 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTFNet: Exploiting Temporal Cues for Fast and Accurate LiDAR Semantic Segmentation
Sep 17, 2023



LiDAR semantic segmentation plays a crucial role in enabling autonomous driving and robots to understand their surroundings accurately and robustly. There are different types of methods, such as point-based, range-image-based, polar-based, and hybrid methods. Among these, range-image-based methods are widely used due to their efficiency. However, they face a significant challenge known as the ``many-to-one'' problem caused by the range image's limited horizontal and vertical angular resolution. As a result, around 20\% of the 3D points can be occluded. In this paper, we present TFNet, a range-image-based LiDAR semantic segmentation method that utilizes temporal information to address this issue. Specifically, we incorporate a temporal fusion layer to extract useful information from previous scans and integrate it with the current scan. We then design a max-voting-based post-processing technique to correct false predictions, particularly those caused by the ``many-to-one'' issue. We evaluated the approach on two benchmarks and demonstrate that the post-processing technique is generic and can be applied to various networks. We will release our code and models.
How Much Temporal Long-Term Context is Needed for Action Segmentation?
Aug 22, 2023Modeling long-term context in videos is crucial for many fine-grained tasks including temporal action segmentation. An interesting question that is still open is how much long-term temporal context is needed for optimal performance. While transformers can model the long-term context of a video, this becomes computationally prohibitive for long videos. Recent works on temporal action segmentation thus combine temporal convolutional networks with self-attentions that are computed only for a local temporal window. While these approaches show good results, their performance is limited by their inability to capture the full context of a video. In this work, we try to answer how much long-term temporal context is required for temporal action segmentation by introducing a transformer-based model that leverages sparse attention to capture the full context of a video. We compare our model with the current state of the art on three datasets for temporal action segmentation, namely 50Salads, Breakfast, and Assembly101. Our experiments show that modeling the full context of a video is necessary to obtain the best performance for temporal action segmentation.
Semantic RGB-D Image Synthesis
Aug 22, 2023



Collecting diverse sets of training images for RGB-D semantic image segmentation is not always possible. In particular, when robots need to operate in privacy-sensitive areas like homes, the collection is often limited to a small set of locations. As a consequence, the annotated images lack diversity in appearance and approaches for RGB-D semantic image segmentation tend to overfit the training data. In this paper, we thus introduce semantic RGB-D image synthesis to address this problem. It requires synthesising a realistic-looking RGB-D image for a given semantic label map. Current approaches, however, are uni-modal and cannot cope with multi-modal data. Indeed, we show that extending uni-modal approaches to multi-modal data does not perform well. In this paper, we therefore propose a generator for multi-modal data that separates modal-independent information of the semantic layout from the modal-dependent information that is needed to generate an RGB and a depth image, respectively. Furthermore, we propose a discriminator that ensures semantic consistency between the label maps and the generated images and perceptual similarity between the real and generated images. Our comprehensive experiments demonstrate that the proposed method outperforms previous uni-modal methods by a large margin and that the accuracy of an approach for RGB-D semantic segmentation can be significantly improved by mixing real and generated images during training.
Smoothness Similarity Regularization for Few-Shot GAN Adaptation
Aug 18, 2023



The task of few-shot GAN adaptation aims to adapt a pre-trained GAN model to a small dataset with very few training images. While existing methods perform well when the dataset for pre-training is structurally similar to the target dataset, the approaches suffer from training instabilities or memorization issues when the objects in the two domains have a very different structure. To mitigate this limitation, we propose a new smoothness similarity regularization that transfers the inherently learned smoothness of the pre-trained GAN to the few-shot target domain even if the two domains are very different. We evaluate our approach by adapting an unconditional and a class-conditional GAN to diverse few-shot target domains. Our proposed method significantly outperforms prior few-shot GAN adaptation methods in the challenging case of structurally dissimilar source-target domains, while performing on par with the state of the art for similar source-target domains.
3DMOTFormer: Graph Transformer for Online 3D Multi-Object Tracking
Aug 12, 2023Tracking 3D objects accurately and consistently is crucial for autonomous vehicles, enabling more reliable downstream tasks such as trajectory prediction and motion planning. Based on the substantial progress in object detection in recent years, the tracking-by-detection paradigm has become a popular choice due to its simplicity and efficiency. State-of-the-art 3D multi-object tracking (MOT) approaches typically rely on non-learned model-based algorithms such as Kalman Filter but require many manually tuned parameters. On the other hand, learning-based approaches face the problem of adapting the training to the online setting, leading to inevitable distribution mismatch between training and inference as well as suboptimal performance. In this work, we propose 3DMOTFormer, a learned geometry-based 3D MOT framework building upon the transformer architecture. We use an Edge-Augmented Graph Transformer to reason on the track-detection bipartite graph frame-by-frame and conduct data association via edge classification. To reduce the distribution mismatch between training and inference, we propose a novel online training strategy with an autoregressive and recurrent forward pass as well as sequential batch optimization. Using CenterPoint detections, our approach achieves 71.2% and 68.2% AMOTA on the nuScenes validation and test split, respectively. In addition, a trained 3DMOTFormer model generalizes well across different object detectors. Code is available at: https://github.com/dsx0511/3DMOTFormer.
Action Anticipation with Goal Consistency
Jun 26, 2023In this paper, we address the problem of short-term action anticipation, i.e., we want to predict an upcoming action one second before it happens. We propose to harness high-level intent information to anticipate actions that will take place in the future. To this end, we incorporate an additional goal prediction branch into our model and propose a consistency loss function that encourages the anticipated actions to conform to the high-level goal pursued in the video. In our experiments, we show the effectiveness of the proposed approach and demonstrate that our method achieves state-of-the-art results on two large-scale datasets: Assembly101 and COIN.
PowerBEV: A Powerful Yet Lightweight Framework for Instance Prediction in Bird's-Eye View
Jun 19, 2023Accurately perceiving instances and predicting their future motion are key tasks for autonomous vehicles, enabling them to navigate safely in complex urban traffic. While bird's-eye view (BEV) representations are commonplace in perception for autonomous driving, their potential in a motion prediction setting is less explored. Existing approaches for BEV instance prediction from surround cameras rely on a multi-task auto-regressive setup coupled with complex post-processing to predict future instances in a spatio-temporally consistent manner. In this paper, we depart from this paradigm and propose an efficient novel end-to-end framework named POWERBEV, which differs in several design choices aimed at reducing the inherent redundancy in previous methods. First, rather than predicting the future in an auto-regressive fashion, POWERBEV uses a parallel, multi-scale module built from lightweight 2D convolutional networks. Second, we show that segmentation and centripetal backward flow are sufficient for prediction, simplifying previous multi-task objectives by eliminating redundant output modalities. Building on this output representation, we propose a simple, flow warping-based post-processing approach which produces more stable instance associations across time. Through this lightweight yet powerful design, POWERBEV outperforms state-of-the-art baselines on the NuScenes Dataset and poses an alternative paradigm for BEV instance prediction. We made our code publicly available at: https://github.com/EdwardLeeLPZ/PowerBEV.
A Dual-Source Attention Transformer for Multi-Person Pose Tracking
Jun 09, 2023Multi-person pose tracking is an important element for many applications and requires to estimate the human poses of all persons in a video and to track them over time. The association of poses across frames remains an open research problem, in particular for online tracking methods, due to motion blur, crowded scenes and occlusions. To tackle the association challenge, we propose a Dual-Source Attention Transformer that incorporates three core aspects: i) In order to re-identify persons that have been occluded, we propose a pose-conditioned re-identification network that provides an initial embedding and allows to match persons even if the number of visible joints differs between the frames. ii) We incorporate edge embeddings based on temporal pose similarity and the impact of appearance and pose similarity is automatically adapted. iii) We propose an attention based matching layer for pose-to-track association and duplicate removal. We evaluate our approach on Market1501, PoseTrack 2018 and PoseTrack21.
Location-aware Adaptive Denormalization: A Deep Learning Approach For Wildfire Danger Forecasting
Dec 16, 2022Climate change is expected to intensify and increase extreme events in the weather cycle. Since this has a significant impact on various sectors of our life, recent works are concerned with identifying and predicting such extreme events from Earth observations. This paper proposes a 2D/3D two-branch convolutional neural network (CNN) for wildfire danger forecasting. To use a unified framework, previous approaches duplicate static variables along the time dimension and neglect the intrinsic differences between static and dynamic variables. Furthermore, most existing multi-branch architectures lose the interconnections between the branches during the feature learning stage. To address these issues, we propose a two-branch architecture with a Location-aware Adaptive Denormalization layer (LOADE). Using LOADE as a building block, we can modulate the dynamic features conditional on their geographical location. Thus, our approach considers feature properties as a unified yet compound 2D/3D model. Besides, we propose using an absolute temporal encoding for time-related forecasting problems. Our experimental results show a better performance of our approach than other baselines on the challenging FireCube dataset.
Robust Action Segmentation from Timestamp Supervision
Oct 12, 2022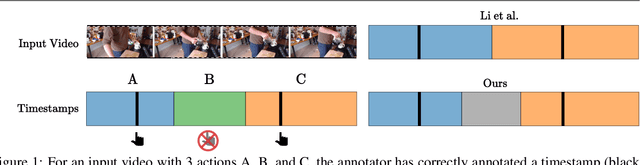
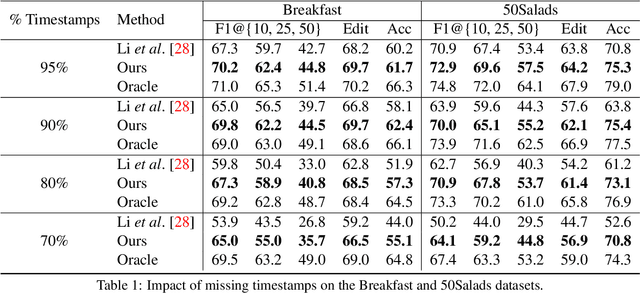
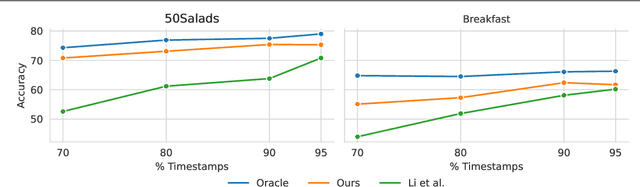
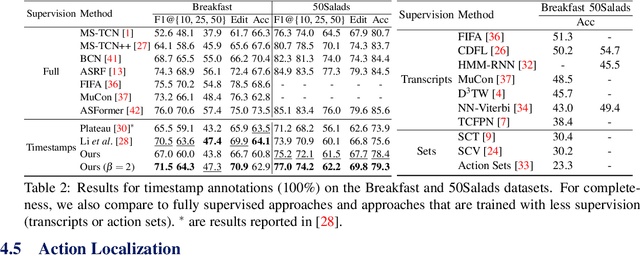
Action segmentation is the task of predicting an action label for each frame of an untrimmed video. As obtaining annotations to train an approach for action segmentation in a fully supervised way is expensive, various approaches have been proposed to train action segmentation models using different forms of weak supervision, e.g., action transcripts, action sets, or more recently timestamps. Timestamp supervision is a promising type of weak supervision as obtaining one timestamp per action is less expensive than annotating all frames, but it provides more information than other forms of weak supervision. However, previous works assume that every action instance is annotated with a timestamp, which is a restrictive assumption since it assumes that annotators do not miss any action. In this work, we relax this restrictive assumption and take missing annotations for some action instances into account. We show that our approach is more robust to missing annotations compared to other approaches and various baselines.