate semantic embeddings, and then combines them with existing entity embeddings through linear aggregation. Extensive experiments show the effectiveness of such embeddings. Based on our entity embeddings, we achieved new sate-of-the-art performance on entity linking.
* 6 pages, 3 figures, ACL 2020
SVT-Net: Super Light-Weight Sparse Voxel Transformer for Large Scale Place Recognition
May 30, 2021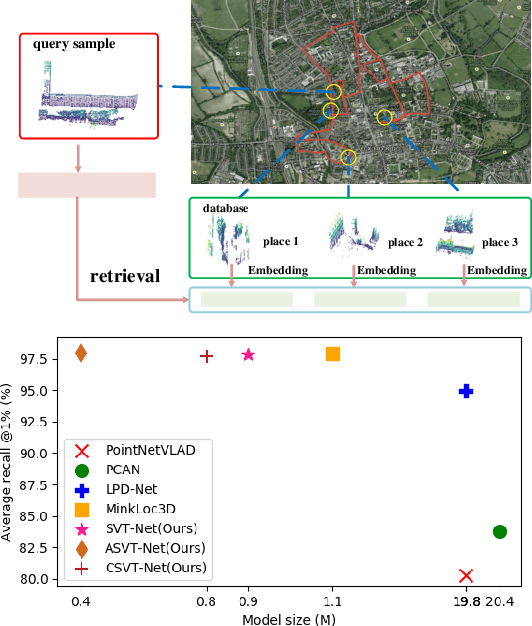
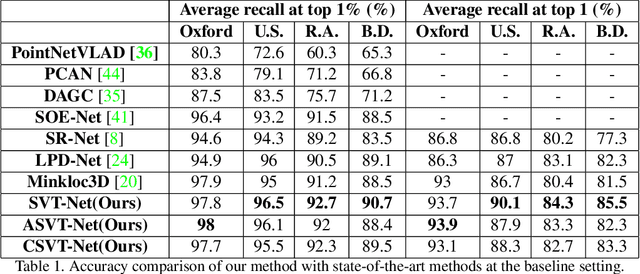
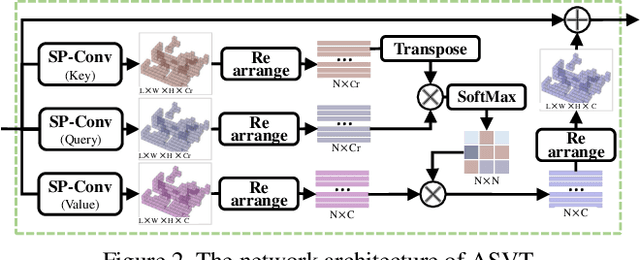
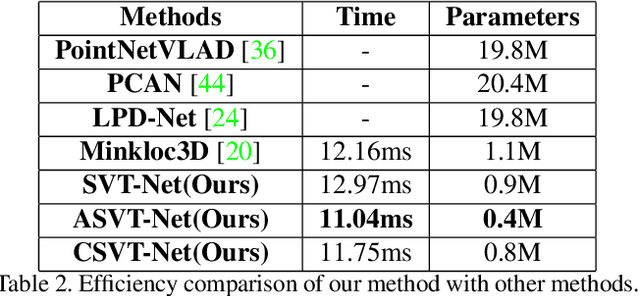
Point cloud-based large scale place recognition is fundamental for many applications like Simultaneous Localization and Mapping (SLAM). Although many models have been proposed and have achieved good performance by learning short-range local features, long-range contextual properties have often been neglected. Moreover, the model size has also become a bottleneck for their wide applications. To overcome these challenges, we propose a super light-weight network model termed SVT-Net for large scale place recognition. Specifically, on top of the highly efficient 3D Sparse Convolution (SP-Conv), an Atom-based Sparse Voxel Transformer (ASVT) and a Cluster-based Sparse Voxel Transformer (CSVT) are proposed to learn both short-range local features and long-range contextual features in this model. Consisting of ASVT and CSVT, SVT-Net can achieve state-of-the-art on benchmark datasets in terms of both accuracy and speed with a super-light model size (0.9M). Meanwhile, two simplified versions of SVT-Net are introduced, which also achieve state-of-the-art and further reduce the model size to 0.8M and 0.4M respectively.
Deep Learning on Monocular Object Pose Detection and Tracking: A Comprehensive Overview
May 29, 2021
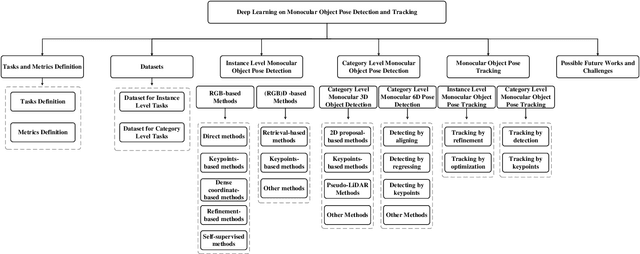

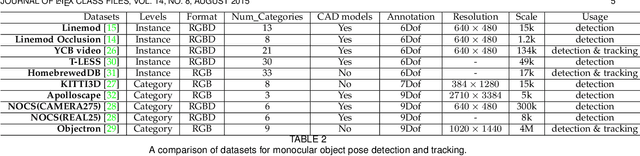
Object pose detection and tracking has recently attracted increasing attention due to its wide applications in many areas, such as autonomous driving, robotics, and augmented reality. Among methods for object pose detection and tracking, deep learning is the most promising one that has shown better performance than others. However, there is lack of survey study about latest development of deep learning based methods. Therefore, this paper presents a comprehensive review of recent progress in object pose detection and tracking that belongs to the deep learning technical route. To achieve a more thorough introduction, the scope of this paper is limited to methods taking monocular RGB/RGBD data as input, covering three kinds of major tasks: instance-level monocular object pose detection, category-level monocular object pose detection, and monocular object pose tracking. In our work, metrics, datasets, and methods about both detection and tracking are presented in detail. Comparative results of current state-of-the-art methods on several publicly available datasets are also presented, together with insightful observations and inspiring future research directions.
Revisiting Deep Local Descriptor for Improved Few-Shot Classification
Mar 30, 2021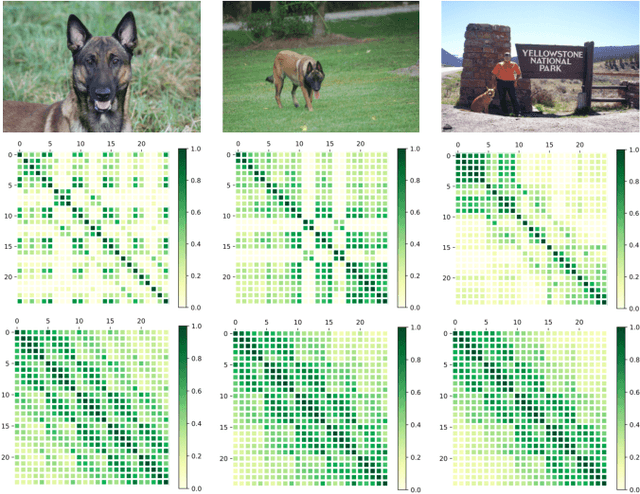
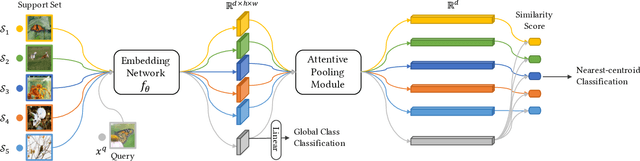
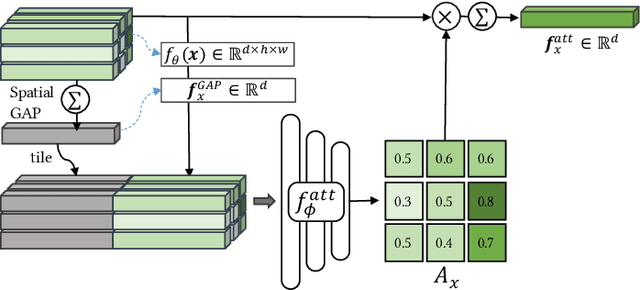
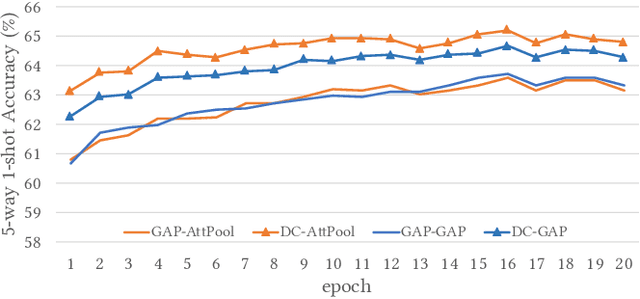
Few-shot classification studies the problem of quickly adapting a deep learner to understanding novel classes based on few support images. In this context, recent research efforts have been aimed at designing more and more complex classifiers that measure similarities between query and support images, but left the importance of feature embeddings seldom explored. We show that the reliance on sophisticated classifier is not necessary and a simple classifier applied directly to improved feature embeddings can outperform state-of-the-art methods. To this end, we present a new method named \textbf{DCAP} in which we investigate how one can improve the quality of embeddings by leveraging \textbf{D}ense \textbf{C}lassification and \textbf{A}ttentive \textbf{P}ooling. Specifically, we propose to pre-train a learner on base classes with abundant samples to solve dense classification problem first and then fine-tune the learner on a bunch of randomly sampled few-shot tasks to adapt it to few-shot scenerio or the test time scenerio. We suggest to pool feature maps by applying attentive pooling instead of the widely used global average pooling (GAP) to prepare embeddings for few-shot classification during meta-finetuning. Attentive pooling learns to reweight local descriptors, explaining what the learner is looking for as evidence for decision making. Experiments on two benchmark datasets show the proposed method to be superior in multiple few-shot settings while being simpler and more explainable. Code is available at: \url{https://github.com/Ukeyboard/dcap/}.
LID 2020: The Learning from Imperfect Data Challenge Results
Oct 17, 2020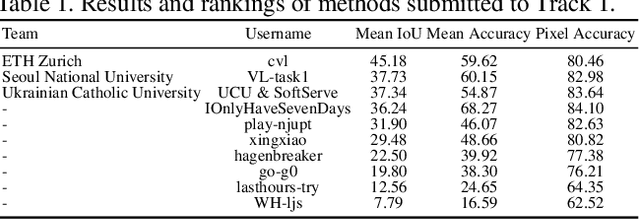
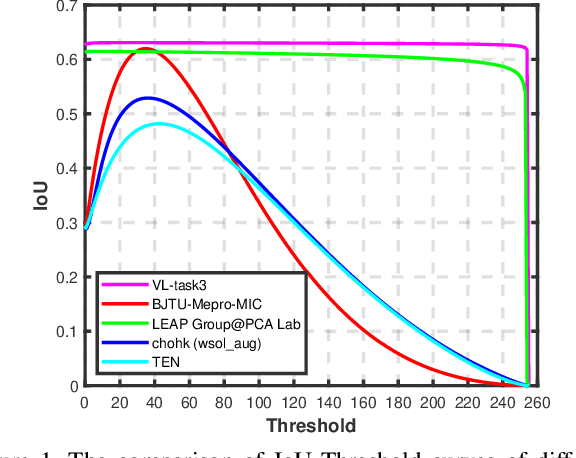

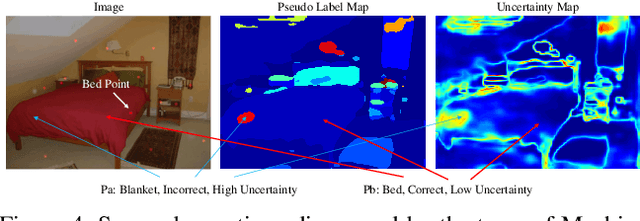
Learning from imperfect data becomes an issue in many industrial applications after the research community has made profound progress in supervised learning from perfectly annotated datasets. The purpose of the Learning from Imperfect Data (LID) workshop is to inspire and facilitate the research in developing novel approaches that would harness the imperfect data and improve the data-efficiency during training. A massive amount of user-generated data nowadays available on multiple internet services. How to leverage those and improve the machine learning models is a high impact problem. We organize the challenges in conjunction with the workshop. The goal of these challenges is to find the state-of-the-art approaches in the weakly supervised learning setting for object detection, semantic segmentation, and scene parsing. There are three tracks in the challenge, i.e., weakly supervised semantic segmentation (Track 1), weakly supervised scene parsing (Track 2), and weakly supervised object localization (Track 3). In Track 1, based on ILSVRC DET, we provide pixel-level annotations of 15K images from 200 categories for evaluation. In Track 2, we provide point-based annotations for the training set of ADE20K. In Track 3, based on ILSVRC CLS-LOC, we provide pixel-level annotations of 44,271 images for evaluation. Besides, we further introduce a new evaluation metric proposed by \cite{zhang2020rethinking}, i.e., IoU curve, to measure the quality of the generated object localization maps. This technical report summarizes the highlights from the challenge. The challenge submission server and the leaderboard will continue to open for the researchers who are interested in it. More details regarding the challenge and the benchmarks are available at https://lidchallenge.github.io
DanHAR: Dual Attention Network For Multimodal Human Activity Recognition Using Wearable Sensors
Jun 25, 2020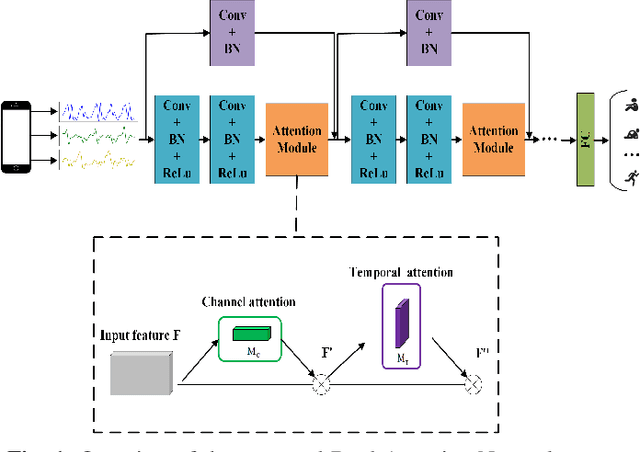
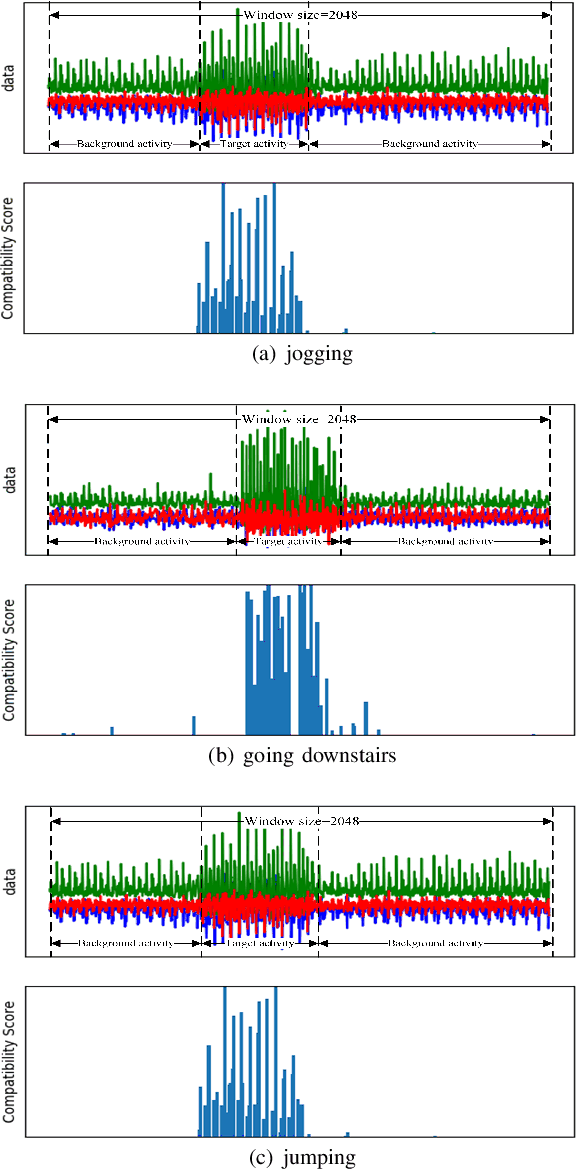
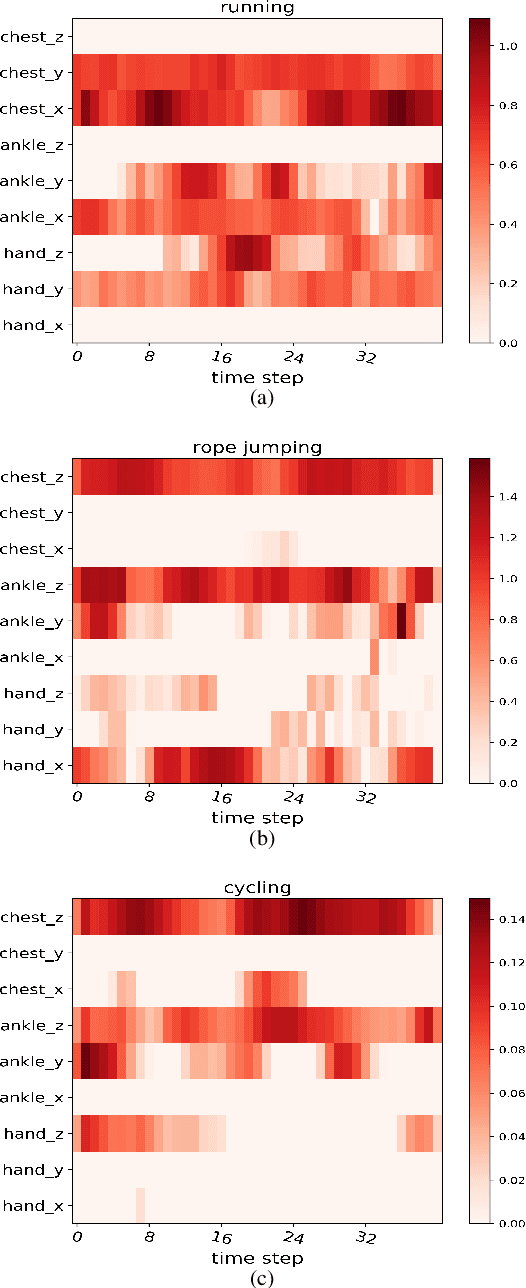
Human activity recognition (HAR) in ubiquitous computing has been beginning to incorporate attention into the context of deep neural networks (DNNs), in which the rich sensing data from multimodal sensors such as accelerometer and gyroscope is used to infer human activities. Recently, two attention methods are proposed via combining with Gated Recurrent Units (GRU) and Long Short-Term Memory (LSTM) network, which can capture the dependencies of sensing signals in both spatial and temporal domains simultaneously. However, recurrent networks often have a weak feature representing power compared with convolutional neural networks (CNNs). On the other hand, two attention, i.e., hard attention and soft attention, are applied in temporal domains via combining with CNN, which pay more attention to the target activity from a long sequence. However, they can only tell where to focus and miss channel information, which plays an important role in deciding what to focus. As a result, they fail to address the spatial-temporal dependencies of multimodal sensing signals, compared with attention-based GRU or LSTM. In the paper, we propose a novel dual attention method called DanHAR, which introduces the framework of blending channel attention and temporal attention on a CNN, demonstrating superiority in improving the comprehensibility for multimodal HAR. Extensive experiments on four public HAR datasets and weakly labeled dataset show that DanHAR achieves state-of-the-art performance with negligible overhead of parameters. Furthermore, visualizing analysis is provided to show that our attention can amplifies more important sensor modalities and timesteps during classification, which agrees well with human common intuition.