 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Evaluation Framework for Deep Model Robustness
Jan 24, 2021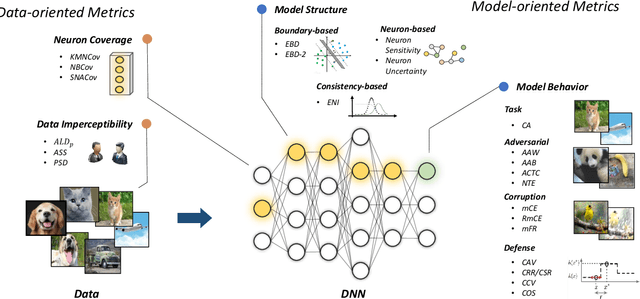
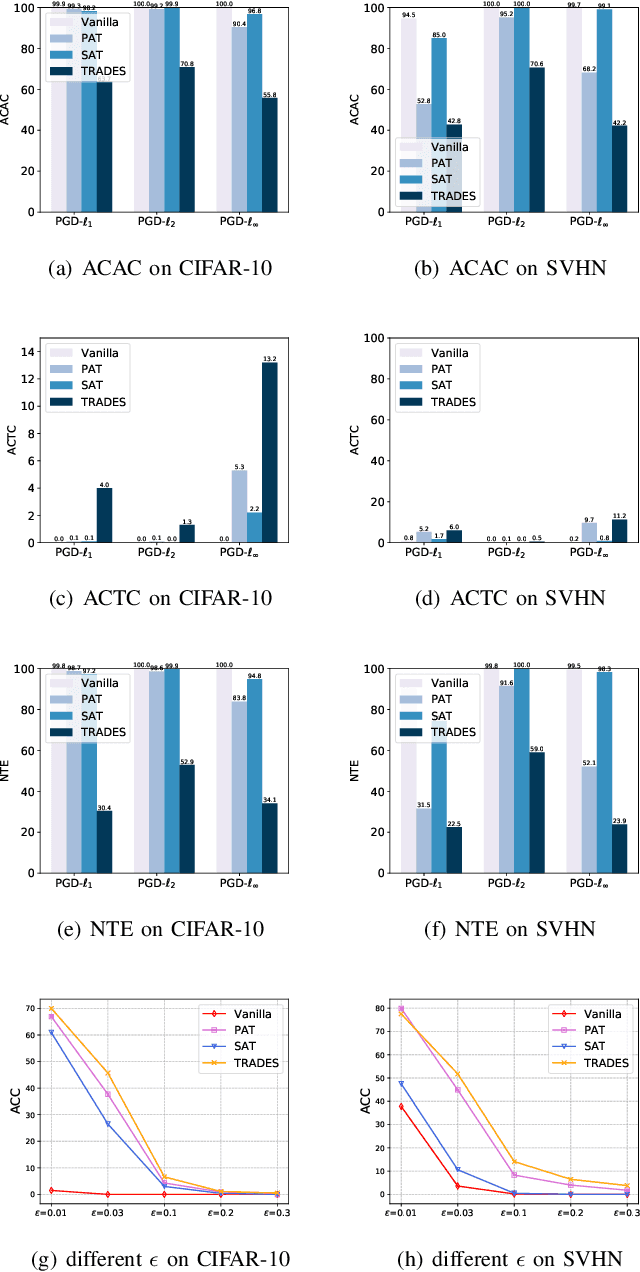
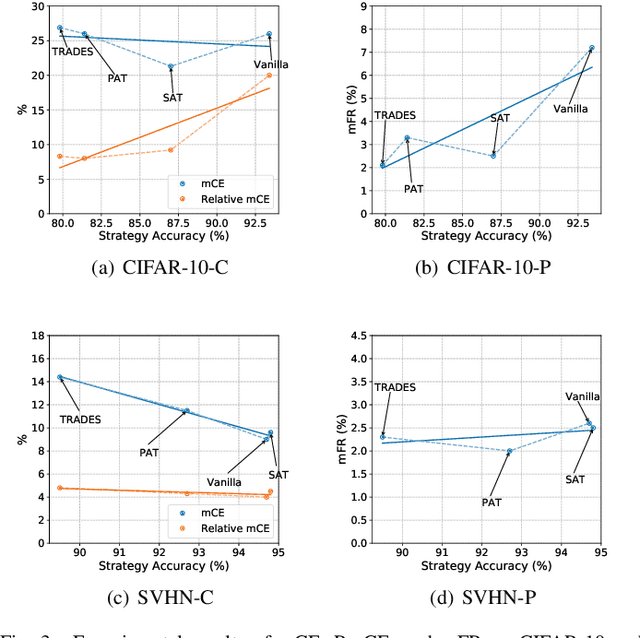
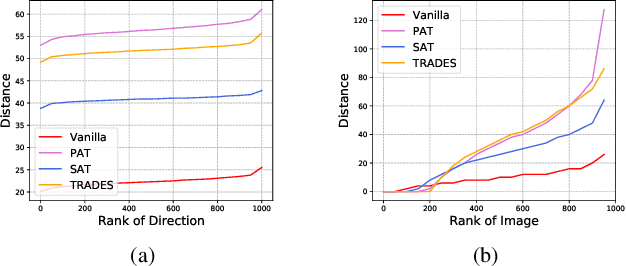
Deep neural networks (DNNs) have achieved remarkable performance across a wide area of applications. However, they are vulnerable to adversarial examples, which motivates the adversarial defense. By adopting simple evaluation metrics, most of the current defenses only conduct incomplete evaluations, which are far from providing comprehensive understandings of the limitations of these defenses. Thus, most proposed defenses are quickly shown to be attacked successfully, which result in the "arm race" phenomenon between attack and defense. To mitigate this problem, we establish a model robustness evaluation framework containing a comprehensive, rigorous, and coherent set of evaluation metrics, which could fully evaluate model robustness and provide deep insights into building robust models. With 23 evaluation metrics in total, our framework primarily focuses on the two key factors of adversarial learning (\ie, data and model). Through neuron coverage and data imperceptibility, we use data-oriented metrics to measure the integrity of test examples; by delving into model structure and behavior, we exploit model-oriented metrics to further evaluate robustness in the adversarial setting. To fully demonstrate the effectiveness of our framework, we conduct large-scale experiments on multiple datasets including CIFAR-10 and SVHN using different models and defenses with our open-source platform AISafety. Overall, our paper aims to provide a comprehensive evaluation framework which could demonstrate detailed inspections of the model robustness, and we hope that our paper can inspire further improvement to the model robustness.
Progressive Co-Attention Network for Fine-grained Visual Classification
Jan 21, 2021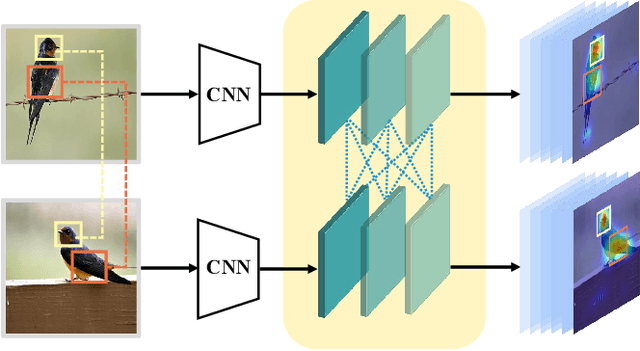

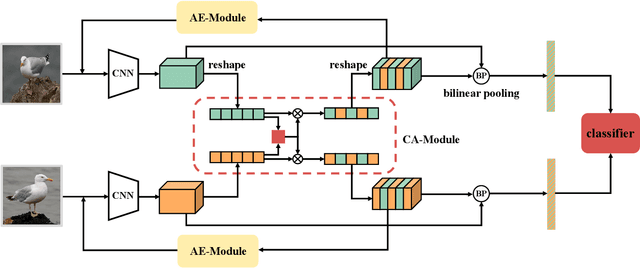

Fine-grained visual classification aims to recognize images belonging to multiple sub-categories within a same category. It is a challenging task due to the inherently subtle variations among highly-confused categories. Most existing methods only take individual image as input, which may limit the ability of models to recognize contrastive clues from different images. In this paper, we propose an effective method called progressive co-attention network (PCA-Net) to tackle this problem. Specifically, we calculate the channel-wise similarity by interacting the feature channels within same-category images to capture the common discriminative features. Considering that complementary imformation is also crucial for recognition, we erase the prominent areas enhanced by the channel interaction to force the network to focus on other discriminative regions. The proposed model can be trained in an end-to-end manner, and only requires image-level label supervision. It has achieved competitive results on three fine-grained visual classification benchmark datasets: CUB-200-2011, Stanford Cars, and FGVC Aircraft.
Knowledge Transfer Based Fine-grained Visual Classification
Dec 21, 2020
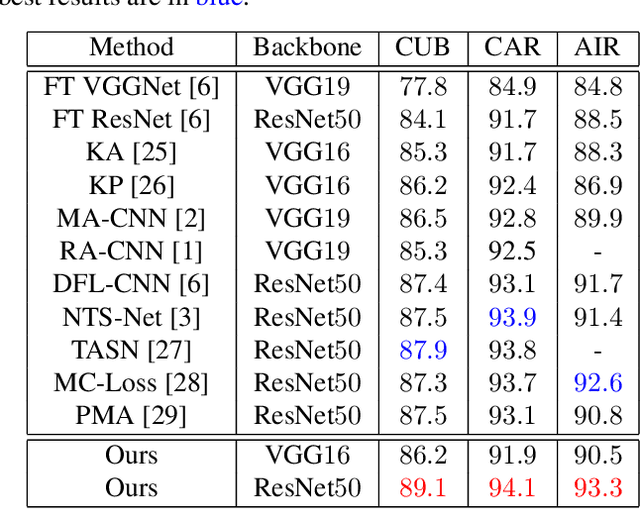
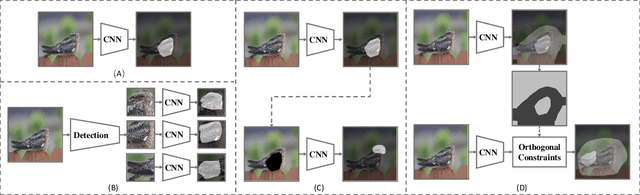

Fine-grained visual classification (FGVC) aims to distinguish the sub-classes of the same category and its essential solution is to mine the subtle and discriminative regions. Convolution neural networks (CNNs), which employ the cross entropy loss (CE-loss) as the loss function, show poor performance since the model can only learn the most discriminative part and ignore other meaningful regions. Some existing works try to solve this problem by mining more discriminative regions by some detection techniques or attention mechanisms. However, most of them will meet the background noise problem when trying to find more discriminative regions. In this paper, we address it in a knowledge transfer learning manner. Multiple models are trained one by one, and all previously trained models are regarded as teacher models to supervise the training of the current one. Specifically, a orthogonal loss (OR-loss) is proposed to encourage the network to find diverse and meaningful regions. In addition, the first model is trained with only CE-Loss. Finally, all models' outputs with complementary knowledge are combined together for the final prediction result. We demonstrate the superiority of the proposed method and obtain state-of-the-art (SOTA) performances on three popular FGVC datasets.
Your "Labrador" is My "Dog": Fine-Grained, or Not
Nov 18, 2020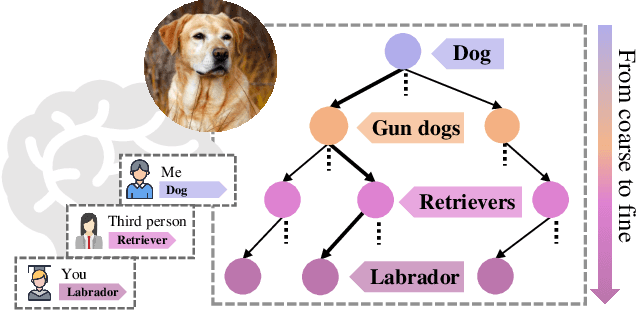

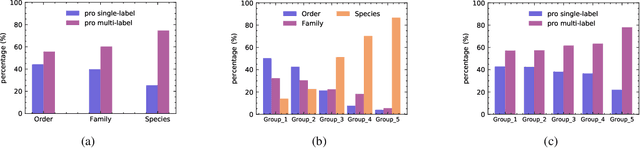
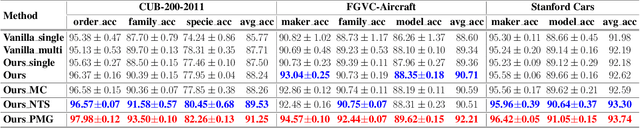
Whether what you see in Figure 1 is a "labrador" or a "dog", is the question we ask in this paper. While fine-grained visual classification (FGVC) strives to arrive at the former, for the majority of us non-experts just "dog" would probably suffice. The real question is therefore -- how can we tailor for different fine-grained definitions under divergent levels of expertise. For that, we re-envisage the traditional setting of FGVC, from single-label classification, to that of top-down traversal of a pre-defined coarse-to-fine label hierarchy -- so that our answer becomes "dog"-->"gun dog"-->"retriever"-->"labrador". To approach this new problem, we first conduct a comprehensive human study where we confirm that most participants prefer multi-granularity labels, regardless whether they consider themselves experts. We then discover the key intuition that: coarse-level label prediction exacerbates fine-grained feature learning, yet fine-level feature betters the learning of coarse-level classifier. This discovery enables us to design a very simple albeit surprisingly effective solution to our new problem, where we (i) leverage level-specific classification heads to disentangle coarse-level features with fine-grained ones, and (ii) allow finer-grained features to participate in coarser-grained label predictions, which in turn helps with better disentanglement. Experiments show that our method achieves superior performance in the new FGVC setting, and performs better than state-of-the-art on traditional single-label FGVC problem as well. Thanks to its simplicity, our method can be easily implemented on top of any existing FGVC frameworks and is parameter-free.
DS-UI: Dual-Supervised Mixture of Gaussian Mixture Models for Uncertainty Inference
Nov 17, 2020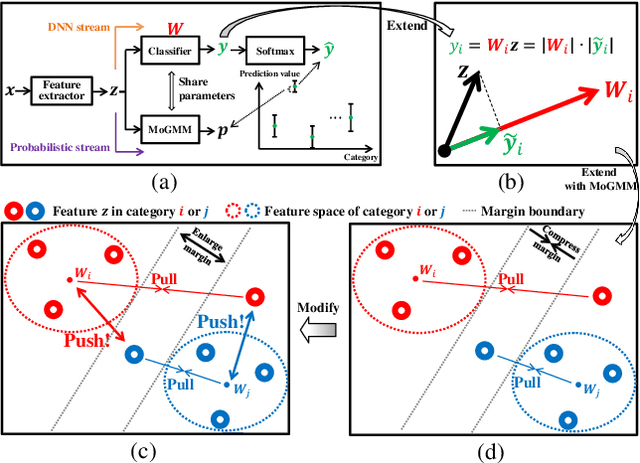
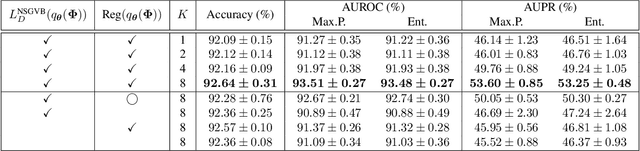
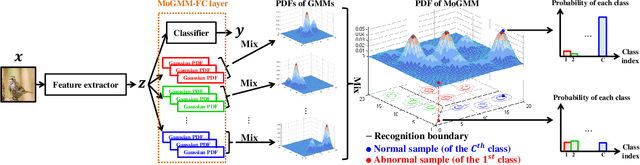
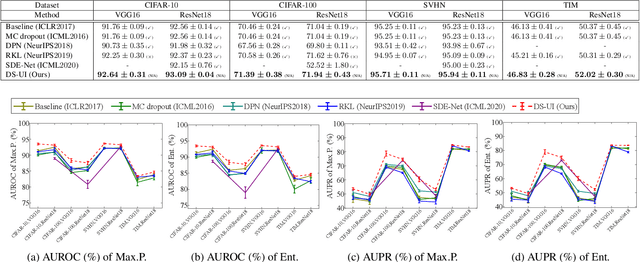
This paper proposes a dual-supervised uncertainty inference (DS-UI) framework for improving Bayesian estimation-based uncertainty inference (UI) in deep neural network (DNN)-based image recognition. In the DS-UI, we combine the classifier of a DNN, i.e., the last fully-connected (FC) layer, with a mixture of Gaussian mixture models (MoGMM) to obtain an MoGMM-FC layer. Unlike existing UI methods for DNNs, which only calculate the means or modes of the DNN outputs' distributions, the proposed MoGMM-FC layer acts as a probabilistic interpreter for the features that are inputs of the classifier to directly calculate the probability density of them for the DS-UI. In addition, we propose a dual-supervised stochastic gradient-based variational Bayes (DS-SGVB) algorithm for the MoGMM-FC layer optimization. Unlike conventional SGVB and optimization algorithms in other UI methods, the DS-SGVB not only models the samples in the specific class for each Gaussian mixture model (GMM) in the MoGMM, but also considers the negative samples from other classes for the GMM to reduce the intra-class distances and enlarge the inter-class margins simultaneously for enhancing the learning ability of the MoGMM-FC layer in the DS-UI. Experimental results show the DS-UI outperforms the state-of-the-art UI methods in misclassification detection. We further evaluate the DS-UI in open-set out-of-domain/-distribution detection and find statistically significant improvements. Visualizations of the feature spaces demonstrate the superiority of the DS-UI.
Advanced Dropout: A Model-free Methodology for Bayesian Dropout Optimization
Oct 11, 2020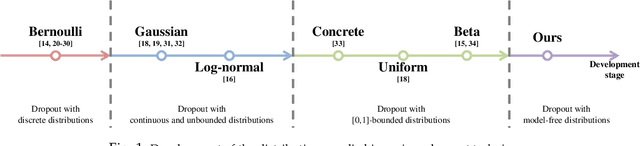
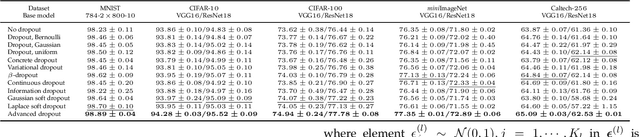
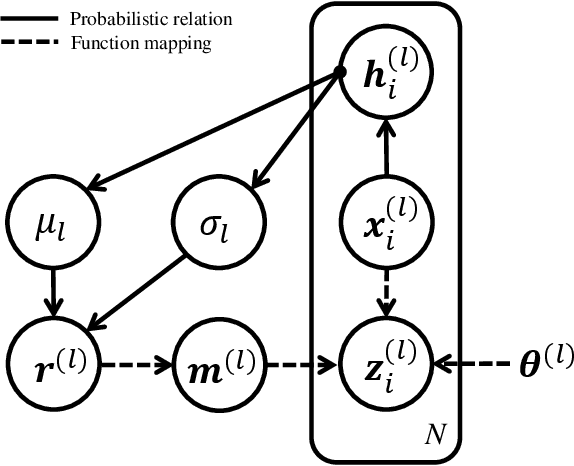

Due to lack of data, overfitting ubiquitously exists in real-world applications of deep neural networks (DNNs). In this paper, we propose advanced dropout, a model-free methodology, to mitigate overfitting and improve the performance of DNNs. The advanced dropout technique applies a model-free and easily implemented distribution with a parametric prior, and adaptively adjusts dropout rate. Specifically, the distribution parameters are optimized by stochastic gradient variational Bayes (SGVB) inference in order to carry out an end-to-end training of DNNs. We evaluate the effectiveness of the advanced dropout against nine dropout techniques on five widely used datasets in computer vision. The advanced dropout outperforms all the referred techniques by 0.83% on average for all the datasets. An ablation study is conducted to analyze the effectiveness of each component. Meanwhile, convergence of dropout rate and ability to prevent overfitting are discussed in terms of classification performance. Moreover, we extend the application of the advanced dropout to uncertainty inference and network pruning, and we find that the advanced dropout is superior to the corresponding referred methods. The advanced dropout improves classification accuracies by 4% in uncertainty inference and by 0.2% and 0.5% when pruning more than 90% of nodes and 99.8% of parameters, respectively.
Transformer-GCRF: Recovering Chinese Dropped Pronouns with General Conditional Random Fields
Oct 07, 2020
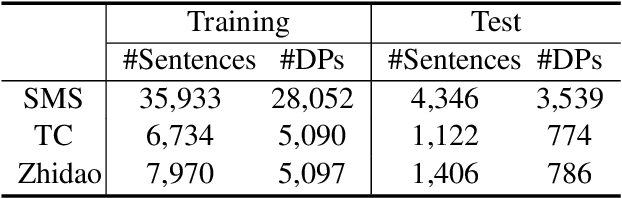
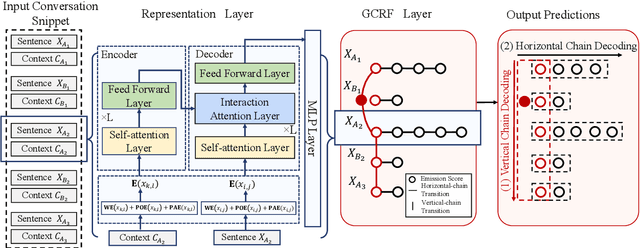
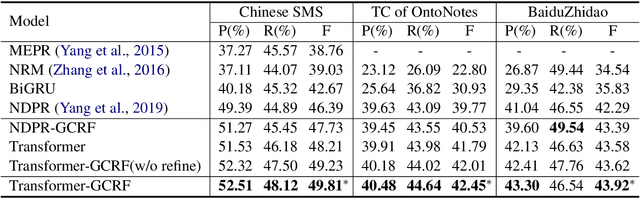
Pronouns are often dropped in Chinese conversations and recovering the dropped pronouns is important for NLP applications such as Machine Translation. Existing approaches usually formulate this as a sequence labeling task of predicting whether there is a dropped pronoun before each token and its type. Each utterance is considered to be a sequence and labeled independently. Although these approaches have shown promise, labeling each utterance independently ignores the dependencies between pronouns in neighboring utterances. Modeling these dependencies is critical to improving the performance of dropped pronoun recovery. In this paper, we present a novel framework that combines the strength of Transformer network with General Conditional Random Fields (GCRF) to model the dependencies between pronouns in neighboring utterances. Results on three Chinese conversation datasets show that the Transformer-GCRF model outperforms the state-of-the-art dropped pronoun recovery models. Exploratory analysis also demonstrates that the GCRF did help to capture the dependencies between pronouns in neighboring utterances, thus contributes to the performance improvements.
SSKD: Self-Supervised Knowledge Distillation for Cross Domain Adaptive Person Re-Identification
Sep 13, 2020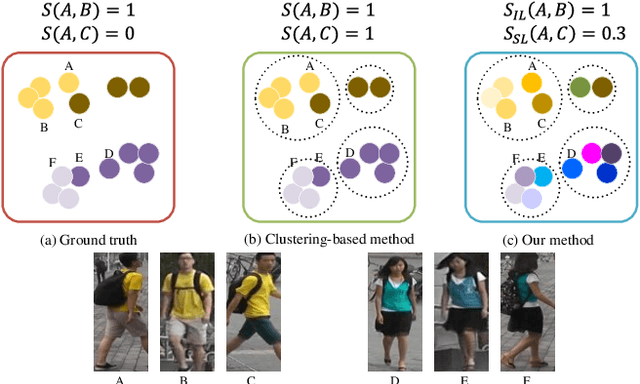
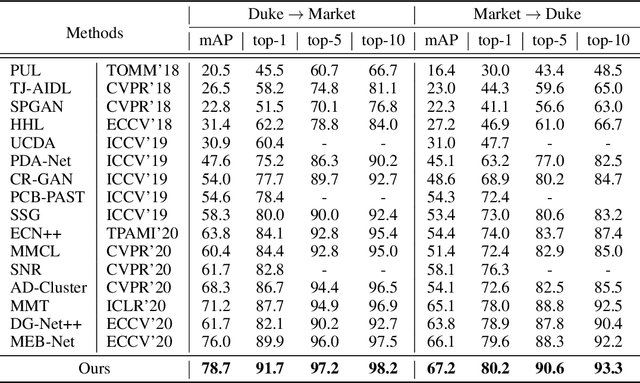
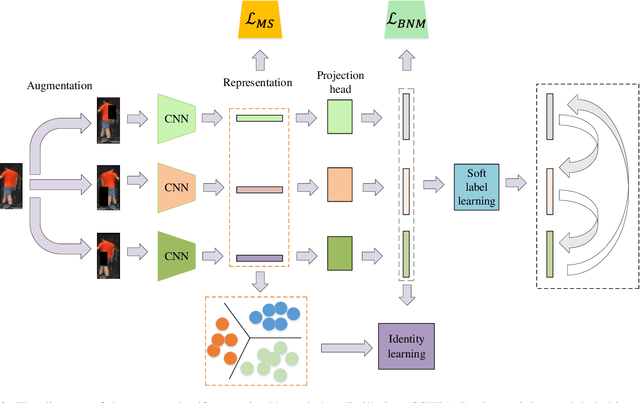
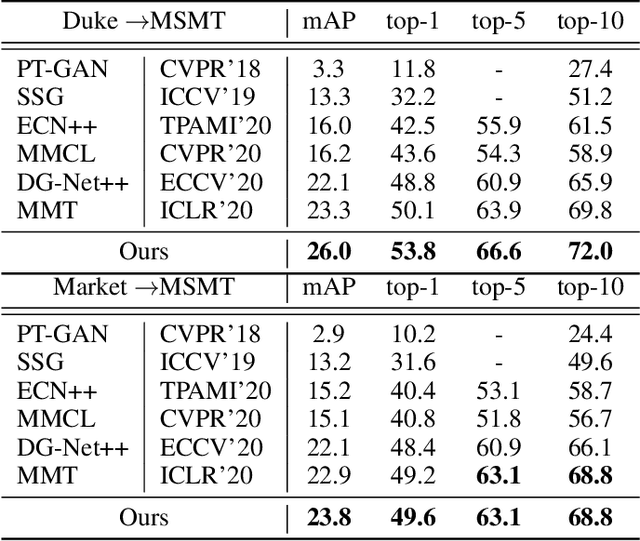
Domain adaptive person re-identification (re-ID) is a challenging task due to the large discrepancy between the source domain and the target domain. To reduce the domain discrepancy, existing methods mainly attempt to generate pseudo labels for unlabeled target images by clustering algorithms. However, clustering methods tend to bring noisy labels and the rich fine-grained details in unlabeled images are not sufficiently exploited. In this paper, we seek to improve the quality of labels by capturing feature representation from multiple augmented views of unlabeled images. To this end, we propose a Self-Supervised Knowledge Distillation (SSKD) technique containing two modules, the identity learning and the soft label learning. Identity learning explores the relationship between unlabeled samples and predicts their one-hot labels by clustering to give exact information for confidently distinguished images. Soft label learning regards labels as a distribution and induces an image to be associated with several related classes for training peer network in a self-supervised manner, where the slowly evolving network is a core to obtain soft labels as a gentle constraint for reliable images. Finally, the two modules can resist label noise for re-ID by enhancing each other and systematically integrating label information from unlabeled images. Extensive experiments on several adaptation tasks demonstrate that the proposed method outperforms the current state-of-the-art approaches by large margins.
ReMarNet: Conjoint Relation and Margin Learning for Small-Sample Image Classification
Jun 27, 2020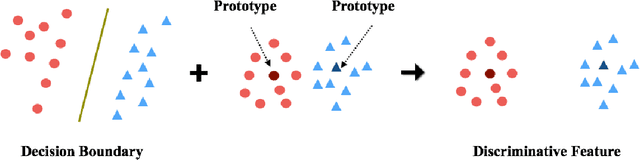
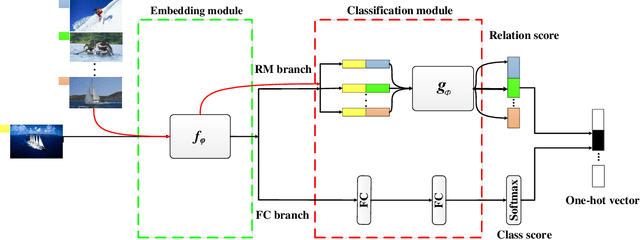
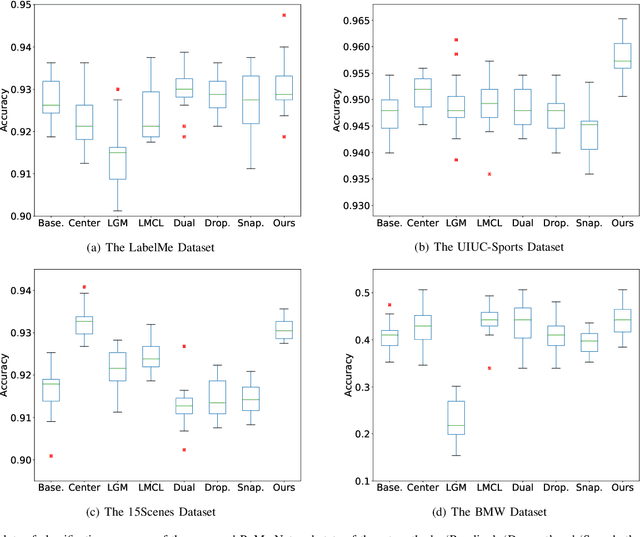
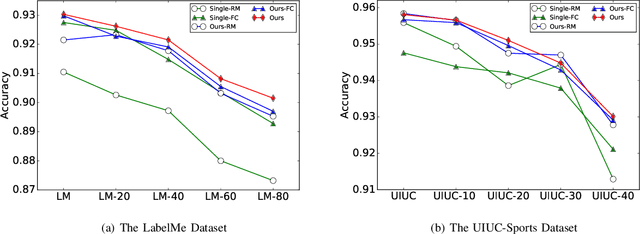
Despite achieving state-of-the-art performance, deep learning methods generally require a large amount of labeled data during training and may suffer from overfitting when the sample size is small. To ensure good generalizability of deep networks under small sample sizes, learning discriminative features is crucial. To this end, several loss functions have been proposed to encourage large intra-class compactness and inter-class separability. In this paper, we propose to enhance the discriminative power of features from a new perspective by introducing a novel neural network termed Relation-and-Margin learning Network (ReMarNet). Our method assembles two networks of different backbones so as to learn the features that can perform excellently in both of the aforementioned two classification mechanisms. Specifically, a relation network is used to learn the features that can support classification based on the similarity between a sample and a class prototype; at the meantime, a fully connected network with the cross entropy loss is used for classification via the decision boundary. Experiments on four image datasets demonstrate that our approach is effective in learning discriminative features from a small set of labeled samples and achieves competitive performance against state-of-the-art methods. Codes are available at https://github.com/liyunyu08/ReMarNet.
Attention-guided Context Feature Pyramid Network for Object Detection
May 23, 2020
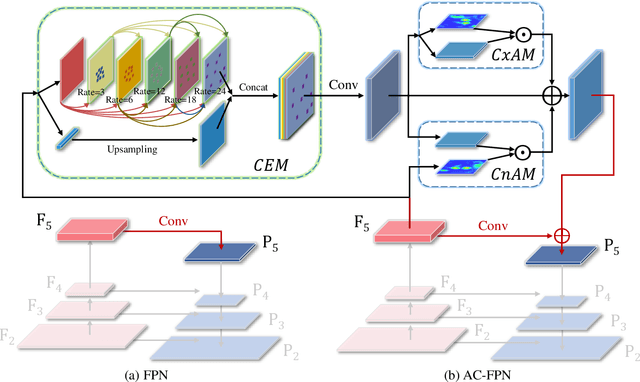
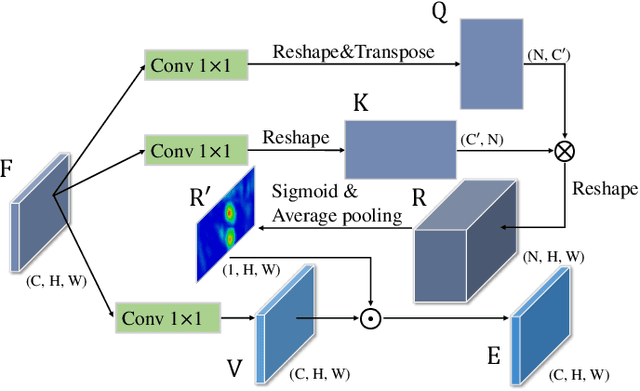
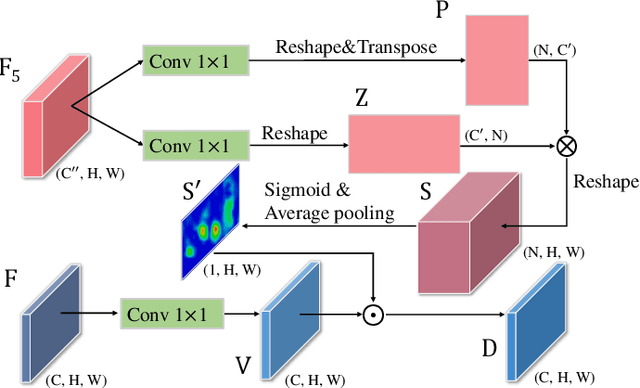
For object detection, how to address the contradictory requirement between feature map resolution and receptive field on high-resolution inputs still remains an open question. In this paper, to tackle this issue, we build a novel architecture, called Attention-guided Context Feature Pyramid Network (AC-FPN), that exploits discriminative information from various large receptive fields via integrating attention-guided multi-path features. The model contains two modules. The first one is Context Extraction Module (CEM) that explores large contextual information from multiple receptive fields. As redundant contextual relations may mislead localization and recognition, we also design the second module named Attention-guided Module (AM), which can adaptively capture the salient dependencies over objects by using the attention mechanism. AM consists of two sub-modules, i.e., Context Attention Module (CxAM) and Content Attention Module (CnAM), which focus on capturing discriminative semantics and locating precise positions, respectively. Most importantly, our AC-FPN can be readily plugged into existing FPN-based models. Extensive experiments on object detection and instance segmentation show that existing models with our proposed CEM and AM significantly surpass their counterparts without them, and our model successfully obtains state-of-the-art results. We have released the source code at https://github.com/Caojunxu/AC-FPN.