 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP-Count: Persistence-based Counting of White Matter Hyperintensities in Brain MRI
Mar 20, 2024



White matter hyperintensities (WMH) are a hallmark of cerebrovascular disease and multiple sclerosis. Automated WMH segmentation methods enable quantitative analysis via estimation of total lesion load, spatial distribution of lesions, and number of lesions (i.e., number of connected components after thresholding), all of which are correlated with patient outcomes. While the two former measures can generally be estimated robustly, the number of lesions is highly sensitive to noise and segmentation mistakes -- even when small connected components are eroded or disregarded. In this article, we present P-Count, an algebraic WMH counting tool based on persistent homology that accounts for the topological features of WM lesions in a robust manner. Using computational geometry, P-Count takes the persistence of connected components into consideration, effectively filtering out the noisy WMH positives, resulting in a more accurate count of true lesions. We validated P-Count on the ISBI2015 longitudinal lesion segmentation dataset, where it produces significantly more accurate results than direct thresholding.
H-SynEx: Using synthetic images and ultra-high resolution ex vivo MRI for hypothalamus subregion segmentation
Jan 30, 2024



Purpose: To develop a method for automated segmentation of hypothalamus subregions informed by ultra-high resolution ex vivo magnetic resonance images (MRI), which generalizes across MRI sequences and resolutions without retraining. Materials and Methods: We trained our deep learning method, H-synEx, with synthetic images derived from label maps built from ultra-high resolution ex vivo MRI scans, which enables finer-grained manual segmentation when compared with 1mm isometric in vivo images. We validated this retrospective study using 1535 in vivo images from six datasets and six MRI sequences. The quantitative evaluation used the Dice Coefficient (DC) and Average Hausdorff distance (AVD). Statistical analysis compared hypothalamic subregion volumes in controls, Alzheimer's disease (AD), and behavioral variant frontotemporal dementia (bvFTD) subjects using the area under the curve (AUC) and Wilcoxon rank sum test. Results: H-SynEx can segment the hypothalamus across various MRI sequences, encompassing FLAIR sequences with significant slice spacing (5mm). Using hypothalamic volumes on T1w images to distinguish control from AD and bvFTD patients, we observed AUC values of 0.74 and 0.79 respectively. Additionally, AUC=0.66 was found for volume variation on FLAIR scans when comparing control and non-patients. Conclusion: Our results show that H-SynEx successfully leverages information from ultra-high resolution scans to segment in vivo from different MRI sequences such as T1w, T2w, PD, qT1, FA, and FLAIR. We also found that our automated segmentation was able to discriminate controls versus patients on FLAIR images with 5mm spacing. H-SynEx is openly available at https://github.com/liviamarodrigues/hsynex.
JUMP: A joint multimodal registration pipeline for neuroimaging with minimal preprocessing
Jan 25, 2024
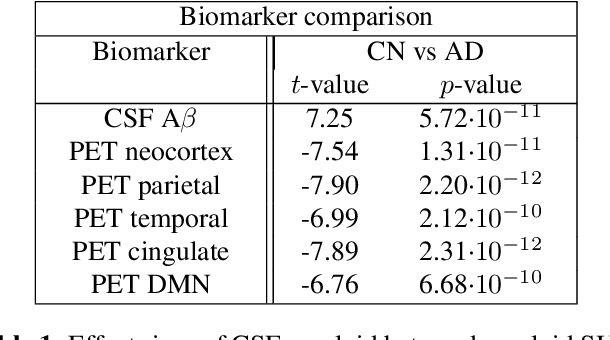
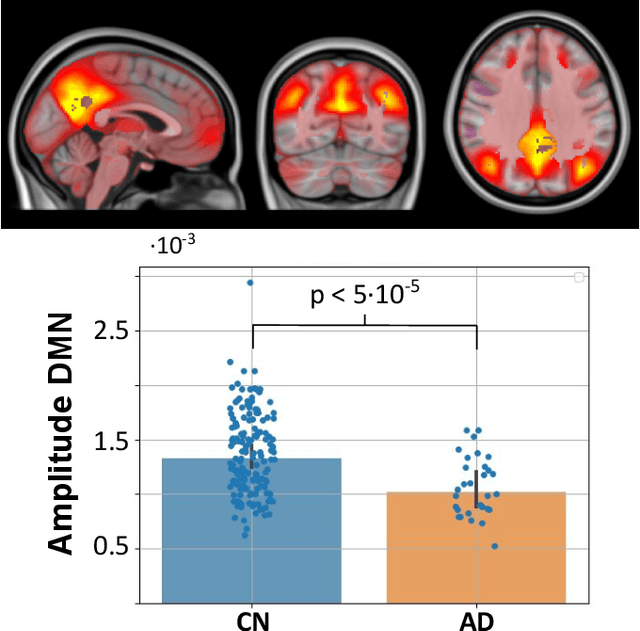
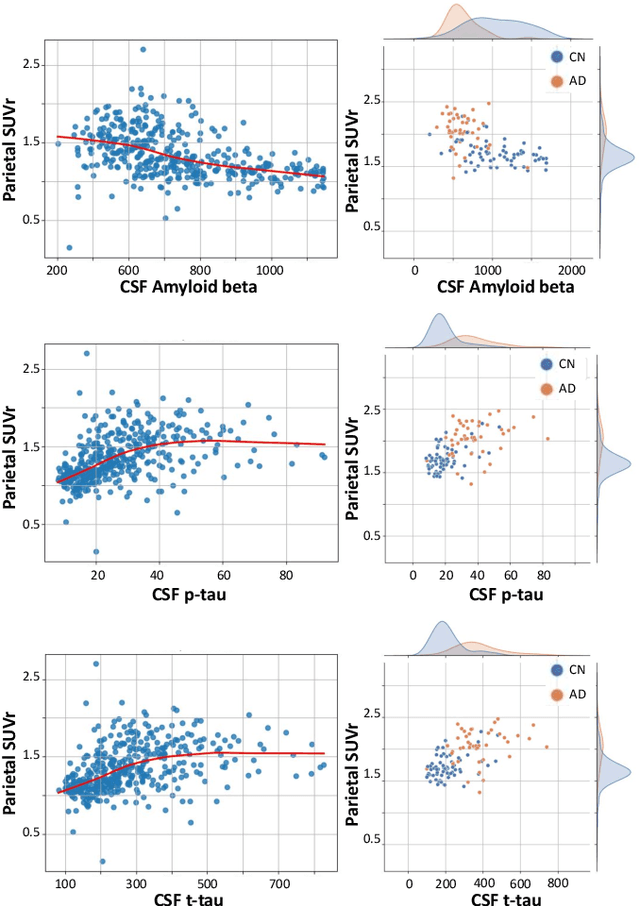
We present a pipeline for unbiased and robust multimodal registration of neuroimaging modalities with minimal pre-processing. While typical multimodal studies need to use multiple independent processing pipelines, with diverse options and hyperparameters, we propose a single and structured framework to jointly process different image modalities. The use of state-of-the-art learning-based techniques enables fast inferences, which makes the presented method suitable for large-scale and/or multi-cohort datasets with a diverse number of modalities per session. The pipeline currently works with structural MRI, resting state fMRI and amyloid PET images. We show the predictive power of the derived biomarkers using in a case-control study and study the cross-modal relationship between different image modalities. The code can be found in https: //github.com/acasamitjana/JUMP.
Quantifying white matter hyperintensity and brain volumes in heterogeneous clinical and low-field portable MRI
Dec 08, 2023



Brain atrophy and white matter hyperintensity (WMH) are critical neuroimaging features for ascertaining brain injury in cerebrovascular disease and multiple sclerosis. Automated segmentation and quantification is desirable but existing methods require high-resolution MRI with good signal-to-noise ratio (SNR). This precludes application to clinical and low-field portable MRI (pMRI) scans, thus hampering large-scale tracking of atrophy and WMH progression, especially in underserved areas where pMRI has huge potential. Here we present a method that segments white matter hyperintensity and 36 brain regions from scans of any resolution and contrast (including pMRI) without retraining. We show results on six public datasets and on a private dataset with paired high- and low-field scans (3T and 64mT), where we attain strong correlation between the WMH ($\rho$=.85) and hippocampal volumes (r=.89) estimated at both fields. Our method is publicly available as part of FreeSurfer, at: http://surfer.nmr.mgh.harvard.edu/fswiki/WMH-SynthSeg.
Fully Convolutional Slice-to-Volume Reconstruction for Single-Stack MRI
Dec 05, 2023



In magnetic resonance imaging (MRI), slice-to-volume reconstruction (SVR) refers to computational reconstruction of an unknown 3D magnetic resonance volume from stacks of 2D slices corrupted by motion. While promising, current SVR methods require multiple slice stacks for accurate 3D reconstruction, leading to long scans and limiting their use in time-sensitive applications such as fetal fMRI. Here, we propose a SVR method that overcomes the shortcomings of previous work and produces state-of-the-art reconstructions in the presence of extreme inter-slice motion. Inspired by the recent success of single-view depth estimation methods, we formulate SVR as a single-stack motion estimation task and train a fully convolutional network to predict a motion stack for a given slice stack, producing a 3D reconstruction as a byproduct of the predicted motion. Extensive experiments on the SVR of adult and fetal brains demonstrate that our fully convolutional method is twice as accurate as previous SVR methods. Our code is available at github.com/seannz/svr.
Brain-ID: Learning Robust Feature Representations for Brain Imaging
Nov 28, 2023Recent learning-based approaches have made astonishing advances in calibrated medical imaging like computerized tomography, yet they struggle to generalize in uncalibrated modalities -- notoriously magnetic resonance imaging (MRI), where performance is highly sensitive to the differences in MR contrast, resolution, and orientation between the training and testing data. This prevents broad applicability to the diverse clinical acquisition protocols in the real world. We introduce Brain-ID, a robust feature representation learning strategy for brain imaging, which is contrast-agnostic, and robust to the brain anatomy of each subject regardless of the appearance of acquired images (i.e., deformation, contrast, resolution, orientation, artifacts, etc). Brain-ID is trained entirely on synthetic data, and easily adapts to downstream tasks with our proposed simple one-layer solution. We validate the robustness of Brain-ID features, and evaluate their performance in a variety of downstream applications, including both contrast-independent (anatomy reconstruction/contrast synthesis, brain segmentation), and contrast-dependent (super-resolution, bias field estimation) tasks. Extensive experiments on 6 public datasets demonstrate that Brain-ID achieves state-of-the-art performance in all tasks, and more importantly, preserves its performance when only limited training data is available.
Resolution- and Stimulus-agnostic Super-Resolution of Ultra-High-Field Functional MRI: Application to Visual Studies
Nov 25, 2023



High-resolution fMRI provides a window into the brain's mesoscale organization. Yet, higher spatial resolution increases scan times, to compensate for the low signal and contrast-to-noise ratio. This work introduces a deep learning-based 3D super-resolution (SR) method for fMRI. By incorporating a resolution-agnostic image augmentation framework, our method adapts to varying voxel sizes without retraining. We apply this innovative technique to localize fine-scale motion-selective sites in the early visual areas. Detection of these sites typically requires a resolution higher than 1 mm isotropic, whereas here, we visualize them based on lower resolution (2-3mm isotropic) fMRI data. Remarkably, the super-resolved fMRI is able to recover high-frequency detail of the interdigitated organization of these sites (relative to the color-selective sites), even with training data sourced from different subjects and experimental paradigms -- including non-visual resting-state fMRI, underscoring its robustness and versatility. Quantitative and qualitative results indicate that our method has the potential to enhance the spatial resolution of fMRI, leading to a drastic reduction in acquisition time.
USLR: an open-source tool for unbiased and smooth longitudinal registration of brain MR
Nov 14, 2023We present USLR, a computational framework for longitudinal registration of brain MRI scans to estimate nonlinear image trajectories that are smooth across time, unbiased to any timepoint, and robust to imaging artefacts. It operates on the Lie algebra parameterisation of spatial transforms (which is compatible with rigid transforms and stationary velocity fields for nonlinear deformation) and takes advantage of log-domain properties to solve the problem using Bayesian inference. USRL estimates rigid and nonlinear registrations that: (i) bring all timepoints to an unbiased subject-specific space; and (i) compute a smooth trajectory across the imaging time-series. We capitalise on learning-based registration algorithms and closed-form expressions for fast inference. A use-case Alzheimer's disease study is used to showcase the benefits of the pipeline in multiple fronts, such as time-consistent image segmentation to reduce intra-subject variability, subject-specific prediction or population analysis using tensor-based morphometry. We demonstrate that such approach improves upon cross-sectional methods in identifying group differences, which can be helpful in detecting more subtle atrophy levels or in reducing sample sizes in clinical trials. The code is publicly available in https://github.com/acasamitjana/uslr
Diffeomorphic Multi-Resolution Deep Learning Registration for Applications in Breast MRI
Sep 24, 2023



In breast surgical planning, accurate registration of MR images across patient positions has the potential to improve the localisation of tumours during breast cancer treatment. While learning-based registration methods have recently become the state-of-the-art approach for most medical image registration tasks, these methods have yet to make inroads into breast image registration due to certain difficulties-the lack of rich texture information in breast MR images and the need for the deformations to be diffeomophic. In this work, we propose learning strategies for breast MR image registration that are amenable to diffeomorphic constraints, together with early experimental results from in-silico and in-vivo experiments. One key contribution of this work is a registration network which produces superior registration outcomes for breast images in addition to providing diffeomorphic guarantees.
Robust and Generalisable Segmentation of Subtle Epilepsy-causing Lesions: a Graph Convolutional Approach
Jun 05, 2023



Focal cortical dysplasia (FCD) is a leading cause of drug-resistant focal epilepsy, which can be cured by surgery. These lesions are extremely subtle and often missed even by expert neuroradiologists. "Ground truth" manual lesion masks are therefore expensive, limited and have large inter-rater variability. Existing FCD detection methods are limited by high numbers of false positive predictions, primarily due to vertex- or patch-based approaches that lack whole-brain context. Here, we propose to approach the problem as semantic segmentation using graph convolutional networks (GCN), which allows our model to learn spatial relationships between brain regions. To address the specific challenges of FCD identification, our proposed model includes an auxiliary loss to predict distance from the lesion to reduce false positives and a weak supervision classification loss to facilitate learning from uncertain lesion masks. On a multi-centre dataset of 1015 participants with surface-based features and manual lesion masks from structural MRI data, the proposed GCN achieved an AUC of 0.74, a significant improvement against a previously used vertex-wise multi-layer perceptron (MLP) classifier (AUC 0.64). With sensitivity thresholded at 67%, the GCN had a specificity of 71% in comparison to 49% when using the MLP. This improvement in specificity is vital for clinical integration of lesion-detection tools into the radiological workflow, through increasing clinical confidence in the use of AI radiological adjuncts and reducing the number of areas requiring expert review.