 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Long-Term Person Re-Identification with Clothes Change
Feb 08, 2022



We investigate unsupervised person re-identification (Re-ID) with clothes change, a new challenging problem with more practical usability and scalability to real-world deployment. Most existing re-id methods artificially assume the clothes of every single person to be stationary across space and time. This condition is mostly valid for short-term re-id scenarios since an average person would often change the clothes even within a single day. To alleviate this assumption, several recent works have introduced the clothes change facet to re-id, with a focus on supervised learning person identity discriminative representation with invariance to clothes changes. Taking a step further towards this long-term re-id direction, we further eliminate the requirement of person identity labels, as they are significantly more expensive and more tedious to annotate in comparison to short-term person re-id datasets. Compared to conventional unsupervised short-term re-id, this new problem is drastically more challenging as different people may have similar clothes whilst the same person can wear multiple suites of clothes over different locations and times with very distinct appearance. To overcome such obstacles, we introduce a novel Curriculum Person Clustering (CPC) method that can adaptively regulate the unsupervised clustering criterion according to the clustering confidence. Experiments on three long-term person re-id datasets show that our CPC outperforms SOTA unsupervised re-id methods and even closely matches the supervised re-id models.
Clue Me In: Semi-Supervised FGVC with Out-of-Distribution Data
Dec 06, 2021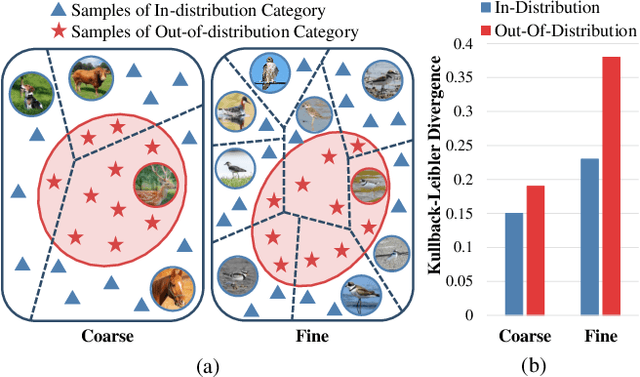
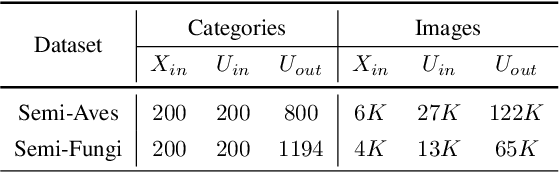
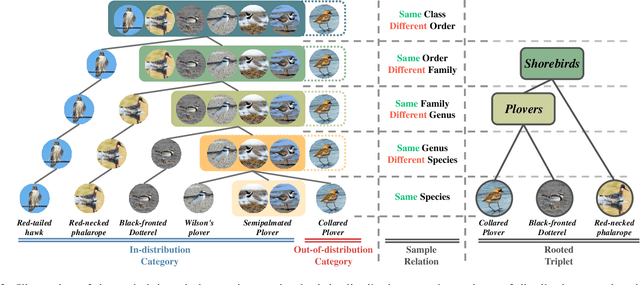
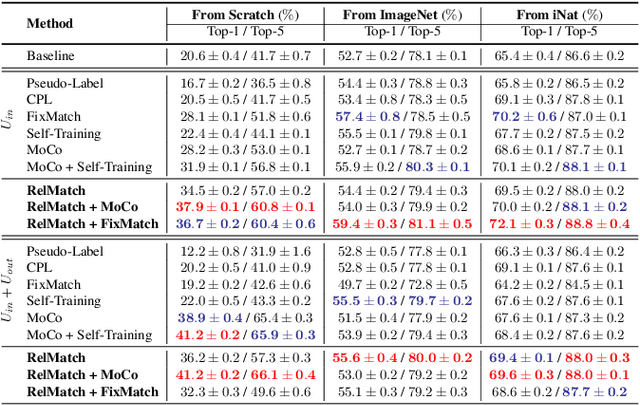
Despite great strides made on fine-grained visual classification (FGVC), current methods are still heavily reliant on fully-supervised paradigms where ample expert labels are called for. Semi-supervised learning (SSL) techniques, acquiring knowledge from unlabeled data, provide a considerable means forward and have shown great promise for coarse-grained problems. However, exiting SSL paradigms mostly assume in-distribution (i.e., category-aligned) unlabeled data, which hinders their effectiveness when re-proposed on FGVC. In this paper, we put forward a novel design specifically aimed at making out-of-distribution data work for semi-supervised FGVC, i.e., to "clue them in". We work off an important assumption that all fine-grained categories naturally follow a hierarchical structure (e.g., the phylogenetic tree of "Aves" that covers all bird species). It follows that, instead of operating on individual samples, we can instead predict sample relations within this tree structure as the optimization goal of SSL. Beyond this, we further introduced two strategies uniquely brought by these tree structures to achieve inter-sample consistency regularization and reliable pseudo-relation. Our experimental results reveal that (i) the proposed method yields good robustness against out-of-distribution data, and (ii) it can be equipped with prior arts, boosting their performance thus yielding state-of-the-art results. Code is available at https://github.com/PRIS-CV/RelMatch.
Making a Bird AI Expert Work for You and Me
Dec 06, 2021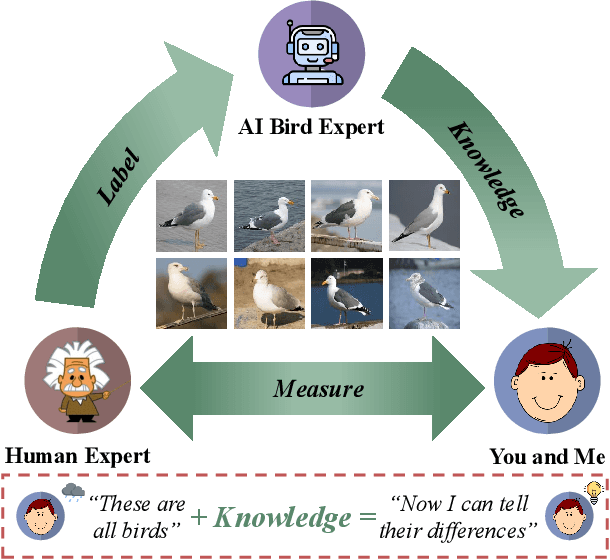



As powerful as fine-grained visual classification (FGVC) is, responding your query with a bird name of "Whip-poor-will" or "Mallard" probably does not make much sense. This however commonly accepted in the literature, underlines a fundamental question interfacing AI and human -- what constitutes transferable knowledge for human to learn from AI? This paper sets out to answer this very question using FGVC as a test bed. Specifically, we envisage a scenario where a trained FGVC model (the AI expert) functions as a knowledge provider in enabling average people (you and me) to become better domain experts ourselves, i.e. those capable in distinguishing between "Whip-poor-will" and "Mallard". Fig. 1 lays out our approach in answering this question. Assuming an AI expert trained using expert human labels, we ask (i) what is the best transferable knowledge we can extract from AI, and (ii) what is the most practical means to measure the gains in expertise given that knowledge? On the former, we propose to represent knowledge as highly discriminative visual regions that are expert-exclusive. For that, we devise a multi-stage learning framework, which starts with modelling visual attention of domain experts and novices before discriminatively distilling their differences to acquire the expert exclusive knowledge. For the latter, we simulate the evaluation process as book guide to best accommodate the learning practice of what is accustomed to humans. A comprehensive human study of 15,000 trials shows our method is able to consistently improve people of divergent bird expertise to recognise once unrecognisable birds. Interestingly, our approach also leads to improved conventional FGVC performance when the extracted knowledge defined is utilised as means to achieve discriminative localisation. Codes are available at: https://github.com/PRIS-CV/Making-a-Bird-AI-Expert-Work-for-You-and-Me
TODSum: Task-Oriented Dialogue Summarization with State Tracking
Oct 25, 2021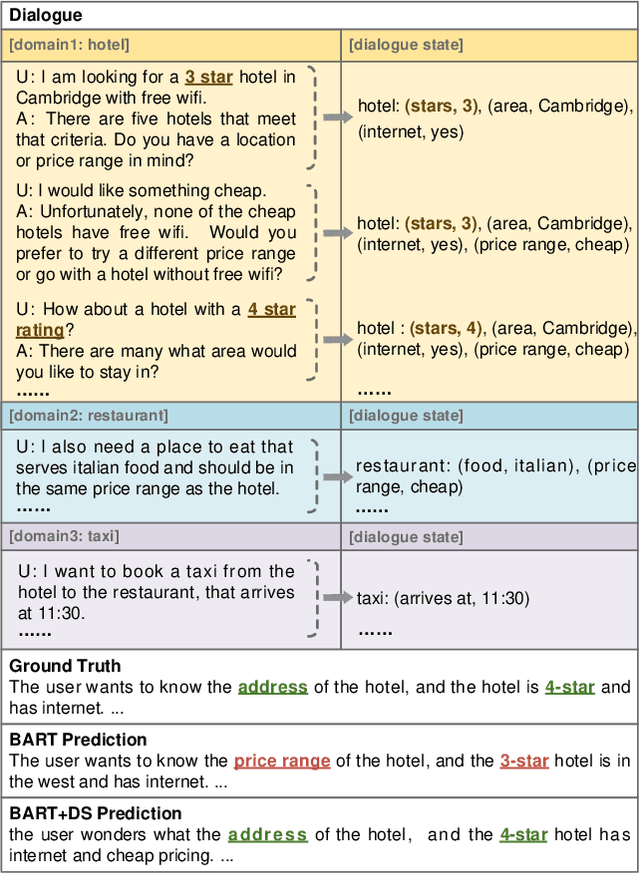
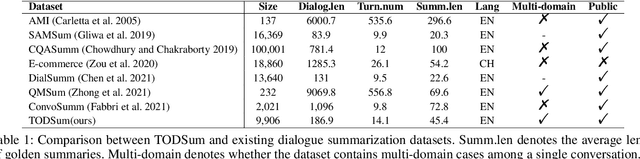

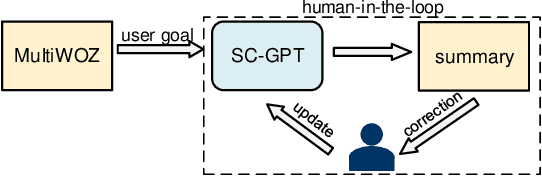
Previous dialogue summarization datasets mainly focus on open-domain chitchat dialogues, while summarization datasets for the broadly used task-oriented dialogue haven't been explored yet. Automatically summarizing such task-oriented dialogues can help a business collect and review needs to improve the service. Besides, previous datasets pay more attention to generate good summaries with higher ROUGE scores, but they hardly understand the structured information of dialogues and ignore the factuality of summaries. In this paper, we introduce a large-scale public Task-Oriented Dialogue Summarization dataset, TODSum, which aims to summarize the key points of the agent completing certain tasks with the user. Compared to existing work, TODSum suffers from severe scattered information issues and requires strict factual consistency, which makes it hard to directly apply recent dialogue summarization models. Therefore, we introduce additional dialogue state knowledge for TODSum to enhance the faithfulness of generated summaries. We hope a better understanding of conversational content helps summarization models generate concise and coherent summaries. Meanwhile, we establish a comprehensive benchmark for TODSum and propose a state-aware structured dialogue summarization model to integrate dialogue state information and dialogue history. Exhaustive experiments and qualitative analysis prove the effectiveness of dialogue structure guidance. Finally, we discuss the current issues of TODSum and potential development directions for future work.
Cluster-guided Asymmetric Contrastive Learning for Unsupervised Person Re-Identification
Jun 15, 2021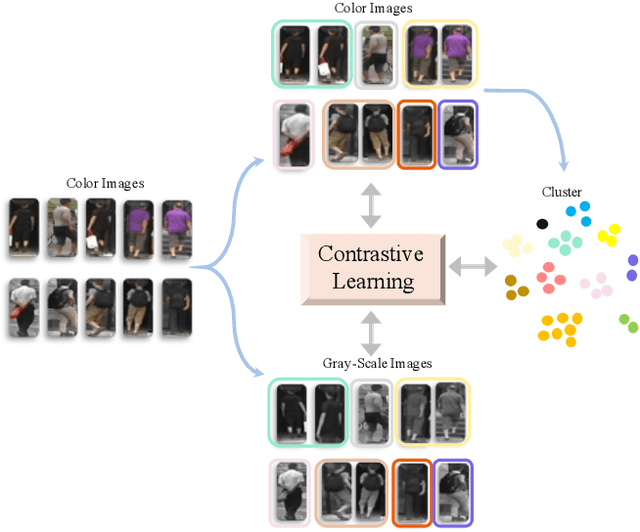
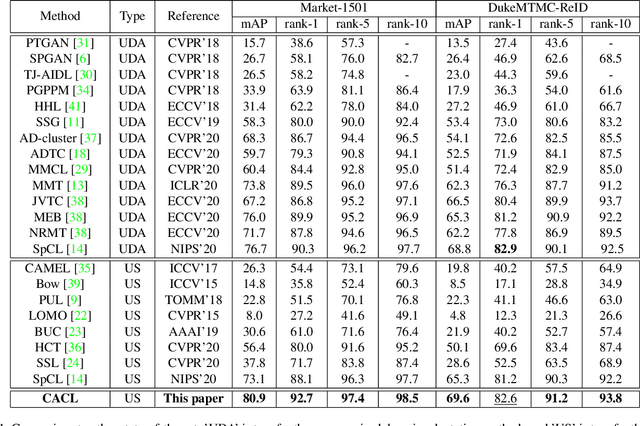

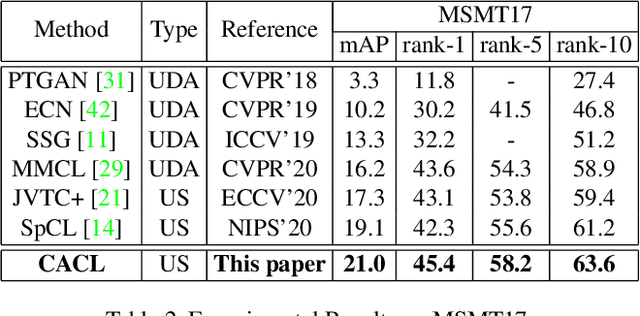
Unsupervised person re-identification (Re-ID) aims to match pedestrian images from different camera views in unsupervised setting. Existing methods for unsupervised person Re-ID are usually built upon the pseudo labels from clustering. However, the quality of clustering depends heavily on the quality of the learned features, which are overwhelmingly dominated by the colors in images especially in the unsupervised setting. In this paper, we propose a Cluster-guided Asymmetric Contrastive Learning (CACL) approach for unsupervised person Re-ID, in which cluster structure is leveraged to guide the feature learning in a properly designed asymmetric contrastive learning framework. To be specific, we propose a novel cluster-level contrastive loss to help the siamese network effectively mine the invariance in feature learning with respect to the cluster structure within and between different data augmentation views, respectively. Extensive experiments conducted on three benchmark datasets demonstrate superior performance of our proposal.
A Joint Model for Dropped Pronoun Recovery and Conversational Discourse Parsing in Chinese Conversational Speech
Jun 07, 2021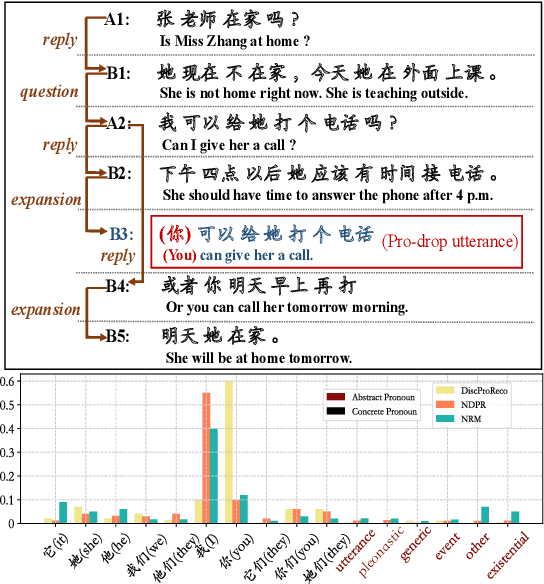
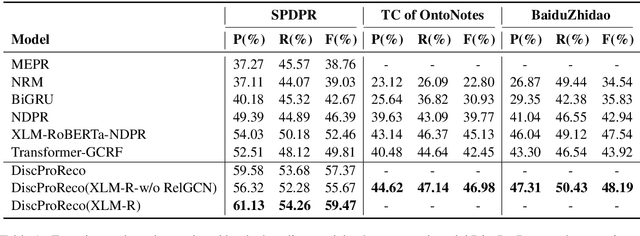
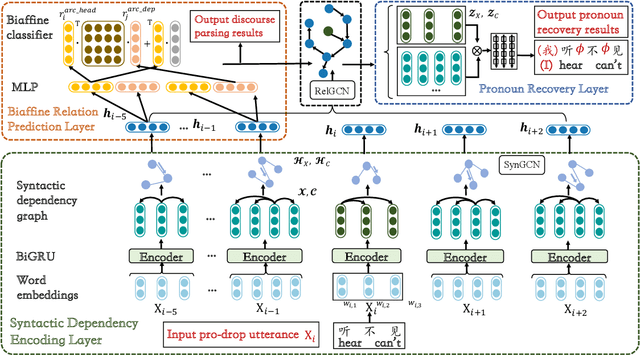
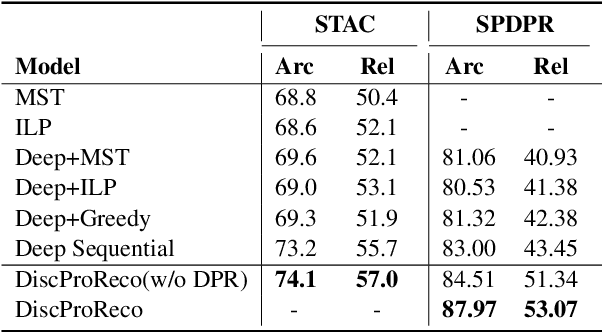
In this paper, we present a neural model for joint dropped pronoun recovery (DPR) and conversational discourse parsing (CDP) in Chinese conversational speech. We show that DPR and CDP are closely related, and a joint model benefits both tasks. We refer to our model as DiscProReco, and it first encodes the tokens in each utterance in a conversation with a directed Graph Convolutional Network (GCN). The token states for an utterance are then aggregated to produce a single state for each utterance. The utterance states are then fed into a biaffine classifier to construct a conversational discourse graph. A second (multi-relational) GCN is then applied to the utterance states to produce a discourse relation-augmented representation for the utterances, which are then fused together with token states in each utterance as input to a dropped pronoun recovery layer. The joint model is trained and evaluated on a new Structure Parsing-enhanced Dropped Pronoun Recovery (SPDPR) dataset that we annotated with both two types of information. Experimental results on the SPDPR dataset and other benchmarks show that DiscProReco significantly outperforms the state-of-the-art baselines of both tasks.
DF^2AM: Dual-level Feature Fusion and Affinity Modeling for RGB-Infrared Cross-modality Person Re-identification
Apr 01, 2021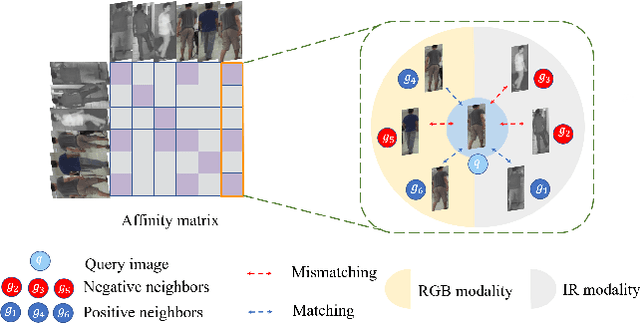
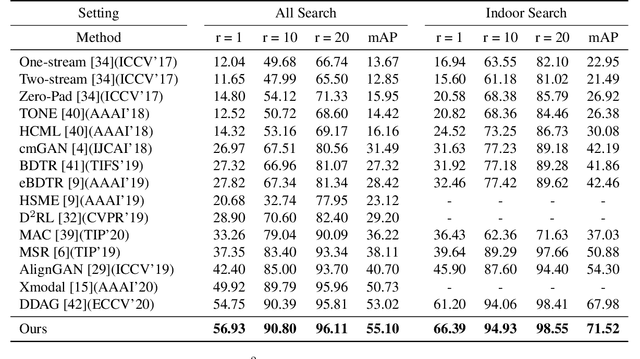
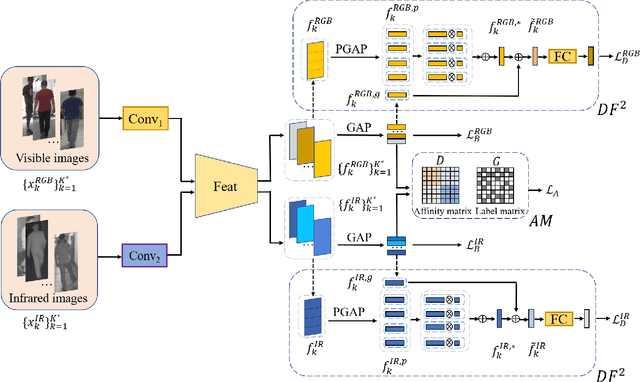
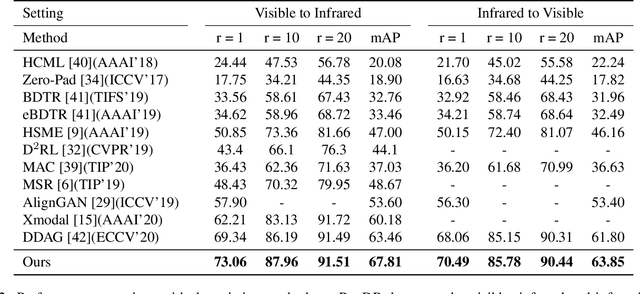
RGB-infrared person re-identification is a challenging task due to the intra-class variations and cross-modality discrepancy. Existing works mainly focus on learning modality-shared global representations by aligning image styles or feature distributions across modalities, while local feature from body part and relationships between person images are largely neglected. In this paper, we propose a Dual-level (i.e., local and global) Feature Fusion (DF^2) module by learning attention for discriminative feature from local to global manner. In particular, the attention for a local feature is determined locally, i.e., applying a learned transformation function on itself. Meanwhile, to further mining the relationships between global features from person images, we propose an Affinities Modeling (AM) module to obtain the optimal intra- and inter-modality image matching. Specifically, AM employes intra-class compactness and inter-class separability in the sample similarities as supervised information to model the affinities between intra- and inter-modality samples. Experimental results show that our proposed method outperforms state-of-the-arts by large margins on two widely used cross-modality re-ID datasets SYSU-MM01 and RegDB, respectively.
Unsupervised Person Re-identification via Simultaneous Clustering and Consistency Learning
Apr 01, 2021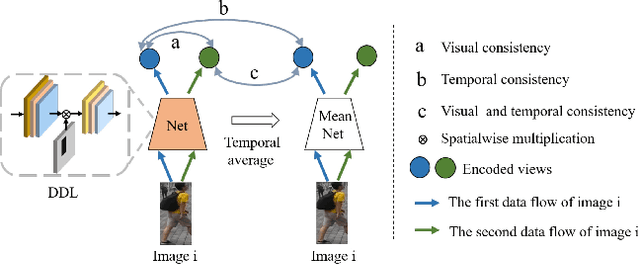
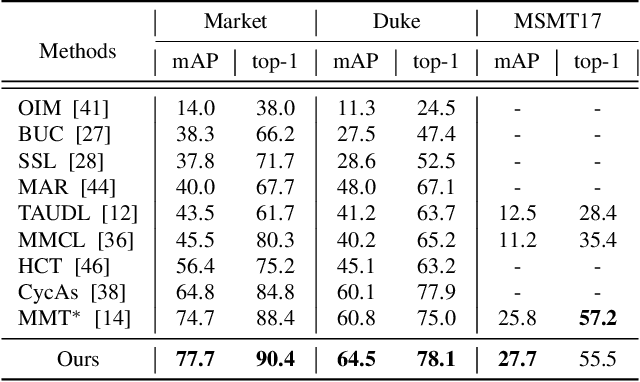
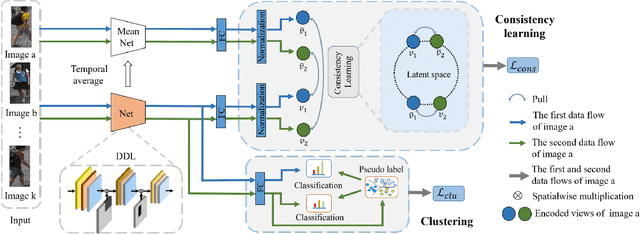
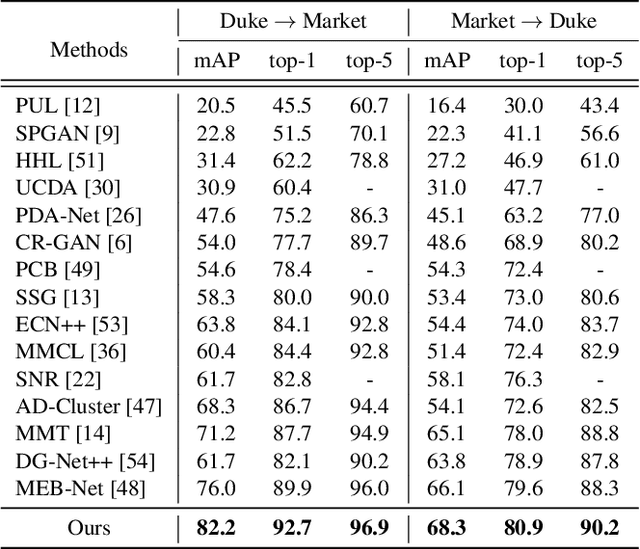
Unsupervised person re-identification (re-ID) has become an important topic due to its potential to resolve the scalability problem of supervised re-ID models. However, existing methods simply utilize pseudo labels from clustering for supervision and thus have not yet fully explored the semantic information in data itself, which limits representation capabilities of learned models. To address this problem, we design a pretext task for unsupervised re-ID by learning visual consistency from still images and temporal consistency during training process, such that the clustering network can separate the images into semantic clusters automatically. Specifically, the pretext task learns semantically meaningful representations by maximizing the agreement between two encoded views of the same image via a consistency loss in latent space. Meanwhile, we optimize the model by grouping the two encoded views into same cluster, thus enhancing the visual consistency between views. Experiments on Market-1501, DukeMTMC-reID and MSMT17 datasets demonstrate that our proposed approach outperforms the state-of-the-art methods by large margins.
Duplex Contextual Relation Network for Polyp Segmentation
Mar 12, 2021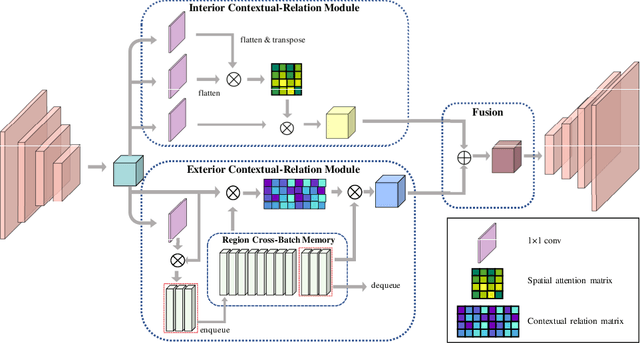
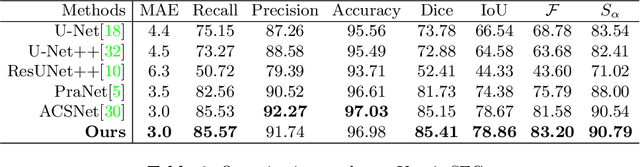
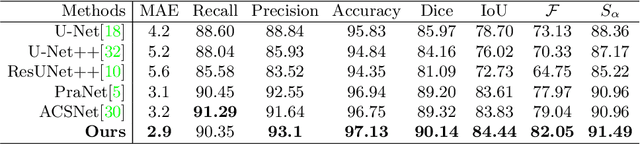
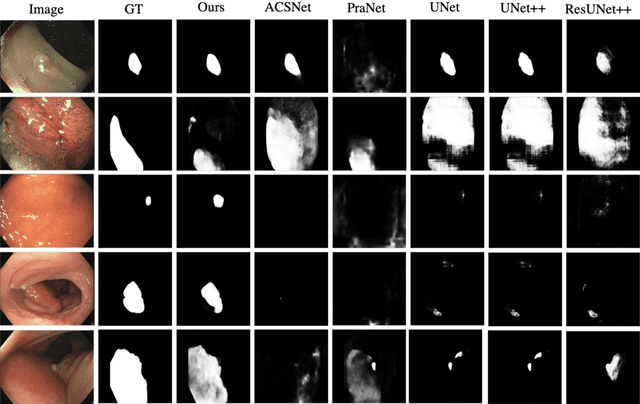
Polyp segmentation is of great importance in the early diagnosis and treatment of colorectal cancer. Since polyps vary in their shape, size, color, and texture, accurate polyp segmentation is very challenging. One promising way to mitigate the diversity of polyps is to model the contextual relation for each pixel such as using attention mechanism. However, previous methods only focus on learning the dependencies between the position within an individual image and ignore the contextual relation across different images. In this paper, we propose Duplex Contextual Relation Network (DCRNet) to capture both within-image and cross-image contextual relations. Specifically, we first design Interior Contextual-Relation Module to estimate the similarity between each position and all the positions within the same image. Then Exterior Contextual-Relation Module is incorporated to estimate the similarity between each position and the positions across different images. Based on the above two types of similarity, the feature at one position can be further enhanced by the contextual region embedding within and across images. To store the characteristic region embedding from all the images, a memory bank is designed and operates as a queue. Therefore, the proposed method can relate similar features even though they come from different images. We evaluate the proposed method on the EndoScene, Kvasir-SEG and the recently released large-scale PICCOLO dataset. Experimental results show that the proposed DCRNet outperforms the state-of-the-art methods in terms of the widely-used evaluation metrics.
A Comprehensive Evaluation Framework for Deep Model Robustness
Jan 24, 2021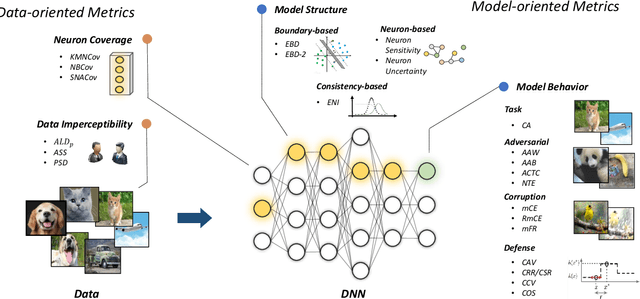
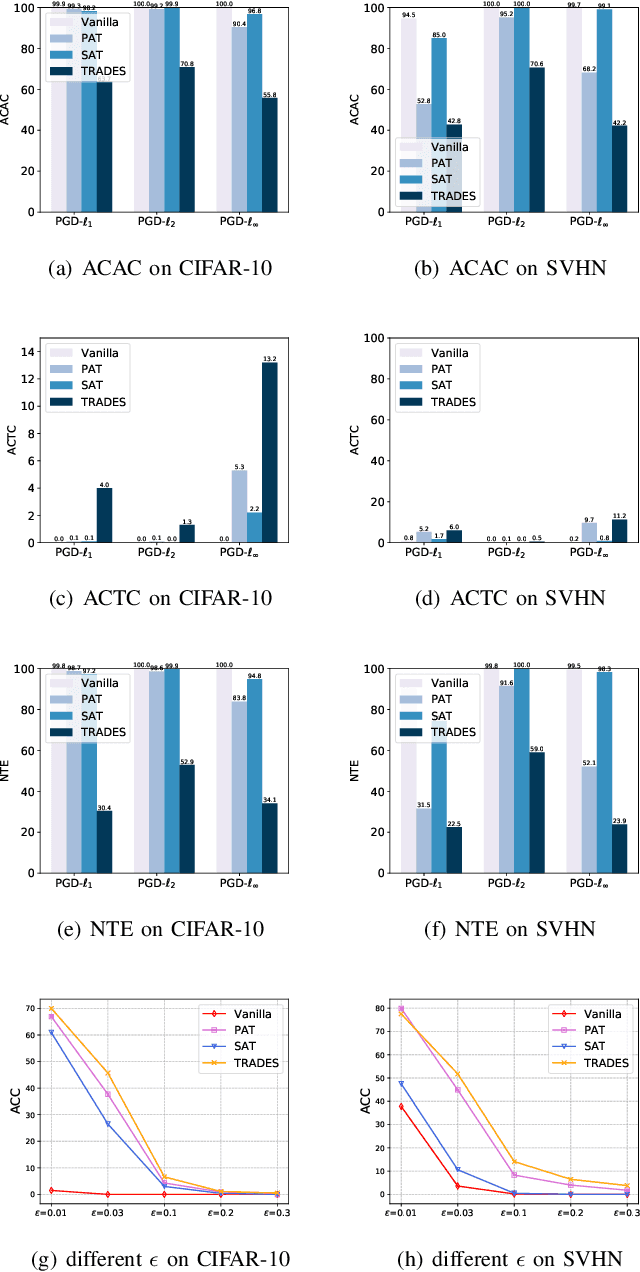
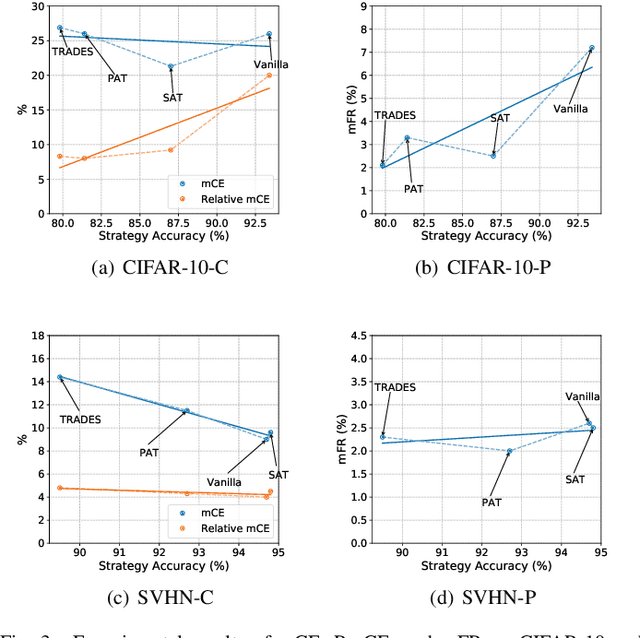
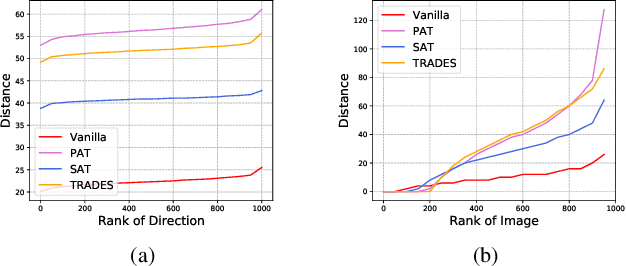
Deep neural networks (DNNs) have achieved remarkable performance across a wide area of applications. However, they are vulnerable to adversarial examples, which motivates the adversarial defense. By adopting simple evaluation metrics, most of the current defenses only conduct incomplete evaluations, which are far from providing comprehensive understandings of the limitations of these defenses. Thus, most proposed defenses are quickly shown to be attacked successfully, which result in the "arm race" phenomenon between attack and defense. To mitigate this problem, we establish a model robustness evaluation framework containing a comprehensive, rigorous, and coherent set of evaluation metrics, which could fully evaluate model robustness and provide deep insights into building robust models. With 23 evaluation metrics in total, our framework primarily focuses on the two key factors of adversarial learning (\ie, data and model). Through neuron coverage and data imperceptibility, we use data-oriented metrics to measure the integrity of test examples; by delving into model structure and behavior, we exploit model-oriented metrics to further evaluate robustness in the adversarial setting. To fully demonstrate the effectiveness of our framework, we conduct large-scale experiments on multiple datasets including CIFAR-10 and SVHN using different models and defenses with our open-source platform AISafety. Overall, our paper aims to provide a comprehensive evaluation framework which could demonstrate detailed inspections of the model robustness, and we hope that our paper can inspire further improvement to the model robustness.